



























Data partitioning is a common concept used in data warehousing and is essentially the separation of large datasets into smaller, distinct chunks, which allows for easier data management, reduced data storage costs, and more efficient access to certain areas or subsets within the overall dataset.
Snowflake micro-partitions are contiguous units of data storage that Snowflake uses to automatically store data in by default. Unlike traditional RDBMSs, Snowflake divides tables into exponentially smaller partitions, allowing for faster query runtimes without having to manage massive chunks of data.
In this article, we will do a deep dive on explorations of what these Snowflake micro-partitions are, how they work, and their importance and benefits.
What is Data partitioning?
Partitioning is the process of breaking down a table into smaller, more manageable parts based on a set of criteria, for example, a date, a geographic region, or a product category. Each partition is treated as a separate table and can be queried independently, allowing faster and more efficient data retrieval. Also, keep in mind that partitioning can help lower storage costs by putting data that is used less often in cheaper storage space.
Let's consider an example to illustrate the benefits of data partitioning. Let's say, for example, that we have a sales database containing millions of records organized into year and month partitions so that data from specific months or years can be promptly accessed. Therefore, by partitioning the data like this, requests are more efficiently processed and more accurate answers can be obtained.
SELECT store_location, SUM(sales_amount)
FROM sales
WHERE transaction_date BETWEEN '2023-01-01' AND '2023-12-31'
AND product_category = 'Electronics'
GROUP BY store_locationAssume that the sales table is partitioned on the transaction_date and store_location columns. The warehouse can prune the partitions only to scan those containing data within a certain time frame or within a particular store location. This way, the number of records it needs to scan is significantly reduced, resulting in faster query times.
Now, hold on! So, what exactly is partition pruning?
Partitioning can also help to improve query performance through the process called “partition pruning”.
Partition pruning is the process of eliminating any partitions that do not contain the necessary information based on query criteria in order to reduce time and resource utilization, particularly for queries involving massive amounts of data.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

What are Snowflake Micro-Partitions?
Snowflake micro-partitions are contiguous units of data storage that Snowflake automatically stores data in by default. Whenever data is loaded into Snowflake tables, it automatically divides them into these micro-partitions, each containing between 50 MB to 500 MB of uncompressed data. Each micro-partition corresponds to a group of rows and is arranged in a columnar format.
Tables in traditional warehouses usually have a limited number of partitions, However, Snowflake’s micro-partitions’ structure allows for extremely granular pruning of very large tables, which can be comprised of millions, or even hundreds of millions, of micro-partitions.
Snowflake stores metadata about all rows stored in a micro-partition, including:
- The range of values for each of the columns in the micro-partition.
- The number of distinct values.
- Additional properties used for both optimization and efficient query processing.
Learn more about it from the official Snowflake documentation.
What do Snowflake micro-partitions look like?
Let's delve a bit deeper into the rabbit hole of Snowflake micro-partitions.
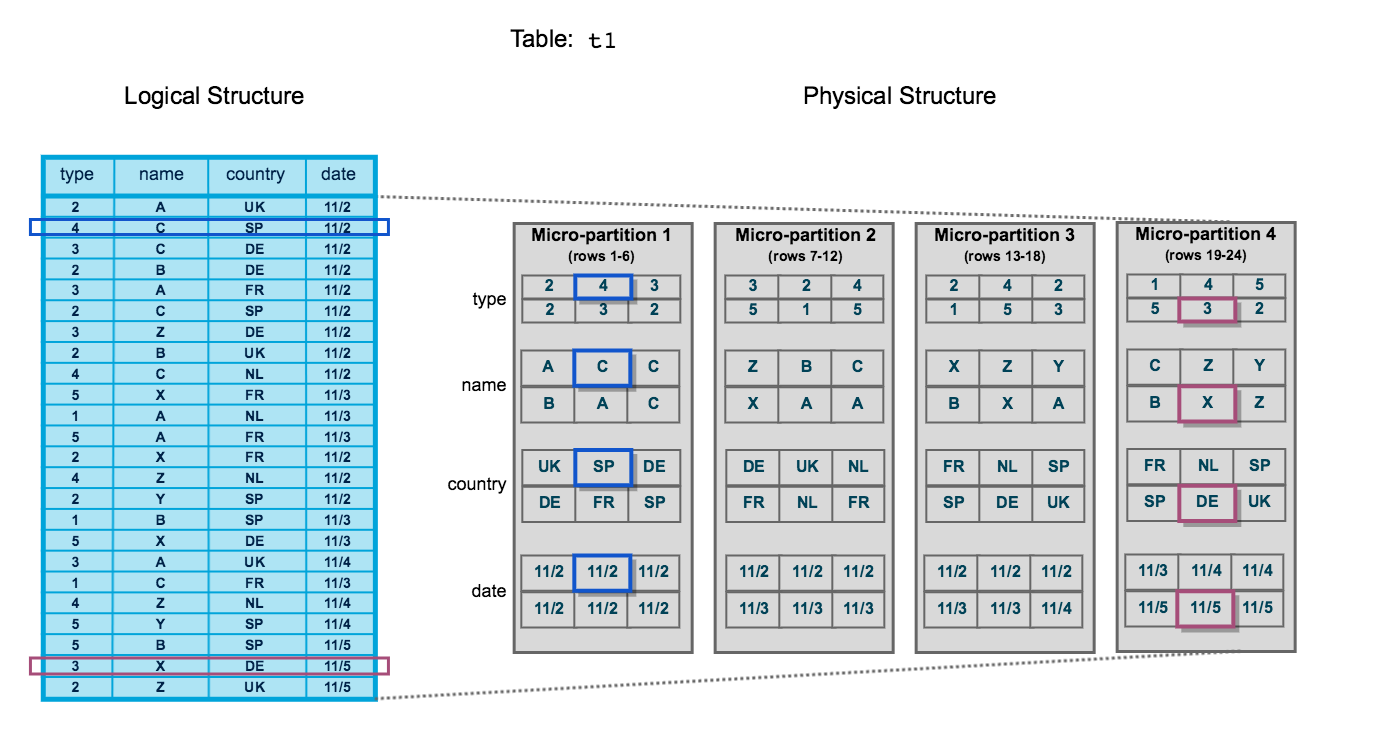
As shown in the image above, the table content on Snowflake is displayed on the left side as the logical structure, and the physical structure on the left side, which consists of four micro-partitions. Each partition can contain upto 50 to 500 MB of uncompressed data. As you can see, there are 24 rows of data in the table, including columns for type, name, country, and date. Also, two specific rows, the second and twenty-third, are highlighted. On the right-hand side, the physical structure of the table is displayed. Snowflake splits the table into four separate micro-partitions, each containing six rows of data. The first micro-partition includes data rows from 1 through 6, while the others contain data rows from 7 to 12, 13 to 18, and 19 to 24, respectively.
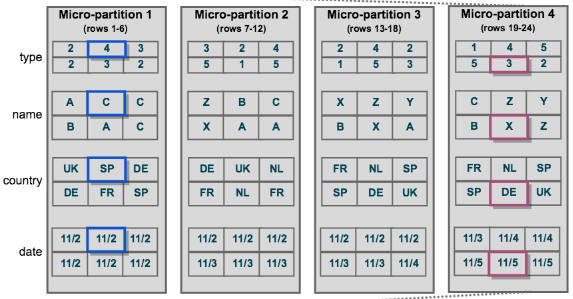
The data in the table is stored by column, not by row, which is then transposed into the multiple micro-partitions. So whenever you are searching for a specific record, the Snowflake identifies the record from the relevant partitions, queries only those partitions as needed, and retrieves it from the micro-partitions.
How many micro-partitions does Snowflake create?
Snowflake can create thousands or even millions of micro-partitions for a very large table. For every new arrival of data chunks, it does not modify the old micro-partitions because they are all immutable by nature, and hence it adds more and more micro-partitions as new data arrives.
Benefits of Snowflake Micro-Partitions
The benefits of Snowflake's approach to partitioning table data include:
- Automatic partitioning requires virtually no user oversight
- Snowflake Micro-partitions are small, allowing for efficient DML operations
- Snowflake Micro-partition metadata enables "zero-copy cloning", allowing for efficient copying of tables, schemas, and databases with no extra storage costs
- Original micro-partitions remain immutable, ensuring data integrity when editing data in a Snowflake zero-copy clone
- Snowflake Micro-partitions improve query performance through horizontal and vertical query pruning, scanning only the needed micro-partitions for better query performance
- Clustering metadata is recorded for each micro-partition, allowing Snowflake to further optimize query performance.
Save up to 30% on your Snowflake spend in a few minutes!


Conclusion
Snowflake micro-partitions are revolutionizing the way Snowflake warehouse assets are managed and queried. This approach breaks large Snowflake tables down into partition sizes much smaller than before, reducing Snowflake query runtimes and providing more efficiency in Snowflake data storage and management. With micro-partitions, Snowflake users can now effectively manage larger datasets without sacrificing speed or resources. In this article, we've discussed several aspects of Snowflake micro-partitions, including its definition and how they work using some examples and thorough explanations to help you better understand the significance and benefits of Snowflake micro-partitions.
Snowflake's micro-partitions are not just small chunks of data—they represent a giant leap forward in the world of data warehousing.
FAQs
How much data does a micro-partition contain?
A single micro-partition can contain up to 16MB of compressed data, typically between 50 and 500MB when uncompressed. There is no limit to the number of micro-partitions a table can have.
What is the purpose of Snowflake query pruning?
Snowflake query pruning is a technique that reduces the number of micro-partitions read during query execution. It eliminates irrelevant micro-partitions based on filters applied in the query, improving query performance by reducing data retrieval.
Can a single table have multiple micro-partitions?
Yes, Snowflake imposes no limit on the number of micro-partitions a single table can have. Large tables may have thousands or even millions of micro-partitions.
How are micro-partitions generated in Snowflake?
Micro-partitions in Snowflake are generated each time data is reclustered based on the clustering key for a table.
Are micro-partitions immutable in Snowflake?
Yes, the original micro-partitions in Snowflake remain immutable. When data is edited through zero-copy clone, new micro-partitions are generated, and the existing ones are never altered.
Is micro-partitioning automatic for all Snowflake tables?
Yes, micro-partitioning is automatically performed on all Snowflake tables.
Where are micro-partitions stored in Snowflake?
Micro-partition is a file that is stored in the blob storage service specific to the cloud provider of the Snowflake account like S3, Azure Blob Storage, and Google Cloud Storage.
What is the difference between cluster and partition in Snowflake ?
Clusters and partitions are two different ways to organize data in Snowflake. Clusters organize data within micro-partitions, while partitions divide a table into smaller units.
Are there any limits to the number of micro-partitions in Snowflake?
Snowflake automatically creates micro-partitions as needed. There is no limit; it can create thousands or even millions of micro-partitions for a very large table.









