





























Modern analytical databases (OLAP systems) are engineered to optimize large-scale, read-heavy queries over historical or event-driven data. Transactional databases (OLTP), on the other hand, are built for handling frequent updates and inserts, focusing on fast, consistent transactions. OLTP is all about fast transactions, dealing with data one row at a time. OLAP (Online Analytical Processing) is different—it often uses columnar storage, reads only the data columns, making complex queries much much faster. Picking the right analytical tool is crucial; it affects how fast your queries are; how well your system handles more data or users; and even your budget. Get it wrong, and you could face sluggish reports and spiraling costs. So, let's look at two popular options: ClickHouse, an open source database that was born at Yandex and is known for its speed, and Snowflake, a cloud-based SaaS platform that's popular for its flexibility and ease of management.
In this article, we will compare ClickHouse vs Snowflake—two leading OLAP solutions with distinct designs philosophies—across seven key areas: architecture, performance, data ingestion, deployment options, ecosystem, security, and pricing.
In a hurry? Jump straight to each section:
What is ClickHouse?
ClickHouse (“Clickstream Data Warehouse”) is a high-performance, open source OLAP database developed by Yandex. It is purpose-built for sub-second analytical queries over petabyte-scale datasets, especially for real-time analytics on large, append-only event data.
Key Features & Strengths of ClickHouse:
So, what gives ClickHouse its reputation for speed and makes it a distinct player? Let's break down its core features and strengths.
1) Columnar Storage — Data is stored in columns, not rows, which allows for efficient compression, vectorized execution, and fast scans of only the columns needed by each query.
2) Vectorized Query Execution — ClickHouse processes data in batches (vectors), not row-by-row. This approach leverages CPU cache locality and SIMD (Single Instruction, Multiple Data) instructions, significantly improving throughput for analytical workloads.
3) Efficient Data Compression — ClickHouse supports codecs like LZ4 (default—very fast), ZSTD (higher compression ratio), and others. Columnar storage amplifies compression because column values tend to be similar (low cardinality), reducing storage and I/O costs.
4) MergeTree Engine Family — MergeTree engine family is arguably the secret sauce behind ClickHouse's performance, especially for writes and reads. The MergeTree engine (and its variations like ReplacingMergeTree, SummingMergeTree, AggregatingMergeTree, CollapsingMergeTree) is optimized for high-insertion rates and fast data retrieval. Data is written in parts, sorted by a primary key, and merged in the background. Note that this primary key also acts as a sparse index, allowing Clickhouse to quickly skip irrelevant data blocks during reads.
5) Distributed Query Processing — ClickHouse clusters support horizontal scaling (sharding across nodes), replication for high availability, and distributed query processing. Queries can be executed in parallel across shards, with coordination handled by the client or server.
6) Real-time Data Ingestion — ClickHouse can ingest millions of rows per second and make them available for querying with minimal delay (~seconds). It is widely used for observability, log analytics, and telemetry use cases.
7) Extensible SQL Support — ClickHouse implements a large subset of ANSI SQL, with extensions for array processing, custom aggregate functions, low-latency materialized views, window functions, and more.
8) Open Source and Self-Hostable — ClickHouse is open source and licensed under Apache 2.0. It can be deployed on-premises, in private clouds, or via managed services (ClickHouse Cloud, Altinity.Cloud, and more).
And What About Snowflake?
Snowflake is a fully managed, cloud-native SaaS data platform for analytics, warehousing, data lakes, data engineering, and secure data sharing. Unlike ClickHouse, Snowflake is not open source and is only available as a managed service on major clouds (AWS, Azure, GCP).
Snowflake’s core design principle is the separation of storage and compute—enabling independent scaling, workload isolation, and elasticity.
What is Snowflake? - ClickHouse vs Snowflake - Cloud Data Platform
Key Features & Strengths of Snowflake:
So what makes Snowflake stand out, particularly in the ClickHouse vs Snowflake comparison?
1) Cloud-Native, Multi-Cloud Architecture — Snowflake was built from the ground up for the cloud (no on-premises version). It leverages native cloud object storage (S3, Azure Blob, GCS) for persistent data, and cloud VMs for compute.
2) Separation of Storage and Compute — In Snowflake, your data is stored centrally in compressed, columnar, immutable files in object storage(like S3, ADLS, GCS). Compute is handled by “Virtual Warehouses”—independent clusters that can be sized and scaled elastically, or even auto-paused to save cost. Multiple warehouses can simultaneously query the same data without contention.
3) Multi-Cluster Shared Data Architecture — Snowflake, which builds on the concept of isolation, allows several virtual warehouses to access the same central data store at the same time without interfering with one another.
4) Support for Structured, Semi-Structured, and Unstructured Data — Snowflake provides native support for relational/tabular data alongside semi-structured formats (JSON, Avro, Parquet, ORC, XML). Snowflake’s VARIANT, ARRAY, and OBJECT types allow seamless ingestion and querying of semi-structured data. Unstructured data (images, PDFs, etc.) is supported via external tables and directory tables.
5) Time Travel & Fail-safe(Undo Button for Data) — Snowflake automatically retains historical versions of every table for a configurable period (up to 90 days, depending on edition). You can query previous versions (Time Travel), recover dropped tables, or restore from accidental data loss. After Time Travel, a 7-day Fail-safe period allows Snowflake support to recover data (non-user-accessible).
6) Zero-Copy Cloning — Snowflake allows you to create instant, space-efficient clones of databases, schemas, or tables for testing, development, or branching—without duplicating underlying storage.
7) Secure, Cross-Account Data Sharing — Snowflake allows you to securely share live, read-only data with other Snowflake accounts (or even external organizations) without physically moving or copying data. Data sharing is managed at the metadata level.
8) Snowsight Web UI and APIs — Snowflake provides a modern web interface (Snowsight) for querying, visualizations, data exploration, as well as programmatic APIs, connectors, and SDKs.
9) Enterprise-Grade Security — Snowflake has built in Enterprise-Grade security like Always-on encryption (in-transit and at-rest), role-based access control, multi-factor authentication, network policies, private connectivity, and compliance certifications (SOC2, HIPAA, PCI DSS, FedRAMP, etc.).
10) Automatic Scaling, Maintenance, and High Availability — Snowflake handles patching, availability, resource optimization, and disaster recovery transparently.
… and so much more!
What Is the Difference Between Clickhouse and Snowflake?
🔮 ClickHouse vs Snowflake—Side-by-Side Comparison 🔮
Here is a high level summary of ClickHouse vs Snowflake.
| ClickHouse | 🔮 | Snowflake |
| Shared-nothing, distributed MPP engine; three-layer design (query, storage, integration); supports compute-storage separation in cloud (object storage for data, stateless compute) | Architecture | Cloud-native SaaS platform architected for full separation of compute and storage (object storage, micro-partitioned), with a central cloud services layer for metadata, control, and governance |
| Open-source columnar OLAP database (Apache 2.0) with optional managed ClickHouse Cloud on AWS/GCP/Azure | Primary Model | Fully managed SaaS data platform (not open source); no self-hosted/on-premises version; available on AWS, Azure, GCP |
| Ultra-low-latency OLAP on petabyte-scale data via vectorized execution, sparse primary indexes, adaptive compression; performance tunable via table engines, storage & schema design | Performance Profile | Optimized for consistent and scalable BI/analytical workloads; automatic pruning (micro-partitions), result/warehouse caching, elastic scaling; sub-second for cached queries, seconds for cold data |
| Real-time and near-real-time analytics, event/time-series data, observability (logs, metrics, traces), high-frequency dashboards | Use Cases | Enterprise data warehousing, BI/analytics, ELT/ETL, federated data lakes, ML/AI pipelines, secure data sharing & marketplace, data applications |
| High-throughput bulk ingestion (INSERT), Kafka table engine or ClickPipes for near real-time streaming, optimized for append-only workloads | Data Ingestion | COPY INTO (batch), Snowpipe (continuous, 1–5 min latency); Snowpipe Streaming (row-level, ~1 second latency); rich partner/integration ecosystem (Fivetran, dbt, Airbyte, ...more) |
| OLAP queries (aggregates/scans) typically sub-second for most workloads; latencies in low milliseconds with proper schema/indexing | Real-Time Query Latency | Generally seconds (cold data); Snowpipe Streaming adds ~1 sec for ingest, but full end-to-end latency is seconds to minutes for new data |
| Self-managed: manual sharding, ReplicatedMergeTree for HA; Cloud: stateless compute + object storage (SharedMergeTree) for massive, elastic scale and high concurrency | Scalability | True independent scaling: storage is virtually unlimited (object store); compute scales up (warehouse size) and out (multi-cluster/concurrency) |
| Self-hosted (bare metal, VM, Kubernetes, containers), clickhouse-local, chDB (embedded), or ClickHouse Cloud (BYOC or fully managed) | Deployment Options | SaaS-only; no on-premises or self-managed deployment; available in all major public clouds |
| Primitives (Int, UInt, Float, String), Array, Tuple, Map, Nested (for simple nested structures), strong JSON/Protobuf/CSV/Parquet ingest, JSON/XML parsing, but no native semi-structured column type | Data Types Supported | Structured types, plus native semi-structured (VARIANT for JSON/Avro/Parquet/XML), GEOGRAPHY (spatial), and external tables; rich UDFs (Snowpark: Python, Java, Scala) |
| SQL-like dialect (ANSI-SQL subset + extensions: arrays/lambdas, aggregate combinators); supports subqueries, joins, windows. No stored procedures; experimental multi-statement transactions | SQL Compliance | Highly ANSI-compliant SQL, full DML (UPDATE/DELETE/MERGE), CTEs, windows, semi-structured support, stored procedures, UDFs, and Snowpark for custom logic (Python, Java, Scala) |
| UPDATE/DELETE via asynchronous “mutations” (ALTER TABLE …), which rewrite data parts (I/O intensive, eventual consistency); fast for bulk, less ideal for frequent granular updates | Update/Delete Handling | Standard ACID UPDATE, DELETE, MERGE (atomic, metadata-driven); implemented via immutable micro-partitions: old data retained (for time travel), efficient pruning, high concurrency |
| Statement-level ACID for single INSERTs, snapshot isolation; multi-statement transactions are experimental and not recommended for production | Transactions | Full ACID: multi-statement transactions (BEGIN/COMMIT/ROLLBACK), snapshot isolation, system-wide consistency |
| Strong OSS ecosystem, native Kafka engine, TCP/HTTP, ODBC/JDBC, REST APIs, BI integration emerging; ClickHouse Cloud offers connectors for major tools | Ecosystem & Integration | Very mature: native Tableau/Power BI, Fivetran/dbt, Data Governance, Marketplace, Snowpark (ML/AI), native apps via Data Cloud, extensive 3rd-party integrations |
| RBAC, row/column policies, TLS for client/server/inter-node, audit logs; at-rest encryption optional in OSS, TDE and CMEK in Cloud | Security Features | Comprehensive: end-to-end encryption, SSO/SAML, PrivateLink, Dynamic Masking, Time Travel, network policies, data classification, multi-region compliance (SOC 2, HIPAA, PCI, FedRAMP) |
| RBAC, row policies, quotas/profiles in OSS; ClickHouse Cloud adds audit, usage, and workspace-level controls | Advance Governance Features | Advanced: row/column masking, object tagging, sensitive data discovery, access history, lineage, dependency tracking, integrated UI for governance (Snowsight) |
| Free OSS (infra/ops costs only). ClickHouse Cloud: usage-based (tiers: Basic/Scale/Enterprise), compute/storage/network egress billed separately | Pricing Model | Consumption-based credits: per-second warehouse/serverless billing, $/TB-month storage, edition-based feature sets; requires active cost monitoring (potential for unpredictable spend) |
Let’s dive into the core of this article—ClickHouse vs Snowflake: 7 Reasons to Choose One Over the Other.
1) ClickHouse vs Snowflake—Architectural Deep Dive
a) ClickHouse Architecture:
ClickHouse open source typically uses a shared-nothing architecture in self-managed setups, coupling compute, memory, and storage on nodes. But note that the open source version can be configured to utilize object storage like S3, enabling a separation of compute and storage. ClickHouse Cloud explicitly adopts this decoupled model, using cloud object storage for persistence, similar to Snowflake. To mitigate potential latency issues associated with object storage, ClickHouse Cloud often uses local SSDs for caching.
ClickHouse architecture commonly includes three layers:
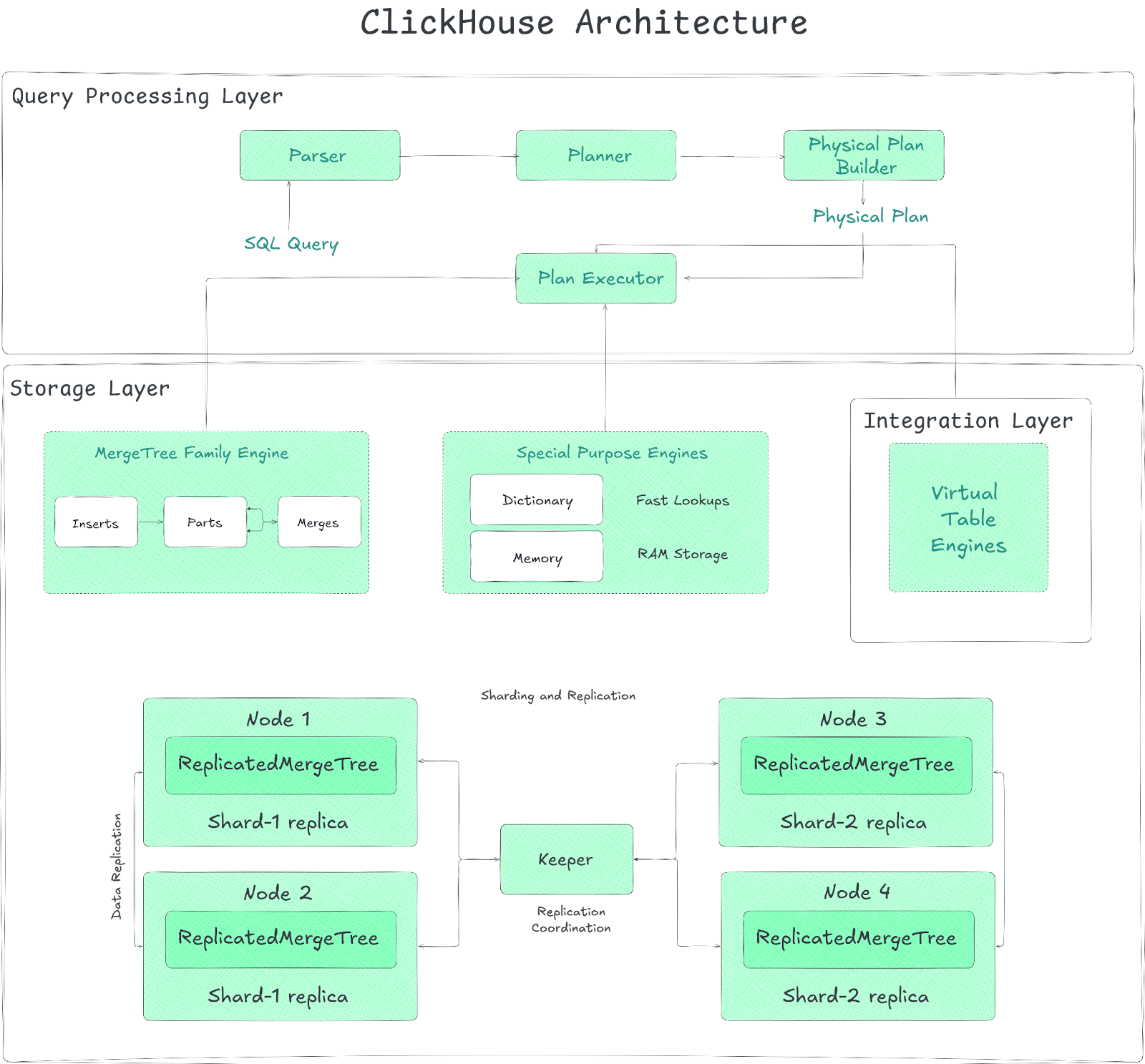
Query Processing Layer serves as the system’s computational engine, ingesting SQL statements, parsing them, and producing optimized logical and physical execution plans. Its vectorized execution engine processes data in batches (vectors) rather than row by row, dramatically boosting CPU efficiency by improving cache locality and taking advantage of SIMD instructions. Query execution leverages heavy parallelism—automatically engaging multiple CPU cores on a single node and distributing work across shards in a cluster. The layer also uses data pruning techniques, leveraging indexes (primary, skipping) and projections to minimize the amount of data read during query execution.
2) Data Storage Layer (dominated by the MergeTree engine family)
The storage layer manages data persistence and organization. Its core is the MergeTree family of storage engines, LSM-based architectures optimized for high-velocity ingestion. Incoming data is committed into immutable “parts,” each internally sorted by the table’s primary key (ORDER BY clause). ClickHouse runs background processes to merge smaller parts into larger ones, optimizing storage and query performance. Data within parts is stored in a columnar format, with each column typically residing in separate files (in Wide format) or grouped in a single file for small parts (Compact format). Data is further divided into "granules" (blocks of rows, typically 8192), which are the smallest units indexed by the sparse primary index. The storage layer also handles data compression using various codecs and manages data partitioning based on a user-defined key. Replication (asynchronous multi-master) and sharding are managed at this layer, often coordinated by ClickHouse Keeper. Storage can utilize local disks or object storage via abstraction layers (Disks, Volumes, Policies).
3) Integration Layer (for external connections)
The integration layer facilitates interaction with the outside world. It includes table engines and functions that allow ClickHouse to read from and write to external systems like other databases (MySQL, PostgreSQL), file systems (HDFS), object storage (S3, GCS), message queues (Kafka), and through standard protocols (JDBC, ODBC). It also supports various data formats for input and output. Client connections are managed via protocols like HTTP and the native TCP protocol, supported by official and third-party drivers.
Scalability and availability in distributed deployments are managed through sharding (partitioning data across nodes) and replication (creating copies of shards).
Check out the article below to learn more in-depth about ClickHouse Architecture.

b) Snowflake Architecture:
Snowflake's architecture is cloud-native with three distinct, independently scalable layers:
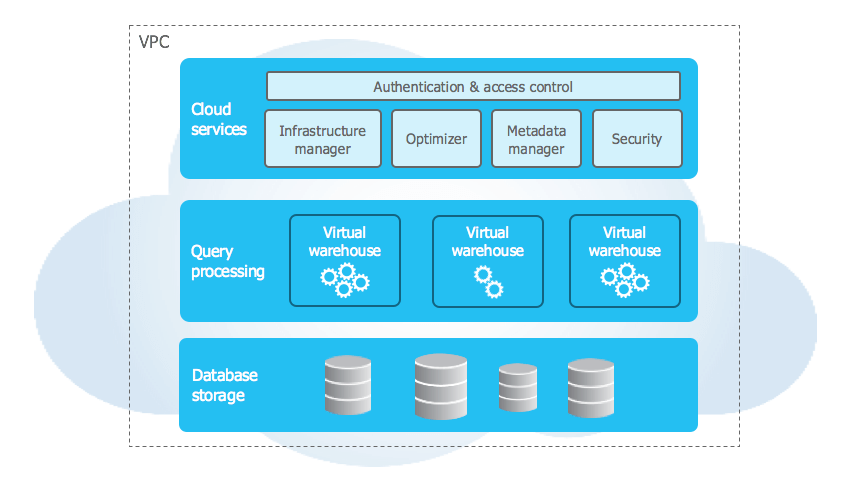
The Snowflake storage layer is the foundational layer which provides durable, scalable, and cost-effective data persistence. It leverages the underlying cloud provider's object storage (Amazon S3, Azure Blob Storage, Google Cloud Storage) as the central repository for all user data. Incoming data is automatically converted into an internal, optimized, compressed columnar format and organized into immutable micro-partitions—typically 50–500 MB before compression. Each micro-partition carries rich metadata (value ranges, distinct counts per column) that drives efficient pruning and enables Snowflake to skip irrelevant partitions during query execution. Snowflake manages all aspects of storage organization, file sizing, compression, and metadata; the underlying files are not directly accessible to users. Users can optionally define Clustering Keys to influence data layout within micro-partitions, potentially improving pruning for specific query patterns.
2) Query Processing Layer (Snowflake Compute Layer)
Query Processing Layer, aka Compute Layer, is responsible for executing SQL queries. Compute resources are provided through Virtual Warehouses, which are essentially MPP (Massively Parallel Processing) compute clusters provisioned on demand from the cloud provider. Here are some key characteristics of the Query Processing layer (Snowflake Compute Layer):
- Independence — Warehouses access shared storage but operate independently compute-wise.
- Scalability — Warehouses scale up/down instantly (X-Small to 6X-Large). Resizing typically takes seconds.
- Elastic Nature — Warehouses can auto-suspend when idle and resume quickly.
- Concurrency Scaling — Multi-cluster warehouses (Enterprise+) automatically add clusters to handle high query loads.
- Caching — Each warehouse node uses local SSD cache for data from the storage layer, speeding up repeat queries.
3) Snowflake Cloud Services Layer
Snowflake Cloud Services Layer acts as the central system or "brain" of the Snowflake platform. It's a collection of highly available, distributed services that manage and coordinate all activities across Snowflake. Its responsibilities include:
- User Management & Security — Authentication, access control (RBAC enforcement), session management.
- Query Management — Parsing, optimization (generating efficient distributed query plans), and dispatching queries to the appropriate virtual warehouse.
- Metadata Management — Maintaining the catalog of all objects (databases, tables, views, stages, etc.) and statistics about data (used for optimization and pruning).
- Transaction Management — Ensuring ACID consistency for DML operations.
- Infrastructure Management — Provisioning and managing virtual warehouses and other underlying cloud resources.
- Results Caching — Manages the global results cache. Runs on Snowflake-managed resources; credit usage typically waived unless disproportionately high.
Check out the article below to learn more in-depth about Snowflake Architecture.

🔮 ClickHouse vs Snowflake TL;DR: ClickHouse can offer latency advantages and control (especially self-hosted) by minimizing layers and optimizing its engine. Snowflake prioritizes flexibility, management ease, and independent scaling, accepting potential inter-layer network latency (mitigated by caching/pruning) for operational simplicity and workload isolation.
2) ClickHouse vs Snowflake—Performance Breakdown
ClickHouse vs Snowflake both use unique techniques to deliver fast query results, but their approaches differ significantly.
ClickHouse Performance Breakdown:
ClickHouse targets extreme query speed, especially for OLAP tasks like large aggregations, filtering, and real-time analysis. Its performance is the result of a combination of architectural choices and low-level optimizations:
➥ Columnar Storage — Minimizes disk I/O by reading only necessary columns.
➥ Vectorized Execution — Processing data in batches (vectors) instead of row-by-row dramatically improves CPU efficiency through better cache utilization and the application of SIMD instructions.
➥ Parallel Processing — Queries are automatically parallelized across available CPU cores on a single node and distributed across nodes (shards) in a cluster, maximizing hardware utilization.
➥ Data Pruning (Indexing):
- Sparse Primary Index — Quickly locates relevant granules, skips irrelevant data.
- Data Skipping Indexes — Secondary indexes (minmax, set, bloom filter) store metadata about data blocks, allowing ClickHouse to skip blocks where the data cannot possibly match the query predicates.
- Partition Pruning — If a table is partitioned (e.g: by month), ClickHouse only reads data from partitions relevant to the query's filters.
➥ MergeTree Engine — ClickHouse uses MergeTree engine, which is optimized for fast appends and efficient background merging. The sorted nature of data within parts enhances compression and index effectiveness.
➥ Efficient Compression — ClickHouse supports advanced compression algorithms like LZ4 and ZSTD which reduces data size, lowering I/O requirements and often speeding up queries, especially when I/O bound. Specialized codecs provide high compression ratios for specific data types.
➥ Materialized Views — ClickHouse also supports Materialized Views, like Snowflake. It pre-aggregates data which drastically speed up common, repetitive queries by shifting computation from query time to ingestion time.
According to the benchmark test conducted by ClickHouse, ClickHouse can outperform Snowflake, sometimes significantly (~2x faster queries), particularly in real-time analytics involving aggregations/filtering on large datasets.
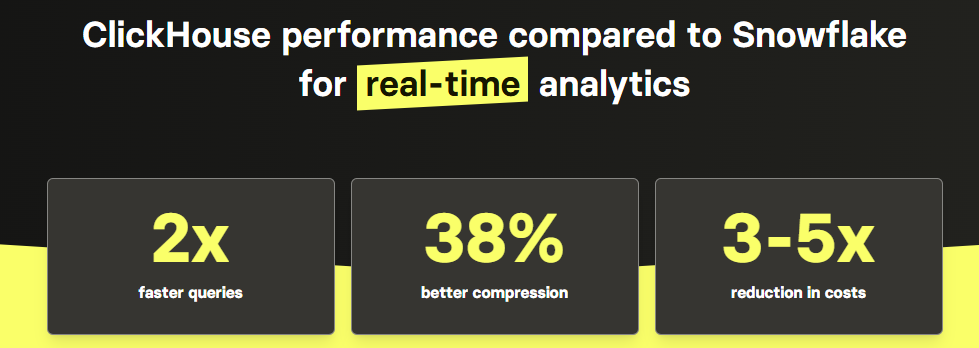
Note: Optimal ClickHouse performance often requires careful schema design and tuning. Complex JOINs are supported but might not match RDBMS performance. Frequent updates/deletes negatively impact query performance (merge overhead).
Snowflake Performance Breakdown:
Snowflake provides solid performance across a wide range of BI and data warehousing applications, with a focus on scalability and ease of management. Its performance is based on its cloud-native architecture and automatic optimization features:
➥ Separation of Storage and Compute — Snowflake allows independent scaling of compute resources (Virtual Warehouses) to match query demands without impacting storage or other workloads.
➥ Micro-partitioning and Pruning — Snowflake automatically stores data in small, columnar micro-partitions with rich metadata, which the optimizer leverages to prune (skip) irrelevant micro-partitions during query execution, reducing the amount of data scanned and improving query performance.
➥ Clustering Keys — Snowflake allows users to define clustering keys on large tables to physically co-locate related data within micro-partitions based on specified columns (like date, category)
➥ Virtual Warehouse Scaling — Snowflake's performance can be directly influenced by the size of the virtual warehouse used for querying. Larger warehouses offer more CPU, memory, and temporary storage, which typically speeds up the execution of complex queries. Scaling up the warehouse is a primary tuning mechanism for improving query performance.
➥ Caching — Snowflake utilizes multiple layers of caching:
- Results Cache — Stores the results of previously executed queries. If an identical query is submitted, the cached result is returned instantly without compute usage.
- Local Disk Cache (Warehouse Cache) — Each virtual warehouse node caches micro-partition data retrieved from the Snowflake storage layer on local SSDs. Subsequent queries needing the same data can read from this faster cache instead of remote storage. Cache size depends on the warehouse size; cache is lost when the warehouse is suspended.
➥ Automatic Query Optimization — Snowflake Cloud Services layer includes a sophisticated cost-based optimizer that generates efficient distributed query execution plans.
➥ Other Specialized Services:
- Snowflake provides the Query Acceleration Service (QAS), which helps improve the performance of large, complex queries by offloading parts of the query processing, such as scanning and filtering, to dedicated compute resources. It is only available for Enterprise+ customers.
- Snowflake offers the Search Optimization Service (SOS), designed to optimize query performance for highly selective, point-based lookups on large tables. SOS works by creating specialized search indexes, which speed up searches for specific values, which is perfect for workloads that require fast access to particular rows in extensive datasets.
- Snowflake supports Materialized Views, which store precomputed query results, such as aggregations or joins, to accelerate query performance. Materialized views automatically refresh to reflect changes in the underlying data, but do require compute resources to maintain and update the results.
Snowflake's speed can be influenced by factors such as warehouse sizing (selecting too small a size can result in slow queries or disk spillage; selecting too large raises costs unnecessarily), data clustering effectiveness, and cache state. Because of its decoupled architecture, which involves network connectivity between compute and storage, it may have higher baseline latency for certain simple, low-latency requests than a fully integrated system such as ClickHouse. Concurrency is managed per warehouse cluster (default limit 8 concurrent queries); multi-cluster warehouses (Enterprise+) scale concurrency.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

🔮 ClickHouse vs Snowflake TL;DR: ClickHouse often achieves top performance via low-level optimizations and requires schema tuning, excelling in specific high-speed analytics. Snowflake provides scalable performance across a wide range of workloads, with a primary focus on elastic compute provisioning (warehouse scaling and clustering) and the utilization of managed optimization services.
3) ClickHouse vs Snowflake—Data Ingestion & Real‑Time Analytics
Getting data in quickly and having it ready for analysis is key, especially when you need real-time information. ClickHouse and Snowflake handle this process differently, each with their own strengths and considerations for various use cases and latency requirements.
ClickHouse Data Ingestion & Real‑Time Analytics Breakdown
ClickHouse is fundamentally designed for high-volume, low-latency data ingestion and analytical query processing, making it a strong choice for real-time analytics applications
📥 ClickHouse Data Ingestion Methods
Here are a few common ingestion methods:
- ClickHouse provides Bulk Inserts. You can use INSERT INTO... SELECT or INSERT INTO... VALUES statements. For optimal performance with MergeTree tables, it is best to insert data in large batches (e.g: 10000–100000 rows or more rows at once). Performing frequent small inserts can lead to inefficiencies because of the overhead associated with creating and merging numerous small data parts in the MergeTree engine. Utilizing asynchronous inserts can help improve throughput by batching inserts on the server side.
- ClickHouse supports Streaming Ingestion via Kafka. ClickHouse offers a native Kafka table engine that functions as a Kafka consumer. It allows direct querying of Kafka topics. However, direct SELECT queries on the Kafka engine table are generally not supported. Often, users pair it with a Materialized View. The Materialized View acts as an insert trigger, automatically pulling data from the Kafka engine table as it arrives and inserting it into a persistent storage table, typically from the MergeTree family, for efficient storage and analysis.
Note: Kafka table engine isn’t supported on ClickHouse Cloud; for Cloud, use ClickPipes or Kafka Connect.
- ClickHouse Cloud offers ClickPipes (ClickHouse Pipelines), a managed ingestion service. It simplifies integrating data from various sources into ClickHouse Cloud. It supports connections to sources like Kafka, Amazon S3, Google Cloud Storage, Azure Blob Storage, and Postgres CDC (via integration with PeerDB) and more. ClickPipes manages aspects like batching data for optimal insertion into ClickHouse tables. ClickPipes manages aspects like batching data for optimal insertion into ClickHouse tables. Latency can depend on factors such as the source system, network conditions, message size, and ClickPipes' internal batching intervals (e.g: flushing data every 5 seconds or based on size thresholds). ClickPipes guarantees at-least-once delivery for reliability.
- ClickHouse supports File/Object Storage Ingestion. ClickHouse can load data from local files using standard SQL methods like INFILE. It also provides table functions (like s3, hdfs) and table engines to directly read data from various external storage systems, including HDFS, Amazon S3, Google Cloud Storage, and Azure Blob Storage. This provides flexibility for ingesting data from various storage solutions and can also be utilized by ClickPipes.
- ClickHouse provides Connectors & Integrations with a wide range of official core integrations, partner integrations, and a whole bunch of community-developed connectors.
⏱️ Real-Time Analytics Performance
ClickHouse excels in Real-Time Analytics Performance, driven by its combination of:
- Low-Latency Ingestion — Data ingested through streaming methods like the Kafka engine(with Materialized Views), ClickPipes, or efficient bulk inserts becomes queryable with minimal delay.
- Fast Query Engine — ClickHouse's analytical query engine is highly optimized. It utilizes vectorized query execution, processing data in batches ("vectors") using modern CPU instructions (like SIMD), which significantly reduces CPU cycles per row. Queries are also automatically parallelized across multiple CPU cores and nodes in a cluster, leveraging available hardware resources to achieve sub-second query response times on incoming data enabling real-time dashboards and interactive applications.
- Materialized Views — ClickHouse also supports MVs which are powerful for real-time analytics. They can perform aggregations, transformations, and calculations on data as it is being ingested and store the results in a separate target table. Due to this, pre-computation it makes complex analytical results immediately available for querying with very low latency, avoiding costly on-the-fly calculations during query execution.
⏳ Latency Considerations
Although ClickHouse is optimized for low-latency operations, end-to-end latency can vary depending on the ingestion method:
- Kafka integration latency using the Kafka engine is influenced by factors like Kafka broker performance, network conditions, ClickHouse consumer settings (such as the number of consumers and batch size), and the background merge activity of the MergeTree tables where data is landed.
- ClickPipes targets latency in the range of seconds. However, as it manages batching intervals (e.g: flushing data every 5 seconds or based on size), this can introduce slight delays. ClickPipes does not provide specific latency guarantees.
Snowflake Data Ingestion & Real‑Time Analytics Breakdown
Snowflake provides multiple data ingestion methods designed to address different latency requirements, ranging from traditional batch processing to near real-time streaming.
📥 Data Ingestion Methods
Snowflake offers several ways to get data in:
- Snowflake offers Bulk Loading via COPY INTO, which is the traditional and common method for loading large volumes of data from files staged either internally within Snowflake or externally on cloud storage like Amazon S3, Azure Blob Storage, or Google Cloud Storage. Snowflake COPY INTO command is best suited for batch processing scenarios, such as hourly or daily data loads, where latency measured in minutes or hours is acceptable. Loading performance is directly impacted by factors like file size (Snowflake recommends optimal compressed file sizes of 100–250MB) and the size of the virtual warehouse used for the loading process. Latency is primarily determined by the frequency at which these batch loading processes are executed.
- Snowflake provides Snowpipe, a serverless, continuous data ingestion service. It automates the loading of data files from staged locations as they arrive. Snowpipe is typically triggered by cloud storage event notifications (e.g: S3 Event Notifications via SQS, Azure Event Grid, GCP Pub/Sub) or through calls to its REST API. It processes data in micro-batches, making the data available for querying in the target table typically within minutes of the file being staged. Snowpipe utilizes Snowflake-managed compute resources, which are automatically scaled but billed based on consumption.
- Snowflake implements Snowpipe Streaming, an API that allows applications (such as custom Kafka consumers or other streaming applications) to write data rows directly into Snowflake tables without requiring intermediate file staging. Snowpipe Streaming offers the lowest latency among Snowflake's ingestion methods, enabling data to become available for querying within seconds or even sub-second latency. This approach is often more cost-effective than file-based Snowpipe for high-volume streaming workloads due to bypassing file staging. The Snowflake Connector for Kafka supports ingestion using the Snowpipe Streaming API (requires connector version 2.0.0 or later). The MAX_CLIENT_LAG parameter in Snowpipe Streaming can be configured (from 1 second up to 10 minutes) to control how often buffered data is flushed to Snowflake, allowing fine-tuning between latency and ingestion efficiency.
- Snowflake also supports multiple Connectors & Integrations, providing extensive ecosystem support through Partner Connect and standard drivers.
⏱️ Real-Time Analytics Performance
Snowflake supports near real-time analytics mainly via Snowpipe Streaming. While data can be ingested with low latency, the query performance for real-time dashboards might not always match ClickHouse's sub-second capabilities due to architectural differences (network latency between layers, warehouse resume times). However, Snowflake's ability to handle diverse query types and scale compute elastically makes it suitable for many less latency-critical analytical applications that require fresh data.
⏳ Latency Considerations
The ingestion method chosen significantly impacts the data availability latency in Snowflake:
- Snowflake COPY INTO method operates on a batch-driven model, and its latency is directly tied to the scheduled frequency of the batch loading jobs.
- Snowpipe (file-based) typically offers minute-level latency, with data becoming available within a few minutes of files landing in the stage. The actual delay can vary based on factors such as file size, network conditions, and the frequency of file arrivals.
- Snowpipe Streaming method provides the lowest latency, enabling data to be queryable within seconds or sub-seconds by writing data rows directly via the API. The MAX_CLIENT_LAG parameter allows controlling the flush interval and thus the latency, configurable between 1 second and 10 minutes.
Note that for bulk loading large volumes of data (e.g: 10TB/day), scheduled COPY INTO operations often provide better cost-efficiency than continuous Snowpipe, if near real-time data availability is not a strict requirement.
🔮 ClickHouse vs Snowflake TL;DR: ClickHouse and Snowflake are both solid options for real-time analytics, but the right one for you depends on your specific needs. If you need ultra-low latency, ClickHouse is the way to go. It's designed for speed, making it ideal for applications that require instant insights and super-fast query responses. Snowflake, on the other hand, is better suited for situations where data needs to be updated within a minute or so. It has tools like Snowpipe and Snowpipe Streaming for near real-time data ingestion, but may not be the best choice if you need query responses in under a second.
4) ClickHouse vs Snowflake—Deployment Options
The ways in which ClickHouse vs Snowflake can be deployed and managed differ fundamentally, presenting distinct choices for organizations evaluating ClickHouse vs Snowflake.
ClickHouse Deployment Option
➥ Open Source (Self-Managed)
ClickHouse core is fully open source and available under the permissive Apache 2.0 license, allowing users to download and install the software on their own.
You can deploy ClickHouse core on bare metal servers, virtual machines (in private data centers or public clouds like AWS, GCP, Azure), or within containers (Docker, Kubernetes).
With ClickHouse OSS core, users are responsible for handling all infrastructure provisioning, installation, configuration (via XML files or SQL), scaling (manual setup of sharding and replication with ClickHouse Keeper), monitoring, upgrades, backups, and security tasks.
ClickHouse OSS core provides maximum control over the environment and configuration. The main costs are related to the underlying infrastructure (compute, storage, network) and the engineering effort required for management, but it can be highly cost-effective with efficient management.
➥ ClickHouse Cloud (Managed Service)
ClickHouse Cloud is an official SaaS offering from ClickHouse, Inc..
ClickHouse Cloud runs on AWS, Azure, and GCP infrastructure—all managed by ClickHouse.
ClickHouse Cloud is a fully managed service that handles deployment, scaling (with some auto-scaling options), high availability, backups, upgrades, and security patching. Data is stored separately from compute using object storage.
ClickHouse Cloud provides features like a web-based SQL Console, Query Insights, managed ingestion (ClickPipes), and integrated support. It's offered in three tiers - Basic, Scale, Enterprise - each with its own set of capabilities, SLAs, and pricing.
ClickHouse Cloud offers a "Bring Your Own Cloud" model—you can run the managed service right in your own cloud account. This setup helps with meeting data residency and security requirements.
➥ clickhouse-local
clickhouse-local is a command-line tool packaged as a single binary that includes the full ClickHouse engine. It allows running SQL queries on local files or remote data sources without needing a running ClickHouse server instance. It is extremely useful for local data analysis, scripting, and simple ETL tasks.
➥ chDB (Embedded)
chDB is an embedded version of the ClickHouse engine available as a library for languages like Python, Go, Rust, and Node.js. It allows applications to leverage ClickHouse's analytical capabilities directly within their own process without external database dependencies.
Snowflake Deployment Option
Snowflake offers a single, consistent deployment model across multiple cloud platforms.
➥ Fully Managed SaaS
Snowflake is exclusively available as a cloud-based Software-as-a-Service. There is no option for on-premises or self-hosted deployment. Snowflake manages all underlying infrastructure, software, maintenance, and upgrades.
➥ Multi-Cloud Availability
Snowflake accounts can be hosted on any of the three major public cloud providers: Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP). Customers choose the cloud provider and specific region during account setup. An organization can have multiple Snowflake accounts, potentially hosted on different clouds or regions.
➥ Global Regions
Snowflake is available in numerous geographic regions across North America, Europe, Asia Pacific, and other areas on each supported cloud platform. Specialized government cloud regions (e.g: AWS GovCloud, Azure Government) are also available for specific compliance needs (FedRAMP, ITAR, DoD IL).
➥ Editions
Snowflake offers different service editions that provide varying levels of features, performance capabilities, security, and support, which affect the cost per credit.
- Standard — This edition offers basic features and 1-day Time Travel.
- Enterprise — This edition adds multi-cluster warehouses, extended Time Travel, data masking and row policies, materialized views, and search optimization.
- Business Critical — This edition adds enhanced security features, including Tri-Secret Secure and Private Link, as well as compliance with HIPAA and PCI, and database failover and failback.
- Virtual Private Snowflake (VPS) — VPS provides the highest level of isolation in a dedicated Snowflake environment, offering the most advanced features.
🔮 ClickHouse vs Snowflake TL;DR: ClickHouse gives users options and control, letting them choose a deployment model that suits their needs—from handling everything themselves with open source to a managed cloud service. Due to this, users can pick the one that fits their skills, budget, and how much control they want. Snowflake, on the other hand, focuses on simplicity and ease of use with its fully managed SaaS model. It makes scaling and using it across major cloud platforms a breeze, but it also means users have less flexibility in how it's set up and less direct control over the underlying systems.
5) ClickHouse vs Snowflake—Ecosystem & Integration
For a database, being able to work seamlessly with other tools and systems is a huge plus. ClickHouse vs Snowflake have both developed their own ecosystems—each with its own priorities.
ClickHouse Ecosystem & Integration
ClickHouse's open source nature and performance focus have helped it build a strong foundation in three main areas. It's got great developer tools, solid data ingestion pipelines—especially for streaming data. And a lot of community-driven integrations.
➥ Language Clients & Drivers
ClickHouse provides official clients for C++, Go, Java (JDBC), Python, JavaScript, and Rust. There are also official HTTP and native protocols. The ecosystem includes high-quality third-party clients for PHP, Node.js, Ruby, R, Elixir and others. Both ODBC and JDBC drivers are available for broad compatibility with analytics and ETL tools.
➥ SQL Clients & IDEs
ClickHouse ships with a native CLI (clickhouse-client) and supports connections from widely used database IDEs such as DBeaver, DataGrip, and DbVisualizer via JDBC/ODBC. ClickHouse Cloud offers a web-based SQL editor for query development and management.
➥ BI & Visualization Tools
ClickHouse integrates with leading BI tools, including:
- Grafana (native plugin)
- Tableau (via ODBC/JDBC)
- Apache Superset, Metabase, Redash (native/SQL)
- Power BI (using ODBC/JDBC and third-party connectors)
- Looker Studio (via MySQL compatibility mode and community drivers)
While integration is strong, some advanced BI features may require additional configuration compared to enterprise-oriented warehouses.
➥ Data Ingestion & ETL
ClickHouse excels at ingesting high-velocity data, with native support for:
- Kafka (via Kafka table engine)
- RabbitMQ, NATS (third-party/community integrations)
- Object storage: S3, GCS, Azure Blob (for external tables, table functions, and backup/restore)
- HDFS (table functions)
- Relational databases: MySQL, PostgreSQL, MongoDB (table engines, external dictionaries, CDC tools)
- ETL/ELT tools: Airbyte, Fivetran, dbt, Talend, Spark, Flink, Vector, and Fluent Bit.
Recent releases add support for semi-structured formats (Parquet, ORC, JSONEachRow), and ClickHouse’s open format simplifies bulk and streaming ingestion.
➥ Infrastructure & Orchestration
ClickHouse supports container orchestration via Helm charts and Kubernetes operators (notably Altinity ClickHouse Operator). There are also Ansible and Puppet modules for configuration management, and Docker images for rapid deployment.
➥ Monitoring & Observability
ClickHouse integrates with:
- Prometheus (native export and exporters)
- Grafana (monitoring dashboards)
- Zabbix, Sematext (community integrations)
- It is also used as a backend for log and trace analytics (e.g: via Loki, Jaeger, Tempo).
➥ Data Lake & Modern Workloads
ClickHouse supports open data lake formats such as Apache Iceberg (native, experimental), Delta Lake, and Hudi (via external table engines or connectors). It is expanding support for vector search (via Vector Search engine) and GeoIP/spatial queries.
➥ Community & Extensibility
ClickHouse also has a vibrant open source community drives rapid plugin and integration development. Commercial ecosystem is also maturing, with managed ClickHouse cloud offerings, enterprise support, and growing partnerships.
Snowflake Ecosystem & Integration
Snowflake delivers a comprehensive, cloud-native analytics platform with a strong focus on enterprise-grade integrations, seamless scaling, and unique data sharing capabilities.
➥ Language Clients & Drivers
Snowflake offers official connectors for:
- Python (snowflake-connector-python)
- Java (JDBC)
- Go, Node.js, .NET, C/C++, PHP, Ruby
- ODBC (broad compatibility)
- Spark (native connector)
- Snowflake SQL API (RESTful access)
➥ SQL Clients & IDEs
Snowflake provides a web-based UI called Snowsight and a command-line client called SnowSQL. It also integrates seamlessly with popular SQL IDEs like DataGrip, DBeaver, DbVisualizer, SQL Workbench/J, and more (via JDBC/ODBC).
➥ BI & Visualization Tools
Snowflake’s integrations are mature, with certified/native connectors for:
- Tableau (certified connector)
- Power BI (certified connector)
- Looker (native support)
- Looker, Qlik, MicroStrategy, Sigma Computing, ThoughtSpot, Domo and more (native or partner-certified)
➥ Data Ingestion & ETL/ELT
Snowflake offers native capabilities like COPY INTO, Snowpipe, and Snowpipe Streaming, as well as extensive partnerships with major ETL/ELT vendors like Fivetran, dbt Labs, Informatica, Talend, Matillion, Airbyte, Stitch, and so much more. These partnerships are often facilitated through Partner Connect for easy setup. Also, Snowflake integrates with cloud provider services like AWS Glue and Azure Data Factory, and provides Kafka and Spark connectors.
➥ Data Science & Machine Learning
Snowflake's Snowpark offers APIs for data processing and ML model development and deployment using Python, Java, and Scala directly within Snowflake's engine. It also integrates with external ML platforms like Amazon SageMaker, DataRobot, Dataiku, and H2O.ai. Snowflake Cortex provides built-in LLM (Large Language Model) and ML functions, and Snowpark Container Services enable running arbitrary containerized applications, such as ML models, within Snowflake.
➥ Data Governance & Security
Snowflake integrates with leading data catalog, governance, and security platforms:
- Collibra, Alation (data catalog)
- Immuta, BigID (data governance)
- Okta, SailPoint (identity management, SSO, SCIM)
- Audit, masking, and data classification are built-in.
➥ Data Marketplace & Sharing
- Snowflake Marketplace — Discover, access, and purchase third-party datasets, data services, and native apps.
- Secure Data Sharing — Enables live, secure sharing of data between Snowflake accounts and organizations without data movement or duplication.
- Snowflake Native Apps Framework — Enables partners/customers to build, distribute, and monetize applications that run securely inside Snowflake.
➥ API & Extensibility
Snowflake provides a SQL API (REST) for programmatic access. External Functions allow calling code hosted on cloud functions like AWS Lambda, Azure Functions, and GCP Cloud Functions. The Snowflake Native Application Framework enables partners and customers to build and distribute applications that run directly within Snowflake.
🔮 ClickHouse vs Snowflake TL;DR: Snowflake ecosystem is mature and focused on enterprise needs. It excels in integrating BI tools, forming ETL partnerships, and offering unique data sharing and marketplace features. ClickHouse benefits from a strong open-source community. It provides powerful tools for developers and integrates well with streaming data sources like Kafka. Its commercial partner ecosystem is also growing quickly. So the final choice between them depends on what you, as a user, value more: enterprise integrations and data sharing with Snowflake or the flexibility and open source tools of ClickHouse.
6) ClickHouse vs Snowflake—Security & Governance
Security and governance are critical for any data platform handling sensitive data. ClickHouse and Snowflake both address these needs, but differ significantly in depth, automation, and enterprise-readiness of their features.
ClickHouse Security & Governance:
ClickHouse offers a robust security model, but its feature set is more foundational in self-managed environments, with advanced capabilities (especially for compliance) delivered primarily through ClickHouse Cloud.
➥ Authentication
- Self-managed ClickHouse supports username/password authentication, with passwords hashed using SHA-256. You may also configure external authenticators like LDAP, Kerberos, or OAuth/JWT (JWT support is via HTTP interface or through custom authenticators).
- ClickHouse Cloud adds SSO, including SAML 2.0 and OIDC, with support for enterprise identity providers (IdPs).
- Host/IP address restrictions and login time limits are supported, including the VALID UNTIL clause for user expiration.
➥ Authorization (RBAC)
- Role-Based Access Control is SQL-driven.
- Privileges can be granted/revoked at the column, table, database, or global level.
- Supported privilege hierarchy includes SELECT, INSERT, ALTER, CREATE, DROP, SHOW, and many more—including fine-grained grants such as SELECT(column) or INSERT(column).
- Roles can be nested; WITH GRANT OPTION supports privilege delegation.
- RBAC is object-based (tables, columns, views, dictionaries, functions, etc.) and does not rely solely on file or process-level permissions.
➥ Row-Level Security
- Row Policies (docs) allow for dynamic, user-specific row filtering during query execution.
- Row policies can be permissive (OR) or restrictive (AND), and can be combined for complex access patterns.
- Policies are attached to users or roles, and are enforced at query runtime without query rewrites.
➥ Encryption:
- In Transit — ClickHouse supports full TLS/SSL encryption for client-server and inter-node communication. Mutual TLS (mTLS) is supported for strong client identity.
- At Rest:
- Self-managed — Relies on OS-level encryption (e.g: LUKS, dm-crypt) or storage provider encryption. Native column-level encryption is available via encryption functions, but not transparent at-rest encryption of data files.
- ClickHouse Cloud — Provides default AES-256 encryption at rest. Customer-Managed Keys (CMEK) are supported in enterprise environments.
➥ Auditing
- All queries, including errors, performance metrics, and affected users, are logged to system tables (system.query_log, system.query_thread_log, etc.).
- Audit logs can be exported to external SIEM or log management tools.
- ClickHouse Cloud offers enhanced audit logging, including access and administrative actions.
➥ Data Masking
ClickHouse does not have a built-in dynamic data masking feature. Instead, you can implement masking manually using using views, UDFs, or SQL functions (e.g: string manipulation or encryption functions). There is no policy-driven masking tied to roles/users as in Snowflake.
➥ Resource Governance
- Resource usage can be controlled via quotas, limiting queries per user/role, memory, query duration, and result rows.
- Settings Profiles allow grouping and assigning resource policies to users or roles for fine-grained control.
➥ Compliance (Cloud)
- ClickHouse Cloud is SOC 2 Type II and ISO 27001 certified.
- HIPAA and PCI DSS support is available on the Enterprise tier, but requires a BAA and may entail extra configuration.
- Self-managed ClickHouse has no built-in compliance certifications; it is up to the operator to configure and document controls.
Snowflake Security & Governance
Snowflake delivers a comprehensive, enterprise-grade security and governance platform, with many advanced features only available in upper-tier editions (Enterprise+, Business Critical+).
➥ Authentication
- Supports username/password, Multi-Factor Authentication (MFA), and federated authentication (SAML 2.0, OIDC) with leading IdPs (Okta, Azure AD, Google Workspace, etc.).
- OAuth 2.0 supported for applications.
- SSO is natively integrated and widely used in enterprise deployments.
➥ Authorization (RBAC)
- Hierarchical RBAC — Privileges are granted to roles, which are assigned to users or other roles, supporting inheritance and separation of duties.
- System roles — ACCOUNTADMIN, SECURITYADMIN, SYSADMIN, PUBLIC, etc., enforce administrative boundaries.
- Granular object-level privileges — Warehouses, databases, schemas, tables, routines, etc., with explicit privilege controls (SELECT, INSERT, MODIFY, USAGE, OPERATE, MONITOR, etc.).
➥ Network Security
- Network Policies restrict access by IP address or range.
- Private connectivity: AWS PrivateLink, Azure Private Link, GCP Private Service Connect (Business Critical+).
- Always-on TLS: All client, inter-service, and inter-node communication is TLS-encrypted.
➥ Encryption
- In Transit — All communication is automatically encrypted using Universal TLS 1.2+.
- At Rest — All customer data is encrypted with AES-256 as standard; managed by Snowflake’s own KMS, with regular key rotation.
- Tri-Secret Secure — Customers in Business Critical+ can provide their own key (BYOK/CMEK) for dual control with Snowflake KMS.
➥ Fine-Grained Access Control & Governance
- Column-Level Security — Dynamic Data Masking masks column values on SELECT, based on user/role/policy.
- Row-Level Security — Row Access Policies dynamically filter rows at query time.
- Object Tagging — Snowflake allows applying tags to objects (tables, columns, warehouses, etc.) for classification, tracking sensitive data, and cost allocation (Enterprise+).
- Data Classification — Automated classification detects and categorizes sensitive data types (PII, PCI, etc.).
- External Tokenization — Integrates with third-party tokenization providers (Enterprise+).
➥ Data Protection
- Time Travel provides access to historical data versions (up to 90 days) for recovery or analysis.
- Fail-safe offers a 7-day non-configurable recovery period for disaster recovery beyond Time Travel.
➥ Auditing
- Snowflake provides comprehensive logging of user activity, logins, DDL/DML, privilege changes, and data access history.
- Account Usage, Information Schema, and Access History (Enterprise+) provide detailed, queryable audit logs.
This is accessible via system views (QUERY_HISTORY, LOGIN_HISTORY, ACCESS_HISTORY [Enterprise+]) and Information Schema functions.
➥ Compliance
Snowflake holds a wide range of industry and government compliance certifications, including SOC 1/2 Type II, PCI DSS, HIPAA, HITRUST, ISO 27001 series, FedRAMP (Moderate, High), DoD IL4/IL5, StateRAMP, GDPR, CCPA, and more.
🔮 ClickHouse vs Snowflake TL;DR:
Snowflake offers a deeply integrated, feature-rich security and governance platform with advanced controls for large, regulated enterprises. ClickHouse provides strong core security (RBAC, encryption, row-level security), especially in Cloud, but some advanced controls (dynamic masking, integrated classification, automated audit export, compliance) may require additional engineering or only exist in the managed Cloud offering.
For highly regulated environments or those requiring automated controls and auditability, Snowflake leads. For speed, flexibility, and open-source extensibility, ClickHouse (especially Cloud) may be sufficient, but requires more manual configuration for full parity.
7) ClickHouse vs Snowflake—Pricing Breakdown
Now that we've covered most of the article, let's talk about what really sets ClickHouse and Snowflake apart: their pricing models and cost structures, a major consideration when choosing between ClickHouse vs Snowflake.
ClickHouse Pricing Breakdown:
ClickHouse offers a free open source version and a managed ClickHouse Cloud. The self-hosted edition has no software license cost – you just pay for the servers (cloud or on-prem), storage and maintenance. On the other hand, ClickHouse Cloud bills for compute, storage, network and optional services. Cloud users choose from three tiers (Basic, Scale, Enterprise) with usage-based pricing. We’ll deep dive into each tier’s costs and features, plus extra charges (storage, backups, data transfer, support) and how prices vary by region.
1) Self-Hosted (Open Source) Costs
- Licensing — ClickHouse is open source under the Apache 2.0 license—no software cost.
- You pay for — Underlying infrastructure (on-prem or cloud VMs), storage, network, and your own operational/maintenance overhead.
- Features — No managed features (e.g., auto-scaling, managed HA, automated upgrades/backups). You are responsible for monitoring, scaling, data replication, backup, upgrades, and security.
- Typical deployments — Kubernetes, Docker, or VM clusters. No per-core or per-node fee.
- Total cost — Determined by infrastructure provider, scale, and support (if you purchase commercial support from a vendor).
2) ClickHouse Cloud Plans
ClickHouse Cloud offers three managed plans: Basic, Scale, and Enterprise. All plans are usage-based, and prices vary by region/cloud.
- Basic Tier — The Basic plan is for development, testing or small projects. It includes up to ~1 TB of compressed data storage (typically 500 GB data + 500 GB daily backup) and a single replica with 8–12 GB RAM and 2 vCPUs. Built-in daily backups (retained 1 day) are included. Basic runs in 1 availability zone and offers standard “expert” support with a 1-business-day response time.
Pricing starts at about $66.52 per month under a typical light-use scenario. For e.g: with one replica (8 GB RAM, 2 vCPU) active ~6 hours/day and 500 GB of data, the bill is $66.52 (compute ~$39.91, storage $25.30, ~10 GB egress $1.15, ~5 GB cross-region $0.16). Run 24/7 the same setup would be ~$186/mo. A Basic cluster includes 10 GB/month of free public egress and 5 GB cross-region egress; beyond that network use is charged (see Data Transfer below). In short: Basic gives you a small fixed-size cluster with daily backups and basic support, for roughly $70–200/mo depending on usage.
- Scale Tier — The Scale plan is for production workloads that need reliability and autoscaling. Scale runs 24/7 with at least two replicas (for fault tolerance) and supports manual/automatic scaling of resources. Features in this tier include unlimited storage, configurable compute size, separation of compute and storage tiers, configurable backups, private networking, and 2+ availability zones. Support is faster (1-hour response for Severity 1 issues, 24×7).
Pricing starts at about $499.38 per month. Say for instance, a Scale service with two 8 GB RAM replicas (2 vCPU each) and ~1 TB data (plus backup) costs $499.38 under 100% active load. The breakdown was compute $436.95, storage $50.60 (1 TB+backup), plus ~$11.52 egress and $0.31 cross-region. In practice, Scale costs grow with data size and replication.
- 2×8 GB replicas, 1 TB data (+1 backup) = ~$499.38/mo.
- 3×16 GB replicas, 3 TB data (+backup) = ~$1,474.47/mo.
Scale is best for workloads requiring high uptime and auto-scaling.
- Enterprise Tier — Enterprise is for very large, mission-critical deployments with strict compliance. It includes everything in Scale plus enterprise features: SAML SSO, private (dedicated) regions, custom hardware profiles (high-CPU or high-memory node types), manual vertical scaling of custom profiles, the ability to export backups to your own cloud, and advanced security (transparent encryption, CMEK, HIPAA compliance). Its support is top-tier (30-minute response for Severity 1, named lead engineer, scheduled upgrades, consultative migration guides).
Pricing for Enterprise is customized (you get a quote) and varies with size.
Now, beyond the base plan, ClickHouse Cloud bills separately for actual usage.
Storage — You pay per GB-month of stored data. Storage is measured on the compressed size in ClickHouse tables. Backups count toward storage, so if you have one daily backup, that doubles the stored data (e.g: 5 TB data + 1 day backup = 10 TB storage usage). From the examples, storage runs roughly $25.30 per TB-month for 500 GB data+500 GB backup, i.e. about $50–52 per TB-month of primary data. (Rates vary slightly by region and cloud provider.) All plans bill the same storage rate.
Backups — Daily backups are included by default (one snapshot retained for 1 day). You can enable additional backups or longer retention, but each extra snapshot increases your storage usage (and cost). The software count includes backups at the same per-GB rate.
Data Transfer — Traffic leaving the ClickHouse cluster is charged by the GB. There are two categories: public internet egress and inter-region (cross-region) egress. Intra-region transfer (within the same region) is free. Public egress starts around $0.1152 per GB in major regions (e.g: AWS US/EU). Cross-region egress is lower. Azure has a similar scheme. (Exact rates depend on provider and regions; see official ClickHouse pricing for more)
ClickPipes — If you use ClickHouse’s managed ingestion service (ClickPipes), it has its own rates: $0.04 per GB of data ingested, and $0.20 per compute-hour per ClickPipes replica. (ClickPipes is optional and billed separately.)
Support/Services — Each plan includes a support level as noted above. Additional consulting, custom SLAs or training would be extra but are typically negotiated in Enterprise contracts. Note that ClickHouse Cloud supports flexible billing: you can pay monthly by credit card, commit to prepaid annual credits, or even buy through AWS/GCP/Azure marketplaces (PAYG or reserved).
Regional Pricing Differences
ClickHouse Cloud pricing varies by region and cloud provider. Compute-unit and storage rates depend on the underlying infrastructure cost. For instance, AWS and Azure US/EU regions generally have base rates, while Asia regions often cost ~20–30% more. Storage and compute unit prices are higher in premium regions (e.g: Singapore, Tokyo). Network egress also changes by region.
In short, AWS US/EU regions typically offer the lowest base rates (both for compute and egress). Asia and APAC regions are higher. GCP/Azure have their own tiers.
See the Official ClickHouse Cloud pricing.
Snowflake Pricing Breakdown:
Snowflake offers four editions with increasing features and costs:
- Standard
- Enterprise
- Business Critical
- Virtual Private Snowflake (VPS)
Each edition has a different per-credit price. For example (in AWS US East) a credit costs roughly ~$2.00 for Standard, ~$3.00 for Enterprise, and ~$4.00 for Business Critical; VPS pricing is custom (you need to contact Snowflake). Features scale accordingly (e.g: Enterprise adds multi-cluster warehouses, Business Critical adds HIPAA-grade security, VPS is a fully isolated deployment).
Here is the table that summarizes the list prices per credit (USD) in a representative region (AWS US) for each edition:
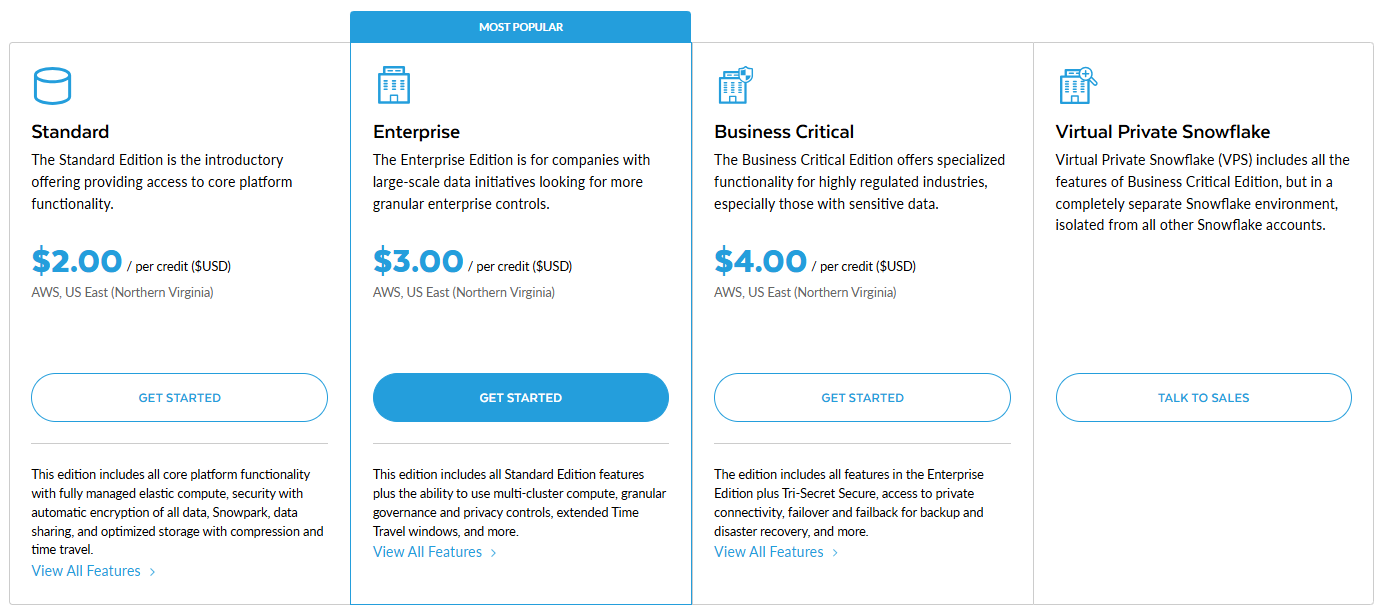
Note: Actual prices vary by cloud region and purchasing model. The per-credit rates above (Standard $2.00, etc.) refer to a typical AWS US region on an on-demand account. Users can pre-purchase credits (capacity contracts) at discounted rates. Prices on Azure or GCP are similar in structure but may be modestly higher due to underlying cloud costs.
Compute (Virtual Warehouse) Pricing
Compute usage is measured in Snowflake credits. Virtual warehouses consume credits only while running (paused/idle time is free). Billing is per-second with a 60-second minimum charge each time a warehouse starts. The number of credits consumed depends on warehouse size. Smaller warehouses consume fewer credits per hour; each larger size typically doubles the credits/hour.
Here is the table that summarizes typical credit rates for each warehouse size (Standard edition) and the higher-cost Snowpark-optimized warehouses (which offer more memory):
| Warehouse Size | Credits per Hour (Standard) | Credits per Hour (Snowpark-optimized) |
| X-Small | 1 | N/A |
| Small | 2 | N/A |
| Medium | 4 | 6 |
| Large | 8 | 12 |
| X-Large | 16 | 24 |
| 2X-Large | 32 | 48 |
| 3X-Large | 64 | 96 |
| 4X-Large | 128 | 192 |
| 5X-Large | 256 | 384 |
| 6X-Large | 512 | 768 |
Credit pricing example: Running a Small warehouse (2 credits/hour) for 10 hours uses 20 credits. At $2/credit (Standard, AWS US), this costs $40. Snowpark-optimized warehouses cost ~50% more credits for large sizes (see table).
Check out this article to learn more in-depth on Snowflake's compute costs and how they are calculated.
Storage Pricing
Snowflake charges storage by the average compressed data stored per month (flat $/TB). The exact $/TB rate depends on your purchase model and region. For AWS US regions, typical rates are:
- On-demand (no contract): ~$40 per TB-month in US East (N. Virginia).
- Pre-purchased (Capacity contract): ~$23 per TB-month in the same region.
Other regions/clouds vary. For example, AWS Canada (Central) on-demand is ~$46/TB. Using a capacity contract (1–3yr commitment) can cut the price substantially.
Check out this article to learn more in-depth on Snowflake's storage costs and how they are calculated.
Serverless and Add-On Features
Snowflake charges credits for many serverless features. The following table summarizes the compute credits per hour for each Serverless feature:
| Feature | Snowflake-managed compute | Cloud Services |
| Clustered Tables | 2 | 1 |
| Copy Files | 2 | N/A |
| Data Quality Monitoring | 2 | 1 |
| Hybrid Tables Requests | 1 | 1 |
| Logging | 1.25 | N/A |
| Materialized Views maintenance | 10 | 5 |
| Materialized Views maintenance in secondary databases | 2 | 1 |
| Query Acceleration | 1 | N/A |
| Replication | 2 | 0.35 |
| Search Optimization Service | 10 | 5 |
| Search Optimization Service in secondary databases | 2 | 1 |
| Serverless Alerts | 1.2 | 1 |
| Serverless Tasks | 1.2 | 1 |
| Snowpipe | 1.25 | 0.06/1k files |
| Snowpipe Streaming | 1 | 0.01/hr/inst |
Full details: Official serverless pricing.
4) Snowpark Container Services Cost
Snowflake has introduced Snowpark Container Services, a fully managed container offering that allows running containerized workloads directly within the Snowflake ecosystem.
SPCS (Snowpark Container Services) utilizes Compute Pools, which are distinct from virtual warehouses. SPCS is billed per compute pool node-hour:
| Compute Node Types | XS | S | M | L |
| CPU | 0.11 | 0.22 | 0.43 | 1.65 |
| High-Memory CPU | N/A | 0.56 | 2.22 | 8.88 |
| GPU | N/A | 1.14 | 5.36 | 28.24 |
(All values in credits per hour)
5) Snowflake Cloud Services Cost
Snowflake's cloud services layer is not billed separately unless usage exceeds a threshold. Specifically, if cloud services usage stays within 10% of daily virtual warehouse compute usage, it’s free. If it exceeds 10%, the excess is charged. Most users don’t see extra charges, as typical usage stays under this threshold.
6) Snowflake Data Transfer Cost
- Ingress (into Snowflake) is Free.
- Egress (out of Snowflake):
- Same cloud & region is Free.
- Cross-region/cross-cloud is billed per GB/TB, at cloud provider’s current rates.
- Rates may vary by provider/region.
Check out this article to learn more in-depth on Snowflake's data transfer costs and how they are calculated.
7) Snowflake AI Services Cost
Snowflake's AI features, such as Cortex LLM Functions, leverage Snowflake-managed compute resources, referred to as "Snowflake AI Features". The pricing for these AI features is dependent on tokens, which represent the smallest unit of text processed by the underlying Cortex model.
Token costs vary based on the specific Cortex model used, and the total number of tokens processed includes both input and output tokens. It is important to consider the conversion rate of raw input and output text into tokens when evaluating the cost of Snowflake's AI features for your data management needs.
Check out this article to learn more in-depth on Snowflake AI Services Cost.
🔮 ClickHouse vs Snowflake TL;DR:
- ClickHouse: True open core—no “community/enterprise” split. Managed service is single-vendor (ClickHouse Inc.), not resold by major clouds. All cloud prices are by usage, no minimums, and storage is always billed on compressed size—including backups. Backups and storage are not “free” at any tier.
- Snowflake: Credits are the universal unit for all compute, serverless features, and some platform services. Storage is highly compressed; $/TB/mo is for compressed size, not raw. Compute only billed when running; auto-pause/auto-resume is standard. Data transfer out is generally free within the same region/provider, but expensive cross-cloud/region. Cloud services (metadata, auth, API, ...) are mostly free unless you exceed 10% of daily compute usage.
ClickHouse vs Snowflake—Use Cases
Now lets deep dive into use case of ClickHouse vs Snowflake:
What is ClickHouse used for?
ClickHouse is perfect for situations where you need to quickly ingest data and get answers fast, especially when dealing with huge amounts of machine-generated or event data. Some top use cases are:
1) Real-Time Analytics and Dashboards — ClickHouse excels at ultra-fast, low-latency analytics, powering interactive dashboards and user-facing applications where fresh data and instant insights are highly critical.
2) Observability (Logs, Metrics, Traces) — ClickHouse handles massive scale ingestion and querying of log/event data, metrics, and distributed traces. It is used by companies like Cloudflare, Uber and more for real-time observability and security analytics.
3) Web Analytics and Clickstream Analysis — ClickHouse can be used to examine user behavior on websites and applications by processing large streams of click events, page views, and user interactions, providing insights into user journeys and personalized experiences. This was ClickHouse's original use case at Yandex.Metrica.
4) Time-Series Data Analysis — ClickHouse efficiently stores and queries high-cardinality, time-stamped data (IoT, financial tick data, infrastructure monitoring, telemetry), thanks to its MergeTree engine and advanced indexing.
5) Advertising Technology (AdTech) — ClickHouse supports campaign analytics, impression/click/event stream processing, and real-time bidding analysis at very high throughput and low latency.
6) Security Analytics and Fraud Detection — ClickHouse enables real-time detection of anomalies, threats, and fraud by analyzing event streams and logs at scale, supporting both batch and streaming ingestion
… and so much more!
What is Snowflake used for?
Snowflake's flexible architecture, ease of use, and broad ecosystem make it suitable for a wider range of enterprise data initiatives. Here are some key use cases:
1) Enterprise Data Warehousing — Snowflake acts as a central repository for structured and semi-structured data. It scales storage and compute independently to power enterprise reporting and analytics.
2) Business Intelligence and Reporting — Snowflake integrates with BI tools (Tableau, Power BI, Looker), enabling fast, concurrent dashboarding, ad-hoc queries, and enterprise-scale reporting.
3) Data Lakes — Snowflake natively ingests and queries raw, semi-structured, and even some unstructured data; external tables, Snowpark, and Iceberg support broaden data lake capabilities.4) Data Engineering (ETL/ELT) — Snowflake supports robust transformation pipelines with SQL, Snowpark (Python, Scala, Java), dbt, and orchestration tools (Airflow, Dagster), including UDFs and stored procedures.5) Secure Data Sharing and Collaboration — Snowflake Data Sharing allows real-time, zero-copy sharing of live datasets across accounts or organizations, with advanced privacy features (e.g., Data Clean Rooms).
6) Data Science and Machine Learning — Snowpark lets you prepare data and train models inside Snowflake. Cortex AI offers LLMs, retrieval-augmented generation, and text-to-SQL for generative AI workflows.7) Developing Data Applications — The Native App Framework and connectors let you build and deploy apps directly on Snowflake. Streamlit support and REST APIs connect your code to live data with no extra layers.
8) Cybersecurity Analytics — Snowflake powers security data lakes for log storage and threat hunting. It supports real-time analytics and integrates with security platforms for unified visibility.
ClickHouse is purpose-built for real-time, high-throughput analytics on event/time-series data. Snowflake is a generalist, cloud-native data platform for end-to-end enterprise analytics, data engineering, and sharing.
ClickHouse vs Snowflake—Pros & Cons
Here are the main ClickHouse pros and cons:
ClickHouse Pros and Cons
ClickHouse Pros:
- Ultra-fast OLAP (Online Analytical Processing) performance. Highly optimized for analytical queries (vectorized execution, columnar storage, compression, secondary indexes, skip indexes).
- ClickHouse is available as open source; can be self-hosted on-prem, in any cloud, or as a managed ClickHouse Cloud service (multi-cloud, Kubernetes support).
- Supports high-throughput streaming ingest (Kafka, RabbitMQ, S3), materialized views for near real-time analytics.
- Supports ANSI SQL with robust window functions, arrays, maps, and advanced analytical features.
- ClickHouse provides powerful engines (MergeTree & Table Engines) for partitioning, replication, high availability, and data retention policies.
ClickHouse Limitations:
- Lacks full ACID transactions; supports atomic inserts, but multi-statement transactions are experimental and not recommended for critical workloads.
- Mutable operations (UPDATE, DELETE) are executed as background mutations, which can be slow and resource-intensive compared to row-oriented DBMS or Snowflake.
- Requires significant expertise for tuning, scaling, and backups unless using ClickHouse Cloud.
- Lacks some features like integrated data catalog, data sharing/marketplace, or built-in governance found in Snowflake.
- Concurrency is ultimately limited by hardware; no auto-scaling unless using managed cloud version.
Snowflake Pros and Cons
Here are the main Snowflake pros and cons:
Snowflake Benifits:
- No infrastructure management; instant elasticity of compute/storage, automatic upgrades, disaster recovery.
- Enables independent scaling, workload isolation, and high concurrency (concurrent "virtual warehouses" for different user groups).
- Full transactional compliance (ACID) for all DML/DDL operations, including multi-statement transactions.
- Supports advanced features (row/column-level security, masking, RBAC, OAuth, audit logging, HIPAA, PCI, FedRAMP, etc.).
- Industry-leading zero-copy data sharing, clean rooms, and a global data marketplace.
- Handles clustering, partitioning, micro-partitioning, adaptive caching, and query optimization with minimal user tuning.
- Extensive support for BI, ELT, ML, application development (via Snowpark, Streamlit, REST APIs, connectors).
Snowflake Limitations:
- No self-hosted/on-premises option; you're fully dependent on Snowflake’s cloud service (AWS, Azure, GCP).
- Usage-based compute (per-second/credit billing) can become expensive under high concurrency or large data processing workloads.
- While Snowpipe and Streams support micro-batch ingestion, true millisecond-latency streaming analytics is not a primary strength compared to ClickHouse.
- Users cannot directly tune file format, compression, or certain physical storage details.
- Data egress, migration, and dependency on proprietary features make switching platforms non-trivial.
ClickHouse vs Snowflake—When Would You Pick One Over the Other?
Choose ClickHouse if:
- Millisecond/sub-second query latency on large, fast-arriving event/time-series data is mission-critical.
- You require maximum performance per dollar for analytical workloads, especially at massive scale.
- Open source, self-hosting, or fine-grained control over infrastructure is required.
- Your team has expertise to manage/tune the system (unless using ClickHouse Cloud).
- Primary workloads involve aggregations, filtering, and analytics on append-only datasets (e.g., logs, telemetry, metrics).
Choose Snowflake if:
- You need a versatile, easy-to-use, fully managed data platform supporting a wide variety of workloads: data warehousing, BI, ELT, data lakes, ML, app development.
- Seamless scaling, workload isolation, and high concurrency are priorities.
- Security, governance, compliance, and data sharing are essential (e.g., regulated industries, data monetization).
- Integration with a broad ecosystem of BI/ETL/ML tools is necessary.
- You want to minimize operational overhead and infrastructure management.
Further Reading
- ClickHouse vs Druid
- ClickHouse Alternatives: 10 True Competitors
- ClickHouse Architecture 101
- Snowflake Documentation
- Databricks vs Snowflake
Save up to 30% on your Snowflake spend in a few minutes!


Conclusion
And that wraps up our comparison of ClickHouse vs Snowflake. ClickHouse and Snowflake are two different, highly capable approaches to solving the challenges of modern data analytics. Neither is better; the optimal choice depends entirely on the specific requirements, priorities, technical expertise, and budget constraints of the organization and the intended use case.
In this article, we have covered:
- What is ClickHouse?
- What is Snowflake?
- What Is the Difference Between Clickhouse vs Snowflake?
- ClickHouse vs Snowflake—Architectural Deep Dive
- ClickHouse vs Snowflake—Performance Breakdown
- ClickHouse vs Snowflake—Data Ingestion & Real‑Time Analytics
- ClickHouse vs Snowflake—Deployment Options
- ClickHouse vs Snowflake—Ecosystem & Integration
- ClickHouse vs Snowflake—Security & Governance
- ClickHouse vs Snowflake—Pricing Breakdown
- ClickHouse vs Snowflake—Use Cases
- ClickHouse vs Snowflake — Pros & Cons
… and so much more!
FAQs
Why is ClickHouse so popular?
ClickHouse's popularity arises from its exceptional performance in OLAP (Online Analytical Processing) environments. Its columnar storage model, vectorized query execution, and efficient use of hardware resources allow it to deliver significantly faster query performance for specific analytical workloads compared to traditional row-oriented databases. Also, its open source nature also drives adoption and community support.
Is ClickHouse better than Snowflake?
Neither ClickHouse nor Snowflake is universally better; the choice depends on specific use cases. ClickHouse typically excels in raw query speed, real-time data ingestion, and cost-efficiency for performance-sensitive applications, providing flexibility in deployment options. Conversely, Snowflake is renowned for its ease of use, fully managed operations, elastic scalability, broad workload support, advanced data sharing capabilities, and built-in enterprise governance features. Each solution has trade-offs: ClickHouse may require more manual tuning and has limitations regarding transactions, while Snowflake can become costly and may exhibit higher latency for some real-time queries.
Is ClickHouse the best database?
ClickHouse is an outstanding choice for OLAP workloads, particularly for real-time analytics, log analysis, and time-series data. But, it is not always the best fit for all scenarios. It’s unsuitable for OLTP (Online Transaction Processing) workloads due to its limited support for ACID transactions and inefficiencies in handling frequent row-level updates and deletes. Its effectiveness is highly use-case dependent.
What are the drawbacks of ClickHouse?
Drawbacks of ClickHouse include being not optimized for frequent updates/deletes (mutations are heavy), lack of full multi-statement ACID transactions, potentially complex JOIN tuning, significant management overhead if self-hosted, complex concurrency scaling, and a steeper learning curve for optimal tuning.
What are the drawbacks of Snowflake?
Drawbacks of Snowflake include a usage-based cost model that can become expensive without management, potential network latency impacting extreme low-latency queries, proprietary platform lock-in, no on-premises option, less user control over low-level tuning, and concurrency limits per warehouse cluster requiring Enterprise edition for higher loads.
Can I run Snowflake on my own servers or on-premises?
No, Snowflake is strictly a cloud-based service and operates exclusively on public cloud infrastructure (AWS, Azure, GCP). It does not support on-premises or private cloud deployment.
Is ClickHouse a replacement for Snowflake?
Generally, no. While there is some overlap in their capabilities, especially with ClickHouse Cloud offering a managed service, they often serve different primary needs or complement each other. Snowflake typically addresses broader data warehousing, data lake, and enterprise application needs, while ClickHouse focuses on high-performance, real-time analytical tasks.
Can ClickHouse and Snowflake be used together?
Yes, ClickHouse and Snowflake can be, and sometimes are, used together. ClickHouse for real-time hot data analytics/observability, feeding aggregated results into Snowflake for broader enterprise warehousing, BI, and data sharing.
Is ClickHouse suitable for OLTP?
No, ClickHouse is designed specifically for OLAP workloads and lacks the necessary features for efficient OLTP operations, such as single-row transaction handling and full ACID compliance.
How does Snowflake handle concurrency?
Snowflake manages concurrency through its multi-cluster virtual warehouse feature, available in the Enterprise edition and above. A virtual warehouse can automatically spin up additional compute clusters to handle incoming queries, thereby preventing queuing and providing scalable concurrency. Standard edition warehouses have a fixed concurrency limit per cluster (typically around 8). Different workloads can also run on separate warehouses, allowing for efficient resource allocation without interference.
What types of workloads are best suited for ClickHouse?
ClickHouse is perfect for analytical workloads that require high-speed query performance, such as log analysis, real-time data analytics, time-series analysis, and large-scale data aggregation tasks.
What types of workloads are best suited for Snowflake?
Snowflake excels in diverse workloads, including data warehousing, ETL processes, data lakes, business intelligence, and scenarios requiring complex joins across large datasets. It is particularly beneficial for organizations needing a scalable solution with strong data sharing capabilities.















