












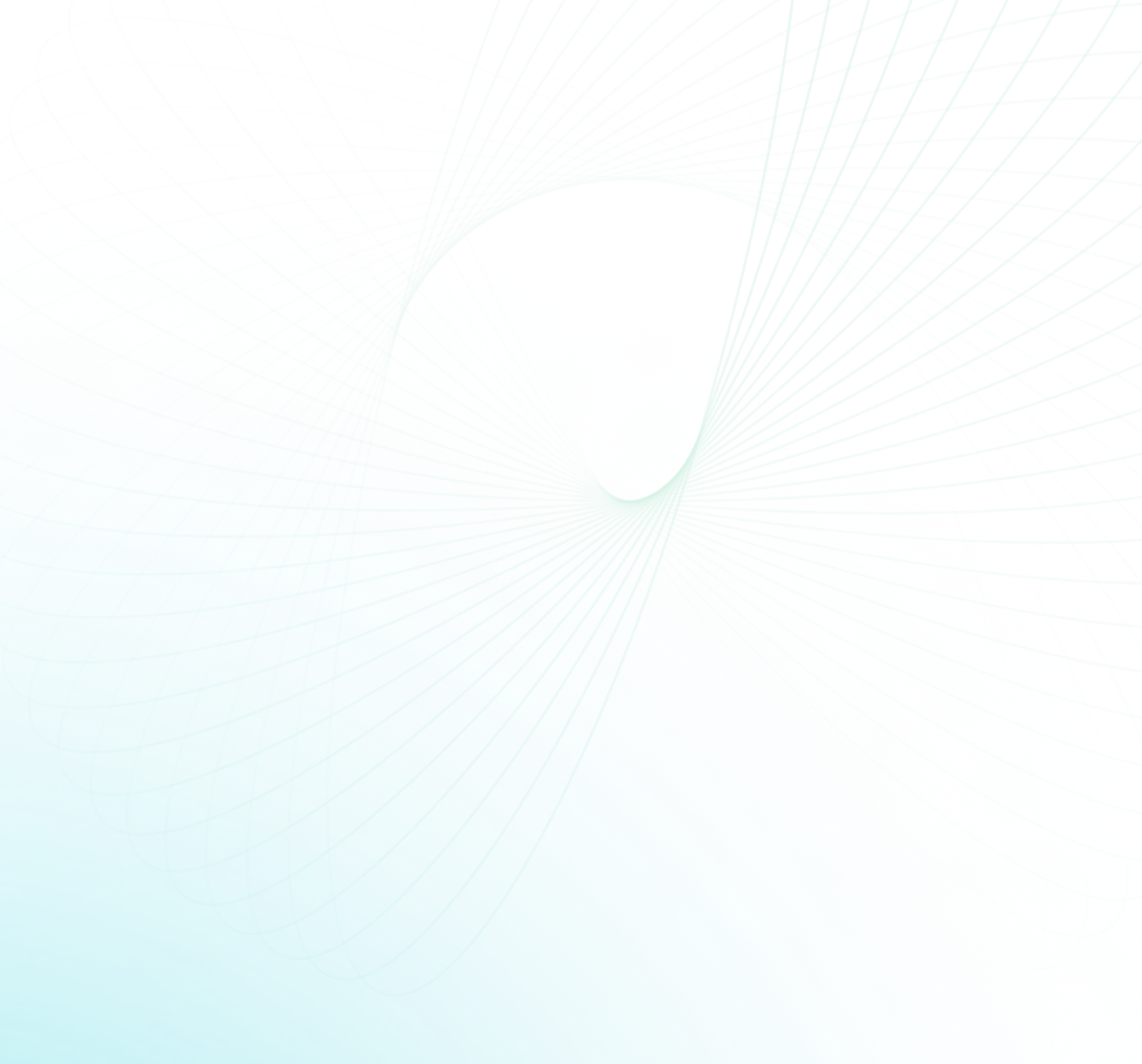
















Snowflake and Databricks are two leading cloud data platforms. Both of ‘em aim to simplify working with data in the cloud, but they go about it in very different ways. So, which platform comes out on top? Snowflake has established itself as a best-in-class cloud data warehouse, providing instant elasticity and separation of storage and compute. Databricks, on the other hand, began as a cloud service for Apache Spark, has developed its "Lakehouse" concept with Delta Lake technology, providing a unified solution for data engineering, analytics, and machine learnin capabilities.
In this article, we will compare Databricks vs Snowflake (🧱 vs ❄️) across 5 different key criteria—architecture, performance, integration/ecosystem, security, machine learning capabilities and so much more!! We'll highlight the unique capabilities and use cases of each platform, and outline the core pros and cons to consider. Additionally, investing in database training is essential for users to effectively leverage the full potential of these platforms. Proper training ensures that users can maximize the benefits of Snowflake’s and Databricks’ advanced features.
Let's see how these two data titans stack up!
Databricks vs Snowflake—Comparing the Cloud Data Titans
If you're in a hurry, here's a quick high-level summary of the key differences between Databricks vs Snowflake !
What is Databricks?
Databricks—The Data Lakehouse Pioneer—is a cloud-based data lakehouse platform founded in 2013 that today offers a unified analytics platform for data and AI. Its origins trace back to the University of California, Berkeley, where its creators developed tools such as Apache Spark, Delta Lake and MlFlow. Databricks is a unified analytics platform that combines the power of Apache Spark, Delta Lake, and MLFlow with cloud-native infrastructure—a One-Stop Shop—to simplify the end-to-end analytics process. It is a managed service that provides a single platform for data engineering, DS (Data Science), and machine learning tasks—Combining the Key Capabilities Needed for Modern Data Analytics.
TL;DR: Databricks is a cloud data platform that implements the "data lakehouse" concept to combine the benefits of data warehouses and data lakes.

The platform offers:
- Robust Analytics Platform: Databricks provides a unified workspace for data engineering, data science, and AI, enabling collaboration between teams.
- Performance + Scalability: Leveraging Apache Spark, Databricks offers high performance and scalability for big data analytics and AI workloads.
- Interactive Workspace + Notebooks: Databricks provides interactive workspace that supports Python, R, Scala, SQL, and notebooks for exploring and visualizing data.
- Data pipelines: Users can build data ingestion, transformation, and machine learning pipelines.
- AI/Machine learning: It provides libraries and tools to build, train and deploy machine learning models at scale.
- ML Lifecycle Management: Databricks manages the entire machine learning lifecycle, including experiment tracking, model packaging, and model deployment, using MLflow and other capabilities.
- Delta Lake: Delta Lake brings ACID transactions, data quality enforcement, and other reliability features to data lakes stored on cloud object stores like AWS S3.
- Rich Visualizations: Rich visualizations and dashboards can be built on top of data for insights.
- Robust Security: Databricks provides enterprise-grade security, including access controls, encryption, auditing and more!!
Databricks is primarily used for data engineering workflows and large-scale machine learning. Many big businesses/organizations use it for ETL, data preparation, data science, and ML/AI initiatives.
Save up to 50% on your Databricks spend in a few minutes!


What is Snowflake?
Snowflake is a cloud-based data warehouse as a service that utilizes a unique architecture to provide businesses/organizations massive scalability and flexibility when managing and analyzing their data.

The other major perk is Snowflake's ability to securely share data, making it a top choice for cloud analytics and business intelligence tools. The company is growing like crazy too. Also, with capabilities like zero-copy cloning and time travel, Snowflake offers features not found in typical on-premise data warehouses.
For an in-depth look at Snowflake's full capabilities—including the fundamentals of Snowflake architecture, security, and key features—check out this article. It covers everything you need to know about this innovative data warehouse.
Save up to 30% on your Snowflake spend in a few minutes!


Now let’s see how they compare across 5 key features:
What Is the Difference Between Snowflake and Databricks?
Databricks vs Snowflake — which data platform reigns supreme? Let's cut through the weeds and break down their key features and differences.
1). Databricks vs Snowflake — Architecture Comparison
Databricks vs Snowflake, two cloud platforms: one renowned for performance and simplicity, the other for an enterprise-grade experience.
The best choice varies based on individual needs, and together, they push data warehouse innovation. Now, let's explore their architectural differences.
Snowflake Architecture
Snowflake uses a unique hybrid architecture combining elements of shared disk and shared nothing architectures. In the storage layer, data resides in centralized cloud storage accessible to all compute nodes, like a shared disk. However, the compute layer uses independent Virtual Warehouses that process queries in parallel, like a shared nothing architecture.
The Snowflake architecture has three layers:
- Storage Layer: Optimizes data storage and access. Data loaded into Snowflake is converted into a compressed, columnar format for faster queries and lower storage needs. The cloud-based storage is fully managed by Snowflake.
- Compute Layer: Uses scalable Virtual Warehouses to execute queries in parallel. Virtual Warehouses are independent MPP compute clusters provisioned on-demand by Snowflake. Their independence ensures optimal performance.
- Cloud Services Layer: Handles authentication, infrastructure, metadata, query optimization, access control. Runs on compute instances provisioned by Snowflake.
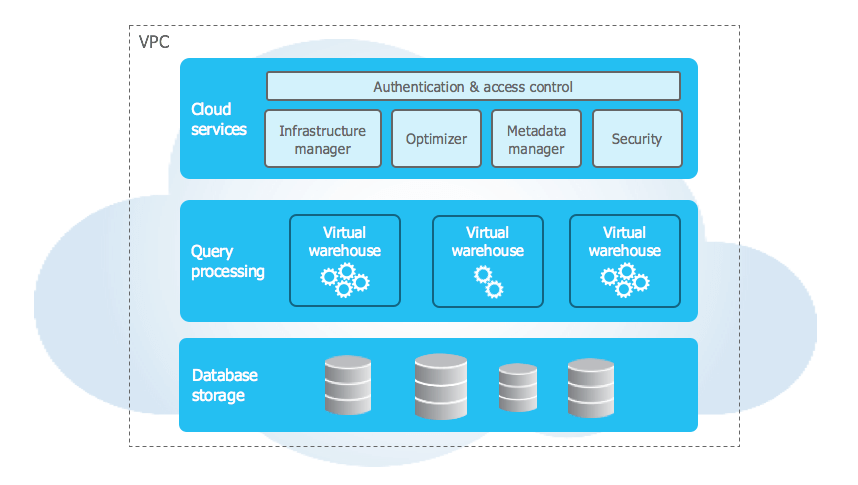
If you want to learn more in-depth about the capabilities and architecture behind Snowflake, check out this in-depth article.
Databricks Data Lakehouse Architecture
Databricks is a unified data analytics platform that provides a comprehensive solution for data engineering, data science, machine learning, and analytics. The Databricks architecture is designed to handle big data workloads, and it is built on top of Apache Spark, a powerful open-source processing engine.
The Databricks architecture is layered and integrates several components:
- Delta Lake: Delta Lake is Databricks' optimized storage layer that enables ACID (Atomicity, Consistency, Isolation, and Durability) transactions, scalable metadata, and unified streaming/batch processing on data lake storage. Delta Lake extends Parquet data files with a transaction log to provide ACID capabilities on top of cloud object stores like S3. Metadata operations are made highly scalable through log-structured metadata handling. Delta Lake is fully compatible with Apache Spark APIs. It tightly integrates with Structured Streaming to enable using the same data copy for both batch and streaming workloads. This allows incremental processing at scale, meaning it can handle large volumes of data and diverse data types, while maintaining data integrity and consistency.
- Delta Engine: This is an optimized query engine designed for efficient processing of data stored in the Delta Lake. It leverages advanced techniques such as caching, indexing, and query optimization to provide high-performance SQL execution on data lakes. This allows for faster data retrieval and analysis, which is crucial for data-intensive applications.
- Built-in Tools: Databricks includes several built-in tools to support Data Science, data engineering, Business Intelligence (BI) Reporting, Machine Learning Operations (MLOps) and moree!! These tools are designed to work seamlessly with the data stored in the Delta Lake and processed by the Delta Engine, providing a comprehensive suite of capabilities for data analysis, visualization, model training, and deployment.
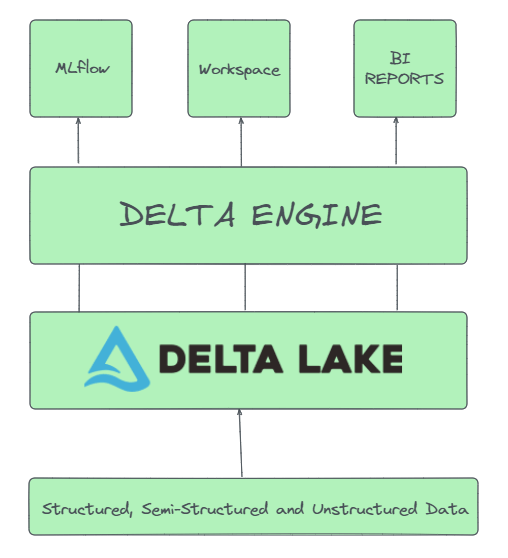
The above components are accessed from a single 'Workspace' user interface (UI) that can be hosted on the cloud of your choice. This provides a unified platform for data engineers, data scientists, and business analysts to collaborate and work with data.
Although architectures can vary depending on custom configurations, the following section represents the most common structure and flow of data for Databricks in AWS environments.
Databricks Data Lakehouse Architecture on AWS
Databricks on AWS has a split architecture consisting of a control plane and a data plane.
- Control Plane: The Control Plane is responsible for managing and orchestrating the Databricks workspace, which includes user interfaces, APIs, and the job scheduler. It handles user authentication, access control, workspace setup, job scheduling, and cluster management. The Control Plane is hosted and managed by Databricks in a multi-tenant environment, which means that it is shared among multiple Databricks users.
- Data Plane: The Data Plane is where the actual data processing occurs. It consists of Databricks clusters, which are groups of cloud resources that run data processing tasks. Each cluster runs an instance of the Databricks Runtime, which includes Apache Spark and other components optimized for Databricks. The Data Plane is hosted in the user’s cloud account, which means that the data never leaves the user’s environment. There are two types of data planes:
- Classic Data Plane: Used for notebooks, jobs, and Classic SQL warehouses.
- Serverless Data Plane: Used for Serverless SQL warehouses.
Communication between the planes is secured using SSH tunnels. The Control Plane sends commands to start/stop clusters and run jobs. The Data Plane sends back results and status updates.
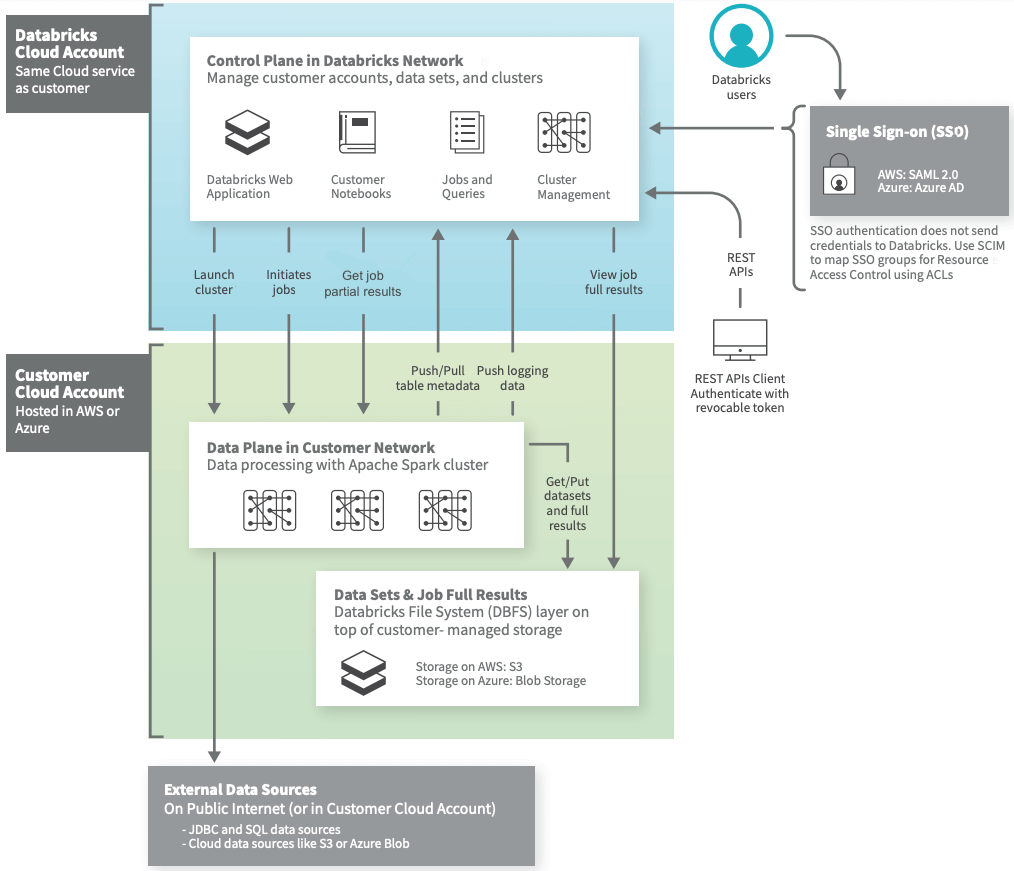
Key components:
- Connectors: Allow clusters to connect to external data sources outside the AWS or Azure account for data ingestion and storage.
- Data Lake: User data at rest resides in object storage (e.g. S3 or Azure blob) in their AWS/Azure account.
- Job Results: Output of jobs is stored in the user's cloud storage.
- Notebooks: Interactive notebook results are split between control plane (for UI display) and the user's cloud storage.
E2 Architecture:
Databricks released the E2 version of the platform in September 2020, and it provides the following features:
- Multi-workspace accounts: Multiple workspaces per account.
- Customer-managed VPCs: Workspaces can be created in the user's own VPC.
- Secure cluster connectivity: Nodes only have private IP addresses.
- Customer-managed keys: Encrypt control plane data with customer KMS keys.
Note: E2 architecture provides more security, scalability, and user control. New accounts are typically created on E2.
Cluster Types
Databricks supports two cluster types:
- Interactive/All-purpose clusters: These clusters are used for interactive analysis and are shared by all workspace users.
- Jobs clusters: These clusters are created for a specific job and terminated after the job is complete. They isolate workloads and can be configured to meet the specific needs of the job.
2). Databricks vs Snowflake — Battle of Performance and Scalability
Now that we've covered the architecture and components of Snowflake and Databricks, fast query performance and scalability are critical requirements for any data warehouse. Snowflake and Databricks leverage different architectures to deliver optimal speeds.
Let's compare the performance and scalability of these two powerful platforms to find which one has the competitive advantage.
Databricks vs Snowflake — Battle of Scalability
Snowflake Scalability
At its core, Snowflake's architecture is designed for scalability. It uses a shared disk and shared nothing architecture with separate storage and compute resources. This decoupled design allows Snowflake to scale these resources independently as your data and query loads change.
For storage, Snowflake can easily scale its data warehouse by adding more storage nodes, allowing you to accommodate growth in your data volume without affecting your query performance.
For compute, Snowflake offers virtual warehouses that can be scaled up or down independently of storage, which gives you the flexibility to right-size your query capacity based on your current workload.
While this provides easy scalability, Snowflake has some constraints:
- Snowflake relies on the underlying cloud infrastructure (like AWS, GCP and Azure). So any performance or reliability issues from the cloud provider will impact Snowflake.
- Users are limited to choosing from fixed warehouse sizes, ranging from X-Small to 6X-Large. Users can't manually customize the CPU, RAM or storage at a granular level, which can lead to over or under provisioning if your workloads don't fit the predefined sizes.
- Users cannot dynamically resize nodes within a warehouse. They can only add more warehouses to scale out.
- Once large amounts of data are loaded into Snowflake, it can be challenging to move ‘em elsewhere due to egress fees and bandwidth limits, which effectively create lock-in.
- Snowflake limits clusters to a maximum of 128 nodes.
Databricks Scalability
Databricks allows high levels of customization and control when scaling clusters. Users can choose different node types, sizes and quantities to optimize for their specific workloads. This provides flexibility to tailor clusters as needed. BUT, there are practical limits to scaling based on available infrastructure and costs. And managing Databricks clusters does require some technical expertise to optimize node configurations.
While Databricks enables flexible scaling options, cluster creation and management does involve some overhead. Scaling is customizable but not entirely seamless.
In short; Databricks' scaling model emphasizes flexibility and customization, though this does come at the cost of added complexity and management overhead.
Databricks vs Snowflake — Battle of Performance
Snowflake Performance
Snowflake is optimized for high performance SQL analytics workloads. Its columnar storage, clustering, caching, and optimizations provide excellent performance on concurrent queries over structured data. But performance drops on semi-structured data. Overall, Snowflake delivers push-button analytics performance without much tuning.
Databricks Performance
Databricks, on the other hand, is designed for low-latency performance on both batch and real-time workloads. Users have many levers to customize performance — advanced indexing, caching, hash bucketing, query execution plan optimization and more!! This high degree of tuning allows users to customize and tune performance across structured, semi-structured, and unstructured data workloads. However, it does require expertise to leverage these advanced tuning capabilities.
Tl;DR; Snowflake wins on out-of-the-box analytics performance, while Databricks enables greater customization and versatility across workloads. The choice depends on use case simplicity vs advanced tuning needs.
3). Databricks vs Snowflake — Ecosystem and Integration
Snowflake and Databricks take differing approaches when it comes to ecosystem and integration. This section compares their ecosystems, integrations and marketplaces.
Snowflake Ecosystem and Integration
Snowflake has built a robust ecosystem of technology partnerships and integrations. It offers connectivity to major business intelligence tools like Tableau, Looker and Power BI that allow easy visualization and dashboarding using Snowflake data. Snowflake also comes with pre-built as well as third-party connectors to ingest and analyze data from popular SaaS applications.
On top of that, Snowflake has deep integrations with all the major cloud platforms – AWS, Azure, and GCP. This allows organizations to efficiently host on their preferred cloud infrastructure.
Snowflake also provides an API that enables custom integrations to be built with a wide range of third-party applications as per business needs.
To augment its analytics capabilities, Snowflake partners with leading data management and governance solutions. For example, it has partnered with Collibra for data cataloging and metadata management, Talend for ETL and data integration, and Alteryx for data blending and preparation. The Snowflake Marketplace provides a catalog of applications, connectors and accelerators from technology partners that complement Snowflake's core functionality. BUT, the entire ecosystem is relatively closed compared to Databricks as Snowflake is a proprietary commercial data warehouse.
Databricks Ecosystem and Integration
Databricks leverages the open source Apache Spark ecosystem to build its platform for data engineering, machine learning, and analytics. It natively integrates with popular BI tools like Tableau, Looker, and Power BI while retaining Spark's robust data processing capabilities, enabling easy data visualization.
Databricks comes with an extensive range of connectors to ingest data from diverse sources like databases, data lakes, streaming sources and SaaS applications. This is enabled by Spark's connectivity frameworks and the vibrant open source ecosystem around Spark. Databricks also easily integrates with AWS, Azure, and GCP like Snowflake.
For data management, Databricks has partnered with tools like Collibra, Alation and Qlik. More importantly, it allows engineers to leverage the rich set of machine learning, SQL, graph processing, and streaming libraries from the open source Spark ecosystem. This provides flexibility for quickly developing models and applications.
The Databricks Lakehouse architecture brings data management capabilities like data cataloging to data lakes, enabling an open yet governed lakehouse ecosystem. The Databricks marketplace further augments its capabilities with partner solutions for BI, data integration, monitoring and more.
4). Databricks vs Snowflake — Security and Governance
Snowflake and Databricks both offer robust security and governance features, ensuring data protection and compliance. In this section, we'll explore their distinct approaches and strengths in safeguarding your valuable data. Let's delve into the battle of "Databricks vs Snowflake" for data security and governance supremacy.
Snowflake Security
Snowflake provides robust security capabilities to safeguard data and meet compliance requirements. Snowflake utilizes a multi-layered security architecture consisting of network security, access control, and End-to-End encryption.
Network security
Snowflake allows configuring network policies to restrict access to only authorized IP addresses or virtual private cloud (VPC) endpoints. Users can set up private connectivity options like AWS PrivateLink or Azure Private Link to establish private channels between Snowflake and other cloud resources.
Access Control
Snowflake has extensive access control mechanisms built on roles and privileges. Users can create roles aligned to specific job functions and assign privileges like ownership or read-write access accordingly. Granular access control is also possible through Object Access Control, Row Access Control via Secure Views and Column Access Control by masking columns. Multi-factor authentication and federated authentication via OAuth provide additional access security.
Encryption
Encryption is a core part of Snowflake's security posture. All data stored in Snowflake is encrypted at rest using AES-256 encryption by default. Snowflake supports both platform-managed and customer-managed encryption keys. For key management, Snowflake provides built-in key rotation and re-keying capabilities. Users can also enable client-side and column-level encryption for enhanced data protection.
Snowflake Governance
Snowflake offers robust governance capabilities through features like column-level security, row-level access policies, object tagging, tag-based masking, data classification, object dependencies, and access history. These built-in controls help secure sensitive data, track usage, simplify compliance, and provide visibility into user activities.
To learn more in-depth about implementing strong data governance with Snowflake, check out this article
Databricks Security
Databricks takes data security very seriously and has built security into every layer of its Lakehouse Platform. Trust is established through transparency — Databricks publicly shares details on how the platform is secured and operates. The platform undergoes rigorous penetration testing, vulnerability management, and follows secure software development practices.
Data Encryption
Data encryption is a core security capability. Data at rest is encrypted using industry-standard AES-256 encryption. Data in transit between components is encrypted with TLS 1.2. Databricks supports customer-managed encryption keys, allowing customers to control the keys used to encrypt their data.
Network security
Network controls and segmentation provide isolation and prevent unauthorized access. The platform uses private IP addresses and subnets to isolate workloads. Lateral movement between workloads is restricted. Traffic stays on the cloud provider's network rather than traversing the public internet.
Access Controls
Access controls enforce the principle of least privilege. Users are granted the minimal permissions needed for their role. Short-lived access tokens are used instead of long-lived credentials. Multi-factor authentication is required for sensitive operations.
Auditing
Auditing provides visibility into platform activity. Security events from various sources are collected into the platform to enable detections and investigations. Logs are analyzed using statistical ML models to surface suspicious activity.
Serverless compute
Databricks serverless compute provides additional isolation and security. Each workload runs on dedicated, compute resources that are wiped after use. Resources have no credentials and are isolated from other workloads.
Compliance
The platform enables compliance with standards like HIPAA, PCI DSS, and FedRAMP through its security capabilities and controls. It maintains ISO 27001, SOC 2 Type II, and other certifications. Customers can run compliant workloads using a hardened environment and encryption.
Databricks Governance
Databricks provides robust data governance capabilities for the lakehouse across multiple clouds through Unity Catalog and Delta Sharing. Unity Catalog is a centralized data catalog that enables fine-grained access control, auditing, lineage tracking, and discovery for data and AI assets. Delta Sharing facilitates secure data sharing across organizations and platforms.
To learn more in-depth about Databricks data governance features and best practices, check out this article
5). Databricks vs Snowflake — Data Science, AI and Machine Learning Capabilities
Finally, let’s Embrace the cutting-edge world of data science and machine learning as we compare Databricks vs Snowflake. Both platforms have equally powerful capabilities in this domain. In this section, we'll delve into the showdown of "Databricks vs Snowflake" and discover which platform reigns supreme in advancing data science and machine learning.
Snowflake Data Science and Machine Learning Capabilities
Snowflake is designed for storing and analyzing large datasets. While it doesn't possess native machine learning capabilities like databricks, BUT it does provide the infrastructure necessary for machine learning initiatives.
Snowflake supports the loading, cleansing, transformation, and querying of large volumes of structured and semi-structured data. This data can be used to train and operationalize machine learning (ML) models with external tools. SQL queries can be executed to extract, filter, aggregate, and transform data into features suitable for machine learning algorithms.
Snowflake offers connectors and various tools for exploratory data analysis. It also supports Python, user-defined functions, Stored Procedures, External Functions and Snowpark API for data preprocessing and transformation. The Snowpark API allows Python, and custom user-defined functions to be executed within Snowflake for feature engineering, data transformation before exporting to external machine learning platforms.
Databricks Data Science, AI and Machine Learning Capabilities
Databricks offers an integrated platform designed for creating and deploying robust end-to-end machine learning pipelines. It comes with pre-installed distributed machine learning libraries, packages and tools, facilitating high-performance modeling on big data.
Databricks simplifies the model building process with automated hyperparameter tuning, model selection, visualization, and interpretability through AutoML. Its feature store allows data engineers/teams to manage and share machine learning features, accelerating development.
MLflow, an open source platform for managing the end-to-end machine learning lifecycle, is provided to track experiments(to record and compare parameters and results), register models, and package ML models and deploy ‘em. Models built on Databricks can be directly deployed for real-time inference via REST APIs and can be easily integrated into various applications.
Databricks also offers enterprise-grade security, access controls, and governance capabilities, enabling organizations to build secure and compliant machine learning and data science platforms.
Bonus: Databricks vs Snowflake — Billing and Pricing Models
Last but certainly not least, Snowflake and Databricks differ significantly in their pricing models — a crucial factor with major cost efficiency implications. In this section, we'll navigate the intricacies of "Databricks vs Snowflake" pricing to help you make the most informed and budget-conscious decisions for your data platform investment.
Snowflake pricing Breakdown
Snowflake uses a pay-per-second billing model based on actual compute usage, rather than fixed hourly or monthly fees. Users are charged by the second for the processing power used based on the size of virtual warehouses deployed. Snowflake separates storage charges from compute. Storage is charged based on average monthly storage usage after compression.
Note: Snowflake does not charge data ingress fees to bring data into your account, but does charge for data egress
Snowflake offers four editions with different features and pricing:
Snowflake measures usage in "credits", where one credit equals one minute of compute usage on a small virtual warehouse. Credit costs vary by edition and cloud provider.
Snowflake's pricing aligns closely with actual consumption patterns. Users only pay for resources used without having to overprovision capacity. The pay-per-second model and auto-suspending of warehouses helps minimize wasted spend.
Check out this article to learn more in-depth about Snowflake pricing.
Databricks Pricing Breakdown
Databricks offers flexible and scalable pricing for organizations leveraging its Lakehouse Platform for data engineering, data science, machine learning, and analytics workloads. Driven by usage rather than fixed costs, Databricks' pay-as-you-go model ensures cost optimization and elasticity, eliminating the need for heavy upfront investment.
Databricks Units (DBUs)
The core unit of billing on Databricks is the Databricks Unit or DBU. It is a normalized measure of processing capability consumed over time when running workloads on the Databricks platform.
Essentially, the DBU tracks the total compute power and time required to complete jobs like ETL pipelines, machine learning model training, SQL queries, and other data-intensive tasks. It captures the full end-to-end usage across the integrated Databricks environment.
The DBU is conceptually similar to cloud infrastructure units like Snowflake credits or EC2 instance hours. But while those units measure just the infrastructure usage, the DBU measures total software processing consumption in addition to the underlying infrastructure.
Factors Impacting DBU Usage
The amount of DBUs consumed when running a workload depends on three main key factors:
1) Amount of Data Volume
The total volume of data that needs to be processed and analyzed has a direct impact on usage. Processing a 20 TB dataset will consume more DBUs than a 1 TB dataset, assuming all other factors are equal. As data volume increases, DBU consumption grows linearly.
2) Data Complexity
The complexity of data transformations and analysis algorithms also drives up the DBU usage. Tasks like cleaning messy raw data, joining complex data sources, applying ML algorithms, and running interactive ad-hoc queries consume more DBUs than simple ETL and reporting tasks. DBU consumption scales according to the complexity of data tasks.
3) Data Velocity
For streaming and real-time workloads, the total throughput of data processed per hour impacts usage. A high velocity stream processing 100,000 events per second will drive higher DBUs than a batch ETL pipeline running once a day. As data velocity increases, DBU usage grows proportionally.
Hence, by carefully evaluating these three factors, you may predict projected DBU usage when using Databricks. Usage will automatically scale up or down in accordance with variations in these workload parameters.
DBU Rates
Databricks Billing Units (DBUs) are the units used to measure the compute resources consumed in Databricks. The cost of running a workload on Databricks is determined by multiplying the number of DBUs consumed by the applicable DBU rate.
DBU rates vary based on the following factors:
- Cloud Provider — Databricks offers different DBU rates depending on the cloud provider (AWS, Azure, or GCP) where the Databricks workspace is deployed.
- Region: The cloud region where the Databricks workspace is located can influence the DBU rate.
- Databricks Edition — Databricks offers tiered editions (Standard, Premium, and Enterprise) with varying DBU rates. Enterprise edition offers access to advanced features and typically has the highest DBU rate, followed by Premium and Standard.
- Instance Type — The instance type (e.g., memory-optimized, compute-optimized, etc.) used for the Databricks cluster affects the DBU rate.
- Compute Type — Databricks further categorizes DBU pricing by the type of compute workload, including Serverless compute. Each compute type is assigned different DBU rates to reflect the varying resource demands of these tasks.
- Committed Use — Users can secure discounts on DBU rates by entering into committed use contracts. These contracts involve reserving a specific amount of capacity for a predetermined period, with the discount increasing proportionally to the amount of capacity reserved. This option is particularly beneficial for predictable, long-term workloads.
TL;DR; the DBU rate provides multiple tunable knobs through the cloud provider, Databricks edition, compute type and commitments to optimize for specific workloads.
Databricks Products—and Databricks Pricing
Databricks offers several products on its Lakehouse Platform. The usage costs for each product are measured in terms of DBUs consumed based on data volume, complexity, and velocity.
Here are details on the pricing for key Databricks products:
DBU rates for each product vary according to the six factors stated above.
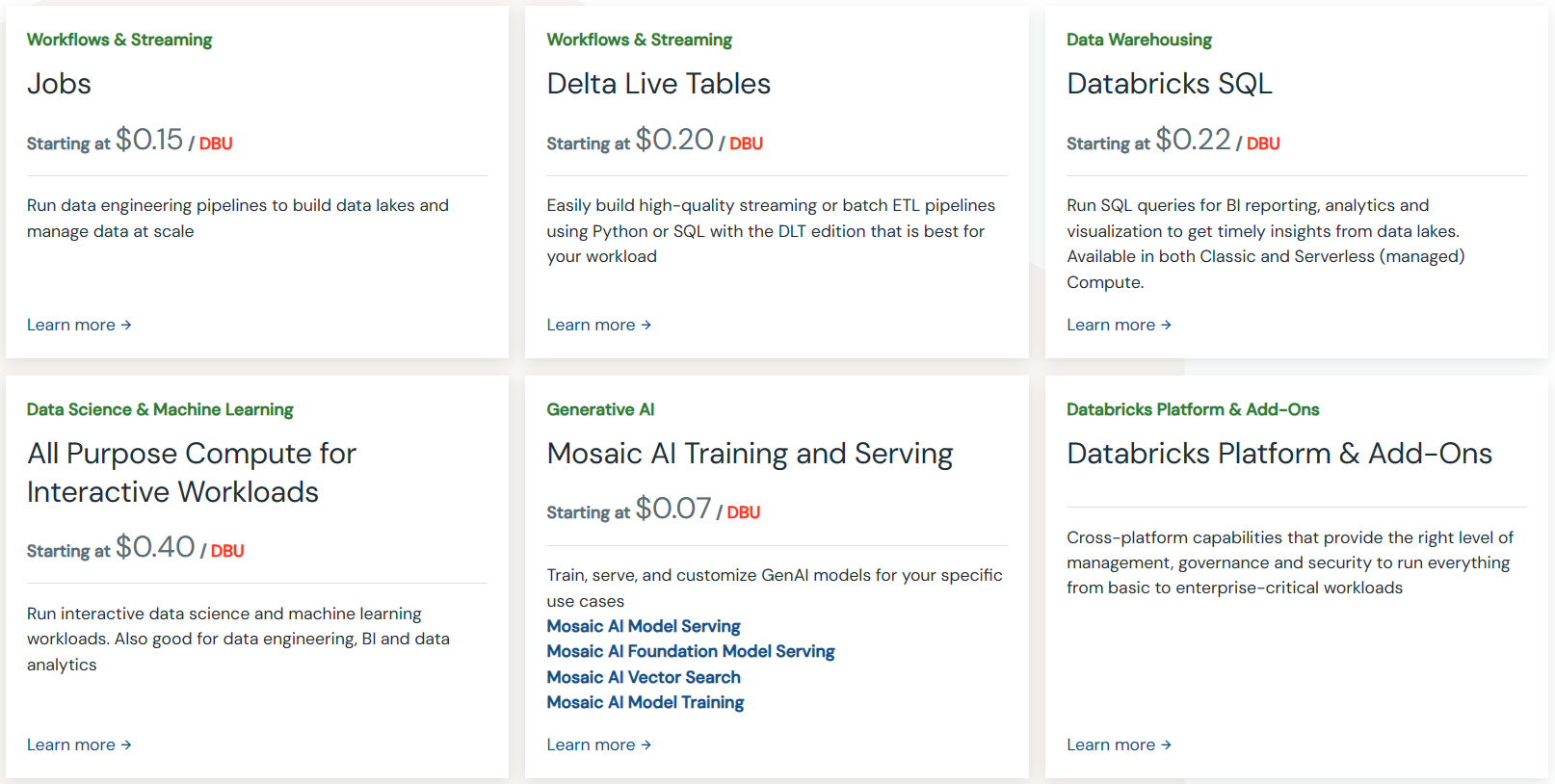
1. Jobs - Starting at $0.15/DBU
Databricks offers two main pricing models for running jobs on their platform: Classic/Classic Photon clusters and Serverless (Preview).
➤ Classic/Classic Photon Clusters
This is a massively parallelized, high-performance version to run data engineering pipelines, build data lakes, and manage data at scale. The pricing for Classic/Classic Photon clusters is based on Databricks Units (DBUs). The cost per DBU varies based on the chosen plan (Standard, Premium, or Enterprise) and the cloud provider (AWS, Azure, or Google Cloud).
For example,
-
On AWS (AP Mumbai region):
- Premium plan: $0.15 per DBU
- Enterprise plan: $0.20 per DBU
-
On Azure (US East region):
- Standard plan: $0.15 per DBU
- Premium plan: $0.30 per DBU
-
On Google Cloud:
- Premium plan: $0.15 per DBU
➤ Serverless (Preview):
This is a fully managed, elastic serverless platform to run jobs. The pricing for Serverless includes the underlying compute costs and is also based on DBUs. There is currently a limited-time promotion starting in May 2024 (Get upto 50% discount).
-
on AWS:
- Premium plan: $0.37 per DBU (discounted from $0.74 per DBU)
- Enterprise plan: $0.47 per DBU (discounted from $0.94 per DBU)
-
On Azure (US East region):
- Premium plan: $0.45 per DBU (discounted from $0.90 per DBU)
2. Delta Live Tables - Starting at $0.20/DBU
Delta Live Tables (DLT) makes building reliable data pipelines using Spark SQL or Python simple and effortless. This enables organizations to easily move data from sources like Kafka, databases, object stores and SaaS applications into Databricks.
Databricks offers three tiers of Delta Live Tables (DLT) pricing: DLT Core, DLT Pro, and DLT Advanced. The pricing varies based on the chosen cloud provider (AWS, Azure, or Google Cloud Platform) and the plan (Premium or Enterprise).
-
On AWS (AP Mumbai region):
- Premium plan:
- DLT Core: $0.20 per DBU (Databricks Unit)
- DLT Pro: $0.25 per DBU
- DLT Advanced: $0.36 per DBU
- Enterprise plan:
- DLT Core: $0.20 per DBU
- DLT Pro: $0.25 per DBU
- DLT Advanced: $0.36 per DBU
- Premium plan:
-
On Azure:
- Premium Plan (Only plan available):
- DLT Core: $0.30 per DBU
- DLT Pro: $0.38 per DBU
- DLT Advanced: $0.54 per DBU
- Premium Plan (Only plan available):
-
On Google Cloud:
- Premium Plan (Only plan available):
- DLT Core: $0.20 per DBU
- DLT Pro: $0.25 per DBU
- DLT Advanced: $0.36 per DBU
- Premium Plan (Only plan available):
- DLT Core: Allows you to easily build scalable streaming or batch pipelines in SQL and Python.
- DLT Pro: In addition to the capabilities of DLT Core, it enables you to handle change data capture (CDC) from any data source.
- DLT Advanced: Builds upon DLT Pro by adding the ability to maximize data credibility with quality expectations and monitoring.
3. Databricks SQL - Starting at $0.22/DBU
Databricks SQL provides a scalable SQL analytics engine optimized for querying large datasets in data lakes. It enables blazing fast queries with ANSI-compliant SQL syntax and BI dashboarding.
Databricks offers three main SQL pricing options: SQL Classic, SQL Pro, and SQL Serverless. The pricing varies depending on the chosen cloud provider (AWS, Azure, or Google Cloud Platform) and the plan (Premium or Enterprise).
Databricks SQL makes it cost-effective to query massive datasets directly instead of having to downsample or pre-aggregate data for BI tools.
-
On AWS (US East (N. Virginia)):
- Premium plan:
- SQL Classic: $0.22 per DBU (Databricks Unit)
- SQL Pro: $0.55 per DBU
- SQL Serverless: $0.70 per DBU (includes cloud instance cost)
- Enterprise plan:
- SQL Classic: $0.22 per DBU
- SQL Pro: $0.55 per DBU
- SQL Serverless: $0.70 per DBU (includes cloud instance cost)
- Premium plan:
-
On Azure (US East (N. Virginia)):
- Premium Plan (Only plan available):
- SQL Classic: $0.22 per DBU
- SQL Pro: $0.55 per DBU
- SQL Serverless: $0.70 per DBU (includes cloud instance cost)
- Premium Plan (Only plan available):
-
On Google Cloud:
- Premium Plan (Only plan available):
- SQL Classic: $0.22 per DBU
- SQL Pro: $0.69 per DBU
- SQL Serverless (Preview): $0.88 per DBU (includes cloud instance cost)
- Premium Plan (Only plan available):
- SQL Classic: Allows you to run interactive SQL queries for data exploration on a self-managed SQL warehouse.
- SQL Pro: Provides better performance and extends the SQL experience on the lakehouse for exploratory SQL, SQL ETL/ELT, data science, and machine learning on a self-managed SQL warehouse.
- SQL Serverless: Offers the best performance for high-concurrency BI and extends the SQL experience on the lakehouse for exploratory SQL, SQL ETL/ELT, data science, and machine learning on a fully managed, elastic, serverless SQL warehouse hosted in the customer's Databricks account. The pricing for SQL Serverless includes the underlying cloud instance cost.
4. Data Science & ML Pricing - Starting at $0.40/DBU
Databricks' machine learning capabilities powered by MLflow, Delta Lake and Spark MLlib provide an end-to-end platform for data teams to collaborate on building, training, deploying and monitoring machine learning models.
Databricks offers pricing options for running data science and machine learning workloads, which vary based on the cloud provider (AWS, Azure, or Google Cloud Platform) and the chosen plan (Standard, Premium, or Enterprise).
-
On AWS (AP Mumbai region):
- Premium plan:
- Classic All-Purpose/Classic All-Purpose Photon clusters: $0.55 per DBU
- Serverless (Preview): $0.75 per DBU (includes underlying compute costs; 30% discount applies starting May 2024)
- Enterprise plan:
- Classic All-Purpose/Classic All-Purpose Photon clusters: $0.65 per DBU
- Serverless (Preview): $0.95 per DBU (includes underlying compute costs; 30% discount applies starting May 2024)
- Premium plan:
-
On Azure (US East region):
- Standard Plan:
- Classic All-Purpose/Classic All-Purpose Photon clusters: $0.40 per DBU
- Premium Plan:
- Classic All-Purpose/Classic All-Purpose Photon clusters: $0.55 per DBU
- Serverless (Preview): $0.95 per DBU (includes underlying compute costs; 30% discount applies starting May 2024)
- Standard Plan:
-
On Google Cloud:
- Premium Plan (Only plan available):
- Classic All-Purpose/Classic All-Purpose Photon clusters: $0.55 per DBU
- Premium Plan (Only plan available):
- Classic All-Purpose/Classic All-Purpose Photon clusters: These are self-managed clusters optimized for running interactive workloads.
- Serverless (Preview): This is a fully managed, elastic serverless platform for running interactive workloads.
5. Model Serving Pricing - Starting at $0.07/DBU
In addition to training models, Databricks enables directly deploying models for real-time inference and predictions through its serverless offering. This allows data teams to integrate ML models with applications, leverage auto-scaling and only pay for what they use.
Databricks offers model serving and feature serving capabilities with pricing that varies based on the cloud provider (AWS, Azure, or Google Cloud Platform) and the chosen plan (Premium or Enterprise).
-
On AWS (US East (N. Virginia)):
- Premium plan:
- Model Serving and Feature Serving: $0.070 per DBU (Databricks Unit), includes cloud instance cost
- GPU Model Serving: $0.07 per DBU, includes cloud instance cost
- Enterprise plan:
- Model Serving and Feature Serving: $0.07 per DBU, includes cloud instance cost
- GPU Model Serving: $0.07 per DBU, includes cloud instance cost
- Premium plan:
-
On Azure (US East region):
- Premium Plan(Only plan available):
- Model Serving and Feature Serving: $0.07 per DBU, includes cloud instance cost
- GPU Model Serving: $0.07 per DBU, includes cloud instance cost
- Premium Plan(Only plan available):
-
On Google Cloud:
- Premium Plan (Only plan available):
- Model Serving and Feature Serving: $0.088 per DBU, includes cloud instance cost
- Premium Plan (Only plan available):
- Model Serving: Allows you to serve any model with high throughput, low latency, and autoscaling. The pricing is based on concurrent requests.
- Feature Serving: Enables you to serve features and functions with low latency. The pricing is also based on concurrent requests.
- GPU Model Serving: Provides GPU-accelerated compute for lower latency and higher throughput on production applications. The pricing is based on GPU instances per hour.
| Instance Size | GPU configuration | DBUs / hour |
|---|---|---|
| Small | T4 or equivalent | 10.48 |
| Medium | A10G x 1GPU or equivalent | 20.00 |
| Medium 4X | A10G x 4GPU or equivalent | 112.00 |
| Medium 8x | A10G x 8GPU or equivalent | 290.80 |
| XLarge | A100 40GB x 8GPU or equivalent | 538.40 |
| XLarge | A100 80GB x 8GPU or equivalent | 628.00 |
Note: Pricing listed here is specific to the information provided and is subject to change or promotional offers by Databricks.
Here is the full Databricks Pricing Breakdown:
Databricks vs Snowflake — Pros & Cons
Snowflake pros and cons: To Flake or Not To Flake?
Here are the main Snowflake pros and cons:
Snowflake Pros:
- Scalable storage and compute — Snowflake can scale storage and compute independently to handle any workload.
- Performance — Snowflake offers fast query processing and ability to run multiple concurrent workloads. It also has built-in caching and micro-partitioning for better performance.
- Security — Snowflake provides robust security with encryption, network policies, access controls, and regulatory compliance.
- Full Availability — Data is stored redundantly across multiple cloud providers and availability zones. Snowflake also offers features like Time Travel and Fail-safe for data recovery.
- Flexible pricing — Pay only for storage and compute used per second. Auto-scaling and auto-suspend features further optimize costs.
- Ease of use — Snowflake uses standard SQL and has an intuitive UI. Easy to set up and use even for non-technical users.
- Robust Ecosystem — Broad set of tools, drivers, and partners integrate natively with Snowflake.
Snowflake Cons:
- Cost — Can be more expensive than alternatives like Redshift for some workloads. Costs can add up quickly if usage isn't monitored and optimized.
- Limited community — Smaller user community compared to competitors. Less third-party support available.
- Data streaming — Snowflake's data streaming capabilities via Snowpipe and Stream are still maturing. Additional ETL tools are often required.
- Unstructured data Mainly optimized for semi-structured and structured data. Limited support for unstructured data workloads.
- On-premises support — Snowflake has traditionally been cloud-only. On-prem support is still new and limited.
- Vendor lock-in — Not as multi-cloud as claimed. Significant benefits from tight integration with major cloud vendors.
Databricks pros and cons: Sparking an Analytics Revolution?
Here are the main databricks pros and cons:
Databricks Pros:
- Unified analytics platform — Databricks provides a unified platform for data engineering, data science, and machine learning workflows on an open data lake house architecture.
- Broad technology integrations — It natively integrates open source technologies like Apache Spark, Delta Lake, MLflow, and Koalas, avoiding vendor lock-in.
- Auto-scaling compute — Databricks auto-scales cluster resources optimized for big data workloads, saving on costs.
- Security capabilities — It offers enterprise-grade security with access controls, encryption, VPC endpoints, auditing trails, and more!!!
- Collaboration features — Databricks enables collaboration through shared notebooks, dashboards, ML models, and data via Delta Sharing.
- ML lifecycle management — End-to-end ML lifecycle managed via Model Registry, Feature Store, Hyperparameter Tuning, and MLflow.
- Open data sharing — Delta Sharing protocol allows open data exchange across organizations.
- Extensive documentation — Detailed documentation and an active community for support.
Databricks Cons:
- Steep learning curve — Especially for non-programmers given the complexity in setup and cluster management.
- Scala-first development — Primary language Scala has a smaller talent pool than Python/R.
- Expensive pricing — Can get expensive at scale if resource usage isn't optimized and monitored closely.
- Small open source community — Not as large as Apache Spark and other open source projects.
- Limited no-code support — Drag-and-drop interfaces are limited compared to dedicated BI/analytics platforms.
- Data ingestion gaps — Data ingestion and streaming capabilities aren't as comprehensive as specialized tools.
- Inconsistent multi-cloud support — Some capabilities like Delta Sharing and MLflow don't work across all clouds uniformly.
What Is the Difference Between Snowpark and Databricks?
By now, you've probably understood what Snowflake is. But did you know that Snowflake also provides a groundbreaking set of libraries and runtimes known as SnowPark? SnowPark allows you to deal with your data directly within Snowflake using programming languages such as Python, Java, and Scala, offering functionalities quite similar to what Databricks offers. This amazing capability opens up new possibilities for data processing, machine learning, and more, all without the need to move your data around.
Let's now compare SnowPark and Databricks, exploring their differences and determining how each provides distinct benefits for your data needs.
| Snowpark | Databricks |
| Snowpark offers direct compute in Snowflake with DataFrame API | Databricks serves as a big data compute and ML workhorse |
| Snowpark supports Java, Scala, Python | Databricks supports Python (PySpark), Scala, SQL (SparkSQL), R |
| Snowpark lacks native ML pipelines and relies on partnerships | Databricks has strong ML pipeline support with MLFlow |
| Snowpark has its own DataFrame API mimicking Spark | Databricks uses Apache Spark DataFrames |
| Snowpark translates DataFrame operations into native Snowflake executions | Databricks executes jobs on managed Spark clusters |
| Snowpark’s tooling is primitive and relies on DBT partnership | Databricks has robust tooling with Delta Lake for ACID transactions |
| Snowpark has limited notebook support (new feature) | Databricks has mature notebook support |
| Snowpark offers good price-performance over competitors | Databricks is known for managing Spark clusters efficiently |
| Snowpark’s MLOps capabilities are not as strong and are evolving | Databricks offers strong support with MLFlow integration |
Save up to 50% on your Databricks spend in a few minutes!
Conclusion
Snowflake’s strength lies in its cloud-native architecture, instant elasticity, and excellent price-performance for analytics workloads. Databricks provides greater depth and flexibility for data engineering, data science, and machine learning use cases.
Snowflake is the easier plug-and-play cloud data warehouse while Databricks enables custom big data processing. For a unified analytics platform with end-to-end ML capabilities, Databricks is the better choice. Otherwise, Snowflake hits the sweet spot for cloud BI, data analytics, and reporting.
Choosing between Snowflake and Databricks is like deciding between a swiss army knife and a full toolkit. The swiss army knife (Snowflake) neatly packages up the most commonly used tools into one simple package. It's easy to use and great for basic tasks. The full toolkit (Databricks) provides deeper capabilities for those who need to handle heavy-duty data jobs. So consider whether you need simple data analysis or extensive data engineering and machine learning. This will lead you to determine the right platform to fulfill your needs.
Further Readings
Video Resources
Snowflake vs Databricks - The Ultimate Comparison 💡 Which One is Right for You?
Snowflake Vs Databricks - 🏃♂️ A Race To Build THE Cloud Data Platform 🏃♂️
FAQs
What are the key differences between the Databricks vs Snowflake architectures?
Snowflake uses a unique hybrid architecture with separate storage and compute layers. Databricks is built on Apache Spark and implements a unified data lakehouse architecture.
How do Databricks vs Snowflake compare for analytics performance?
Snowflake delivers great out-of-the-box analytics performance while Databricks enables extensive tuning across diverse workloads.
When is Snowflake the best choice over Databricks?
For cloud analytics and BI workloads that require simple setup and great out-of-the-box performance.
Is Databricks better than Snowflake?
Snowflake is optimized for analytical workloads like aggregated reports, dashboards, and ad-hoc queries. Databricks is designed for heavy data transformation, ingestion, and machine learning tasks.
What are the main use cases for Databricks vs Snowflake?
Snowflake excels at cloud data warehousing and analytics. Databricks is better suited for data engineering, data science, and machine learning.
Can Snowflake and Databricks work together?
Yes, Snowflake and Databricks can work together. In fact, there is a native connector available in both Snowflake and Databricks, which allows them to read and write data without importing any additional libraries.
Does Snowflake support streaming data processing?
Snowflake has limited support for streaming via Snowpipe and Stream/Tasks. Databricks and Spark are better suited for streaming workloads.
How does the scalability of Snowflake and Databricks compare?
Snowflake offers instant elasticity to scale storage and compute. Databricks provides more fine-grained control over cluster scaling.
Can machine learning models be deployed directly from Databricks?
Yes, Databricks allows deploying models via REST APIs
Does Snowflake require ETL tools for data transformation?
Snowflake can handle lightweight transformations but often benefits from specialized ETL tools.
Which cloud platforms does Snowflake support?
Snowflake is available on AWS, Azure, and GCP. Databricks also supports these major clouds.
Is Snowflake fully managed service?
Yes, Snowflake is a fully managed cloud data warehouse.
Can Databricks connect to databases like Oracle, MySQL etc?
Yes, Databricks provides high-performance connectors to ingest data from diverse sources.
Is Snowflake compliant with regulations like HIPAA, GDPR?
Yes, Snowflake provides capabilities to help meet major compliance standards.
Is Spark SQL supported on Databricks?
Yes, Databricks provides optimized support for running Spark SQL queries.
Can machine learning models be monitored and managed on Databricks?
Yes, Databricks MLflow provides MLOps capabilities like model registry, deployment, and monitoring.
Does Snowflake require indexes like traditional databases?
No, Snowflake uses clustering keys, micro-partitioning and optimization to avoid indexes.
Which has a steeper learning curve - Snowflake or Databricks?
Databricks generally has a steeper learning curve given its breadth of capabilities.
Does Snowflake support time-series data?
Yes, Snowflake has Time-Series optimized storage and query support.
What are some key Snowflake pros and cons?
Pros: Performance, security, availability.
Cons: Cost, limited streaming, and unstructured data support.
Can you use Databricks and Snowflake?
Yes, Databricks provides connectors to read and write Snowflake data. Queries can also be federated across Databricks and Snowflake using Lakehouse architecture. This allows building pipelines leveraging both platforms.
Is Snowflake good for ETL?
Yes, Snowflake is highly suited for ETL with native support for both ETL and ELT modes. It offers high scalability and performance for large data loads and transformations.
Should I learn Snowflake or Databricks?
Snowflake is easier to learn for SQL users while Databricks has a steeper learning curve. Learning both platforms is recommended to leverage their complementary strengths.
Is Snowflake the future?
Yes, with its innovative cloud-native architecture, Snowflake is seen as the future for enterprise data warehousing and analytics. Its popularity and wide adoption reflect its importance.
Is Databricks PaaS or SaaS?
Databricks is offered as a SaaS platform for running data workloads on the cloud. The underlying infrastructure is abstracted away from the user.
Can we use Databricks as ETL?
Yes, Databricks clusters can be used for ETL workflows and data pipelines, providing automated scaling and performance.
Which ETL tool works best with Snowflake?
Fivetran is considered one of the best ETL tools for Snowflake due to its simplicity and native integration in replicating data into Snowflake.
Do data engineers use Snowflake?
Yes, Snowflake is widely used by data engineers for building data pipelines, ETL, and managing the flow of data to analytics and applications.
Is Snowflake better than Azure?
Snowflake is better for a fully managed cloud data warehouse while Azure better integrates with other Microsoft products. The choice depends on the tech stack.
Is Snowflake better than AWS?
Snowflake combines data warehouse and cloud architecture for better performance compared to AWS databases. But AWS offers a wider array of data services. Again, the choice depends on the tech stack.
Is Snowflake good for career?
Yes, Snowflake skills are in very high demand. Snowflake developers are sought-after roles with good salary growth.
Why is Databricks so popular?
Databricks is popular due to its ease of use, power and flexibility in building ML and analytics applications on big data platforms like Spark.
Why is Databricks so fast?
Databricks leverages in-memory Spark clusters and optimized data processing to provide high performance on large datasets.
Is Databricks better than AWS Redshift?
Databricks is more technical and suited for data engineers while AWS Redshift is easier to use. Both have their place in the data ecosystem.
What are some of the main Databricks pros and cons?
Pros: Auto-scaling, data science capabilities, open data sharing.
Cons: Steep learning curve, Expensive pricing.
Does Snowflake have its own machine learning capabilities?
No, Snowflake does not have native ML capabilities. It can store and query ML data, but model building requires using other third party external tools/platforms. Databricks has end-to-end integrated machine learning.
What is the difference between Snowpark and Databricks?
Snowpark is an integrated data processing and machine learning capability within the Snowflake data warehouse, while Databricks is a separate service/platform for big data processing and machine learning on top of Apache Spark.
Who is the main competitor of Snowflake?
Snowflake's main competitor is widely considered to be Databricks. Other notable competitors in the cloud data warehouse and analytics space include Google BigQuery, Microsoft Azure Synapse Analytics, Amazon Redshift, and Teradata.
Who is Databricks' biggest competitor?
Databricks' biggest competitor is Snowflake. It is considered a top competitor to Databricks due to its strong market presence, user base, and the breadth of features it offers.
Which option is cheaper – Databricks vs Snowflake?
It depends on the workload. For analytics queries, Snowflake can be very cost-efficient. Databricks offers optimizations like serverless to reduce costs for data engineering pipelines and ML workloads. Overall costs depend on proper cluster sizing + usage patterns.















