



























For today's data-driven businesses, implementing a high-performance cloud data warehouse is crucial for turning explosive data growth into actionable insights ⚡. But with an overload of options now available, choosing the right platform can feel a bit overwhelming. Two of the biggest names in the data warehouse space are Snowflake and Amazon Redshift. Both offer LOADs of features for handling/managing massive data—but which one is actually right for your needs?
In this article, we will cut through the confusion by outlining 10 key differences between Snowflake vs Redshift ❄️🔥. We will look at how the two data warehouse platforms differ in areas like architecture, performance, security, availability, pricing, and a whole lot more!!
What is Snowflake?
Snowflake burst onto the data warehousing scene in mid-2012 when it launched out of stealth mode with a unique cloud-native architecture. Rather than retrofitting a traditional on-premises data warehouse for cloud implementation like some competitors, Snowflake pioneered a built-for-the-cloud model that completely separated storage from compute. This separation allowed each aspect of the warehouse architecture to scale independently.
Snowflake is a fully managed platform that handles all infrastructure, tuning, and optimization behind the scenes so users can focus purely on deriving value from their data. It provides a high-performance, scalable, and secure cloud data platform for storing, processing, and analyzing massive volumes of data cost-effectively. Snowflake's cloud-native architecture and unique capabilities have cemented its position as a disruptive force in the data warehousing market by freeing businesses to zero in on their data and generate meaningful insights from it.

Some of Snowflake’s standout features include:
Here are some of the key features of Snowflake:
- SQL Support : Snowflake uses standard SQL for querying data, making it familiar for those with SQL skills.
- Concurrency: Snowflake can handle many concurrent users and queries efficiently.
- Data Exchange: Snowflake provides access to a marketplace of data, data services, and applications, simplifying data acquisition and integration.
- Secure: Snowflake has enterprise-grade security and compliance certifications. Data is also encrypted at rest and in transit.
- Managed Service : Snowflake is fully managed with no infrastructure for users to maintain.
- Web Interface : Snowflake provides Snowsight, an intuitive web user interface for creating charts, dashboards, data validation, and ad-hoc data analysis.
- Time Travel: Snowflake allows you to query past states of your data using Time Travel. So you can do backfills or corrections to historical data up to 90 days.
- Security Features: Snowflake provides IP whitelisting, various authentication methods, role-based access control, and strong encryption for data protection.
- Auto-Resume, Auto-Suspend, Auto-Scale: Snowflake provides automated features for performance optimization, cost management, and scalability.
- Snowflake Pricing: Snowflake uses a pay-for-usage model, resource optimization, flexible payment options and supports integration with cost-monitoring platforms (like Chaos Genius) for cost management.
—and much more!!
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

What is Amazon Redshift?
Amazon Web Services introduced Redshift in 2013 as a fully-managed petabyte-scale data warehousing service on AWS. Redshift allows storing and querying of large datasets for analytics and business intelligence applications. It utilizes columnar storage, data compression, and machine learning to get faster query performance compared to traditional on-prem data warehouse.
AWS Redshift takes care of provisioning infrastructure, configuring clusters, replication for high availability, and automating backups. It enables scaling compute and storage separately as needed for workloads. AWS Redshift Spectrum allows querying data directly from Amazon S3 without even loading it, providing extensive flexibility.

Some of Amazon Redshift standout features include:
- Columnar Storage: Amazon Redshift uses a columnar data storage architecture optimized for fast analytics queries.
- Massive Parallel Processing (MPP): Amazon Redshift leverages MPP to enable fast query performance across large datasets.
- Integration: Amazon Redshift integrates with other AWS data sources like Amazon S3, Amazon EMR, and Amazon DynamoDB for easy data ingestion.
- Redshift Security: Amazon Redshift provides encryption for data at rest and in transit. It also enables access controls and integration with Amazon VPC for security.
- Automated Scaling: Amazon Redshift can automatically scale storage and compute resources based on your workload requirements.
- Concurrency Scaling: Amazon Redshift can automatically provision additional clusters to handle spikes in concurrent queries.
- Amazon Redshift Spectrum: With Redshift Spectrum you can directly query data in Amazon S3 without having to load it into Redshift.
- Advanced Machine Learning: Amazon Redshift uses machine learning capabilities to optimize and improve query performance.
- Easy Deployment: Amazon Redshift is fast and simple to deploy as it is a fully managed service from AWS.
- Flexible Billing: Amazon Redshift offers pay-as-you-go pricing model based on provisioned resources like nodes, concurrency scaling, and scanned data.
10 Key Differences Between Snowflake vs AWS Redshift
Now that we’ve provided an overview of Snowflake vs Redshift independently, let’s dig into the nuts and bolts of how these two data warehousing solutions differ from one another:
1) Snowflake vs Redshift — Architecture Showdown
The underlying architecture of a data warehouse platform has significant implications for performance, scalability, security—and costs.
Let's examine how Snowflake vs AWS Redshift differ at an architectural level.
Snowflake Architecture
Snowflake utilizes a unique hybrid architecture that combines elements of shared disk and shared nothing Snowflake architectures. In the storage layer, data is stored in a centralized location in the cloud, accessible by all compute nodes, similar to a shared disk architecture. However, the compute layer operates on a shared nothing model, where independent compute clusters called Virtual Warehouses process queries independently.
Snowflake architecture has three layers—storage, compute, and cloud services.
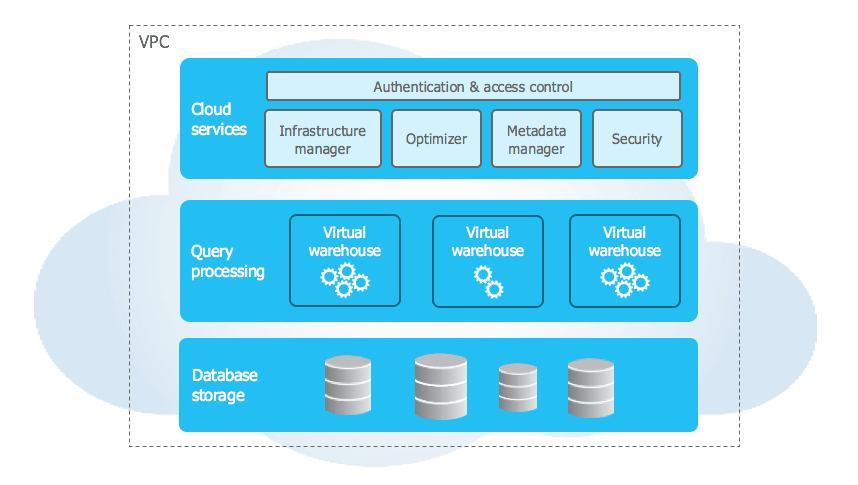
Storage: Snowflake storage layer is designed to optimize data storage and accessibility. When data is loaded into Snowflake, it is converted into an optimized, compressed, columnar format. This format allows for faster query execution and reduced storage requirements. The data is then stored in cloud storage, which is managed entirely by Snowflake. This storage layer is responsible for managing various aspects of data storage, including file size, structure, compression, metadata, statistics, and more. The data stored in Snowflake is not directly accessible to users; instead, it can only be accessed through SQL query operations executed using Snowflake.
Since Snowflake runs completely on the cloud, a Snowflake account can be created on the following cloud providers’ platforms:
Compute: Snowflake compute/query processing layer utilizes "virtual warehouses" to execute each query. Each virtual warehouse is an MPP (massively parallel processing) compute cluster consisting of multiple compute nodes allocated by Snowflake from a cloud provider. This distributed computing environment enables Snowflake to process large volumes of data quickly and efficiently. Each virtual warehouse operates independently, without sharing compute resources with other virtual warehouses. As a result, the performance of one virtual warehouse does not affect the performance of others. This independence allows Snowflake to allocate resources effectively and ensure optimal performance for each user.
Cloud services: The cloud services layer ties together all the different components of Snowflake to process user requests, ranging from login to query dispatch. This layer manages various services, including authentication, infrastructure management, metadata management, query parsing and optimization — and access control. Note that the cloud services layer runs on compute instances provisioned by Snowflake from the cloud provider.
Amazon Redshift Architecture
Amazon Redshift is designed to handle massive data sets, perform complex queries, and deliver high performance analytics. Amazon Redshift utilizes a shared-nothing, Massively Parallel Processing (MPP) architecture. Redshift is meant to work in cluster formation. A typical Redshift Cluster has two or more Compute Nodes which are coordinated through a Leader Node. All client applications communicate with the Cluster only through the Leader Node.
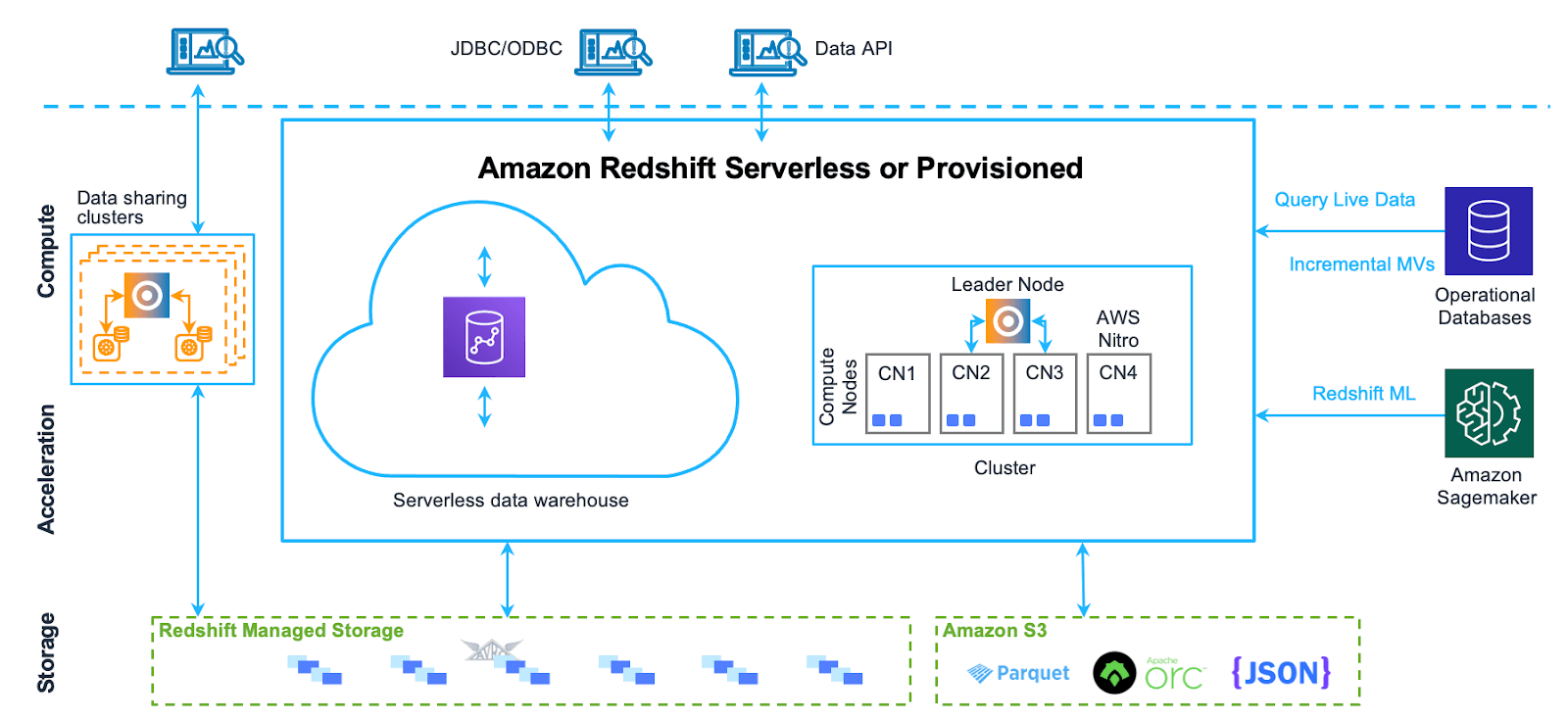
The Amazon Redshift architecture can be broken down into the following components:
- Leader Node: The leader node is responsible for coordinating the compute nodes and handling external communication. It parses and develops execution plans for database operations and distributes them to the compute nodes.
- Compute Nodes: The compute nodes execute the database operations and store the data. They receive the execution plans from the leader node and perform the required operations. Amazon Redshift provides two categories of nodes:
- Dense compute nodes come with SDD and are best for performance-intensive workloads.
- Dense storage nodes come with HDD and are best for large data workloads. - Redshift Managed Storage (RMS): RMS is a separate storage tier that stores data in a scalable manner using Amazon S3 storage. It automatically uses high-performance SSD-based local storage as a tier-1 cache and scales storage automatically to Amazon S3 when needed.
- Node Slices: A compute node is divided into slices, each with its own allocation of memory and disk space. The leader node distributes data and workloads among the slices, which work in parallel to complete operations.
- Internal Network: Amazon Redshift uses a private, high-speed network between the leader node and compute nodes, allowing for fast communication between them.
- Databases: A cluster may contain one or more databases that store user data. The leader node coordinates queries and communicates with the compute nodes to retrieve data.
2) Snowflake vs Redshift — Battle of Query Performance
For any data warehouse, fast query performance and concurrency support for multiple simultaneous queries are critical requirements. Snowflake and Redshift leverage different architectures to deliver optimal query performance / speeds.
Snowflake's Query Performance:
Snowflake architecture separates storage and compute resources, allowing for independent scaling. This means that as your data grows, you can increase your compute power/resources (virtual warehouses) to maintain high-speed query performance. Snowflake's multi-cluster shared data architecture allows multiple queries to run in parallel without any resource contention, ensuring high concurrency.
Furthermore, Snowflake also uses a technique known as “automatic clustering” to organize data in the most efficient way possible in order to enhance query performance. Snowflake also makes use of micro-partitioning, storing table data in small chunks spread across nodes, which enables parallel querying of partitions for faster speeds. It also makes use of caching mechanisms at various levels. For instance, the result set cache allows repeated queries to be fetched instantly without re-computation, and the warehouse cache reduces the spin-up time for compute resources.
Amazon Redshift Query Performance:
Amazon Redshift uses a columnar storage system and massively parallel processing (MPP) architecture, which allows it to execute complex queries quickly. Redshift's query optimizer redistributes the data to compute nodes as needed and performs operations in parallel to speed up query execution.
Amazon Redshift also uses machine learning to deliver high query performance. Its feature, "Short Query Acceleration (SQA)", uses machine learning to prioritize short, interactive queries over long-running ones, ensuring fast query execution. Also, Amazon Redshift's "Automatic Workload Management (WLM)" uses machine learning to manage memory and concurrency, dynamically allocating resources to queries based on their complexity.
3) Snowflake vs Redshift — Scalability
Scalability is a critical factor when considering a data warehouse solution, as it directly impacts the ability of the system to handle increasing volumes of data and concurrent user queries. Snowflake and Amazon Redshift both offer scalability, but they approach it in various different ways.
Snowflake scalability :
Snowflake's architecture is designed around the concept of separate storage and compute resources, which allows it to scale independently. This decoupled architecture means that as your data grows, you can increase your storage without affecting your compute resources. Similarly, if you need to handle more concurrent queries, you can scale up your compute resources without needing to increase your storage. This flexibility is a significant advantage of Snowflake's scalability.
Snowflake also offers automatic scalability. It can automatically adjust compute resources based on the query workload, ensuring optimal performance without manual intervention. This “feature” is particularly beneficial for users/businessess with unpredictable/fluctuating workloads, as it ensures they always have the necessary resources without overpaying for unused capacity.
Amazon Redshift scalability :
On the other hand, Amazon Redshift scalability is more traditional. Redshift uses a clustered approach, where you scale by adding more nodes to your cluster. Each node provides additional compute resources and storage. While this approach can effectively handle large data volumes, it does not offer the same level of flexibility as Snowflake's decoupled architecture.
Redshift scalability is kind of manual, meaning you need to choose when to scale up or down. While Redshift does offer some level of automatic scaling with its "Concurrency Scaling" feature, it's primarily designed to handle short-term increases in query load rather than long-term growth.
4) Snowflake vs Redshift — Security Controls
Snowflake and Redshift both offer robust security controls common across data platforms, like access controls, encryption, compliance certifications – and more!!
Here in this section we’ll focus on two signature security capabilities that set Snowflake and Redshift apart.
For Snowflake, one of the most powerful security features is seamless, granular access controls with secure data sharing. Snowflake also uses a role-based access control model, where access to data objects is governed by users’ roles, not physical data locations. This allows for effortlessly sharing data across accounts, clouds, and external organizations without copying or moving the entire data manually. Users only see the data their role permits. Snowflake also has robust data masking and encryption capabilities built-in.
On the other hand, Amazon Redshift relies on end-to-end encryption for data security by default. All data moving in and out of Redshift, plus backups, are encrypted. Redshift also integrates tightly with other native AWS security tools, including VPCs for network isolation and the AWS Key Management Service. Redshift too offers granular permissions, but data sharing requires some export and import maneuvers since data is not natively or entirely decoupled from infrastructure.
Both Snowflake and Redshift platforms have excellent security but Snowflake facilitates more seamless, fine-grained data access control and sharing due to its unique architecture. But Redshift may appeal to organizations already invested in the AWS only security ecosystem.
5) Snowflake vs Redshift — Availability Zone Face-Off
Cloud data warehouses must offer resilience and high availability to support mission-critical workloads. Snowflake and Redshift leverage cloud-native capabilities differently to maximize uptime.
Snowflake's Availability:
Snowflake's architecture is designed to be fault-tolerant and highly available. It automatically replicates data across multiple availability zones within a region, ensuring that your data is always accessible even if one zone goes down. In addition, Snowflake offers cross-region replication, which allows you to replicate your data to other regions for disaster recovery purposes or to serve global users with lower latency.
On top of that, Snowflake's "Zero-Copy Cloning" feature allows you to create a copy of your database or table without duplicating the storage, which can be used for high availability or testing purposes. Also, Snowflake's "Time Travel" feature allows you to access historical data for a specified period, which can be useful for recovering from accidental data changes or deletions.
Amazon Redshift Availability:
Amazon Redshift also provides high availability by automatically replicating data across multiple nodes in a cluster, and it continuously backs up the data to Amazon S3. Redshift uses Amazon's Availability Zones to make sure and guarantee that your data is highly available and fault-tolerant. If a node fails, Redshift automatically replaces it with a new one, ensuring that your data remains accessible.
Amazon Redshift also offers cross-region snapshots, which allow you to backup your data to other regions for disaster recovery. However, unlike Snowflake, Redshift does not offer cross-region replication, which means you cannot serve your data from multiple regions simultaneously.
6) Snowflake vs Redshift — Cloud Platform and Partner Integrations
The ability to integrate with other data platforms, BI tools, and cloud services is key for a modern data warehouse. Snowflake and Redshift offer extensive integrations but vary in breadth across ecosystems.
Snowflake with Major Cloud Providers
A unique advantage of Snowflake is its vendor-neutral positioning across cloud platforms. Snowflake is available across the three major public clouds — Amazon Web Services (AWS), Google Cloud Platform (GCP) and Microsoft Azure (Azure)
This allows using Snowflake seamlessly across different cloud platforms for multi-cloud and hybrid scenarios. Snowflake also integrates natively with major cloud data services.
Snowflake also has a wide range of technology partners and platform integrations. Using Snowflake, you can sync data bi-directionally with leading data integration platforms. Snowflake also connects with all major BI and data science tools.
Amazon Redshift Integrations with AWS and Partners
Amazon Redshift is deeply integrated with the AWS ecosystem. For AWS-centric environments, Redshift makes it easy to build end-to-end data flows and pipelines within the AWS stack. While Redshift takes advantage of AWS's scalable infrastructure, it does not have the multi-cloud flexibility like that Snowflake offers.
Amazon Redshift also has technology partners and integrates with third-party ETL, visualization, machine learning tools — and a whole lot more! Amazon maintains strong partnerships with vendors to enable Redshift integrations.
While you can connect external applications and services to Redshift, its cloud portability and multi-cloud capabilities are more limited compared to Snowflake.
7) Snowflake vs Redshift — Time Travel, Backup and Restore Capabilities
Time Travel, Backup, and Restore capabilities are essential features of any data warehousing solution, as they ensure data durability and provide a safety net against accidental data loss or changes. Both of ‘em Snowflake and Amazon Redshift, offer these capabilities, but they approach them differently.
Snowflake Time Travel, Backup, and Restore Capabilities:
Snowflake offers a unique feature called "Time Travel" that allows you to access historical data for a specified period. This feature can be used to restore data to any point within the defined time frame, which can be up to 90 days, which is particularly useful for recovering from accidental data changes or even deletions.
In terms of backup, Snowflake automatically replicates all data across multiple availability zones in the same region for high durability. It also provides cross-region replication for disaster recovery purposes. The restore process in Snowflake is straightforward and can be done easily using SQL commands.
Amazon Redshift Time Travel, Backup, and Restore Capabilities:
Amazon Redshift also does offer a feature equivalent to Snowflake. It also does provide robust backup and restore capabilities. Redshift automatically takes snapshots of your data at regular intervals and stores them in Amazon S3. These snapshots can be used to restore your data to any point in time within the snapshot retention period.
Amazon Redshift also replicates all data across multiple nodes in a cluster for high durability and continuously backs up your data to Amazon S3. For disaster recovery, Redshift offers cross-region snapshots, which allow you to backup your data to other regions.
Check out this official documentation to learn more about Amazon Redshift snapshots and backups
8) Snowflake vs Redshift — Developer Experience
Developer experience is a CRUCIAL aspect of any DW solution, as it directly impacts the ease of use, productivity, and overall satisfaction of the developers. Snowflake and Amazon Redshift have both made significant strides in this area, but they offer different experiences.
Here's how Snowflake and AWS Redshift compare in terms of their developer experiences.
Snowflake's Developer Experience:
Snowflake provides a very user-friendly interface (UI) that is intuitive and easy to navigate, making it a favorite among users/developers. It supports standard SQL and offers a host of features that simplify data management, such as automatic concurrency scaling, data sharing, and replication.
Furthermore, Snowflake's decoupled architecture of storage and compute resources allows developers to scale up or down based on their needs without worrying about infrastructure management. This flexibility, combined with Snowflake's support for various data types and semi-structured data, makes it a versatile tool for developers. Also, Snowflake provides extensive capabilities for programmatic access, automation, and customization. The Snowflake REST API allows managing all platform operations through scripting and programming. Snowflake also supports JDBC and ODBC drivers for connecting applications. For data integration, Snowflake provides native connectors to popular ETL/ELT tools. This enables building scalable data pipelines. On top of that, Snowflake provides comprehensive documentation, tutorials, and community support, making it easier for developers to get started and troubleshoot issues.
Amazon Redshift Developer Experience:
Amazon Redshift also offers a robust developer experience. It integrates seamlessly with the AWS ecosystem, making it an excellent choice for developers already working with AWS services. Redshift supports standard SQL and provides features like Redshift Spectrum, which allows querying of data directly from Amazon S3.
However, Amazon Redshift scalability is more manual compared to Snowflake, requiring developers to manage clusters and nodes. While Redshift Concurrency Scaling feature can automatically handle short-term increases in query load.
Like Snowflake, Amazon Redshift also provides a lot of extensive integration, extensive documentation, and community support.
9) Snowflake vs Redshift — Hybrid and Multi-Cloud Capabilities
Hybrid and multi-cloud capabilities are increasingly important in today's data landscape, as they provide flexibility, prevent vendor lock-in, and allow businesses to leverage the best features of different cloud providers.
Snowflake's Hybrid and Multi-Cloud Capabilities:
Snowflake is designed for multi-cloud data platform, supporting AWS, Google Cloud, and Microsoft Azure. This means that you can use Snowflake across different cloud providers, allowing you to leverage the unique benefits of each.
Moreover, Snowflake's architecture separates storage and compute resources, enabling you to store data in one cloud and process it in another. This flexibility is a significant advantage for users/businesses that want to avoid vendor lock-in or need to meet specific regulatory or business requirements.
In terms of hybrid capabilities, Snowflake does not natively support on-premises environments. However, it can integrate with on-premises data sources through data pipelines, allowing you to ingest and process data from your on-premises systems.
Amazon Redshift Hybrid and Multi-Cloud Capabilities:
Amazon Redshift is primarily an AWS service, and as such, it does not natively support multi-cloud deployments. This means that while you can use Redshift to process data from different sources, including other cloud providers, the Redshift service itself runs only on AWS.
In terms of hybrid capabilities, Redshift can integrate with on-premises data sources through AWS Direct Connect or a VPN. Redshift can also access on-premises databases using the database migration service (DMS), allowing you to move data to and from your on-premises systems.
10) Snowflake vs Redshift — Tale of Two Pricing Models
Last but certainly not least, Snowflake and Redshift differ significantly in their pricing models — which can have major cost efficiency implications.
Snowflake Pricing :
Snowflake uses a pay-per-second billing model for compute usage rather than hourly or monthly. Users are charged by the second for the processing power used. Snowflake also separates storage charges from compute. This pricing aligns closely with actual consumption patterns. Unused capacity isn’t paid for.
Check out this article to learn more in-depth about Snowflake pricing.
Redshift pricing :
On the other hand, Amazon Redshift pricing is determined by several key factors and offers flexible pricing options to meet different users needs. With Amazon Redshift, you only pay for the resources you consume, without any upfront costs or long-term commitments.
The main primary components that determine Redshift pricing are:
1) Compute Node Pricing
Amazon Redshift provides a variety of node types optimized for different performance levels and workload patterns. The main node types are:
- Dense Compute (DC) Nodes: Optimized for high performance analytics workloads. DC nodes utilize SSD-based local storage for fast I/O. Users can choose DC nodes based on data size and performance requirements. As data grows, additional nodes can be added to scale storage and compute.
- Dense Storage (DS) Nodes: Optimized for high storage density data warehouses. DS nodes allow independent scaling of compute and storage. DS nodes utilize HDD-based storage to provide higher storage capacity per node compared to DC nodes.
- RA3 Nodes: Provide the ability to independently scale compute and storage using managed storage. RA3 nodes utilize high performance SSDs for fast local caching and automatically scale capacity using managed storage in Amazon S3.
Customers can pay for nodes on an hourly, on-demand basis with no long-term commitments. On-demand pricing enables easy scaling up or down of cluster capacity. For steady state workloads, 1-year or 3-year Reserved Instances offer significant discounts compared to on-demand pricing.
On-demand hourly rates for node types vary based on the specific node size, ranging from $0.25 per hour for a dc2.large node to $4.8 per hour for a high-memory dc2.8xlarge node. Reserved Instances provide up to a 75% discount compared to equivalent on-demand nodes.
Check out all the pricing of dense compute dc2 and ra3:
| vCPU | Memory | I/O | Price | |
| Dense Compute DC2 | ||||
| dc2.large | 2 | 15 GiB | 0.60 GB/s | $0.25 per Hour |
| dc2.8xlarge | 32 | 244 GiB | 7.50 GB/s | $4.80 per Hour |
| RA3 with Redshift Managed Storage* | ||||
| ra3.xlplus | 4 | 32 GiB | 0.65 GB/s | $1.086 per Hour |
| ra3.4xlarge | 12 | 96 GiB | 2.00 GB/s | $3.26 per Hour |
| ra3.16xlarge | 48 | 384 GiB | 8.00 GB/s | $13.04 per Hour |
2) Managed Storage Pricing
Managed storage is exclusively used with RA3 nodes and billed at a per GB-month rate based on total data stored across the RA3 cluster. The same managed storage rate applies irrespective of whether data resides on high performance SSDs or lower-cost S3 storage. This allows auto-scaling of storage independently from compute.
Managed storage pricing is usage-based and customers only pay for resources consumed.
|
Redshift Managed Storage |
Price |
|
Storage/month |
$0.024 per GB |
For example, with 40TB of data stored for a month on RA3 nodes in the US East region, managed storage charges would be:
20 TB * 1024 GB/TB * $0.024 per GB / Month = $491.52Having managed storage paired with RA3 nodes enables cost-effective scaling of storage and compute.
3) Additional Capabilities
Beyond the base cluster pricing, users pay for additional capabilities only when used:
- Concurrency Scaling: This provides additional capacity automatically to handle spikes in demand. After free hourly credits are exhausted, users are charged per second for the duration that additional resources are consumed.
- Redshift Spectrum: AWS Redshift Spectrum allows you to run SQL queries directly in S3 without loading them into Redshift. You are charged based on the number of bytes scanned by it, rounded up to the nearest megabyte, with a 10MB minimum per query.
- Redshift Machine Learning: Users can create, train, and deploy machine learning models from within Redshift. However, after the free tier is over, charges based on the number of data rows/cells processed for model training are applied.
- Backup Storage: There is no charge for automated snapshots stored up to 35 days. However, users need to pay for manual snapshots and backups beyond 35 days, which are charged at the standard S3 rates.
- Data Transfer: There is no charge for transfers between Redshift and S3 in the same region, but standard AWS data transfer rates apply for other transfers.
- Reserved Instances: You can get significant discounts (up to 75%) by committing to 1 or 3-year terms, which is ideal for steady-state production workloads.
- AWS Redshift Serverless: This automatically scales capacity up and down based on workload needs and shuts down when inactive. You only have to pay per second for the capacity consumed.
- Managed Storage: With RA3 nodes, managed storage uses SSDs for fast local storage and S3 for longer-term storage. You pay a simple per-GB rate regardless of where the data resides.
In short, AWS Redshift provides flexible pricing options to only pay for resources used:
- No upfront costs or long term commitments
- Pay per hour for compute capacity with no commitments
- Scale storage independently as needed
- Pay-per-use pricing for features like Concurrency Scaling and Spectrum
- Save significantly with Reserved Instances and Serverless
- Control costs by monitoring resource usage and configuring backups
Redshift makes it easy to optimize price performance by scaling and paying only for resources your workload consumes.
Pricing Example Demo
Finally, let’s look at the simple example to illustrate Redshift’s pricing model based on a typical user workload.
A user runs a AWS Redshift cluster in US East region with:
- 5 RA3 nodes of compute (on-demand)
- 20TB of managed storage
- 50TB of data scanned by Redshift spectrum
- 10 hours of additional concurrency scaling clusters
The monthly cost of Amazon Redshift would be:
RA3 nodes (on-demand):
Per day:
5 nodes * $1.086/hour * 24 hour = $130.32Per month:
5 nodes * $1.086/hour * 720 (24 * 30) hour = $3909.6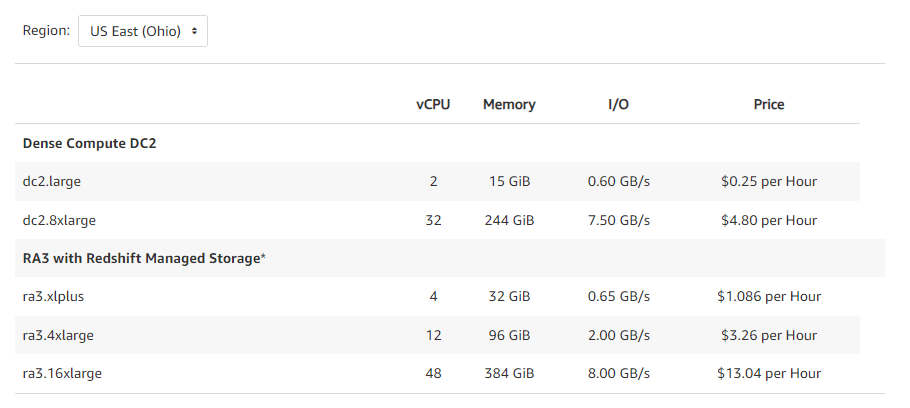
Amazon Redshift Managed Storage:
20TB * 1024 GB/TB * $0.0024 GB/month = $49.152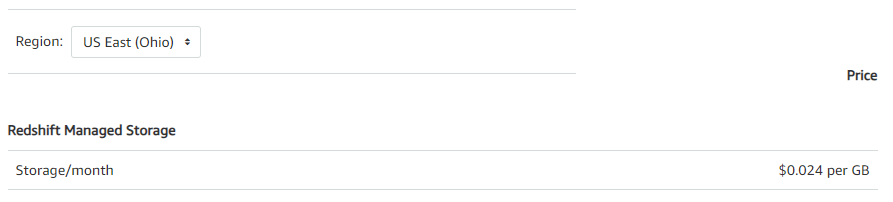
Amazon Redshift Spectrum:
50 TB scanned * $5/TB = $250
Concurrency Scaling:
10 hours * 5 nodes * $0.0003/sec * 3600 sec/hour = $54
Total Monthly cost = $4262.752
Learn more in-depth about Amazon Redshift pricing.
Save up to 30% on your Snowflake spend in a few minutes!


Conclusion
Snowflake and AWS Redshift both aim to provide powerful cloud data warehousing, but their differing architectures lead to distinct strengths and weaknesses. Choose Snowflake for its agility, high concurrency, and multi-cloud flexibility, especially if you have varying workloads. Opt for AWS Redshift if you need robust stability, large storage capacity, and deep AWS integration, particularly for consistent, high-volume workloads within the AWS ecosystem.
In this article, we have covered:
- What is Snowflake?
- What is Amazon Redshift?
- 10 Key Differences Between Snowflake vs AWS Redshift
- Snowflake vs AWS Redshift — Architecture Showdown
- Snowflake vs AWS Redshift — Battle of Query Performance
- Snowflake vs AWS Redshift — Scalability
- Snowflake vs AWS Redshift — Security Controls
- Snowflake vs AWS Redshift — Availability Zone Face-Off
- Snowflake vs AWS Redshift — Cloud Platform and Partner Integrations
- Snowflake vs AWS Redshift — Time Travel, Backup and Restore Capabilities
- Snowflake vs AWS Redshift — Developer Experience
- Snowflake vs AWS Redshift — Hybrid and Multi-Cloud Capabilities
- Snowflake vs AWS Redshift — Tale of Two Pricing Models
...and so much more!
FAQs
Which is better, Redshift or Snowflake?
For semi-structured data, Snowflake provides faster query performance. But Redshift can be faster for SQL analytics on extremely large structured datasets. Overall, performance is comparable for many workloads.
Is Snowflake more scalable than Redshift?
Yes, Snowflake can scale compute and storage separately and automatically. Redshift requires manually resizing clusters with fixed resource ratios.
Which offers higher availability - Snowflake vs Redshift?
Snowflake replicates seamlessly across availability zones for automatic failover, whereas Redshift automatically takes snapshots of your data at regular intervals and stores them in Amazon S3.
Can Snowflake work with multiple cloud providers?
Yes, Snowflake is available on AWS, Google Cloud, and Azure, allowing seamless use across different cloud platforms.
Does Snowflake integrate with AWS like Redshift?
Snowflake integrates with AWS, Azure, and GCP while Redshift is designed solely for AWS. Snowflake enables multi-cloud capabilities.
Which is more secure - Snowflake vs Redshift?
Both platforms offer robust security. Snowflake has an edge with its native role-based access control and secure data sharing capabilities.
Which solution is best for real-time analytics - Snowflake vs Redshift?
Snowflake would be better suited for real-time analytics due to its flexible scaling, semi-structured data support, and pay-per-usage pricing.
Which is better, Redshift or Snowflake?
It depends on your needs. Choose Snowflake for agility, high concurrency, and multi-cloud flexibility. Choose Redshift for stability, large storage capacity, and deep AWS integration.
How is Snowflake better than AWS?
Snowflake offers independent compute-storage scaling, higher concurrency without resource contention, granular access controls, and true multi-cloud flexibility across AWS, Google Cloud, and Azure.
How does Amazon Redshift handle backups and restores?
Redshift automatically takes snapshots stored in S3, which can be used to restore data to any point within the snapshot retention period.
Why migrate from Redshift to Snowflake?
For better scalability with varying workloads, higher concurrency needs, more flexible data sharing capabilities, or multi-cloud deployment requirements.
What are the disadvantages of Snowflake?
- Performance can suffer with large data volumes, leading to slower queries if not optimized.
- Scalability can lead to high costs due to a lack of strict data constraints.
- Limited administrative control prevents fine-tuning of some features.
- Often requires third-party integrations, adding complexity to setup.
- Users may face challenges with bulk data loading using Snowpipe.
- Automation mainly focuses on administrative tasks rather than data management.
- Overall expenses can be high, especially in large deployments.
- Complex configurations can require a steep learning curve.
- Not optimized for real-time data processing.









