


























Snowflake's innovative storage format and cloud data warehousing approach have propelled its popularity among users. The utilization of micro-partitions for Snowflake query optimization, as discussed in our previous article, showcases Snowflake's capability to minimize scanned data volume, leading to quicker query execution and lower costs. Impressive, isn't it? But, to further boost query performance, we can harness the power of effective clustering. Clustering groups frequently accessed data, allowing Snowflake to skip scanning entire micro-partitions during query execution.
In this article, we'll dive into the basics of clustering, how it works with Snowflake micro-partitions, how to choose effective cluster keys, and a hands-on demo to illustrate the benefits of clustering in action.
But before we get into snowflake clustering, let's first understand what snowflake micro-partitions are.
What are Snowflake micro-partitions?
Snowflake micro-partitions refer to the small, self-contained units into which data is divided and stored within the Snowflake data warehouse. These Snowflake micro-partitions are created automatically by Snowflake upon data ingestion and are designed to optimize query performance and storage efficiency.
Each micro-partition in Snowflake contains a specific range of rows and is organized in a columnar format. Typically ranging in size from 50 MB to 500 MB of uncompressed data, these micro-partitions enable parallel processing and selective scanning of only the relevant data during query execution.
Check out this article, where we covered all you need to know about Snowflake micro-partitions.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

What does Pruning do in Snowflake?
Query pruning is a Snowflake query optimization technique that involves reducing the amount of data that must be scanned during query execution. It accomplishes this by utilizing the power of the Snowflake micro-partitions that make up a table to determine which ones contain relevant data and which ones can be skipped.
So, when you run a query in Snowflake, it gets split up into little chunks and distributed across multiple compute nodes. Each of these tasks is responsible for processing a specific set of data, which is determined based on the query's filter predicates. Using statistics on the micro-partitions, Snowflake can skip over partitions that do not contain relevant data and only process the ones that do. This significantly reduces the amount of data that needs to be scanned, resulting in faster and more efficient queries.
For example, consider a scenario where the max and min values of a date column are stored in the metadata of the partitions. If a certain micro-partition has a max date of "2012-01-01" and the query only needs data after "2020-01-01", this entire micro-partition can be skipped or pruned.
What is Snowflake Clustering?
Snowflake clustering is a technique employed in Snowflake tables to group related rows together within the same micro-partition, thereby enhancing query performance for accessing these rows. By organizing the data in a clustered manner, Snowflake can avoid scanning unnecessary micro-partitions during query execution.
When a table is clustered in Snowflake, the system utilizes metadata associated with each micro-partition to optimize the query process. This metadata helps minimize the number of files that need to be scanned, reducing the amount of data accessed and processed. As a result, queries can be executed more quickly due to the reduced I/O operations and improved data locality.
Snowflake clustering offers several benefits. It improves the efficiency of query execution by selectively scanning only the relevant Snowflake micro-partitions, avoiding the need to process irrelevant data. This optimization reduces the amount of disk I/O and network transfer, resulting in faster query response times.
To achieve effective Snowflake clustering, it is crucial to choose appropriate Snowflake clustering keys that align with the data access patterns and query requirements. By clustering the data based on relevant columns, Snowflake ensures that related rows are stored together, maximizing the benefits of reduced data scanning and improved query performance.
What exactly are Snowflake clustering keys?
Snowflake Clustering keys are designated columns or expressions that determine the organization and sorting of data within a clustered table. You can specify one or more columns as clustering keys when creating or altering a table in Snowflake.
For clustered tables, Snowflake uses the values in the clustering key columns to assign rows to micro-partitions during data loading. This process aims to maximize the co-location of similar values within the same micro-partition.
Snowflake Automatic Clustering service provided by Snowflake seamlessly and continuously manages all reclustering operations for clustered tables, eliminating the need for manual monitoring and maintenance tasks related to reclustering.
Snowflake Automatic Clustering feature provides a wide range of benefits. For detailed information on these benefits, please refer to the official Snowflake documentation
Note: If you consistently insert data based on the clustering key, there is no need to explicitly designate it as the clustering key or activate auto-clustering. Also, keep in mind that Snowflake automatic clustering can incur substantial costs; therefore, it is advisable to thoroughly evaluate the trade-offs before enabling it.
Also, remember that Snowflake clustering keys are defined at the table level and can be specified or modified using the Snowflake SQL syntax. The choice of Snowflake clustering keys should be based on the specific data access patterns and query requirements to achieve optimal performance improvements.
How Snowflake Clustering Works?
When data is loaded into Snowflake, it is initially stored in a "load table." The load table is a temporary table used for staging data before it's loaded into the actual table. Once the data is staged in the load table, Snowflake automatically reorganizes it into micro-partitions based on the Snowflake clustering keys defined for the table.
How to Create Snowflake Clustering Keys?
There are a couple of ways to implement “Clustering keys”. You can define a clustering key at the time of table creation using the CREATE TABLE command. Alternatively, you can use the ALTER command to specify a clustering key later on.
To cluster a table based on a particular column, you can use the following ALTER command:
ALTER TABLE some_table_name CLUSTER BY (clustering_column_name);It's also possible to cluster a table based on an expression that uses a column. Here's an example using the LEFT function to cluster by the first two characters of a column:
ALTER TABLE some_table_name CLUSTER BY (LEFT(clustering_column_name, 2));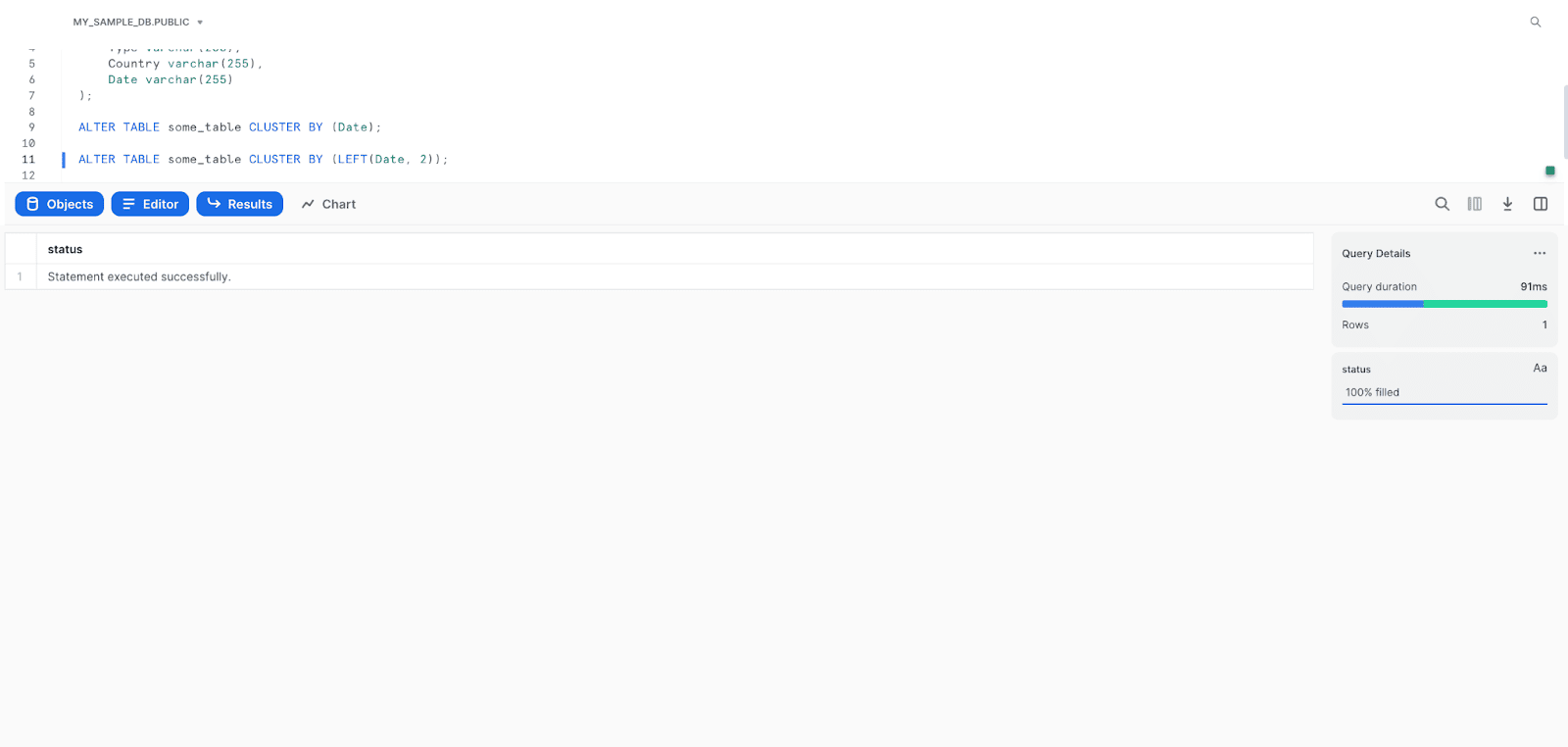
For more on how Snowflake clustering actually works, check out this comprehensive video.
Demonstration of Snowflake Clustering in Action
To create a table with Snowflake clustering enabled, the clustering keys must be configured during the create/alter of the table. When data is inserted into an existing table, the micro partitions are split based on the volume of data and in the order it was received regardless of the clustering configuration on the table. However, if a new table is created via (CREATE TABLE … AS SELECT) and has cluster keys, it will automatically be clustered.
To demonstrate how Snowflake clustering works, we will first create a table with Snowflake clustering keys and insert random data into it. Then, we will execute a query to retrieve all data for a specific age and examine the Query Profile Statistics. This will help us observe the query behavior before clustering is applied.
Let's go through the steps:
Step 1: Create the table and insert random data:
CREATE DATABASE my_database;
USE DATABASE my_database;
CREATE SCHEMA my_schema;
USE SCHEMA my_schema;
CREATE OR REPLACE TABLE cluster_demo_table (
id NUMBER(10,0),
name VARCHAR(100),
age NUMBER(3,0),
country VARCHAR(50)
)
CLUSTER BY (age);
INSERT INTO cluster_demo_table
SELECT
seq4() AS id,
randstr(20, random()) AS name,
uniform(1, 100, random()) AS age,
randstr(10, random()) AS country
FROM table(generator(rowcount => 1000000));As you can see, in this step, we created a table named cluster_demo_table with Snowflake clustering enabled on the age column, and then we inserted 1 million rows of random data into the table, ensuring that multiple Snowflake micro-partitions were created.
Step 2: Perform a query to retrieve data for a specific age:
SELECT * FROM example_table WHERE age = 25;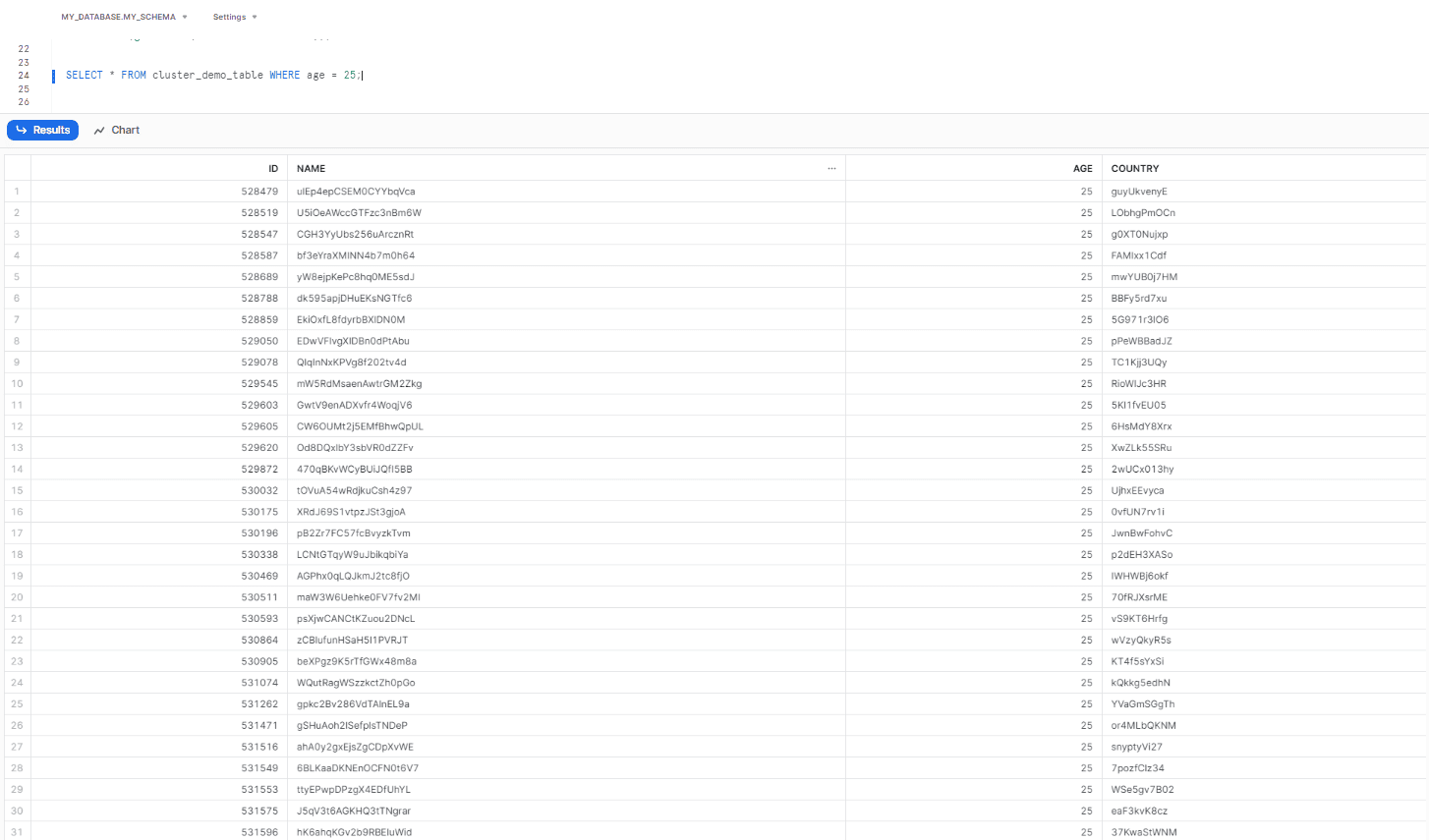
If we fire the query above, it will retrieve all data for the age of 25. But, at this stage, since the data is not yet efficiently clustered, we expect the query to perform a full table scan.
Step 3: Open the Query Profile Statistics
Now, examine the Query Profile Statistics to observe the query execution details and performance, which will help to determine whether the query is scanning the entire table or utilizing clustering optimizations.
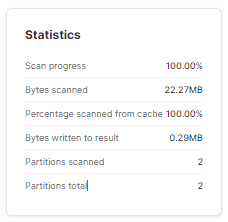
As you can see, there are currently 2 micro-partitions in the table, and both of 'em were scanned to retrieve the query results.
Automatic Clustering in Snowflake
Automatic Clustering is a Snowflake service that automatically manages the reclustering of clustered tables. Reclustering is the process of rearranging the data in a clustered table so that rows with similar values are stored together. This can improve the performance of queries that access the table by the clustering key.
The benefits of Snowflake Automatic Clustering include eliminating the need for manual reclustering and providing full control over the reclustering process. It is transparent and non-blocking, allowing DML statements (inserts, updates, deletes) to be executed on the tables while they are being reclustered, which ensures uninterrupted data operations while optimizing the table's data arrangement for improved performance.
For detailed information on several other benefits of automatic clustering, please refer to the official Snowflake documentation
Credit Usage for Snowflake Automatic Clustering
Automatic Clustering consumes Snowflake credits but does not require you to provide a dedicated virtual warehouse. Instead, Snowflake internally manages and achieves efficient resource utilization for reclustering the tables.
Your account is billed for the actual credits consumed by the Snowflake automatic clustering operations on your clustered tables.
The amount of credits consumed by Snowflake automatic clustering depends on the size of the table and the number of rows that are reclustered. For example, a table with 100 million rows that is reclustered will consume more credits than a table with 1 million rows that is reclustered.
When enabling or resuming Snowflake Automatic Clustering on a clustered table, if it has been a while since the last reclustering, you may experience reclustering activity and corresponding credit charges as Snowflake brings the table to an optimally-clustered state. Once the table is optimally-clustered, the reclustering activity decreases.
Also, note that defining a clustering key on an existing table or changing the clustering key on a clustered table can trigger reclustering and credit charges.
How to Avoid Unexpected Credit Usage for Snowflake Automatic Clustering?
To avoid unexpected credit charges, it is recommended to start with a few selected tables and monitor the credit charges associated with keeping the table well-clustered as DML is performed.
How to Enable and Suspend Snowflake Automatic Clustering for a Table?
To enable Snowflake Automatic Clustering for a table, simply define a clustering key for the table. No additional tasks are usually required.
Note: If you clone a table using the CREATE TABLE CLONE command from a source table that already has Snowflake clustering keys, the new table will have Snowflake Automatic Clustering suspended by default, even if the source table's Automatic Clustering is not suspended.
Source: Snowflake documentation
How to Suspend and Resume Snowflake Automatic Clustering for a Table?
To temporarily suspend Snowflake Automatic Clustering for a table, you can use the ALTER TABLE command with a SUSPEND RECLUSTER clause:
ALTER TABLE cluster_demo_table_sort
SUSPEND RECLUSTER;If you want to resume Snowflake Automatic Clustering for a clustered table, you can use the ALTER TABLE command with a RESUME RECLUSTER clause as shown below:
ALTER TABLE cluster_demo_table_sort
RESUME RECLUSTER;How to Check Snowflake Automatic Clustering is enabled for a Table?
You can use the SHOW TABLES command to check whether Snowflake Automatic Clustering is enabled for a specific table:
SHOW TABLES LIKE 'cluster_demo_table_sort';
After Snowflake automatic clustering has been applied to this table, you will notice that the query will only scan one partition out of the original two.
BUT, if you want to see the result quicker or manually, you can modify the table creation process to sort the data based on the relevant identifier.
Note: This particular manual modification is for demo purposes only and should be approached with CAUTION when working with large datasets.
Step 4: Create a new table and insert same random data:
CREATE OR REPLACE TABLE cluster_demo_table_sort (
id NUMBER(10,0),
name VARCHAR(100),
age NUMBER(3,0),
country VARCHAR(50)
)
CLUSTER BY (age);
INSERT INTO cluster_demo_table_sort
SELECT
seq4() AS id,
randstr(20, random()) AS name,
uniform(1, 100, random()) AS age,
randstr(10, random()) AS country
FROM table(generator(rowcount => 1000000))
ORDER BY age; -- Manually sorting the data before insertingStep 5: Perform a query to retrieve data for a specific age:
SELECT * FROM cluster_demo_table_sort WHERE age = 25;
Step 6: Open the query profile statistics
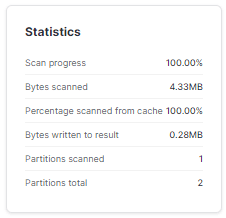
As you can see, it can be observed that the query is able to eliminate most of the data as the data for the age is present in only a few micro-partitions—in this case, only one.
Snowflake can eliminate most of the data in a query because it stores metadata about each micro-partition. This particular metadata is used to determine which micro-partitions contain the data that is relevant to the query. In this case, the data for the age only existed in a small number of micro-partitions, meaning that the query only needs to scan those micro-partitions, which is much faster than having to scan the entire table.
In short, when micropartitions have random data across a large span of values, it is not possible to eliminate any of them during query execution, which means that the query will need to scan all of the micropartitions, which can take a long time.
Why is Snowflake Clustering Important?
Clustering is a critical aspect of Snowflake workloads. Many queries run frequently on these clusters, and they often have similar structures, filtering, and grouping by the same fields. For instance, queries that frequently filter data based on date ranges can be clustered by date and faster query execution. Clustering data effectively leads to query pruning, reducing the need for larger warehouses, and ultimately resulting in credit consumption savings.
While it's possible to use a large number of cores to query a vast dataset sitting in a blob store, this approach merely involves throwing money at the query. Such an approach may be acceptable for research or ad-hoc queries that aren't worth the time and effort to optimize. However, it's not the best approach for expected, frequent queries that can be optimized for better performance.
Therefore, clustering is crucial for optimizing query performance in Snowflake workloads. By clustering data effectively, queries can be pruned, resulting in faster execution times, reduced need for larger warehouses, and credit savings.
How to Choose Cluster Keys?
Choosing the right cluster keys is essential in optimizing performance and reducing costs in Snowflake.
When choosing cluster keys, it is important to consider the following factors:
- Choose columns that are frequently used in selective filters.
- Consider columns frequently used in join predicates.
- If you typically filter queries by two dimensions, then cluster on both columns.
- Choose columns with a large enough number of distinct values to enable effective pruning.
- Choose columns with a small enough number of distinct values to allow Snowflake to effectively group rows in the same micro-partitions. Also, suppose you want to use a column with very high cardinality as a clustering key. In that case, Snowflake suggests defining the key as an expression on the column instead of directly on the column itself. This approach helps reduce the number of distinct values associated with the clustering key, thereby enhancing query performance.
- When clustering on a text field, the cluster key metadata tracks only the first several bytes (typically 5 or 6 bytes).
- In some cases, clustering on columns used in GROUP BY or ORDER BY clauses can be helpful. However, clustering on these columns is usually less helpful than clustering on columns that are heavily used in filter or JOIN operations.
Source: Snowflake documentation
Some examples of good and bad cluster keys:
1) Good cluster keys:
- Date column in a fact table
- Customer ID column in a customer table
- Product ID column in a product table
2) Bad cluster keys:
- Gender column in a customer table
- State column in a customer table
- Zip code column in a customer table
In rare cases where there are multiple query patterns with different filter criteria, materialization may be necessary to support all query patterns. However, this should only be done when there is a significant number of queries with these predicates. Otherwise, it may be more cost-effective to use larger warehouses for the queries.
Also, the effectiveness of table clustering in Snowflake is indicated by the clustering depth; the smaller the average depth, the better clustered the table is with regards to the specified columns.
Clustering depth can be used for a variety of purposes, including:
- Monitoring the clustering “health” of a large table, particularly over time as DML is performed on the table.
- Determining whether a large table would benefit from explicitly defining a clustering key.
Note: Clustering depth doesn't provide an exact measure of the quality of table clustering.
Source: Snowflake Documentation
The best indicator of good clustering is the performance of queries. If queries perform well, it's a strong indication that the table is well-clustered. However, if query performance declines over time, it's likely that the table is no longer effectively clustered and could benefit from being re-clustered.
So how can we calculate or obtain this information in-dpeth? Thankfully, Snowflake has provided two useful functions for this purpose:
The function SYSTEM$CLUSTERING_DEPTH figures out the average depth of the table based on the columns that are given or the clustering key that is set up for the table.The average depth of a table is always equal to or greater than 1, whereas the function SYSTEM$CLUSTERING_INFORMATION returns the clustering information for a table based on the specified columns or the table's defined clustering key.
When to choose Snowflake clustering and when not to?
When to Choose Snowflake Clustering:
- If the table contains a large number of micro-partitions (meaning that the table contains multiple terabytes of data)
- If you have a large dataset that is frequently queried and you want to improve query performance.
- If the table is queried frequently and updated infrequently.
- If you have specific fields that are often filtered on or grouped by in queries.
- If you have time-series data and want to cluster it by date to improve query performance.
When Not to Choose Snowflake Clustering:
- If you have a small dataset that is not frequently queried, clustering may not provide much benefit.
- If you have a dataset with low cardinality (few distinct values), clustering may not be very effective.
- If you have a dataset that is already partitioned in a way that supports efficient querying, clustering may not be necessary.
- If you have ad hoc or exploratory queries that are not frequently executed, the effort of clustering may not be worth the benefit.
- If a table experiences frequent DML operations, clustering may not be the best choice, as it increases its cost.
Save up to 30% on your Snowflake spend in a few minutes!


Conclusion
Snowflake provides businesses with a range of optimization strategies to improve data processing and query performance. Snowflake clustering, one of these strategies, has become increasingly popular for businesses looking to navigate vast data sets and make well-informed decisions quickly.
Here is the summary of what we covered in this article:
- What is Snowflake clustering and why is it important?
- The basics of Snowflake micro-partitions.
- A full hands-on demo of Snowflake clustering in action.
- Importance of Snowflake clustering in reducing costs and improving query performance.
- In-depth understanding of "cluster-keys".
- Snowflake Automatic Clustering hands-on demo.
- How to choose "cluster-keys" based on the shape of the data and common queries.
- When to choose clustering and when not to do it.
Perhaps you can avoid future hassle (and expense) with the help of snowflake clustering. Hence, make sure you effectively use Snowflake clustering if you want faster query times and a happier budget. It could give you a leg up on the competition by helping you save money and speed up your queries.
FAQs
What does pruning do in Snowflake?
Pruning is a query optimization technique in Snowflake that reduces the amount of data scanned during query execution. It utilizes metadata on micro-partitions to skip irrelevant partitions, improving query performance.
When should I use clustering in Snowflake?
Clustering should be considered if you care about performance and cost optimization. It is especially beneficial for tables with multiple terabytes of data, but can also provide benefits for tables starting at hundreds of megabytes.
What is the difference between compute cluster and warehouse in Snowflake?
A cluster in Snowflake is a collection of one or more virtual machines (VMs) that are connected together in a mesh topology. A warehouse is a logical unit of compute and storage resources that is composed of one or more clusters.
Does Snowflake automatically cluster tables?
Yes, Snowflake provides Automatic Clustering, a service that manages reclustering of clustered tables seamlessly and continuously. However, reclustering does not immediately start after defining a clustered table. Snowflake only performs reclustering if it determines that it will provide benefits for the table.









