



























Snowflake is renowned for its distinct pricing model and unique architecture. Users are only charged for the compute resources, storage and data transfer that they use, which allows them to save significantly on Snowflake costs. But, if usage is not closely regulated, costs may escalate. Understanding Snowflake's price structure is crucial for avoiding such complications and maximizing its efficacy.
In this article, we will go over everything you need to know about Snowflake compute costs—the cost of using virtual warehouses, serverless computing, and other cloud services in Snowflake. These costs are determined by the amount of Snowflake compute resources used and the duration of their use; proper optimization might help businesses cut down on their spending without adversely sacrificing Snowflake performance. This article provides actionable tips and real-world examples to help you better understand Snowflake compute costs and maximize your Snowflake ROI.
What Is Snowflake Compute Cost?
Snowflake compute costs are easy to comprehend, but before we even dive into that topic, we need to get a decent understanding of what a Snowflake credit means.
What are Snowflake credits?
Snowflake credits are the units of measure used to pay for the consumption of resources within the Snowflake platform. Essentially, they represent the cost of using the various compute options available within Snowflake, such as Virtual Warehouse Compute, Serverless Compute, and Cloud Services Compute.
If you are interested in learning more about Snowflake pricing and Snowflake credits pricing, you can check out this article for a more in-depth explanation.
Snowflake Virtual Warehouse Compute Costs
Snowflake virtual warehouse is a cluster of computing resources used to execute queries, load data and perform DML(Data Manipulation Language) operations. Unlike other traditional On-Premise types of databases, which rely entirely on a fixed MPP(Massively Parallel Processing) server, Snowflake virtual warehouse is a dynamic group of virtual database servers consisting of CPU cores, memory and SSD that are maintained in a hardware pool and can be deployed quickly and effortlessly.
Snowflake credits are used to measure the processing time consumed by each individual virtual warehouse based on the number of warehouses used, their runtime, and their actual size.
There are mainly two types of virtual warehouses:
- SnowStandard Virtual Warehouse
- Snowpark-optimized Virtual Warehouse
Standard Virtual Warehouse: Standard warehouses in Snowflake are ideal for most data analytics applications, providing the necessary Snowflake compute resources to run efficiently. The main key benefit of using standard warehouses is their flexibility—they can be started and stopped at any moment as per your needs, without any restrictions. Also, standard warehouses can be resized on the fly, even while they are currently under operation, to adjust to the varying resource requirements of your data analytics applications, meaning that you can dynamically allocate more or fewer compute resources to your virtual warehouse, depending on the type of operations it is currently performing. In our upcoming article, we'll go into detail about how a virtual warehouse works, including what snowflake pricing is, how much a virtual warehouse costs, and what its benefits and best practices are.
The various sizes available for Standard virtual warehouse are listed below, indicating the amount of compute resources per cluster. As you move up the size ladder, the hourly credit cost for running the warehouse gets doubled.
| Warehouse Types | X-Small | Small | Medium | Large | XL | 2XL | 3XL | 4XL | 5XL | 6XL |
|---|---|---|---|---|---|---|---|---|---|---|
| Standard Warehouse | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
Snowpark-optimized Virtual Warehouse: Snowpark-optimized Virtual warehouse provides 16x memory per node compared to a standard Snowflake virtual warehouse and is recommended for processes with high memory requirements, such as machine learning training datasets on a single virtual warehouse node.
Creating a Snowpark-optimized virtual warehouse in Snowflake is just as straightforward as creating a standard virtual warehouse. You can do this by writing or copying the SQL script provided below. The script creates a SNOWPARK_OPT_MEDIUM virtual warehouse of medium size, "SNOWPARK-OPTIMIZED" warehouse type, which is optimized for Snowpark operations.
create or replace warehouse SNOWPARK_OPT_MEDIUM with
warehouse_size = 'MEDIUM'
warehouse_type = 'SNOWPARK-OPTIMIZED';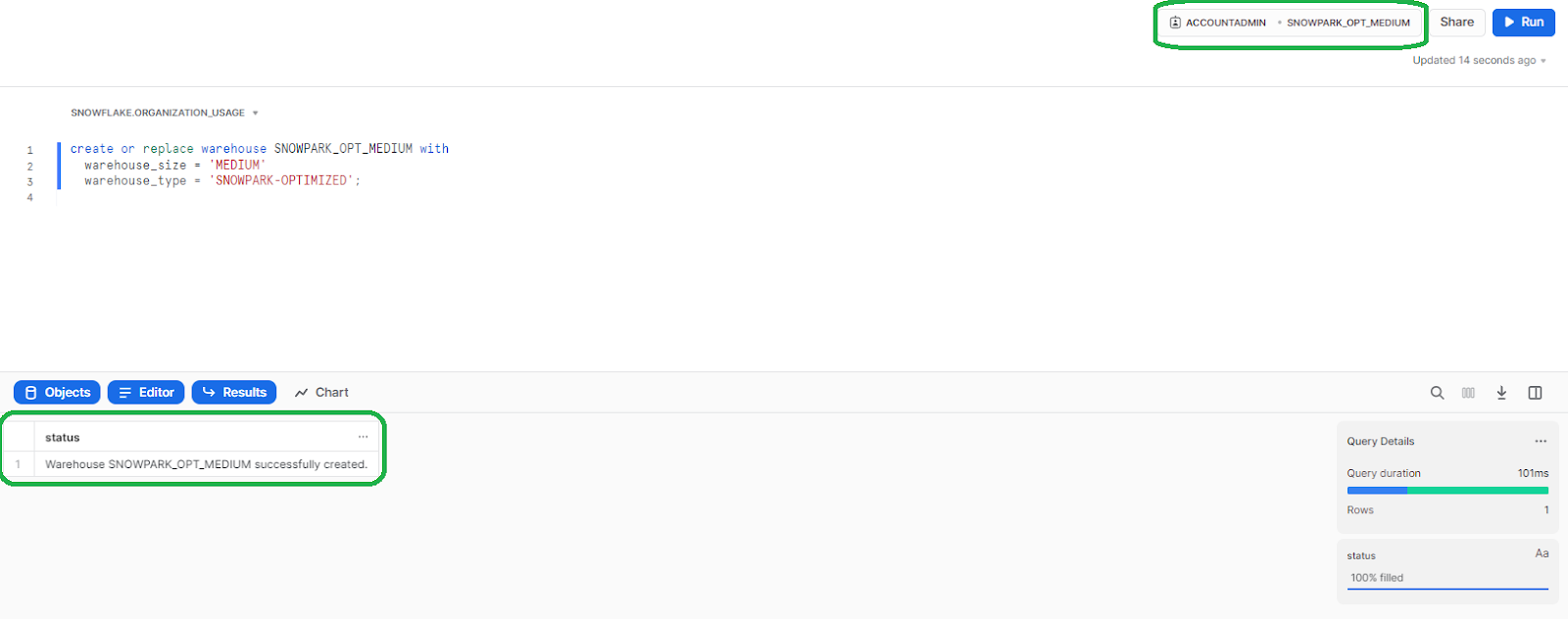
The table above lists the various sizes available for a Snowpark Optimized Virtual Warehouse, indicating the amount of compute resources per cluster. The number of credits charged per hour that the warehouse runs doubles as you progress from one size to the next (but as you can see, for X-Small and Small, it's not available).
| Warehouse Types | X-Small | Small | Medium | Large | XL | 2XL | 3XL | 4XL | 5XL | 6XL |
|---|---|---|---|---|---|---|---|---|---|---|
| Snowpark Optimized Warehouse | N/A | N/A | 6 | 12 | 24 | 48 | 96 | 192 | 384 | 768 |
Note: The larger warehouse sizes, 5X-Large and 6X-Large, are available for all Amazon Web Services (AWS) regions. These sizes are currently in preview mode in specific regions, including US Government regions and Azure regions.
Snowflake pricing for warehouses only occurs when they are running. If a warehouse is suspended, it stops calculating credit usage charges. Credits are billed per second, rounded to the nearest thousandth of a credit, with a minimum charge of 60 seconds, which means that even if a process only runs for a few seconds, it will be billed as 60 seconds.
Note: Once the first minute(60 second) has passed, all subsequent billing is based on the per-second rate until the warehouse is shut down. If a warehouse is suspended and then resumed within the first minute, multiple charges will occur as the 1-minute minimum will start over each time the warehouse is resumed. Also, resizing a warehouse from 5X- or 6X-Large to a smaller size, such as 4X-Large, will result in a brief period during which the warehouse is charged for both the new and old resources while the old resources get paused.
Save up to 30% on your Snowflake spend in a few minutes!


Snowpark Container Services Costs (SPCS Costs)
Snowflake recently introduced Snowpark Container Services, a fully managed container offering that enables containerized workloads to be hosted directly within Snowflake. It is currently accessible to all non-trial Snowflake customers in AWS commercial regions (Private Preview for Azure and Google Cloud is coming soon). This service allows you to deploy, manage, and scale containerized apps without moving data outside of Snowflake's environment. Snowpark Container Services, unlike standard container orchestration systems, provides an OCI runtime execution environment that is designed for Snowflake, allowing OCI images to be executed seamlessly while accessing Snowflake's rich data platform.
SPCS (Snowpark Container Services) utilizes Compute Pools, which are distinct from virtual warehouses. The credit consumption per hour for different Compute Pool configurations is as follows:
| Compute Node Types | XS | S | M | L |
|---|---|---|---|---|
| CPU | 0.11 | 0.22 | 0.43 | 1.65 |
| High-Memory CPU | N/A | 0.56 | 2.22 | 8.88 |
| GPU | N/A | 1.14 | 5.36 | 28.24 |
Snowflake Serverless Compute Costs
Serverless compute in Snowflake refers to the compute resources managed by Snowflake rather than standard virtual warehouse processes. Serverless credit usage refers to utilizing these compute resources provided and managed by Snowflake. Snowflake automatically adjusts the serverless compute resources based on the needs of each workload.
The following is a list of available Snowflake Serverless features:
- Automatic Clustering: Automatic Clustering is a Snowflake serverless feature that efficiently manages the process of reclustering tables as and when required, without any intervention from the user.
- External Tables: A typical table stores its data directly in the database, while an external table is designed to keep its data in files on an external stage. External tables contain file-level information about the data files, such as the file name, version identifier—and other properties. This makes it possible for users to query data stored in external staging files as if it were kept within the database.
Note: External tables are read-only.
- Materialized views: A materialized view is a pre-computed data set based on a specific query and stored for future use. The main benefit of using a materialized view is improved performance because the data has already been computed, making querying the view faster than executing the query against the base table. This performance improvement can be substantial, particularly when the query is fired frequently.
- Query Acceleration Service: A query acceleration service is a feature that can enhance the performance of a warehouse by optimizing the processing of certain parts of the query workload. It minimizes the impact of irregular queries, which consume more resources than the average query, thus improving warehouse performance.
- Search Optimization Service: Search Optimization Service has the potential to make a big difference in the speed of queries that look up small subsets of the data using equality or substring conditions.
- Snowpipe: Snowflake's Snowpipe is a Continuous Data Ingestion service that automatically loads data as soon as it is available in a stage. Snowpipe's serverless compute model helps users initiate data loading of any size without managing a virtual warehouse. Snowflake provides and manages the necessary compute resources, dynamically adjusting the capacity based on the current Snowpipe load.
- Serverless tasks: Serverless tasks in Snowflake are designed to execute various types of SQL code, including single SQL statements, calls to stored procedures, and procedural logic. The versatility of Snowflake serverless tasks makes it ideal for usecases in various scenarios. Serverless tasks can also be used independently to generate periodic reports by inserting or merging rows into a report table or performing other recurring tasks.
... and more!
Serverless feature charges are calculated based on Snowflake-managed compute resources' total usage, measured in compute hours. Compute-hours are calculated per second, rounded up to the nearest whole second. The amount of credit consumed per compute hour varies based on the specific serverless feature.
Let's dig deep into how Snowflake pricing for the above-mentioned + other serverless features works.
| Feature | Snowflake-managed compute | Cloud Services |
|---|---|---|
| Clustered Tables | 2 | 1 |
| Copy Files | 2 | N/A |
| Data Quality Monitoring | 2 | 1 |
| Hybrid Tables Requests | 1 | 1 |
| Logging | 1.25 | N/A |
| Materialized Views | 10 | 5 |
| Materialized Views maintenance in secondary databases | 2 | 1 |
| Query Acceleration | 1 | N/A |
| Replication | 2 | 0.35 |
| Search Optimization Service | 10 | 5 |
| Search Optimization Service in secondary databases | 2 | 1 |
| Serverless Alerts | 1.2 | 1 |
| Serverless Tasks | 1.2 | 1 |
| Snowpipe | 1.25 | N/A; instead charged 0.06 Credits/1000 files |
| Snowpipe Streaming | 1 | N/A; instead charged at an hourly rate of 0.01 Credits/client instance |
These serverless features provide numerous advantages, ranging from improved performance to improved data operations.
Note: Credits are consumed based on the total usage of a particular feature. For example, automatic clustering and replication consume 2 credits per compute hour, materialized views and search optimization service consume 10 credits per compute hour, query acceleration service consumes 1 credit per compute hour, Snowpipe consumes 1.25 credits per compute hour, and serverless tasks consume 1.5 credits per compute hour. So, before deciding to use certain serverless features, you should always be careful to think about how much credit these services will cost.
Snowflake Cloud Services Compute Costs
Snowflake Cloud services layer is a combination of services that manage various tasks within Snowflake, including user authentication, security, query optimization, request caching—and a whole lot more.
This layer integrates all components of Snowflake, including the use of virtual warehouses. It is designed with stateless computing resources that run across multiple availability zones, utilizing a highly available, globally managed metadata store for state management. The Cloud Services Layer operates on compute instances supplied by the cloud provider, and Snowflake credits are used to pay for usage.
Snowflake Cloud Services include the following features:
- User Authentication
- Query parsing and optimization
- Metadata management
- Access control
- Request query caching
How does Snowflake Pricing for Cloud Services work?
Like virtual warehouse usage, cloud service usage is paid for with Snowflake credits but with a unique model. You only pay if your daily cloud service usage exceeds 10% of your total virtual warehouse usage, calculated daily in the UTC time zone for accurate Snowflake credit pricing.
For example, if you use 120 Snowflake Warehouse credits daily, you get a 12-credit discount (10% of 120 = 12). If you use 12 or fewer credits in Cloud Services, they are free of charge. If you use 13 credits for Cloud Services, you'll pay for the 1 credit above 12. However, unused discounts won't be transferred or adjusted with other compute usage.
Note: Serverless compute does not affect the 10% adjustment for cloud services. The 10% adjustment is calculated by multiplying the daily virtual warehouse usage by 10% and is performed in the UTC zone.
| Date | Compute Credits Used (Warehouses only) | Cloud Services Credits Used | Credit Adjustment for Cloud Services | Credits Billed (Sum of Compute, Cloud Services, and Adjustment) |
| Jan 1 | 100 | 20 | -10 | 110 |
| Jan 2 | 120 | 10 | -10 | 120 |
| Jan 3 | 80 | 5 | -5 | 80 |
| Jan 4 | 100 | 13 | -10 | 103 |
| Total | 400 | 48 | -35 | 413 |
How to Calculate Snowflake Compute Costs?
As we saw earlier, the total Snowflake compute cost in Snowflake is composed of the utilization of various components. These include virtual warehouses, which are computing resources controlled and managed by the user; serverless features such as Automatic Clustering and Snowpipe, which utilize Snowflake-managed computing resources; and the cloud services layer of the Snowflake architecture, which also contributes to the total Snowflake compute cost.
To better understand past Snowflake compute costs, you can utilize Snowsight, Snowflake's web interface, or directly write SQL queries using the ACCOUNT_USAGE and ORGANIZATION_USAGE schemas. Snowsight provides a convenient and quick way to access cost information through its visual dashboard.
Check out this comprehensive video for an in-depth understanding of Snowflake compute pricing.
Viewing Snowflake Credit Usage
In Snowflake, all compute resources consume Snowflake credits, including virtual warehouses, serverless features, and cloud services. An account admin can easily monitor the total Snowflake compute credit usage through Snowsight, which provides a simple and easy-to-use interface for monitoring the Snowflake pricing.
To explore Snowflake compute costs using Snowsight, the administrator(ACCOUNTADMIN) can navigate to the Usage section under the Admin tab.
Once you do that, select Compute from the All Usage Types drop-down menu to view the detailed Snowflake compute usage information.
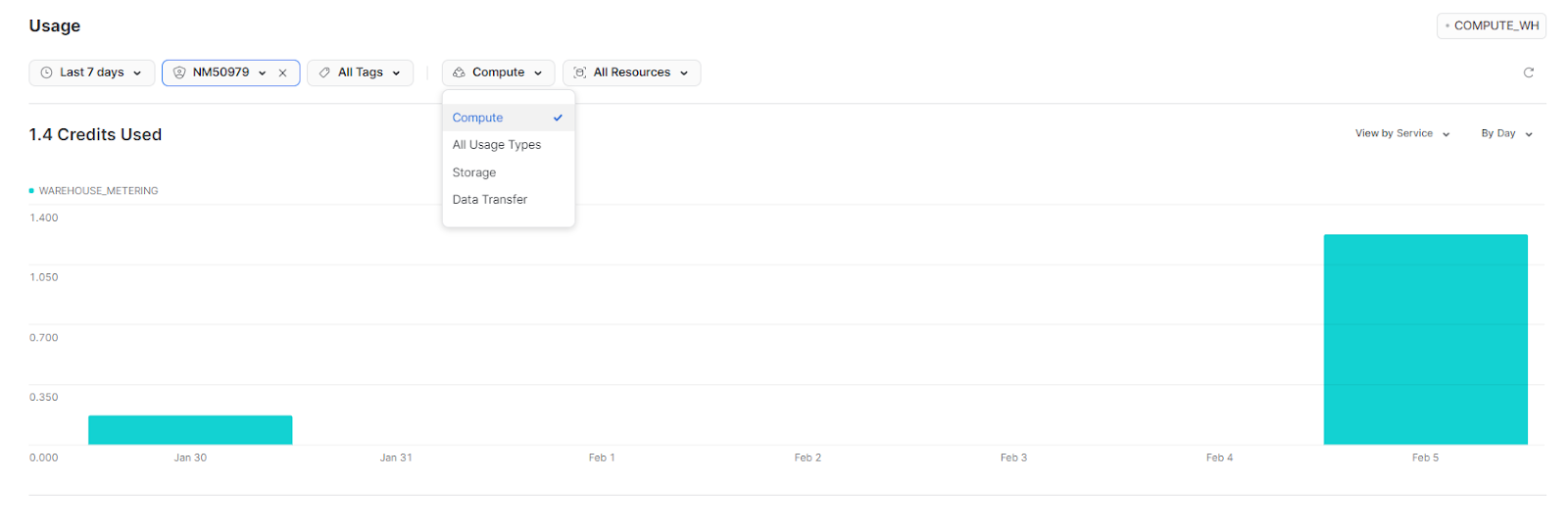
Snowflake Credit Monitoring—Filter By Tag
Filter by tag is a really useful feature in Snowflake that allows you to associate the cost of using resources with a particular unit. A tag is an object in Snowflake that can be assigned one or more values. Users with the rightful privileges can apply these tags and values to resources used by cost centers or other logical units, such as a development environment or business unit, allowing them to isolate costs based on specific tag and value combinations.
To view the costs associated with a specific tag and value combination in Snowsight, users can open the Usage dashboard and select the desired tag from the Tags drop-down menu. And then, select the desired value from the list of values associated with the tag and apply the filter by selecting "Apply."
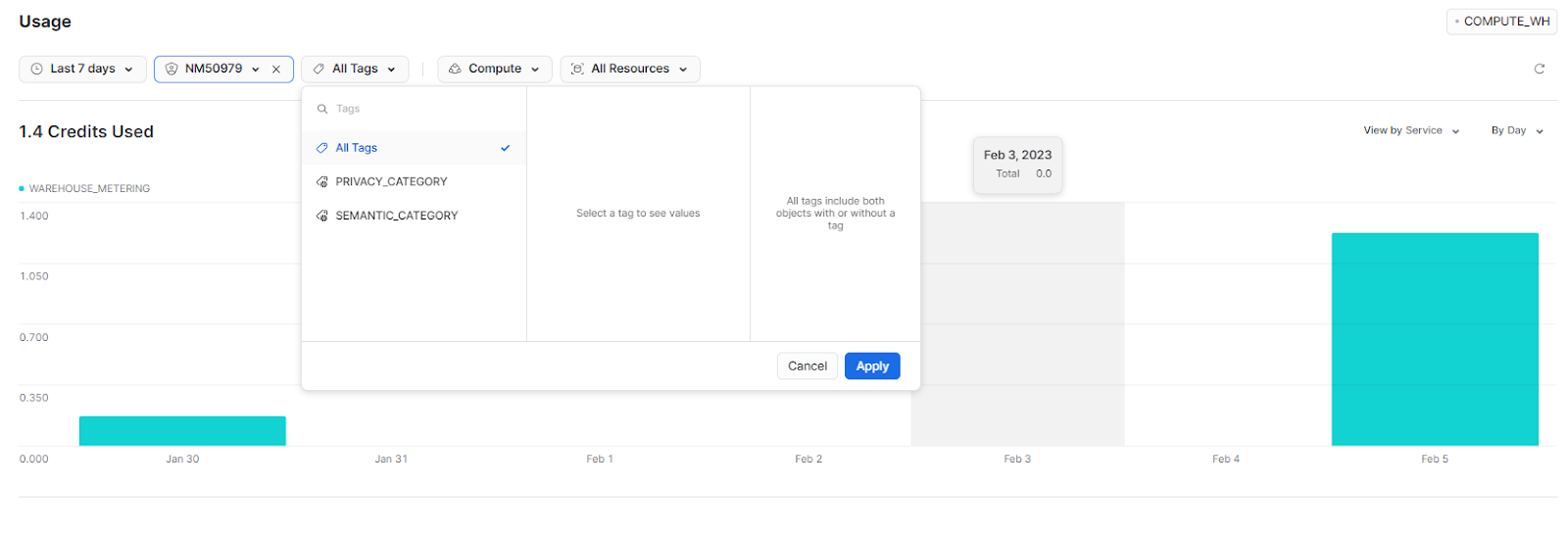
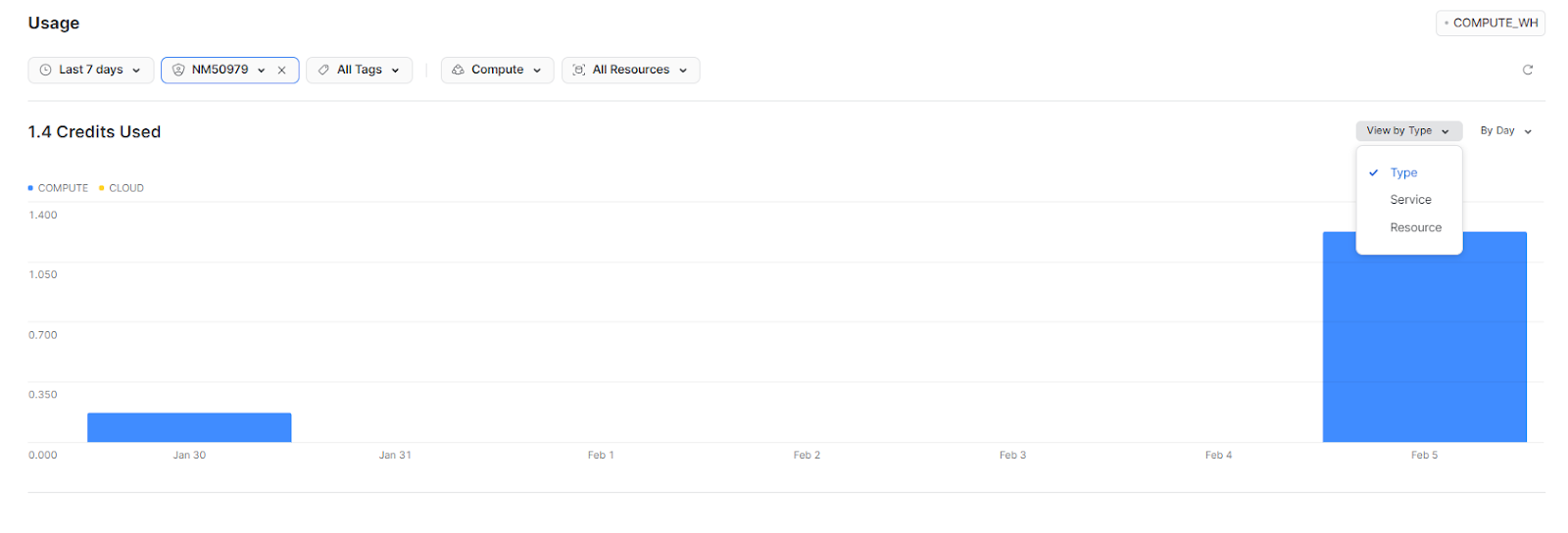
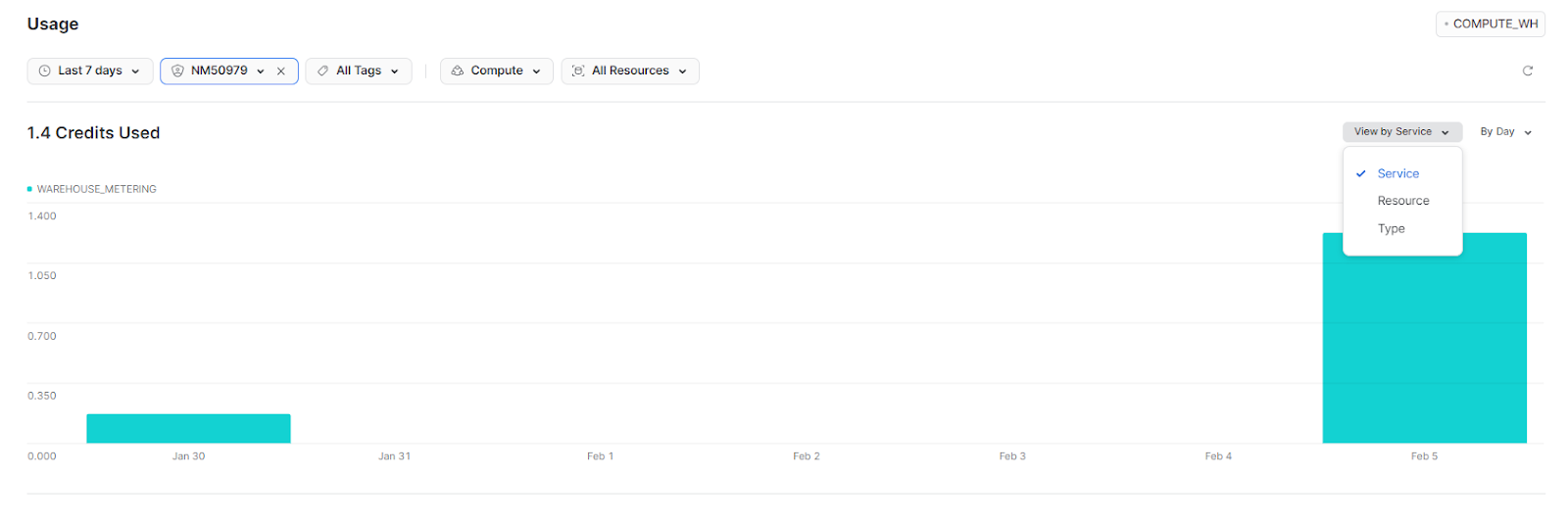
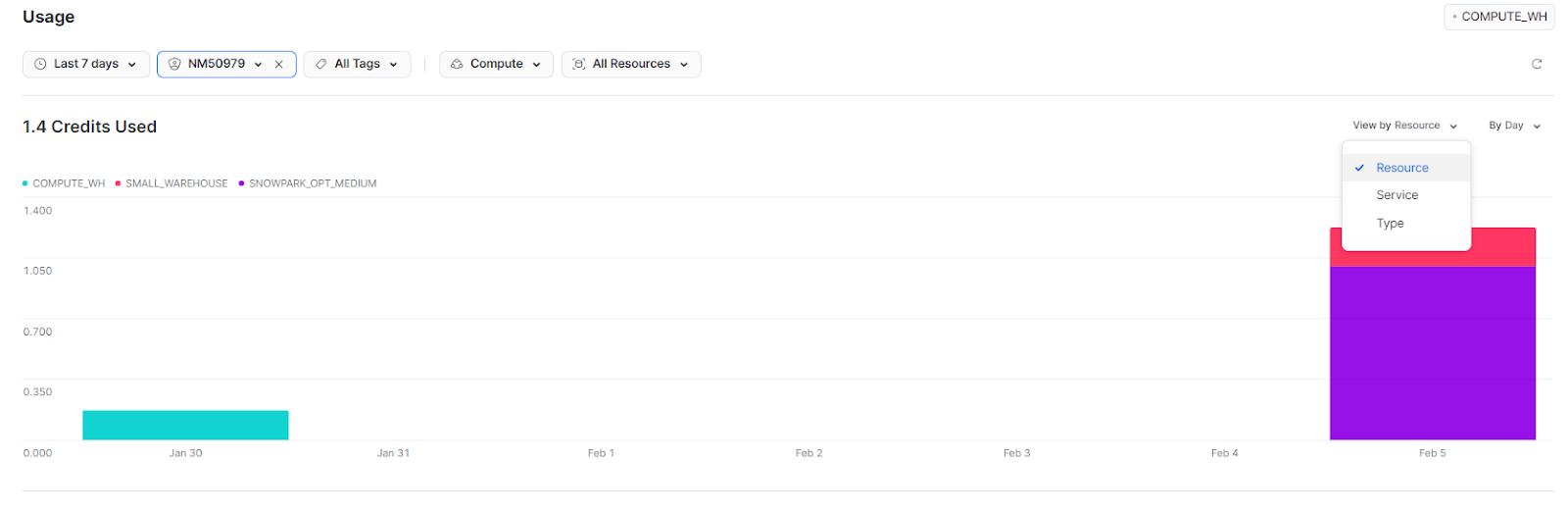
Snowflake Credit Consumption by Type, Service, or Resource
When analyzing the compute history through the bar graph display, you can filter the data based on three criteria:
- By Type
- By Service
- By Resource.
Each filter provides a unique perspective on resource consumption and helps you get a more in-depth understanding of the Snowflake pricing.
By Type allows you to separate the resource consumption into two categories:
- Compute (including virtual warehouses and serverless resources)
- Cloud services
This filter provides a clear distinction between the two types of compute resources.
By Service separates resource consumption into warehouse consumption and consumption by each serverless feature. Cloud services compute are included in the warehouse consumption.
By Resource, on the other hand, separates resource consumption based on the Snowflake object that consumed the credits.
Using SQL Queries for Viewing Snowflake Compute Costs
Snowflake offers two powerful schemas: ORGANIZATION_USAGE and ACCOUNT_USAGE. These Schemas contain rich information about Snowflake credit usage and Snowflake pricing. They provide granular usage data, ready for analytics, and can be used to create custom reports and dashboards.
The majority of the views in these schemas present the cost of compute resources in terms of credits consumed. But suppose you're interested in exploring the cost in currency rather than credits. In that case, you can write queries using the USAGE_IN_CURRENCY_DAILY View, which converts credits consumed into cost in currency using the daily price of credit.
The following views provide wide and important insights into the cost of compute resources and help you to make data-driven decisions on resource usage and cost control. For more thorough information on the cost of computing, refer to the following table:
| View | Compute Resource | Schema |
| AUTOMATIC_CLUSTERING_HISTORY | Serverless | ORGANIZATION_USAGE, ACCOUNT_USAGE |
| DATABASE_REPLICATION_USAGE_HISTORY | Serverless | ACCOUNT_USAGE |
| MATERIALIZED_VIEW_REFRESH_HISTORY | Serverless | ORGANIZATION_USAGE ACCOUNT_USAGE |
| METERING_DAILY_HISTORY | Warehouses Serverless Cloud Services | ORGANIZATION_USAGE ACCOUNT_USAGE |
| METERING_HISTORY | Warehouses Serverless Cloud Services | ACCOUNT_USAGE |
| PIPE_USAGE_HISTORY | Serverless | ORGANIZATION_USAGE ACCOUNT_USAGE |
| QUERY_ACCELERATION_HISTORY | Serverless | ACCOUNT_USAGE |
| REPLICATION_USAGE_HISTORY | Serverless | ORGANIZATION_USAGE ACCOUNT_USAGE |
| REPLICATION_GROUP_USAGE_HISTORY | Serverless | ORGANIZATION_USAGE ACCOUNT_USAGE |
| SEARCH_OPTIMIZATION_HISTORY | Serverless | ACCOUNT_USAGE |
Sample SQL Queries for Monitoring Snowflake Compute Costs
The following queries provide a deep dive into the data contained within the ACCOUNT_USAGE views, offering a closer look at Snowflake compute costs.
How to Calculate Snowflake Compute Costs—Virtual Warehouses
1) Average hour-by-hour Snowflake credits over the past 30 days
The following query gives a full breakdown of credit consumption on a per-hour basis, giving you a clear picture of consumption patterns and trends over the past 30 days. This detailed information can help you identify peak usage times and fluctuations in consumption, allowing for a deeper understanding of resource utilization.
select start_time, warehouse_name, credits_used_compute
from snowflake.account_usage.warehouse_metering_history
where start_time >= dateadd(day, -30, current_timestamp())
and warehouse_id > 0 order by 1 desc, 2;
-- by hour
select date_part('HOUR', start_time) as start_hour, warehouse_name, avg(credits_used_compute) as credits_used_compute_avg
from snowflake.account_usage.warehouse_metering_history
where start_time >= dateadd(day, -30, current_timestamp())
and warehouse_id > 0
group by 1, 2
order by 1, 2;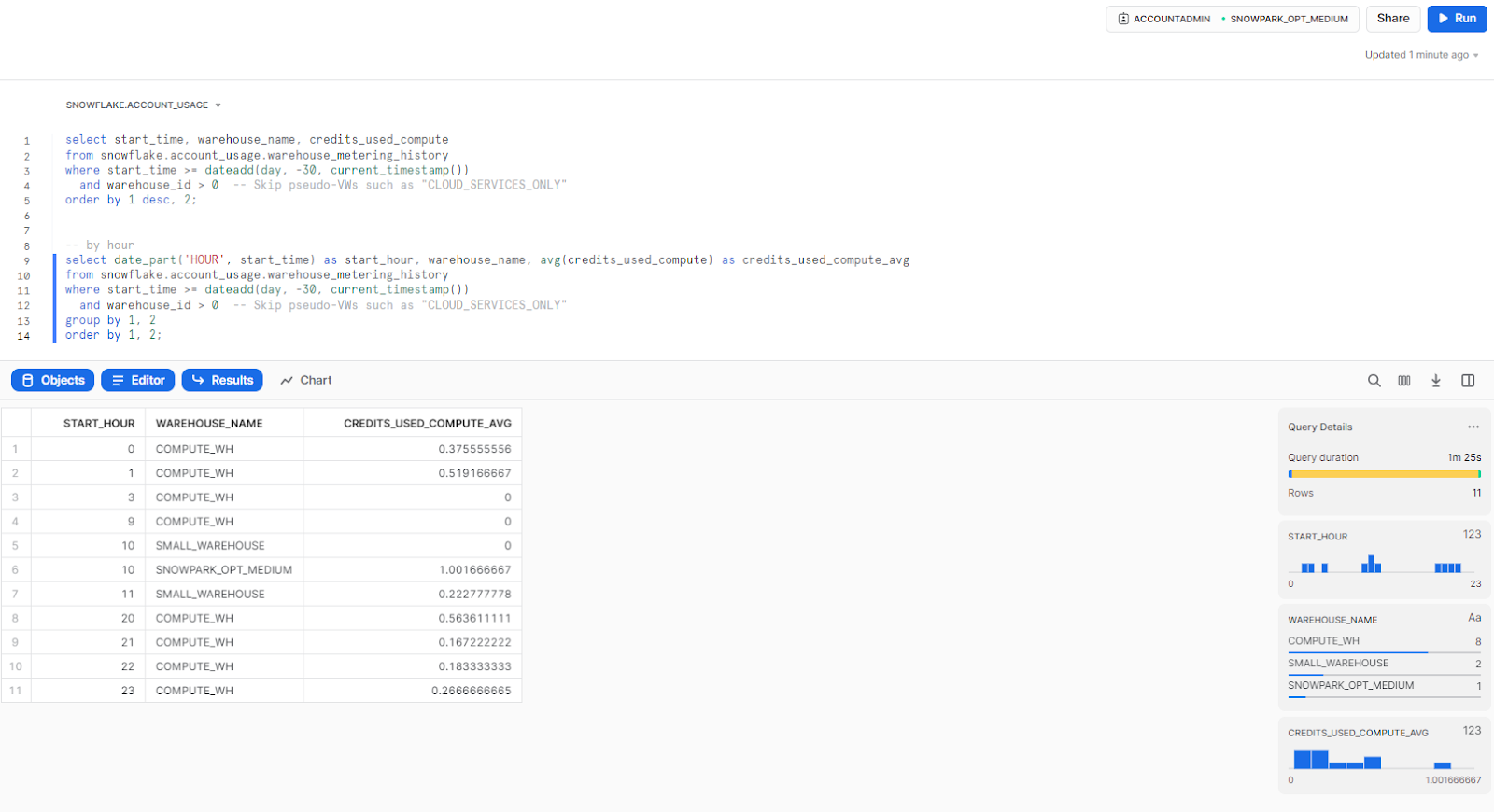
2) Credit consumption by warehouse over a specific period of time
This query shows the total credit consumption for each warehouse over a specific time period. This helps identify warehouses that are consuming more credits than others and specific warehouses that are consuming more credits than anticipated.
-- Credits used (all time = past year)
select warehouse_name
,sum(credits_used_compute) as credits_used_compute_sum
from account_usage.warehouse_metering_history
group by 1
order by 2 desc;
-- Credits used (past 30 days)
select warehouse_name,
sum(credits_used_compute) as credits_used_compute_sum
from account_usage.warehouse_metering_history
where start_time >= dateadd(day, -30, current_timestamp())
group by 1
order by 2 desc;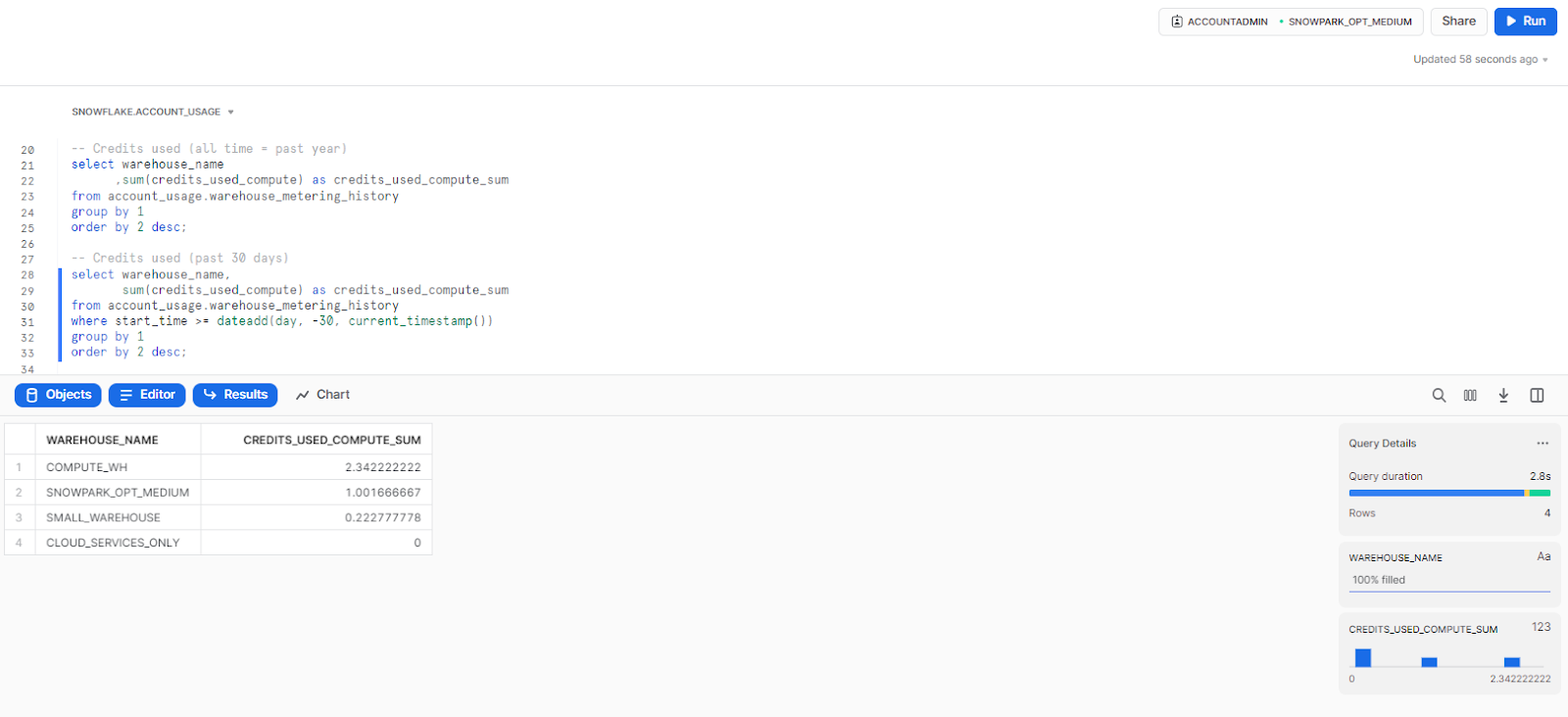
3) Snowflake Warehouse usage over 30-day average
This query calculates the average daily credit usage of each individual warehouse over the past 30 days, along with the percentage increase of each day's usage compared to that average. It filters the results only to show warehouses that have more than 0 credits and have had a day with a usage increase of 50% or more compared to their average. The results are then ordered by the percentage increase. This query helps to identify anomalies in credit consumption for warehouses across weeks from the past year.
with cte_date_wh as(
select to_date(start_time) as start_date
,warehouse_name
,sum(credits_used) as credits_used_date_wh
from snowflake.account_usage.warehouse_metering_history
group by start_date
,warehouse_name
)
select start_date
,warehouse_name
,credits_used_date_wh
,avg(credits_used_date_wh) over (partition by warehouse_name order by start_date rows 60 preceding) as credits_used_m_day_avg
,100.0*((credits_used_date_wh / credits_used_m_day_avg) - 1) as pct_over_to_m_day_average
from cte_date_wh
where credits_used_date_wh > 0
order by pct_over_to_m_day_average desc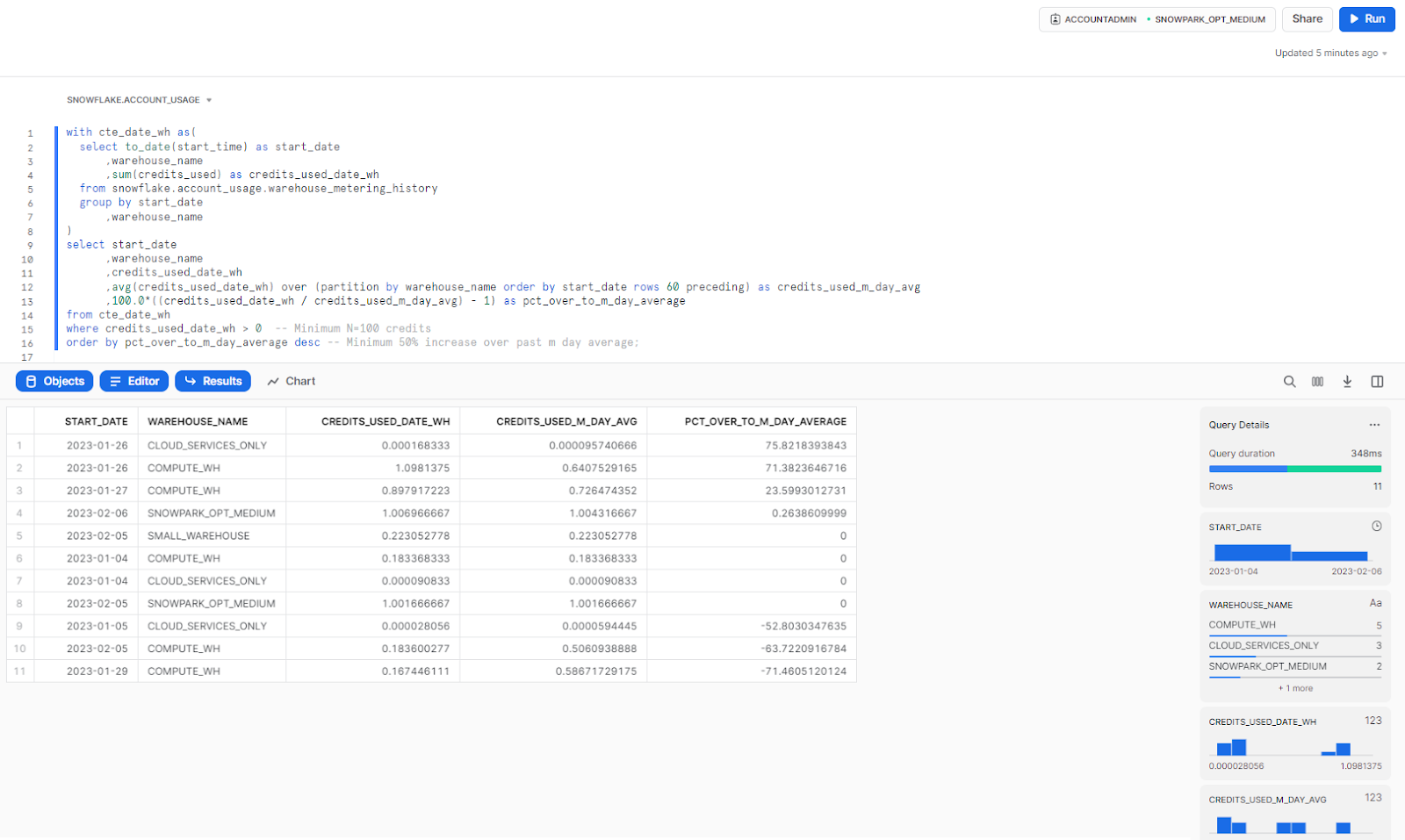
Calculating Snowflake Compute Costs—Automatic Clustering
1) Automatic Clustering cost history (by day, by object)
This query summarizes the credit consumption for automatic clustering over the past month by date, database, schema, and table name, and orders the result in descending order by total credits used.
select to_date(start_time) as date
,database_name
,schema_name
,table_name
,sum(credits_used) as credits_used
from "SNOWFLAKE"."ACCOUNT_USAGE"."AUTOMATIC_CLUSTERING_HISTORY"
where start_time >= dateadd(month,-1,current_timestamp())
group by 1,2,3,4
order by 5 desc;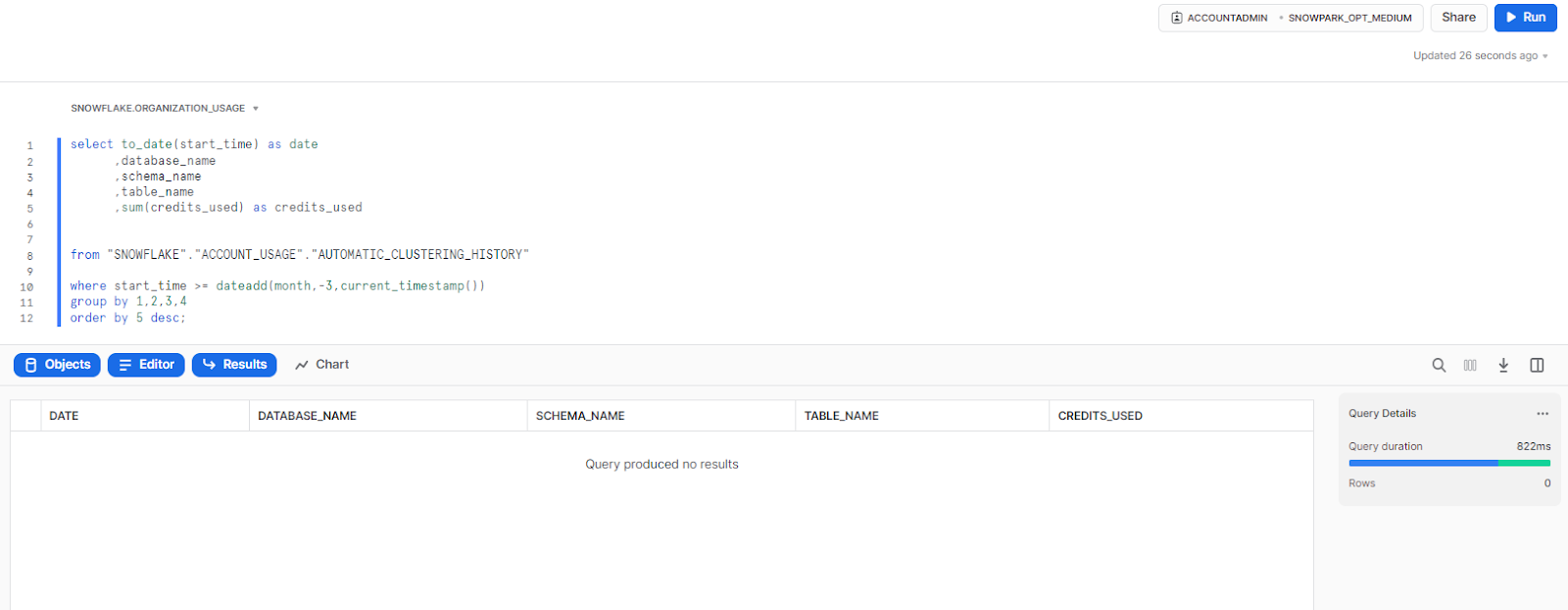
Calculating Snowflake Compute Costs—Snowflake Search Optimization Service
1) Snowflake Search Optimization Service cost history (by day, by object)
This query summarizes the total credits consumed via the services in Snowflake over the past month by date, database name, schema name, and table name, and orders the results in descending order of credits used.
select
to_date(start_time) as date
,database_name
,schema_name
,table_name
,sum(credits_used) as credits_used
from "SNOWFLAKE"."ACCOUNT_USAGE"."SEARCH_OPTIMIZATION_HISTORY"
where start_time >= dateadd(month,-1,current_timestamp())
group by 1,2,3,4
order by 5 desc;2) Search Optimization History
This query calculates the average daily credits used for each week over the past year, then proceeds to group the credits used by day, then groups the average daily credits by week, and orders the results by the date the week starts.
with credits_by_day as (
select to_date(start_time) as date
,sum(credits_used) as credits_used
from "SNOWFLAKE"."ACCOUNT_USAGE"."SEARCH_OPTIMIZATION_HISTORY"
where start_time >= dateadd(year,-1,current_timestamp())
group by 1
order by 2 desc
)
select date_trunc('week',date)
,avg(credits_used) as avg_daily_credits
from credits_by_day
group by 1
order by 1;Calculating Snowflake Compute Costs—Materialized Views
1) Materialized Views cost history (by day, by object)
This query generates a complete report of Materialized Views and the number of credits utilized by the service in the past 30 days, which is then sorted by day.
select
to_date(start_time) as date
,database_name
,schema_name
,table_name
,sum(credits_used) as credits_used
from "SNOWFLAKE"."ACCOUNT_USAGE"."MATERIALIZED_VIEW_REFRESH_HISTORY"
where start_time >= dateadd(month,-1,current_timestamp())
group by 1,2,3,4
order by 5 desc;2) Materialized Views History & m-day average
This query illustrates the average daily credits consumed by Materialized Views grouped by week over the last year. It helps highlight deviations or changes in the daily average, providing an opportunity to examine significant spikes or shifts in Snowflake credit consumption.
with credits_by_day as (
select to_date(start_time) as date
,sum(credits_used) as credits_used
from "SNOWFLAKE"."ACCOUNT_USAGE"."MATERIALIZED_VIEW_REFRESH_HISTORY"
where start_time >= dateadd(year,-1,current_timestamp())
group by 1
order by 2 desc
)
select date_trunc('week',date)
,avg(credits_used) as avg_daily_credits
from credits_by_day
group by 1
order by 1;Calculating Snowflake Compute Costs—Snowpipe
1) Snowpipe cost history (by day, by object)
This query provides a full list of pipes and the volume of credits consumed via the service over the last 1 month, which is then sorted by day.
select
to_date(start_time) as date
,pipe_name
,sum(credits_used) as credits_used
from "SNOWFLAKE"."ACCOUNT_USAGE"."PIPE_USAGE_HISTORY"
where start_time >= dateadd(month,-1,current_timestamp())
group by 1,2
order by 3 desc;Calculating Snowflake Compute Costs—Replication
1) Replication cost history
This query provides a full list of replicated databases and the volume of credits consumed via the replication service over the last 1 month (30days) period.
select
to_date(start_time) as date
,database_name
,sum(credits_used) as credits_used
from "SNOWFLAKE"."ACCOUNT_USAGE"."REPLICATION_USAGE_HISTORY"
where start_time >= dateadd(month,-1,current_timestamp())
group by 1,2
order by 3 desc;2) Replication History & m-day average
This query provides the average daily credits consumed by Replication grouped by week over the last 1 year.
with credits_by_day as (
select to_date(start_time) as date
,sum(credits_used) as credits_used
from "SNOWFLAKE"."ACCOUNT_USAGE"."REPLICATION_USAGE_HISTORY"
where start_time >= dateadd(year,-1,current_timestamp())
group by 1
order by 2 desc
)
select date_trunc('week',date)
,avg(credits_used) as avg_daily_credits
from credits_by_day
group by 1
order by 1;Calculating Snowflake Compute Costs—Cloud Services
1) Warehouses with high cloud services usage
This query shows the warehouses that are not using enough warehouse time to cover the cloud services portion of compute.
select
warehouse_name
,sum(credits_used) as credits_used
,sum(credits_used_cloud_services) as credits_used_cloud_services
,sum(credits_used_cloud_services)/sum(credits_used) as percent_cloud_services
from "SNOWFLAKE"."ACCOUNT_USAGE"."WAREHOUSE_METERING_HISTORY"
where to_date(start_time) >= dateadd(month,-1,current_timestamp())
and credits_used_cloud_services > 0
group by 1
order by 4 desc;How to Reduce Snowflake Compute Cost?
Snowflake provides a usage-based pricing model for its users, where costs are determined based on how much Snowflake compute and storage is used. To effectively manage Snowflake costs, data professionals must ensure their Snowflake credits are being used in the most efficient way possible.
To help with Snowflake cost management, here are a few best practices you can use for optimizing Snowflake compute costs:
1) Snowflake Warehouse Size Optimization
Selecting the right warehouse size for Snowflake can be a tricky decision. Snowflake compute costs increase as you move up in warehouse size, so it is important to consider carefully what size is best for your workload. Generally, larger warehouse tend to run queries faster, but getting the optimal size requires trial and error. An effective strategy may be starting with a smaller warehouse and gradually working your way up based on performance outcomes. Check out this article for a deeper, more in-depth understanding of optimizing your Snowflake warehouse size.
2) Optimizing Cluster and Scaling Policy for Snowflake Warehouses
Managing compute clusters and scaling policy are two essential aspects when aiming to reduce Snowflake compute costs. Most times, it is advised to begin with minimal clusters before gradually growing the number of clusters depending on the workload activities. This functionality is only available for users of Enterprise or higher tiers. For most workloads, the scaling policy is set to Standard. But if queuing is not an issue for your workload, you can set it to Economy, which will conserve credits by trying to keep the running clusters fully loaded.
Note: The Economy scaling policy is also only available in the Enterprise edition or above.
3) Workload Optimization in Snowflake
Group your workloads together and opt for a smaller warehouse to start. According to Snowflake, use only the queries that can be completed within 5 to 10 minutes or less. Monitor your queue to ensure jobs don't spend excessive time waiting, as this will increase execution time and credit consumption for the overall workload.
4) Snowflake Monitoring with Snowflake Resource Monitors
Once you have grouped your workloads and chosen the appropriate warehouse size, set up resource monitors to detect any problems. Snowflake Resource monitors can help you detect any problems with the workloads. They can either stop/suspend all activity or send alert notifications when Snowflake consumption reaches specific thresholds. For more info, check out this article which goes into depth about the Snowflake Resource monitor and how to use it to optimize Snowflake compute costs.
5) Snowflake Observability with Chaos Genius
Snowflake compute costs can quickly add up. The Snowflake resource monitor may not provide the detailed insights you need to manage your costs and keep them from getting out of control. That's where Chaos Genius comes in. This DataOps observability platform provides actionable insights into your Snowflake spending and usage, allowing you to break down costs into meaningful insights, optimize your Snowflake usage, and reduce Snowflake compute costs.
Using Chaos Genius, you can reduce spending on Snowflake compute costs by up to 30%. It provides an in-depth view and insight into workflows, enabling you to pinpoint areas that generate high costs and adjust usage accordingly. It gives you unmatched speed and flexibility in monitoring your expenses, so that you can accurately identify which features or products are driving up your compute costs and take corrective measures without sacrificing performance.
Chaos Genius provides real-time notifications that inform you about cost anomalies as soon as they occur, allowing you to respond swiftly and effectively. Take advantage of this powerful service today – book a demo with us now and see how it can transform your business.
6) Snowflake Query Optimization
Keep in mind that querying data in Snowflake consumes credits. The trick for Snowflake compute costs optimization is to tweak the query code and settings for efficient operation without affecting job performance. Read more on Snowflake Query Optimization in our article here.
7) Snowflake Materialized Views to minimize resource usage
Another way to reduce the Snowflake compute costs is to make use of materialized views. This feature, available only in Snowflake's Enterprise Edition, involves pre-computing large data sets for later use and querying them more efficiently. A materialized view will be especially beneficial when the underlying table or subset of rows do not change that often and consume a lot of resources such as processing time, credits and storage space while generating query results.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Conclusion
Snowflake's innovative pricing model has disrupted the cloud-based data platform industry, but navigating the Snowflake costs can be daunting.
Optimizing Snowflake compute costs is the key to unlocking the full potential of this revolutionary data warehousing solution. You can save big dollars without sacrificing performance by following best practices, tips and leveraging features like Snowflake Resource Monitors and Snowflake Observability tools like Chaos Genius. Make sure to take full benefit of Snowflake's flexible pricing structure and use this guide as your go-to resource for reducing Snowflake compute costs!!
FAQs
What are Snowflake credits?
Snowflake credits are units of measure used to pay for the consumption of computing resources within the Snowflake platform, including Virtual Warehouse Compute, Serverless Compute, and Cloud Services Compute.
What is Snowflake compute cost?
Snowflake compute cost refers to the charges incurred for using computing resources within the Snowflake platform, including Virtual Warehouses, Serverless Compute features, and Cloud Services. These costs are determined by the amount of Snowflake compute resources used and the duration of their usage.
What is a virtual warehouse in Snowflake?
Virtual warehouse in Snowflake is a cluster of computing resources used to execute queries, load data and perform DML(Data Manipulation Language) operations. It consists of CPU cores, memory, and SSD and can be quickly deployed and resized as needed.
What are the two types of Virtual Warehouses in Snowflake?
The two types of Virtual Warehouses in Snowflake are Standard Virtual Warehouses and Snowpark-optimized Virtual Warehouses.
What are Snowpark Container Services (SPCS)?
Snowpark Container Services (SPCS) is a fully managed container offering that enables containerized workloads to be hosted directly within Snowflake, without moving data outside of Snowflake's environment.
What is Snowflake Serverless Compute?
Snowflake Serverless Compute refers to compute resources managed by Snowflake, rather than standard virtual warehouse processes. Snowflake automatically adjusts the serverless compute resources based on the needs of each workload.
What is the pricing model for Snowflake virtual warehouses?
Snowflake virtual warehouses are priced based on the number of warehouses used, their runtime, and their actual size. The pricing varies for different sizes of virtual warehouses.
How are serverless compute costs calculated in Snowflake?
Serverless compute costs in Snowflake are calculated based on the total usage of the specific serverless feature. Each serverless feature consumes a certain number of Snowflake credits per compute hour.
What are some serverless features in Snowflake?
Serverless features in Snowflake include automatic clustering, external tables, materialized views, query acceleration service, search optimization service, Snowpipe, and serverless tasks.
How are Snowflake Serverless features charged?
Serverless feature charges are calculated based on the total usage of Snowflake-managed compute resources, measured in compute hours, with varying credit consumption rates for different features.
What is Snowflake Cloud Services Compute?
Snowflake Cloud Services Compute refers to a combination of services that manage various tasks within Snowflake, such as user authentication, query optimization, and metadata management.
How does Snowflake pricing work for Cloud Services?
Cloud service usage is paid for with Snowflake credits, and you only pay if your daily cloud service usage exceeds 10% of your total virtual warehouse usage.
How to estimate Snowflake costs?
To estimate Snowflake costs, you can utilize Snowsight's visual dashboard or write SQL queries against the ACCOUNT_USAGE and ORGANIZATION_USAGE schemas. These provide detailed information on credit consumption across Virtual Warehouses, Serverless features, and Cloud Services, which can then be translated into cost estimates based on Snowflake's pricing model.
What is the "Filter by Tag" feature in Snowflake?
The "Filter by Tag" feature in Snowflake allows you to associate the cost of using resources with a particular unit, such as a cost center or business unit, enabling cost isolation based on specific tag and value combinations.
How can you view Snowflake credit consumption by type, service, or resource using Snowsight?
In Snowsight, you can filter the credit consumption data by Type (Compute or Cloud Services), by Service (Virtual Warehouses or Serverless features), or by Resource (the specific Snowflake object that consumed the credits).
What is Workload Optimization in Snowflake?
Workload Optimization involves grouping workloads together and opting for a smaller warehouse to start, using only queries that can be completed within 5 to 10 minutes or less, and monitoring the queue to ensure jobs don't spend excessive time waiting.
How can Snowflake Resource Monitors help optimize costs?
Snowflake Resource Monitors can detect problems with workloads and either stop/suspend all activity or send alert notifications when Snowflake consumption reaches specific thresholds.
Can I view Snowflake compute costs in currency instead of credits?
Yes, Snowflake provides the USAGE_IN_CURRENCY_DAILY view to convert credits consumed into cost in currency using the daily price of credits.
How can Materialized Views help minimize Snowflake compute costs?
Materialized Views, available in Snowflake's Enterprise Edition, allow pre-computing large data sets for later use, enabling more efficient querying and potentially reducing compute costs, especially when the underlying data does not change often.
Is Snowflake compute cost expensive?
Snowflake compute cost can be expensive, but it depends on your specific workloads. If you only need a small amount of compute power, Snowflake can be a cost-effective option. However, if you need a lot of compute power, Snowflake can be more expensive than traditional on-premises data warehouses.
Is Snowflake cost-effective?
Snowflake's usage-based pricing model can be cost-effective if compute resources are optimized and utilized efficiently.
How does Snowflake charge their customers for storage and compute?
Snowflake employs a credit-based pricing model for compute resources and a flat rate per terabyte for storage.
- Compute Costs:
Customers are billed based on the number of Snowflake credits consumed for using Virtual Warehouses, Serverless Compute features (like Snowpipe, Materialized Views), and Cloud Services. Credits represent the cost of utilizing these compute resources. - Storage Costs:
Storage costs are separate from compute charges. Snowflake charges a flat monthly rate per terabyte (TB) of data stored, after applying compression. The storage rate varies based on the Cloud Platform (AWS, Azure, or GCP), the specific region, and the account type (Capacity or On-Demand).
References
- https://medium.com/snowflake/snowflake-virtual-warehouse-overview-701ec8e28185
- https://docs.snowflake.com/en/user-guide/cost-understanding-compute.html#serverless-credit-usage
- https://docs.snowflake.com/en/user-guide/warehouses-snowpark-optimized.
- https://docs.snowflake.com/en/user-guide/warehouses-considerations#how-are-credits-charged-for-warehouses
- https://docs.snowflake.com/en/user-guide/data-load-snowpipe-intro









