


























Databricks is a leading data analytics platform that offers a managed Apache Spark service in the cloud. It allows users to easily ingest, process, and analyze large volumes of data at scale. Traditionally, all this raw data would be stored in a centralized data lake for flexibility, but data lakes often lack structure, causing issues like data reliability and performance. This is exactly where Databricks Delta Lake comes into play; it is an open source optimized storage layer built on top of Data Lake. Delta Lake brings reliability to the data lake by enabling schema enforcement, data versioning, and transactional updates. It also allows users to perform any kind of operation that can be done on a traditional database, such as querying, updating, deleting, and merging, on the tables for which the underlying data is stored inside the Delta Lake.
In this article, we will cover what Databricks and Delta Lake are, the architecture and features of Delta Lake, and go through a step-by-step tutorial for getting started with Delta Lake on Databricks.
What is Databricks?
Databricks is a unified, open analytics platform for building, deploying, sharing, and maintaining enterprise-grade data, analytics, and AI solutions at scale. Databricks was founded by the original creators of Apache Spark, the leading unified analytics engine for big data processing.
At its very core, Databricks provides Apache Spark as a service, along with features like Serverless Spark jobs, Delta Lake, MLflow, and integrations with other data platforms. It allows users to create and manage Apache Spark clusters and notebook environments through simple point-and-click interactions using the Databricks web interface.
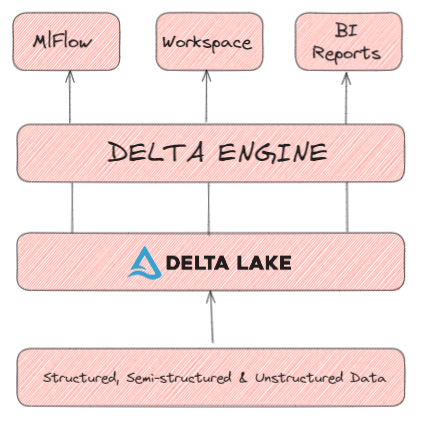
The core components of the Databricks architecture are:
- Apache Spark: Databricks is built on top of the open source Apache Spark cluster computing framework. Spark provides distributed data processing and analytics using RDDs (resilient distributed datasets) and SQL querying. Databricks optimizes Spark with capabilities like auto-scaling, auto-termination, and auto-restarts of clusters.
- Delta Lake: An open source storage layer that brings ACID transactions to data lakes. Delta Lake uses a transaction log to track changes to Parquet data files stored in cloud object stores like S3. This enables features like snapshots, versioning, scalable metadata handling, and unifying streaming and batch workloads.
- Delta Engine: A high-performance query engine designed for optimal performance on data stored in Delta Lake. Techniques like indexing, caching, and query optimization are used to enable fast analytics on large datasets.
- Unified Workspace: The Databricks workspace provides a single platform for everything—data engineering, data science, business intelligence, and machine learning. Users can collaborate on data pipelines, notebooks, dashboards, and models within an integrated environment.
- Built-in Tools: Databricks include ready-to-use tools for ETL, visualization, machine learning, and other tasks. These integrate natively with Delta Lake and Delta Engine.
Check out this article to learn more in-depth about Databricks architecture
Here are some key notable features and benefits of using Databricks:
- Notebooks: An interactive and collaborative workspace environment to develop, run, and share code in Spark, Scala, Python, SQL, R, and other languages.
- Photon SQL engine: High-performance ANSI-compliant engine that is designed to be compatible with Apache Spark APIs and works with existing code in SQL, Python, R, Scala, and Java. It offers fast query execution and optimization for large-scale data processing.
- Scalable and reliable performance: Serverless autoscaling that allows you to run workloads on massive datasets without worrying about cluster sizing. It also provides reliability and fault tolerance for your data pipelines and applications.
- Governance: Central access control, fine-grained role-based access control (RBAC), audit logs, and policy management for governed data insights. You can also use Unity Catalog to manage permissions for accessing data using familiar SQL syntax from within Databricks.
- Integration: Seamless connectivity to popular tools, frameworks, and data sources like SQL/NoSQL databases, object stores, streaming systems, and more. On top of that, you can also use Delta Sharing to securely share data across organizations and platforms using an open protocol.
- Manageability: Automated Apache Spark, library, and dependency management without the overhead of cluster provisioning and maintenance. You can also use workflows to build and manage complex data pipelines using a variety of programming languages.
- Cloud Flexibility: Flexibility across different ecosystems (AWS, GCP, Microsoft Azure).
- Dashboards and BI integration: Integrates with BI tools like Tableau for visualization and dashboards.
- MLflow: An open-source platform for machine learning development on Databricks. It allows you to track, manage, and deploy machine learning models.
- Koalas: Pandas API on Spark for data engineering. It allows you to use the familiar Pandas syntax and functionality to manipulate large-scale data on Spark.
- Databricks Delta Lake: An open-source storage layer that brings reliability and performance to your data lake. It enables ACID transactions, schema enforcement, and time travel on your data.
- Redash: An open-source dashboarding and visualization tool that connects to Databricks and other data sources. It allows you to create and share interactive dashboards and charts with your team.
- Structured Streaming: Near-real-time processing engine that enables scalable and fault-tolerant stream processing. It allows you to write streaming queries using the same syntax and semantics as batch queries.
…and so much more!
So to sum it up, Databricks provides a fully managed Spark platform to accelerate data workloads in a scalable, secure, and collaborative environment.
Getting Started with Databricks
To get started with Databricks, you can sign up for a free trial account. Here is a step-by-step guide on how you can get started with Databricks.
Step 1—Log in to Databricks, create a workspace, and create a cluster
- Login/Signup to Databricks

- Head over to your Databricks workspace and either create a new workspace or select the one you have already created.

- Head over to the Databricks workspace, click "+New" and select "Cluster".
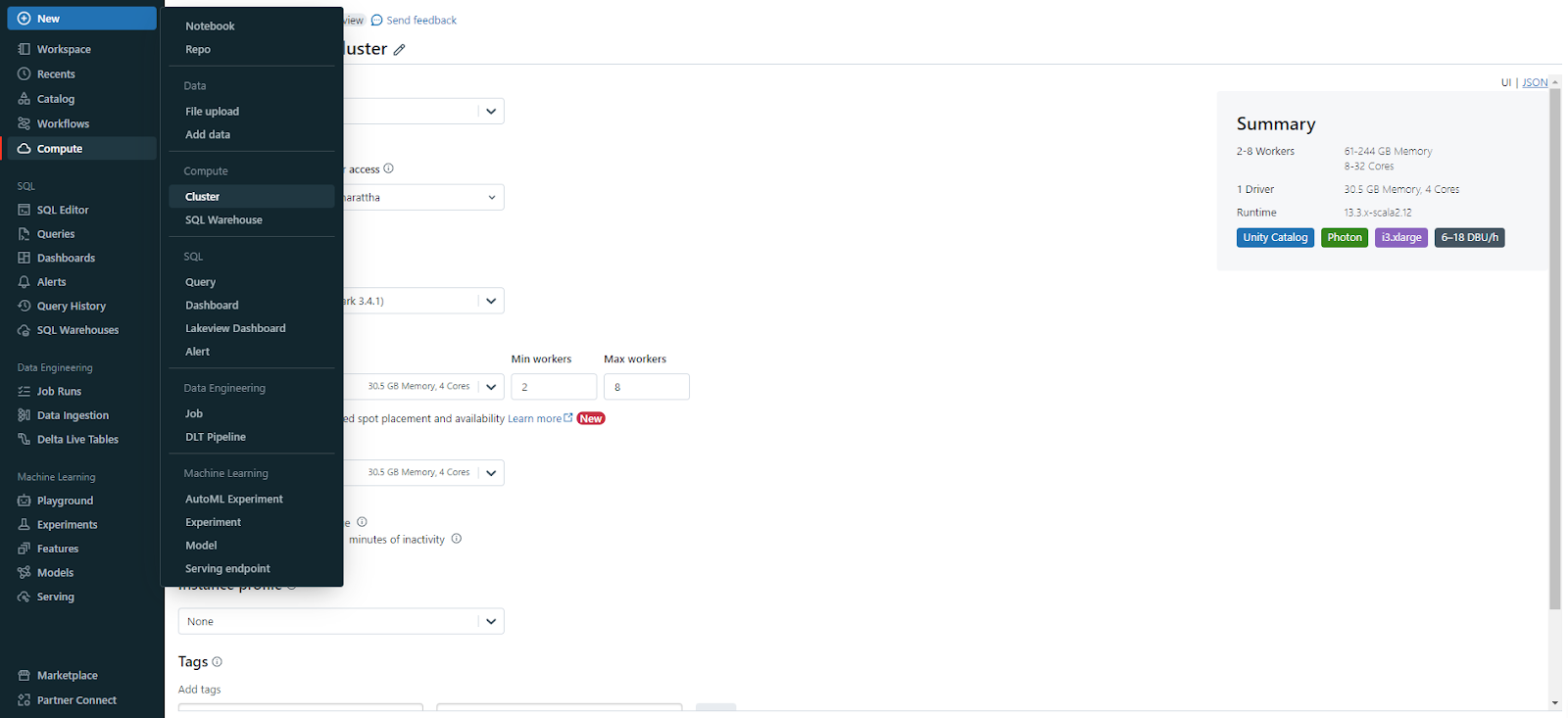
- Give the cluster a name.

- Select a Databricks runtime version and worker type.
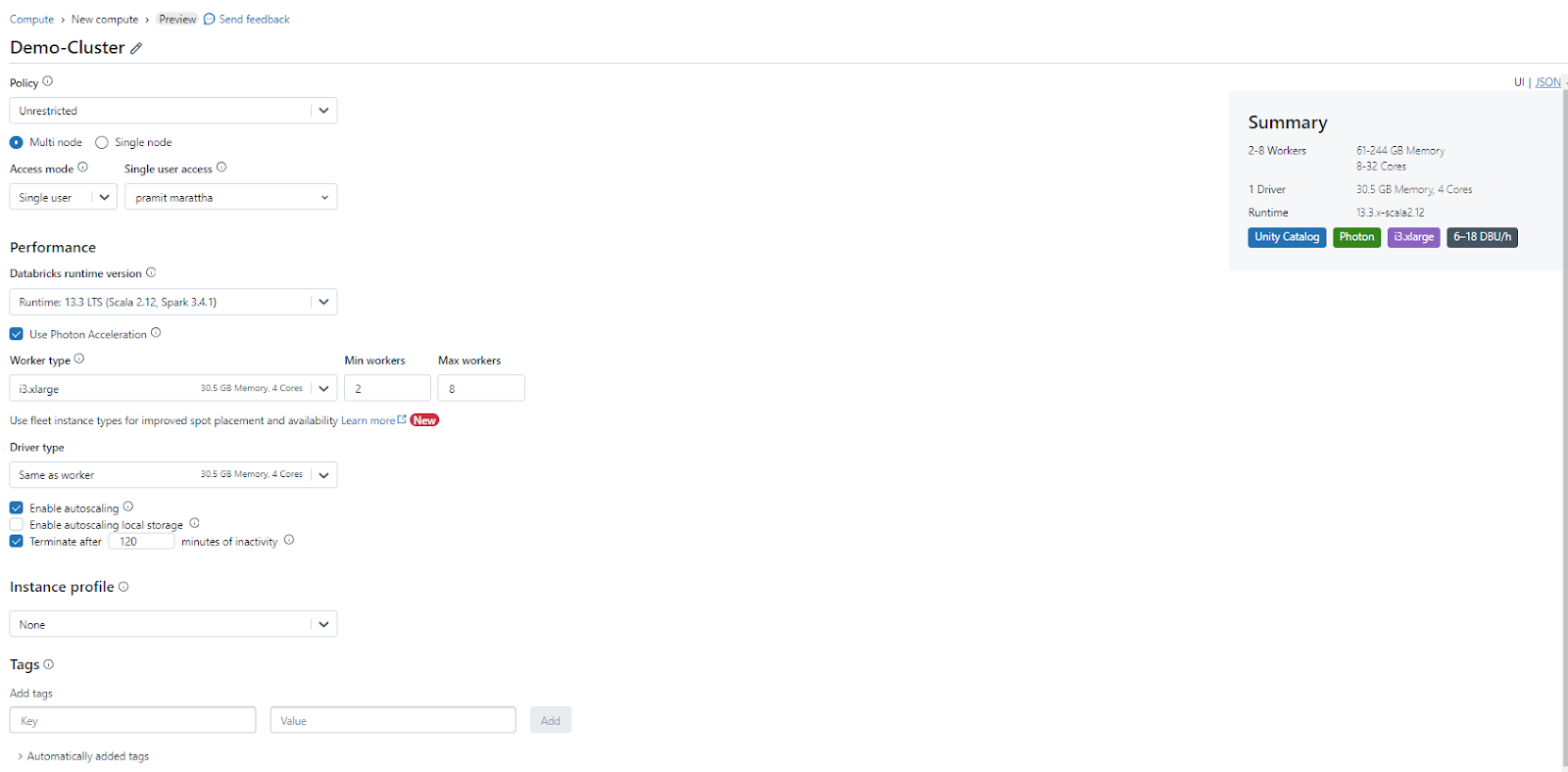
- Select the availability zone as AUTO.

- Click Create Compute. Wait for the cluster to start up.

Note: Cluster will auto-terminate after 2 hours (120 minutes) of inactivity. You can also manually terminate or delete it.

Step 2—Create a notebook
- Click "+New" and select "Notebook".
- Give the notebook a name.
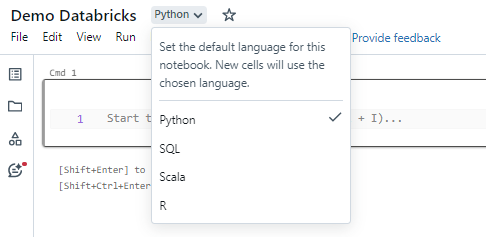
- Select a language: SQL, Scala, Python, or R.
- Select the cluster to attach the notebook to.

Step 3—Run your queries
- Create a new SQL notebook.
- Start writing queries
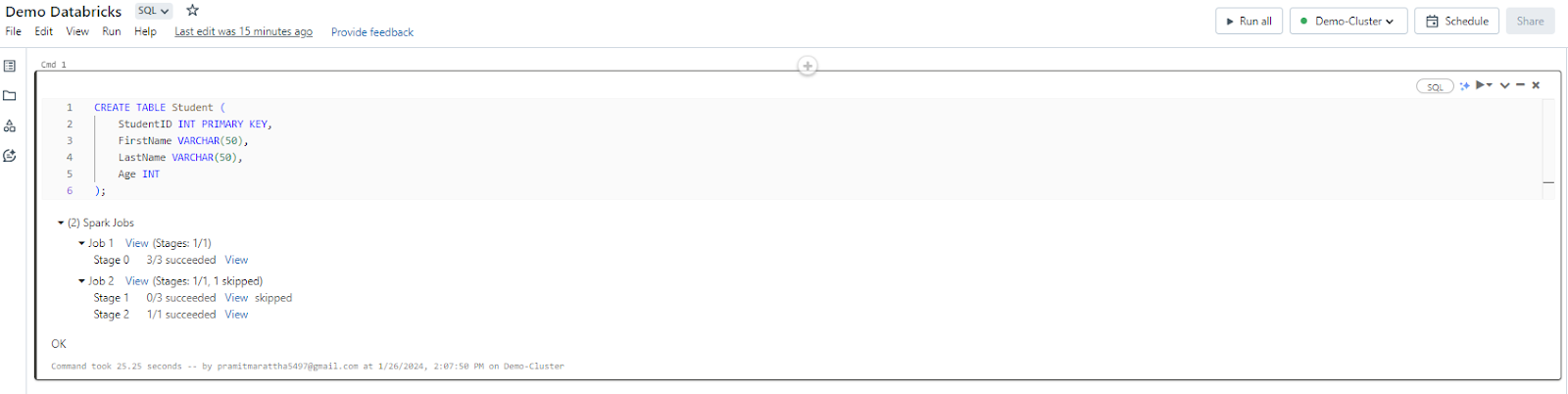
- To run your query, press Ctrl + Enter
What is Data Lake?
Data Lake is a centralized storage repository that allows for the storage of vast amounts of structured and unstructured data at any scale. It addresses the limitations of traditional data warehouses, which can only handle structured data.
In a data lake, raw data from varied sources like databases, applications, and the web is collected and made available for analysis. This avoids costly ETL jobs to curate and structure the data upfront.
However, data lakes have some drawbacks:
- Lack of structure: Data lakes store data as-is without enforcing any schema or quality checks.
- Data spiraling out of control: Data lakes can grow rapidly and uncontrollably as more and more data is ingested without proper governance and management. This can result in data duplication, inconsistency, and inefficiency.
- Data reliability: Data lakes do not provide any guarantees on the consistency, durability, and isolation of the data, which are essential for ensuring data integrity and preventing data corruption. Data lakes also do not support features such as versioning, auditing, and time travel, which are useful for tracking data changes and recovering from errors.
Here is where Delta Lake comes into play by addressing the above challenges and bringing reliability to data lakes at scale.
TL;DR: Here's a meme illustrating what Data Lake truly is. XD

Jokes aside, let's jump into the next section, where we'll dive into understanding what Databricks Delta Lake is.
What is Databricks Delta Lake?
Databricks Delta Lake is an open source storage layer that brings ACID transactions, data versioning, schema enforcement, and efficient handling of batch and streaming data to data lakes. Developed by Databricks, Delta tables provide a reliable and performant foundation for working with large-scale data stored in Apache Spark-based data lakes.
Some key features of Databricks Delta Lake are:
- Schema enforcement: Tables have a defined schema but can evolve over time without restricting new data.
- Transactional semantics: ACID transactions ensure reliable operations and consistency, even during failures.
- Optimized for Spark: Built natively on Spark, queries are 10-100x faster than vanilla Spark/Hive on data lakes.
- Version control: Changes made to tables are tracked, and older versions can be restored as needed.
- Unified batch and streaming: Supports both ingestion methods through a single API and storage format.
- Schema tracking: Table metadata and schema evolution are tracked automatically.
- Time travel: Reverts or accesses any versions of the table as they were at a specific point in time.
- Compliance: Audit logs improve data governance, security, and regulatory compliance needs.
The core components of the Databricks Delta architecture are:
- Databricks Delta Table: Delta tables are like mega-sized spreadsheets optimized for large-scale analysis. They store data in tidy columnar format for lightning-fast querying. But unlike typical tables, Deltas are transactional—any change is recorded chronologically. This maintains data consistency even as schemas evolve over time.
- Delta Log: Keeping track of all transactions is the job of Delta logs. Think of them as a digital ledger that precisely documents every edit made to tables. No matter how vast or varied the changes, logs guarantee data integrity by recording every alteration. They also enable easy rollbacks if issues arise.
- Cloud Object Storage Layer: Storage layer is responsible for storing data in Delta Lake. It is compatible with various object storage systems, like HDFS, S3, or Azure Data Lake. This layer ensures the durability and scalability of the data within Delta Lake, enabling users to store and process extensive datasets without the need to handle the complexities of managing the underlying infrastructure.
When data is inserted or modified in a Delta table, it is first written to cloud storage as JSON files representing the changes. References to these files are then appended to the Delta log. This loosely coupled architecture allows Delta to efficiently scale metadata handling.
The Delta log acts as a System-of-Record and Source-of-truth for the table. All queries are planned using the Delta log, which contains the full history of changes. This enables features like point-in-time queries, rollbacks, and auditability.
Delta Lake removes typical big data headaches. Vast datasets can now be managed, queried, and evolved with ease and confidence on a truly GIGANTIC scale.
In next section, we will discuss the benefits and use cases of Delta Lake.
Benefits of Databricks Delta Lake
As we already know, Delta Lake is a storage layer that brings reliability, performance, and flexibility to data lakes. It offers many benefits and use cases, such as:
1) Reliability and data integrity
Databricks Delta Lake ensures that data is consistent, durable, and isolated, preventing data corruption and enabling concurrent access.
2) ACID transactions and metadata
Databricks Delta Lake enables ACID transactions, which guarantee the atomicity, consistency, isolation, and durability of the data. Delta Lake also maintains a scalable metadata layer, which stores information about the data, such as the schema, partitioning, and statistics.
3) Version control and time travel
Databricks Delta Lake supports version control and time travel, which allow users to access or revert to earlier versions of data for audits, rollbacks, or reproducibility. Delta Lake also provides features such as audit history and data retention, which help users manage the data lifecycle.
4) Data management and DML support
Delta Lake simplifies data management and provides support for data manipulation language (DML) operations such as insert, update, delete, and merge.
5) Delta Sharing
Delta Lake supports Delta Sharing, an open protocol for secure data sharing across organizations.
6) Performance and scalability
Databricks Delta Lake optimizes the performance and scalability of data lake operations, such as reading, writing, updating, and merging data, by using techniques such as compaction, caching, indexing, and partitioning. Delta Lake also leverages the power of Spark and other query engines to process data at scale.
7) Flexibility and openness
Databricks Delta Lake preserves the flexibility and openness of data lakes, allowing users to store and analyze any type of data, from structured to unstructured, using any tool or framework of their choice.
8) Security and compliance
Delta Lake ensures the security and compliance of data lake solutions with features such as encryption, authentication, authorization, auditing, and data governance. Delta Lake also supports various industry standards and regulations, such as GDPR and CCPA.
9) Open Source Adoption
Databricks Delta Lake is completely backed by an active open source community of contributors and adopters.
Platform Supported by Databricks Delta Lake
Delta Lake is an open-format specification. It is supported across a wide range of platforms, including:
…and so much more!
This makes Delta Lake highly portable across many data platforms.
Step-By-Step Guide on Getting Started with Databricks Delta Lake
Now that we understand what Delta Lake is, let's go through the steps to get started with it on Databricks. Let’s dive in and see how Delta Lake works in practice.
Let's revisit the initial section of this article—Getting Started with Databricks—where we created a workspace, notebook, cluster, and attached compute to it. We will omit this step since we've already covered it. If you're not sure, you can refer back to the specific section mentioned above in the article.
Now, let's proceed and begin coding!
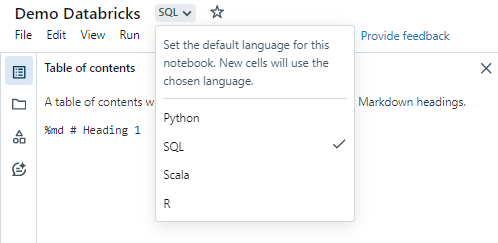
Step 1—Create SQL Notebook in Databricks
Select the dropdown next to the notebook title and make sure that "SQL" is selected.
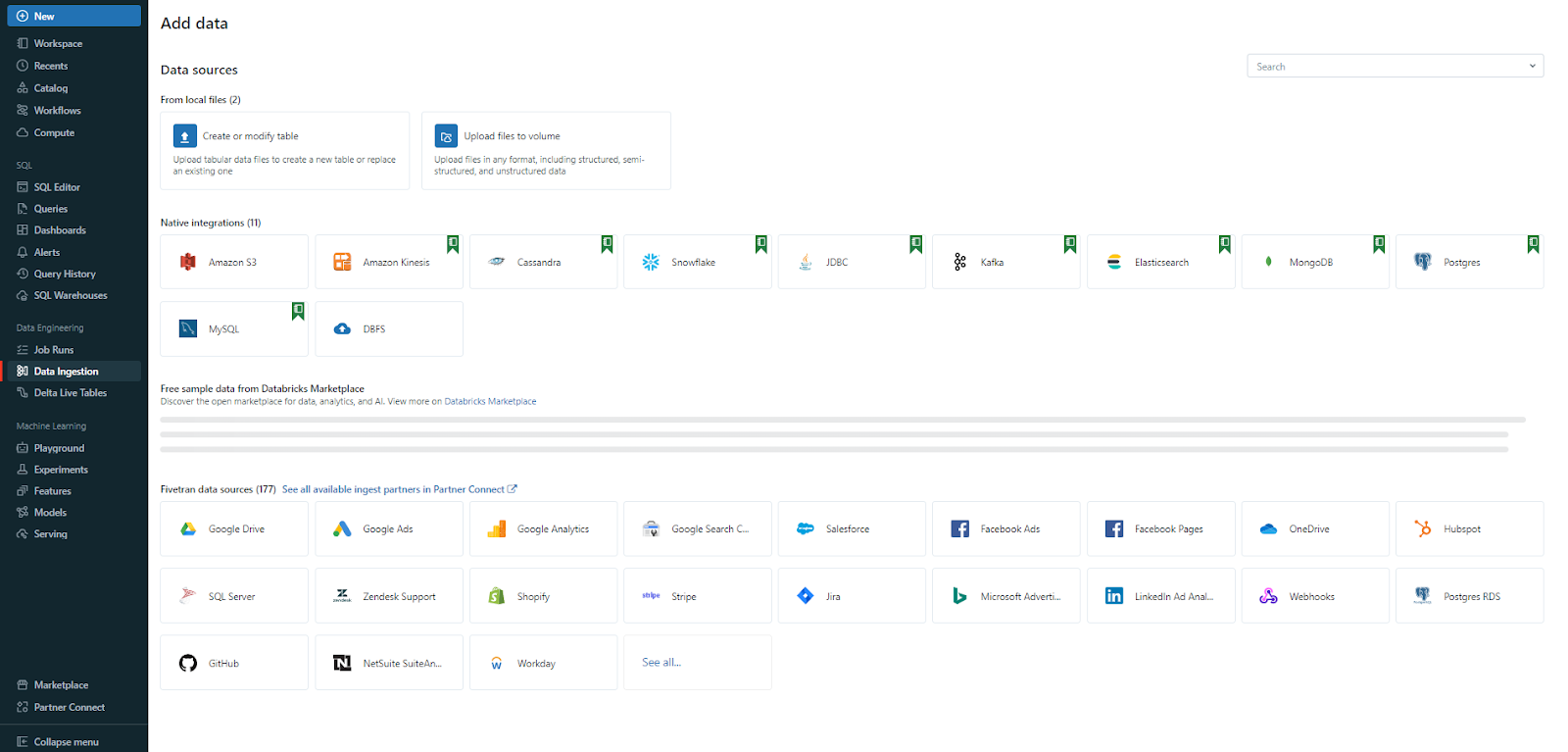
Step 2—Adding Data in Databricks
Now let's move on to the next step, where you have two choices: either use the sample dataset provided by Databricks or bring your own data by uploading it to Databricks. To upload it, head over to Data Ingestion, click on DBFS, and upload your dataset. For example, you can use a few sample datasets provided, which you can access through this GitHub link.
Step 3—Create a Table Using either Sample Datasets or Your Own Dataset
Create a table using either sample datasets or your own Dataset. To do so, execute the code mentioned below inside the SQL notebook.
CREATE TABLE IF NOT EXISTS demo_databricks_data_lake_people_10m
AS SELECT * FROM delta.`/databricks-datasets/learning-spark-v2/people/people-10m.delta`;
In Databricks notebooks, code is entered into cells and can be executed individually or collectively. The output is displayed sequentially, cell by cell.
As you can see, we created a new table called demo_databricks_data_lake_people_10m. It populates the table by selecting all data from the Delta Lake table and then copies the people sample dataset with 10 million rows into an SQL table for analysis. The table leverages Delta Lake for scalable and reliable storage.
Step 4—Selecting All the Record
To retrieve all the records, execute the command mentioned below.
SELECT * FROM demo_databricks_data_lake_people_10m;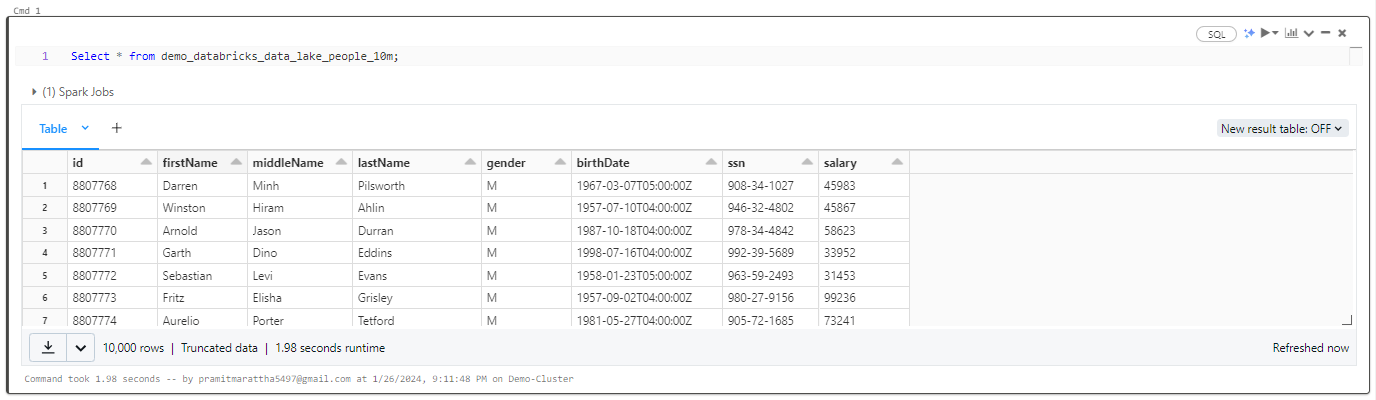
Here is another command to retrieve metadata information about a table's structure.
DESCRIBE demo_databricks_data_lake_people_10m;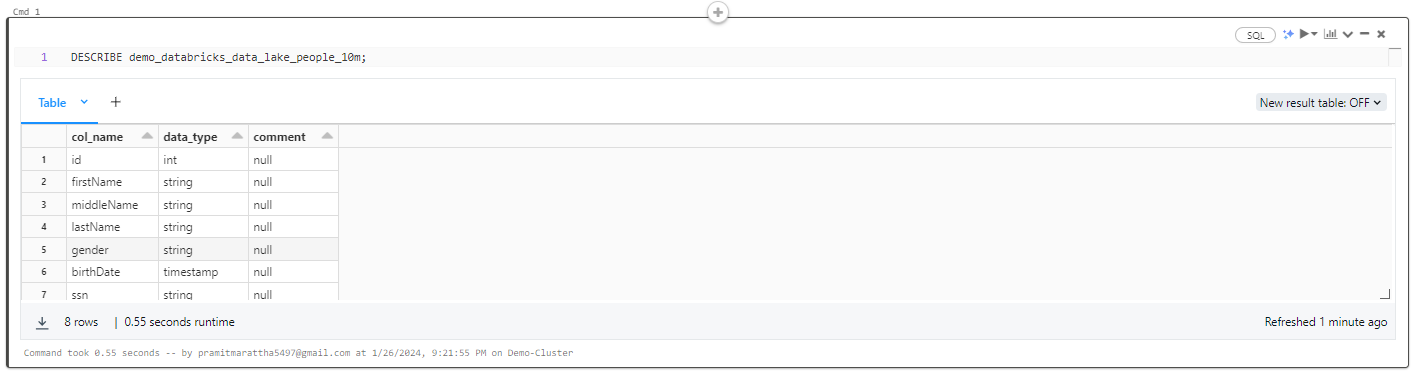
Step 5—Saving the File Into Delta
Suppose you have a CSV file to convert to a delta file. Databricks allows for easy conversion. The platform also supports Python, SQL, Scala, and R interchangeably within the same notebook. You can easily switch between multiple languages using simple magic commands.
%python
demo_databricks_data_lake_people_10m = spark.read.csv("/databricks-datasets/learning-spark-v2/people/people-10m.csv", header="true", inferSchema="true")
demo_databricks_data_lake_people_10m.write.format("delta").mode("overwrite").save("/delta/demoDatabricksPeople10m")You will see that the first block of code loads data from a CSV file located at /databricks-datasets/learning-spark-v2/people/people-10m.csv into a Spark DataFrame named demo_databricks_data_lake_people_10m.
It uses spark.read.csv() to read the CSV file, with the header set to true to treat the first row as column names and inferSchema set to true to automatically infer the DataFrame schema.
This creates a DataFrame containing the contents of the CSV file.
Next, the DataFrame is written out to a Delta Lake table using .write.format("delta").mode("overwrite") to overwrite any existing table. The Delta Lake table is saved to the location /delta/demoDatabricksPeople10m.
Now you can drop any existing table named demo_databricks_data_lake_people_10m” and then create a new Delta Lake table named “demoDatabricksPeople10m” using the data stored in the Delta Lake format at the “/delta/demoDatabricksPeople10m/” location.
DROP TABLE IF EXISTS demo_databricks_data_lake_people_10m;
CREATE TABLE demoDatabricksPeople10m USING DELTA LOCATION '/delta/demoDatabricksPeople10m'Now that we fully know how to create a Delta table in Databricks, let's now learn if Databricks Delta Lake supports DML statements.
The answer is yes! Databricks Delta Lake supports standard SQL DML commands such as SELECT, INSERT, UPDATE, DELETE, and MERGE for querying and manipulating data.
It also supports DDL commands like CREATE TABLE, ALTER TABLE, DROP TABLE, and TRUNCATE TABLE for creating, modifying, and deleting tables and schemas.
Step 6—Inserting Data Into Databricks Delta Table
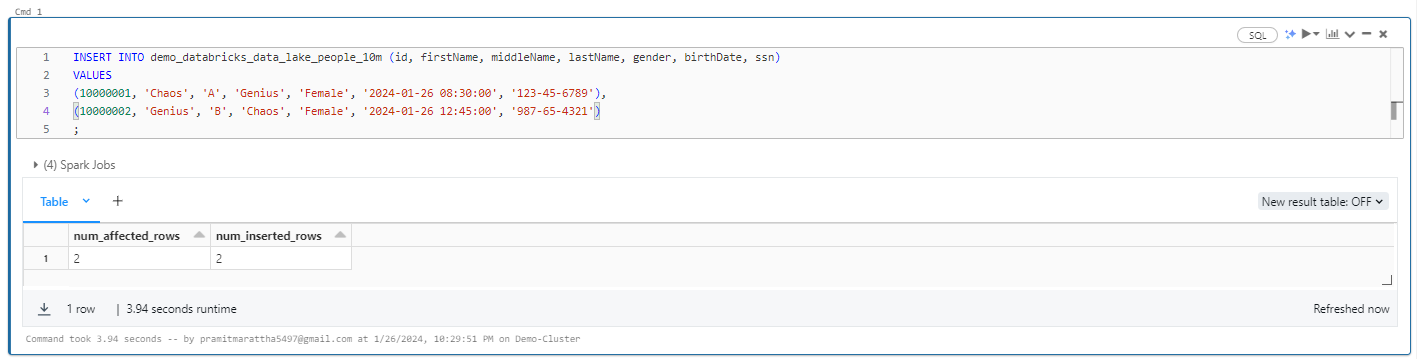
Now, let's explore how to insert data into a Databricks Delta table. Inserting data into a Delta table is similar to inserting data into any traditional database or data warehouse system. All you need to do is use the INSERT INTO command with the table name, its column names, and the values you want to insert.
INSERT INTO demo_databricks_data_lake_people_10m (id, firstName, middleName, lastName, gender, birthDate, ssn)
VALUES
(10000001, 'Chaos', 'A', 'Genius', 'Female', '2024-01-26 08:30:00', '123-45-6789'),
(10000002, 'Genius', 'B', 'Chaos', 'Female', '2024-01-26 12:45:00', '987-65-4321')
;
Step 7—Updating Data Into Databricks Delta Table
Now, let's delve into the process of updating data in a Databricks Delta table. The procedure is similar to updating data in traditional databases or data warehouse systems. To accomplish this, utilize the UPDATE command, specifying the table name, the column to be updated, the desired value, and the unique identifier for the target row.
UPDATE demo_databricks_data_lake_people_10m SET ssn = '456-41115-489' WHERE id = 10000001;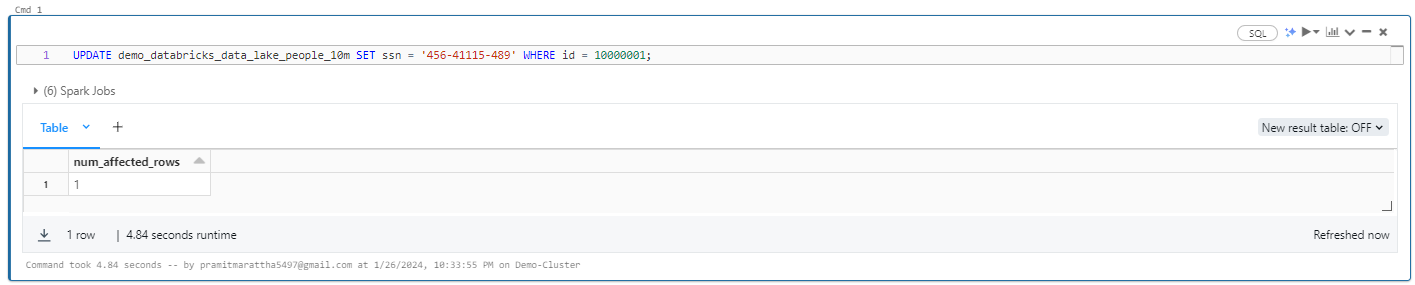
SELECT * FROM demo_databricks_data_lake_people_10m WHERE id = 10000001; 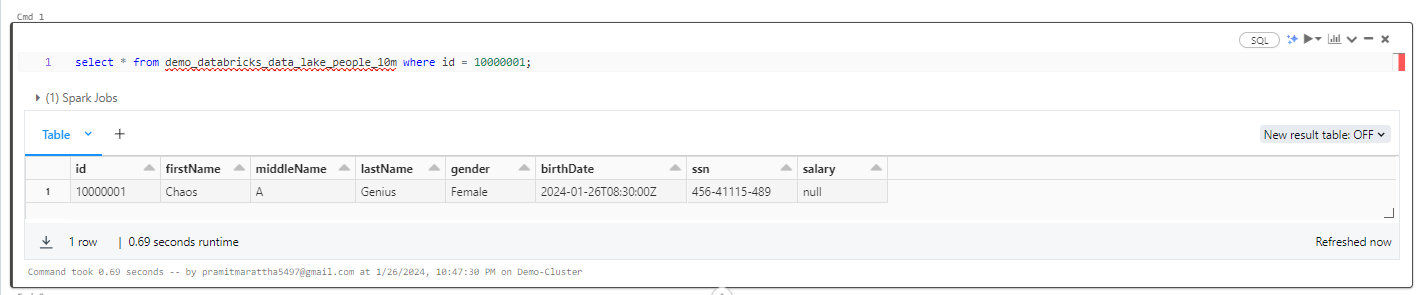
Step 8—Deleting Data Into Databricks Delta Table
Now, let's delve into the process of updating data in a Databricks Delta table. The procedure is similar to deleting data in traditional databases or data warehouse systems. To do this, use the DELETE command.
DELETE FROM demo_databricks_data_lake_people_10m WHERE id = 10000001;
Step 9—Upserting Data Into Databricks Delta Table
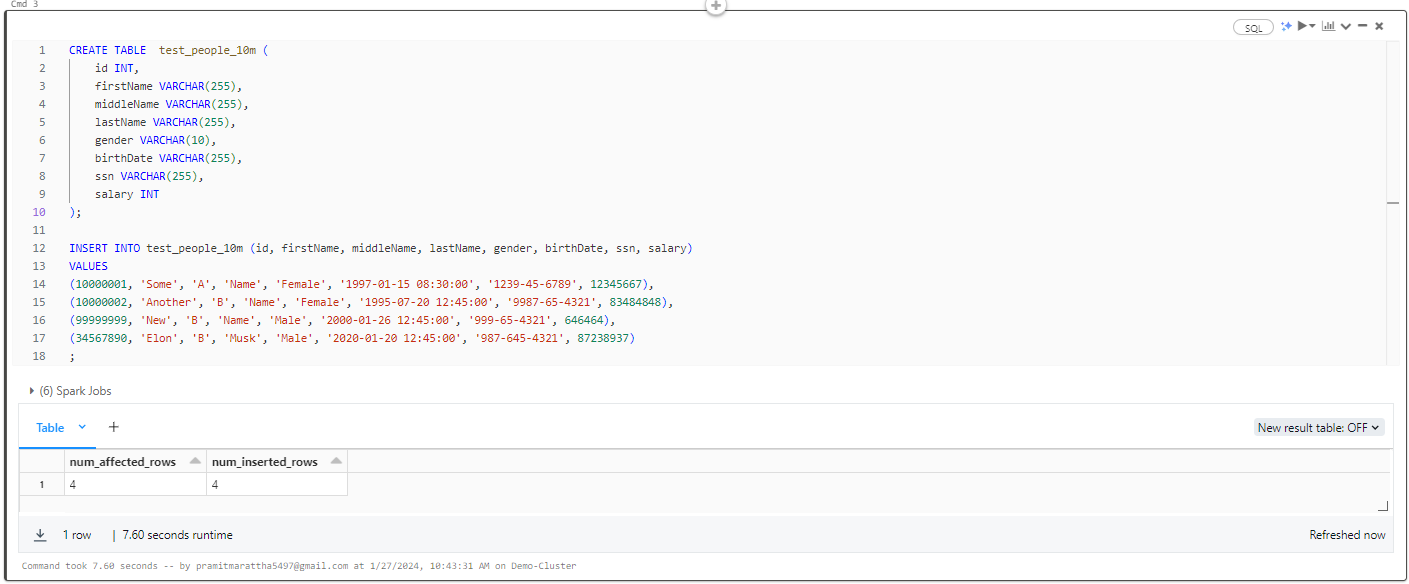
Now, let's perform an upsert operation, which essentially combines insert and update operations on a table. First, we'll create a table named 'test_people_10m' and insert some dummy data. During the insertion, we'll include two values with IDs that already exist in the main table and two values with different and unique ID values. The expected outcome is that the entry with the same ID as the main table will get updated, while the one with a unique ID will be inserted.
CREATE TABLE test_people_10m (
id INT,
firstName VARCHAR(255),
middleName VARCHAR(255),
lastName VARCHAR(255),
gender VARCHAR(10),
birthDate VARCHAR(255),
ssn VARCHAR(255),
salary INT
);
INSERT INTO test_people_10m (id, firstName, middleName, lastName, gender, birthDate, ssn, salary)
VALUES
(10000001, 'Some', 'A', 'Name', 'Female', '1997-01-15 08:30:00', '1239-45-6789', 12345667),
(10000002, 'Another', 'B', 'Name', 'Female', '1995-07-20 12:45:00', '9987-65-4321', 83484848),
(99999999, 'New', 'B', 'Name', 'Male', '2000-01-26 12:45:00', '999-65-4321', 646464),
(34567890, 'Elon', 'B', 'Musk', 'Male', '2020-01-20 12:45:00', '987-645-4321', 87238937)
;
SELECT * FROM test_people_10m;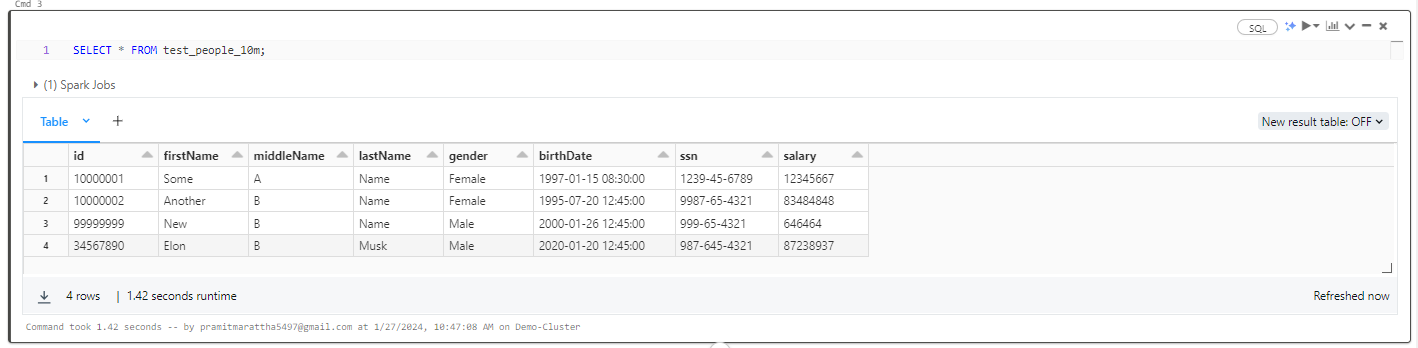
Now, let's execute the UPSERT operation based on matching column and row criteria from the “test_people_10m” table to the “demo_databricks_data_lake_people_10m” table. If a match is identified, the record will be updated; otherwise, it will be inserted.
MERGE INTO demo_databricks_data_lake_people_10m as main USING test_people_10m as test
ON main.id = test.id
WHEN MATCHED THEN
UPDATE SET *
WHEN NOT MATCHED
THEN INSERT * ;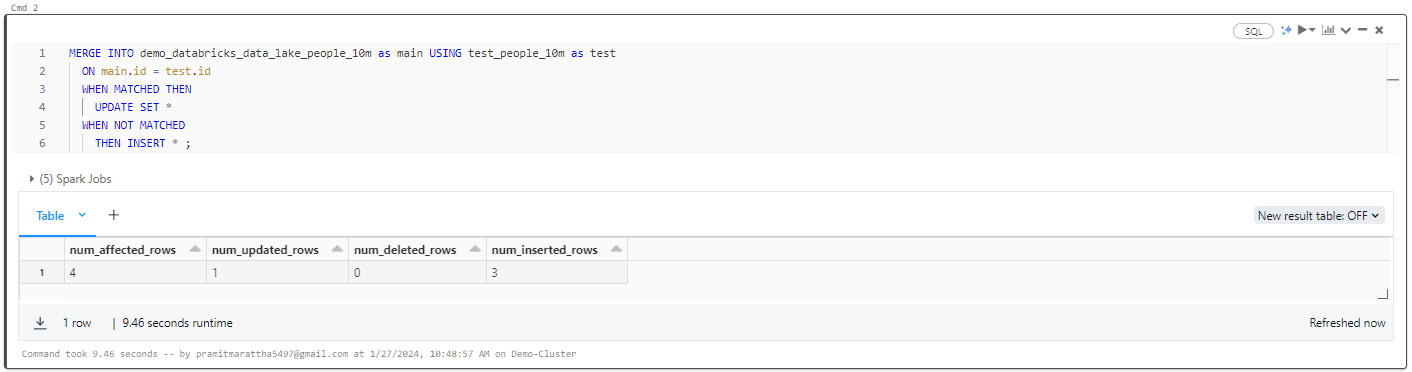
SELECT * FROM demo_databricks_data_lake_people_10m where id in (10000001, 10000002, 99999999, 34567890);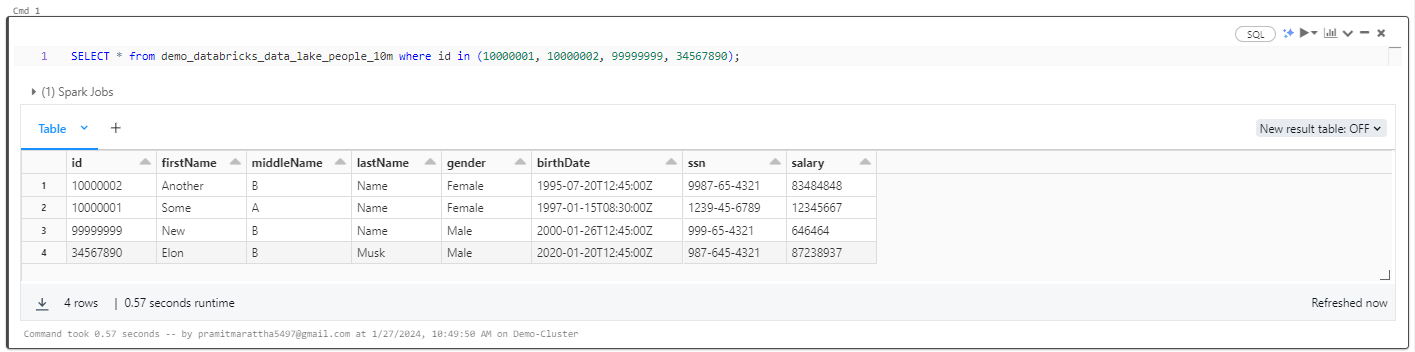
Step 10—Visualizing Data in Delta
Databricks Delta Lake allows you to leverage SQL queries to gain insights from data without requiring complex programming. Here are some effective techniques to visualize data in Databricks Delta Lake:
- Using simple SELECT statements to retrieve specific columns and filter rows using WHERE clauses provides an initial overview.
- Using Aggregate functions like COUNT, SUM, AVG, MIN, and MAX summarize data through operations like counting records, calculating averages, and finding extremes.
- Using GROUP BY clauses, group data by columns and apply aggregates to each group, enabling category-wise analysis and insight generation.
- Using Ranking window functions like ROW_NUMBER, RANK, and DENSE_RANK partitions data into logical windows and calculates rankings or running totals within them, facilitating more granular discovery of patterns.
- Using joins merge related data from multiple tables using techniques like INNER JOIN, enabling cross-table analysis and advanced visualizations.
- Using Subqueries and Common Table Expressions (CTEs) decompose complex queries into manageable parts, simplifying analysis through modularization.
- Using CASE statements aids in custom data labeling or grouping for visualization by conditionally categorizing rows.
Through these SQL constructs, valuable visualizations and visual data summaries can be extracted from Databricks Delta Lake for insightful decision-making.
To visualize the data, you can use any of the techniques mentioned above. Let's explore an example using the COUNT aggregate function for each gender, presenting the results in descending order.
SELECT gender, COUNT(*) AS count
FROM demo_databricks_data_lake_people_10m
GROUP BY gender
ORDER BY count DESC;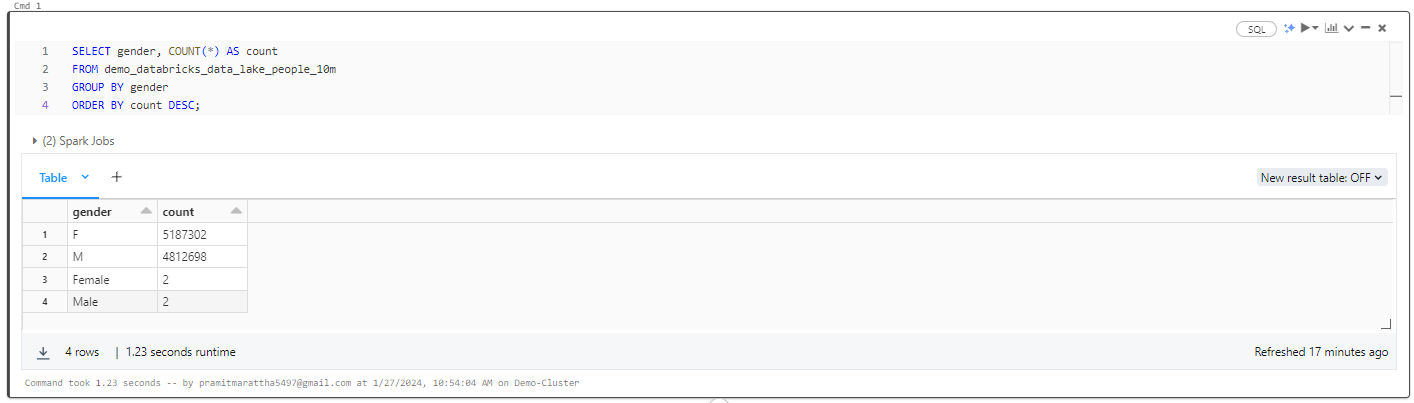
As you can see, this query selects the gender column and utilizes the COUNT() function to determine the occurrences for each clarity value. The resulting set is grouped by gender and sorted in descending order based on the count of all 10 million people.
To visualize the data, click on the "+" button next to the table. A dropdown will appear, and you should find the visualization option. Click on it.
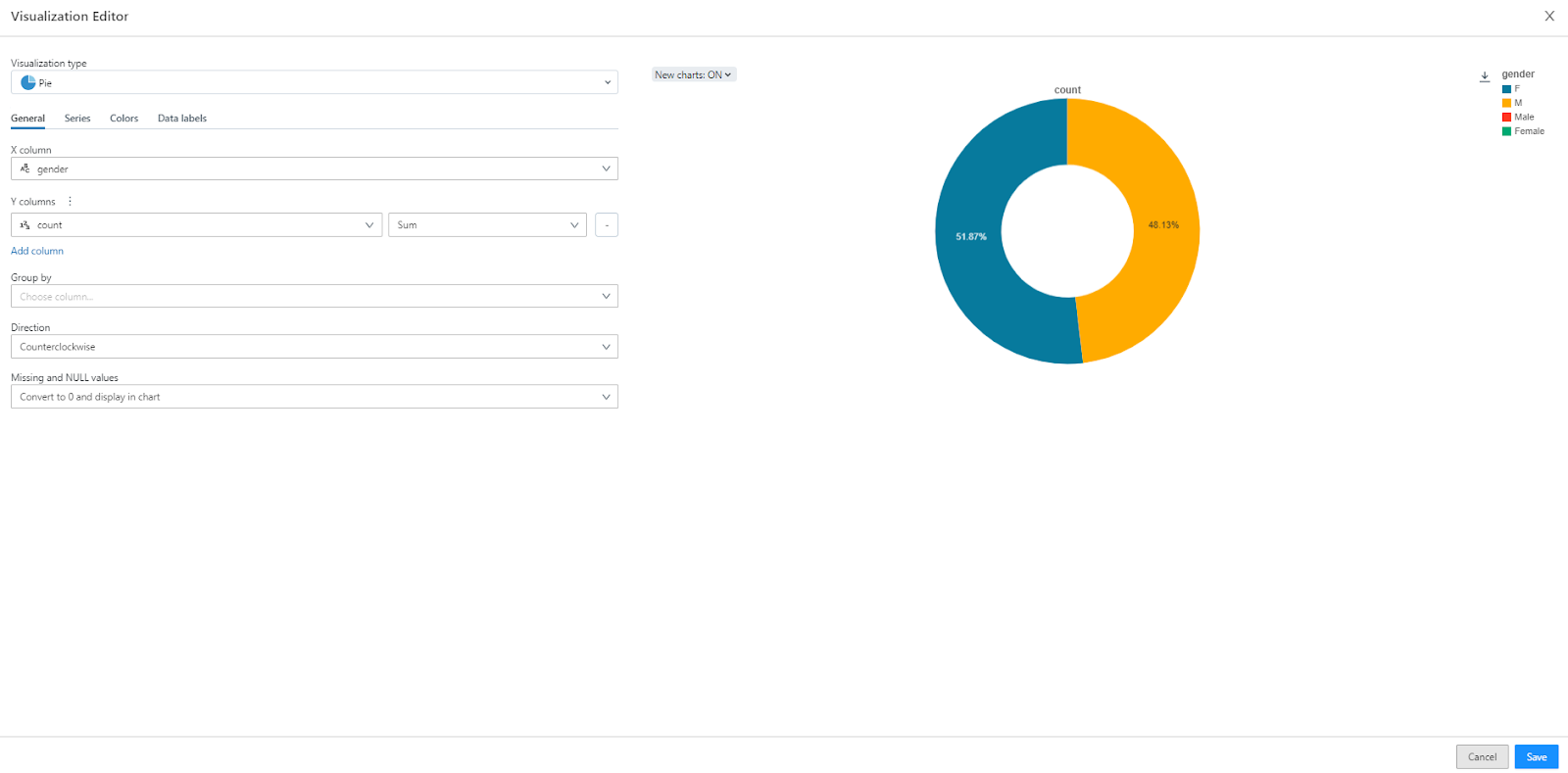
Now, the visualization editor will open, and the visualization will be generated based on the query. All you need to do is tweak it, choose any visualization type, and experiment with different settings.
Step 11—Version Control and Time Travel in Databricks Delta Table
Databricks Delta makes it easy to create data pipelines with its time travel capabilities. This feature proves useful for tasks like auditing data changes, reproducing experiments and reports, or rolling back database transactions. It's also valuable for disaster recovery, enabling us to revert changes and go back to any specific version of a database.
Whenever you write to a Delta table or directory, each operation is automatically versioned. You can query a table by specifying a timestamp or a version number.
For example, the following command provides a list of all versions and timestamps in a table named “demo_databricks_data_lake_people_10m”
DESCRIBE HISTORY demo_databricks_data_lake_people_10m;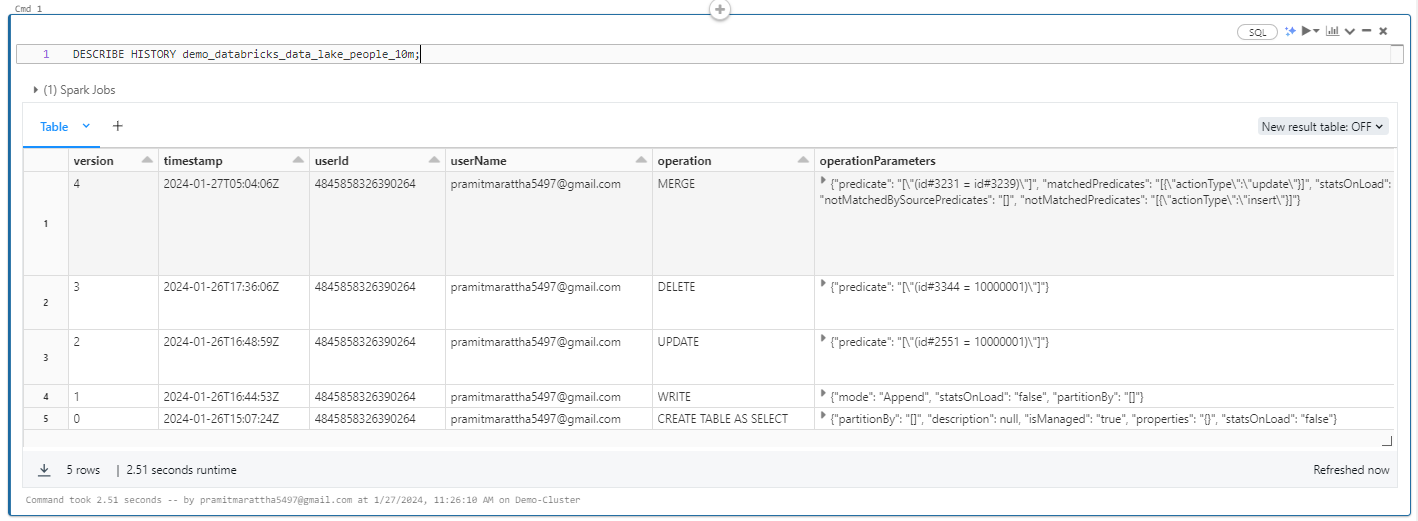
Databricks Delta offers native support for backup and restore strategies to manage challenges such as data corruption or accidental data loss. In this example, we'll deliberately delete 30 rows from the primary table to simulate these scenarios.
Next, we'll utilize Delta's restore functionality to roll back the table to a point in time preceding the delete operation. This process allows us to verify the success of the deletion or the accurate restoration of data to its previous state. Such features guarantee data integrity and offer a convenient method to recover from unwanted alterations or system failures.
Let's delete some tables, but first, let's count the number of records present in our table!
SELECT COUNT(*) FROM demo_databricks_data_lake_people_10m;
Let's delete some tables!
DELETE FROM demo_databricks_data_lake_people_10m where id in (1, 2, 3, 4, 5,6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30);
If you count all the records again, you will see that all 30 records have been deleted from the table.
SELECT COUNT(*) from demo_databricks_data_lake_people_10m;
If you select all the records from the previous version, you will see that all 30 records are there.
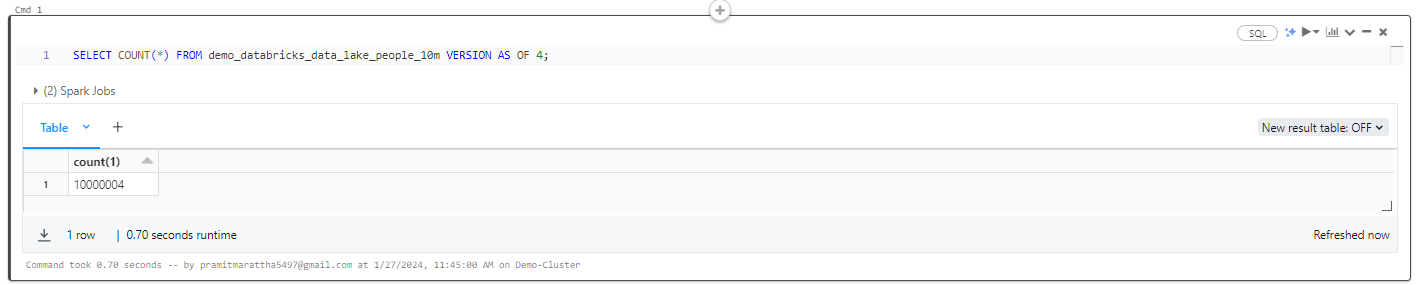
To restore the table version, simply execute the RESTORE command with the table name and specify the version number corresponding to the point in time you want to restore the table. And there you go, it's done!
Note: You can check the version of the table by executing DESCRIBE HISTORY command
RESTORE TABLE demo_databricks_data_lake_people_10m TO VERSION AS OF 4;
Boom! You have effectively restored the records of the table to that specific version.
Now, let's move on to the process of actually cloning the Databricks Delta table.
Step 12—Databricks Delta Table Cloning for Efficient Data Management
Databricks Delta Lake provides native support for cloning existing Delta tables. Cloning creates a replica of a table's metadata and optionally its data at a specific version. This enables use cases like staging data transfers between environments and archiving table versions.
There are two types of clones:
1) Deep Clone
Deep Clone in Databricks creates a completely independent copy of the table data and metadata. The clone is fully detached from the source table.
CREATE TABLE IF NOT EXISTS deep_clone_demo_databricks_data_lake_people_10m
DEEP CLONE demo_databricks_data_lake_people_10m;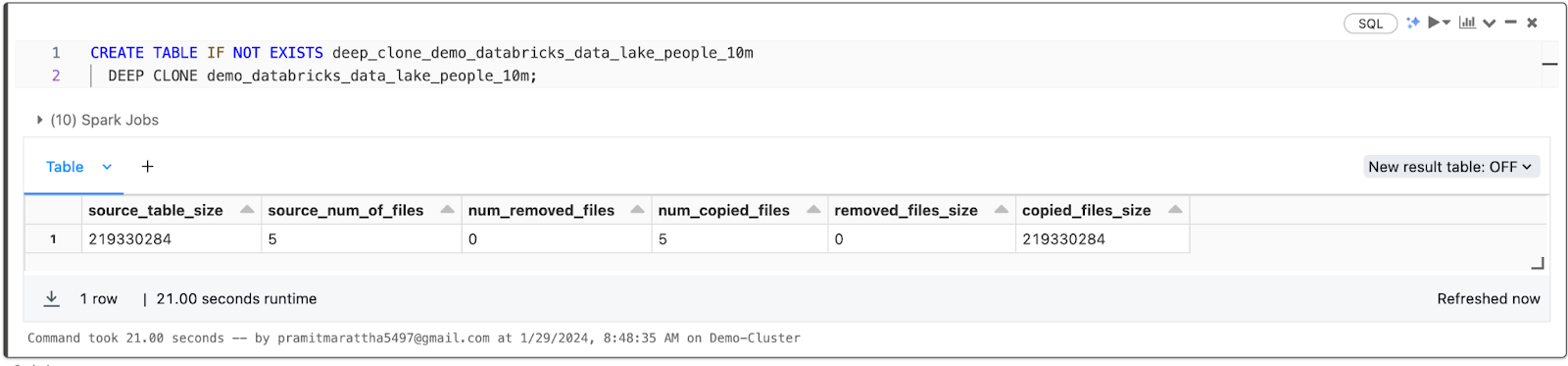
SELECT * FROM deep_clone_demo_databricks_data_lake_people_10m;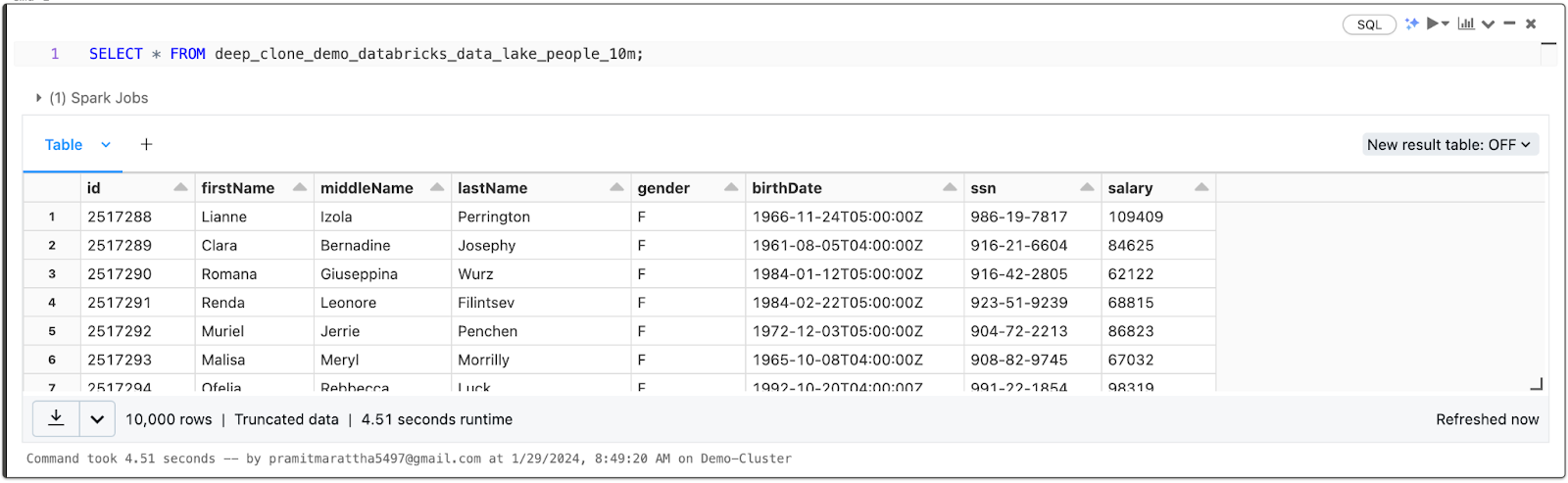
SELECT COUNT(*) FROM deep_clone_demo_databricks_data_lake_people_10m;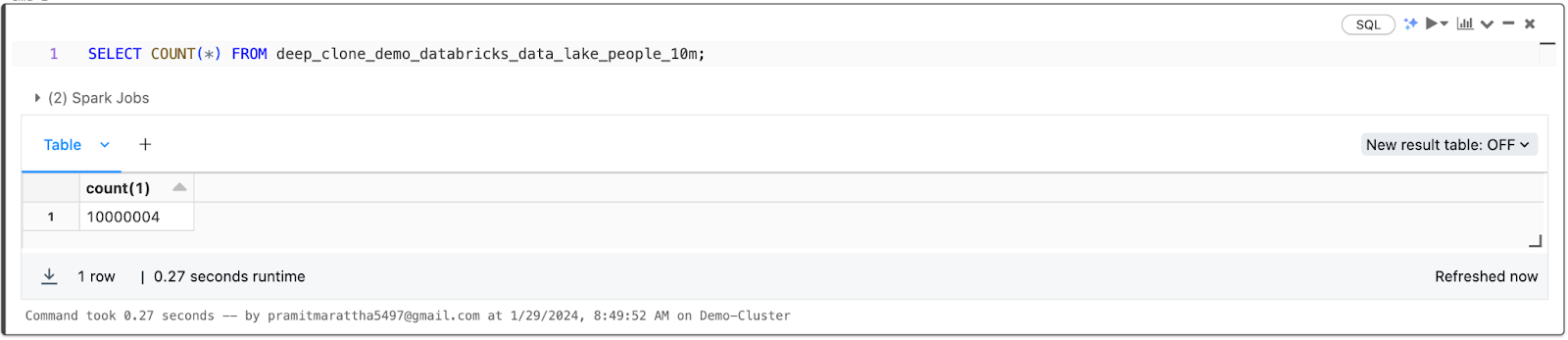
2) Shallow Clone
Shallow Copy Clone in Databricks only copies the table schema/metadata without copying the actual data files to the clone target. Shallow clones act as pointers to the source table data. These types of clones are cheaper to create.
Note: If you run vacuum on the source table, clients can no longer read the referenced data files and a FileNotFoundException is thrown. In this case, running clone with replace over the shallow clone repairs the clone. If this occurs often, consider using a deep clone instead which does not depend on the source table.
CREATE TABLE IF NOT EXISTS shallow_clone_demo_databricks_data_lake_people_10m
SHALLOW CLONE demo_databricks_data_lake_people_10m
VERSION AS OF 4;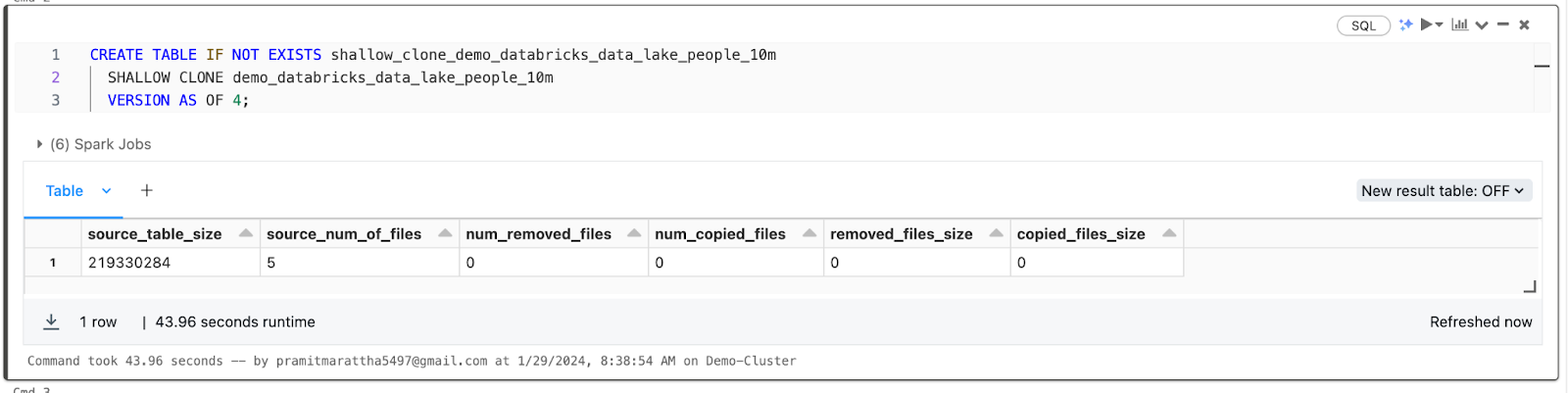
SELECT * FROM shallow_clone_demo_databricks_data_lake_people_10m;
SELECT COUNT(*) FROM shallow_clone_demo_databricks_data_lake_people_10m;
Now, you should have a good grasp of what a Databricks Delta Table is and a solid understanding of the capabilities and features it offers in Databricks Delta Lake.
Conclusion
And that’s a wrap! Databricks offers a managed Apache Spark platform to easily process large amounts of data at scale. Traditionally, raw data is stored in flexible but unreliable data lakes. This is where Databricks Delta Lake comes in—an open source storage layer that brings reliability to data lakes through ACID transactions, schema enforcement, and versioning. Delta Lake enables traditional database capabilities like querying, updating, deleting, and merging directly on data lake storage.
In this article, we have covered:
- What is Databricks?
- What is Data Lake?
- What is Delta Lake?
- Benefits and Use Cases of Databricks Delta Lake
- Platform Supported by Delta Lake
- Step-By-Step Guide on Getting Started with Databricks Delta Lake
…and so much more!
FAQs
What is Databricks Delta Lake?
Databricks Delta Lake is an open source storage layer that brings reliability, ACID transactions, and performance to data lakes built on top of cloud object stores like S3, ADLS, GCS, etc.
What are the key features of Databricks Delta Lake?
The key features of Delta Lake include ACID transactions, schema enforcement, data versioning, time travel, unified batch and streaming sources, and scalable metadata handling.
What are the components of Databricks Delta Lake architecture?
Main components of Delta Lake are Delta Tables, Delta Log, and Object Storage Layer. Delta Tables stores data, Delta Log records transactions, and Object Storage handles storage in cloud stores.
What benefits does Databricks Delta Lake provide?
Delta Lake provides benefits like data reliability, ACID compliance, faster performance, data integrity, metadata handling, time travel for auditability, and security.
What platforms support Databricks Delta Lake?
Delta Lake is supported natively on Databricks and across various platforms like Snowflake, Redshift, Synapse, Apache Spark, Trino, Apache Hive, etc.
How does Databricks Delta Lake bring ACID transactions to data lakes?
Delta Lake uses a transaction log to provide atomicity, consistency, isolation, and durability. All changes are recorded to support ACID properties.
How does Databricks Delta Lake handle schema changes and evolution?
Delta Lake automatically tracks schema changes and table metadata. New columns can be added without affecting existing queries.
How does Databricks Delta Lake enable time travel on Data Lakes?
Delta Lake snapshots table versions on writes. Users can query by time or version number to access older table data.
What operations does Databricks Delta Lake support?
Databricks Delta Lake supports standard DML operations like SELECT, INSERT, UPDATE, DELETE, and MERGE, as well as DDL operations.
How to insert data into a Databricks Delta Lake table?
Use standard INSERT statements. Data will be written to cloud storage and changes recorded in the Delta log.
How to update data in a Databricks Delta Lake table?
You can use UPDATE statement to modify data, like in traditional databases. Changes are logged in the Delta log.
How does Databricks Delta Lake handle streaming data?
Delta Lake provides a unified batch and streaming API. Streaming data can be ingested using the same constructs as batch data.
How to convert CSV data into Delta format?
Read CSV into a DataFrame using Spark, then write the DataFrame into Delta format using .format("delta")
What is Delta Sharing?
Delta Sharing is an open protocol to securely share Delta tables across organizations without data replication.
How can we visualize data in Databricks Delta Lake?
Use standard SQL queries with aggregation functions like COUNT, MAX, AVG, etc, and JOINs to prepare data for visualization.
How does Databricks Delta Lake support version control and time travel?
All writes are versioned automatically. Users can query by time or version number to access older table snapshots.
How can we roll back changes in Databricks Delta Lake?
You can use the RESTORE command to revert a table to an older version based on timestamp or version number.
Does Databricks Delta Lake support DML and DDL operations?
Yes, Delta Lake supports standard data manipulation (DML) and data definition (DDL) operations.
How does Databricks Delta Lake improve performance?
Techniques like data skipping, indexing, caching, and query optimization are used to improve performance.
What programming languages can we use with Databricks Delta Lake?
Delta Lake supports Scala, Python, R, Java, and SQL for development.















