


























Data is all around us and plays a huge role in our daily lives in countless ways. With so much data and information floating around, it's really important to keep data safe, accurate, and well-organized. That's where data governance comes in! It's basically about setting up guidelines and using the right tools to make sure data is secure, accurate, and well-organized throughout its lifecycle, which involves keeping an eye on who can access the data, understanding where it comes from, and making sure it's protected. To lend a hand with all this, Databricks created Unity Catalog—a unified governance layer for data and AI within the Databricks platform. It lets users and organizations keep everything in one place, from structured and unstructured data to ML models, notebooks, dashboards, and files, all while working across any cloud or platform.
In this article, we will cover everything about Databricks Unity Catalog, its architecture, features, and best practices for effective data governance within Databricks platform. Plus, we've got you covered with a simple step-by-step guide to set up and manage Unity Catalog with ease.
What Is the Unity Catalog in Databricks?
Databricks announced Unity Catalog at the Data and AI Summit in 2021 to address the complexities of data governance by providing fine-grained access control within the Databricks ecosystem. Before Databricks Unity Catalog, data governance in Databricks was typically handled by various third party and open source tools, which, while effective, often lacked seamless integration with the Databricks ecosystem. These tools often lacked the integration and granular security controls specifically tailored for data lakes and were sometimes limited to certain cloud platforms. This limitation highlighted the need for a data governance solution that could provide more fine-grained access control and work across different cloud platforms while integrating seamlessly with the Databricks ecosystem. Thus, Databricks Unity Catalog was born to exactly address these challenges.
Databricks Unity Catalog serves as a centralized governance layer within the Databricks Data Intelligence Platform, streamlining the management and security of various data and AI assets. It supports a wide range of assets including files, tables, machine learning models, notebooks, and dashboards. Unity Catalog uniquely identifies each asset type, simplifying access control and ensuring that only authorized users can interact with specific data elements.
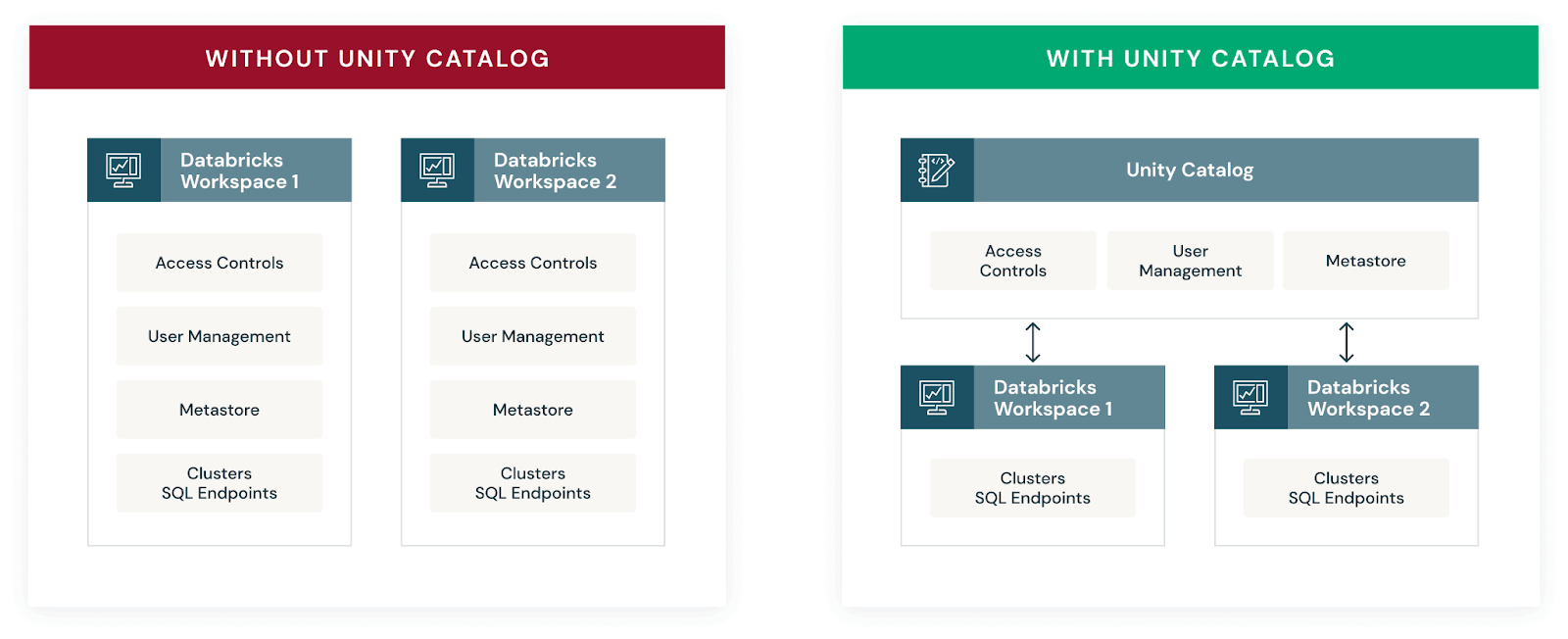
Now, If you’re transitioning from Hive metastore to Databricks Unity Catalog, rest assured that the Databricks Unity Catalog enhances the Hive metastore experience. It not only supports the same functionalities but also introduces advanced governance features. Unity Catalog enables fine-grained access control, allowing you to designate column-level permissions to safeguard sensitive data, such as Personally Identifiable Information (PII). Also, it provides visibility into data lineage, tracing the flow and transformation of your data across different processes.
But that's not all! Databricks Unity Catalog also allows you to share selected tables across different platforms and clouds using Delta sharing.
Key features and benefits of Databricks Unity Catalog:
- Define once, secure everywhere: Databricks Unity Catalog offers a single place to administer data access policies that apply across all workspaces and user personas, ensuring consistent governance.
- Standards-compliant security model: Databricks Unity Catalog's security model is based on standard ANSI SQL, allowing administrators to grant permissions using familiar syntax at various levels (catalogs, schemas, tables, and views).
- Built-in auditing and lineage: Databricks Unity Catalog automatically captures user-level audit logs and data lineage, tracking data access and usage patterns for compliance and troubleshooting purposes.
- Data discovery: Databricks Unity Catalog enables tagging and documenting data assets, providing a search interface to help users easily find and understand the data they need.
- System tables (Public Preview): Databricks Unity Catalog provides access to operational data, including audit logs, billable usage, and lineage, through system tables.
- Managed storage: Databricks Unity Catalog supports managed storage locations at the metastore, catalog, or schema levels, enabling organizations to isolate data physically in their cloud storage based on governance requirements.
- External data access: Databricks Unity Catalog allows registering and governing access to external data sources, such as cloud object storage, databases, and data lakes, through external locations and Lakehouse Federation.
Source: Databricks
Databricks Unity Catalog Architecture Breakdown
Here’s an architecture breakdown of Databricks Unity Catalog:
1) Unified Governance Layer
Databricks Unity Catalog offers a unified governance layer for both structured and unstructured data, tables, machine learning models, notebooks, dashboards and files across any cloud or platform. This layer enables organizations to govern their data and AI assets seamlessly, ensuring regulatory compliance and accelerating data initiatives.
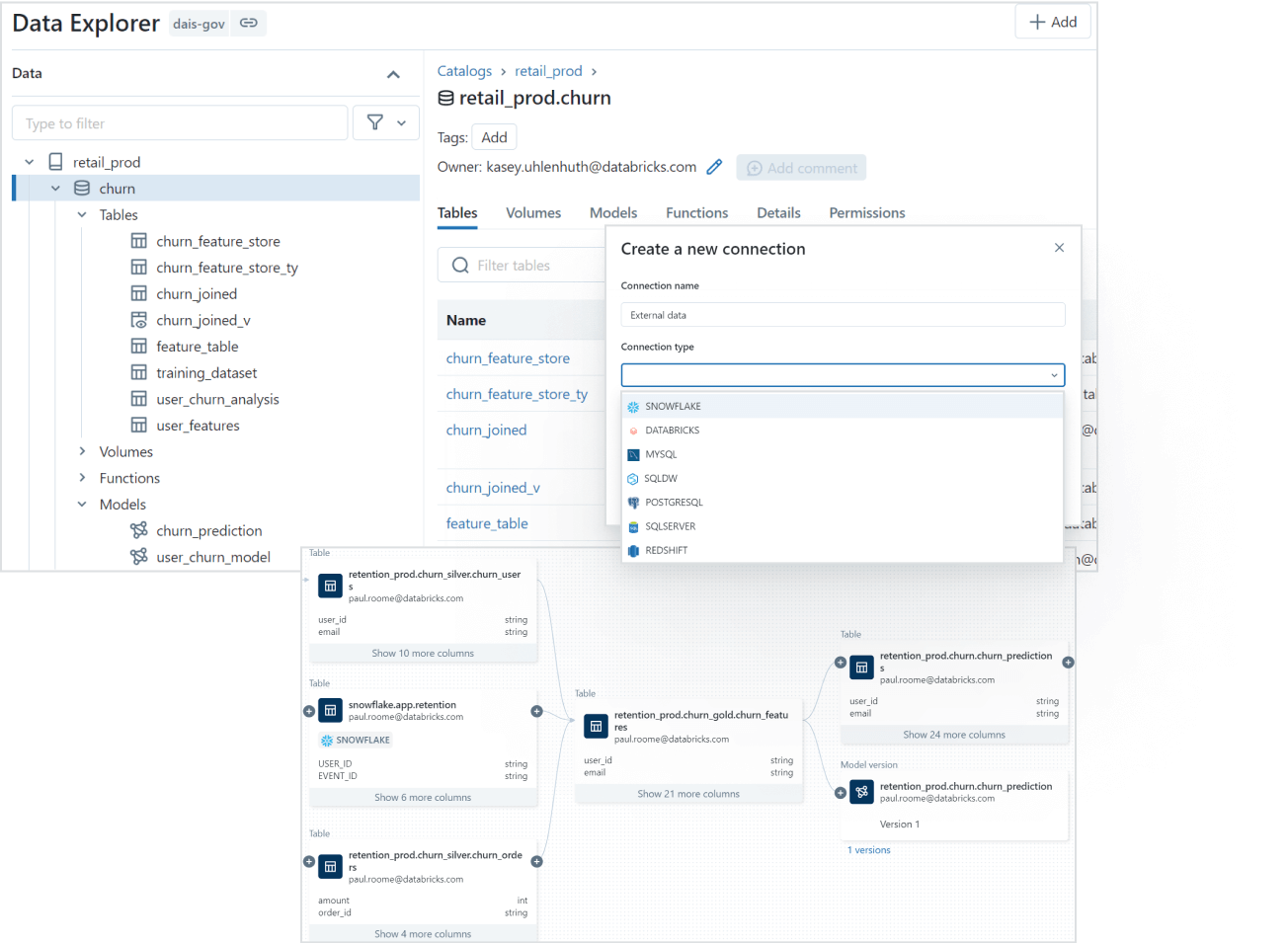
2) Data Discovery
Finding the right data for your needs is simple with Databricks Unity Catalog's discovery features. You can tag and document your data assets, and then use the search interface to locate the specific data you need based on keywords, tags, or other metadata.
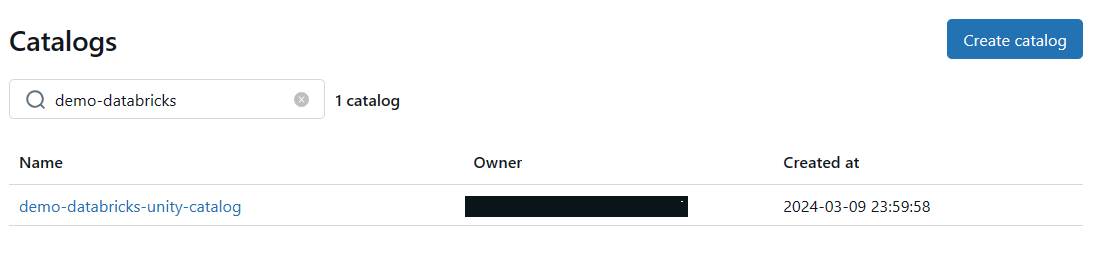
3) Access Control and Security
Databricks Unity Catalog simplifies access management by providing a single interface to define access policies on data and AI assets. It supports fine-grained control on rows and columns and manages access through low-code attribute-based access policies that scale seamlessly across different clouds and platforms.
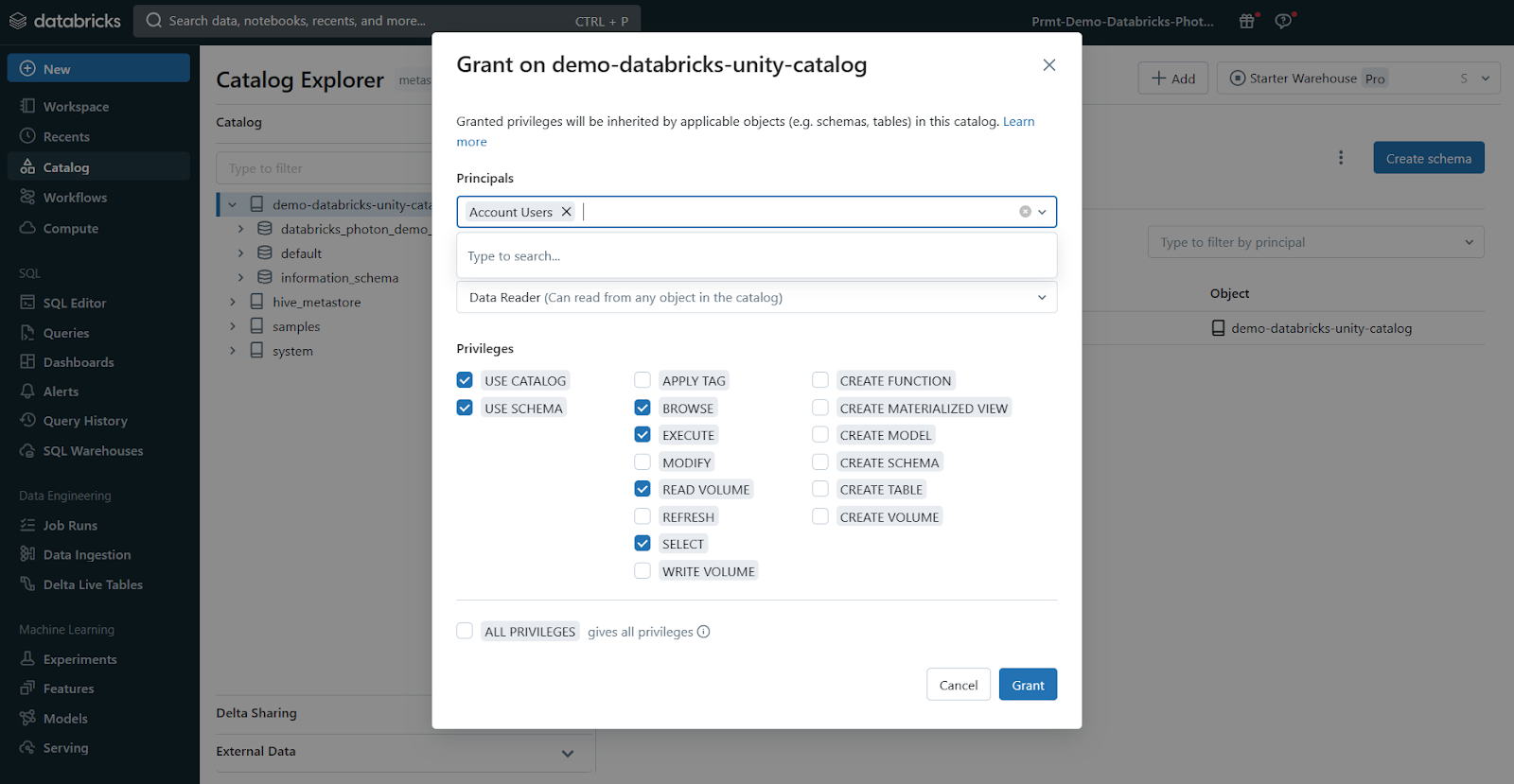
4) Auditing and Lineage
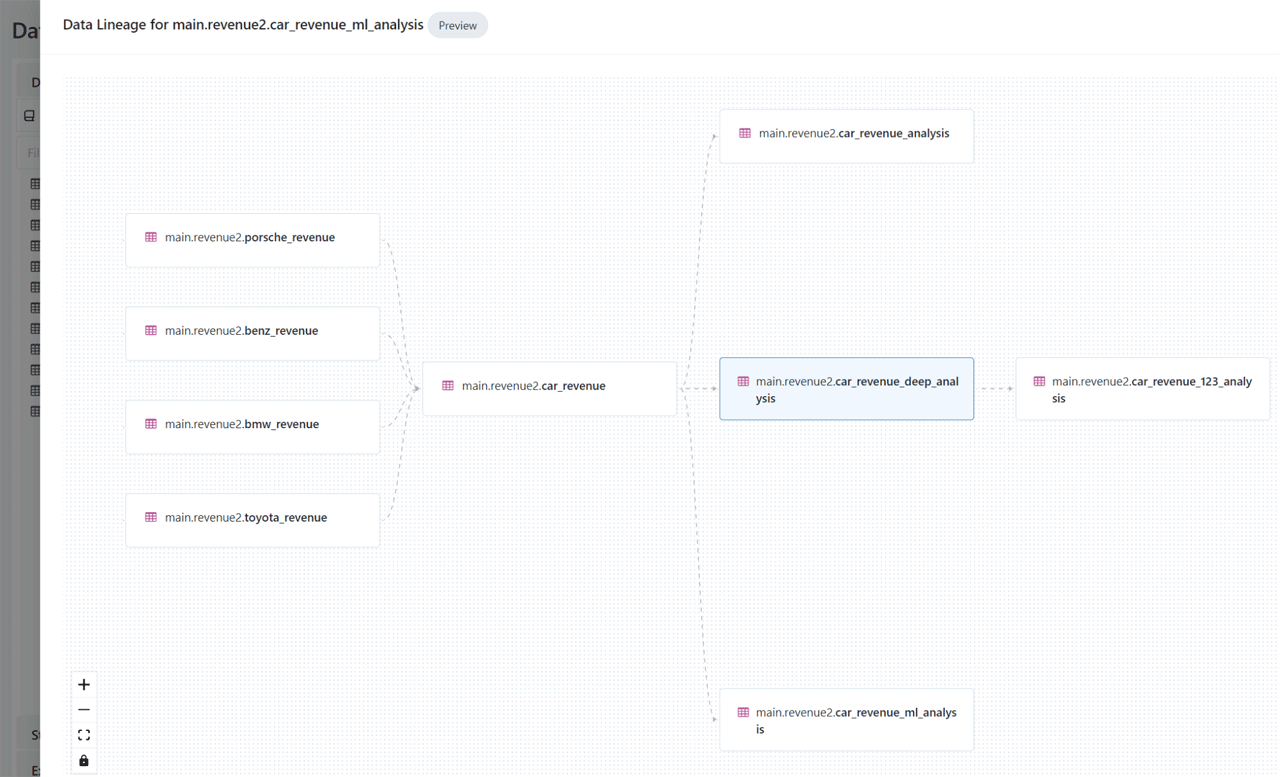
Databricks Unity Catalog automatically captures audit logs that record who accessed which data assets and when. It also tracks the lineage of your data, so you can see how assets were created and how they're being used across different languages and workflows. This lineage information is crucial for understanding data flows and dependencies.
5) Open Data Sharing
Databricks Unity Catalog integrates with open source Delta Sharing, which allows you to securely share data and AI assets across clouds, regions, and platforms without relying on proprietary formats or complex ETL processes.

6) Object Model
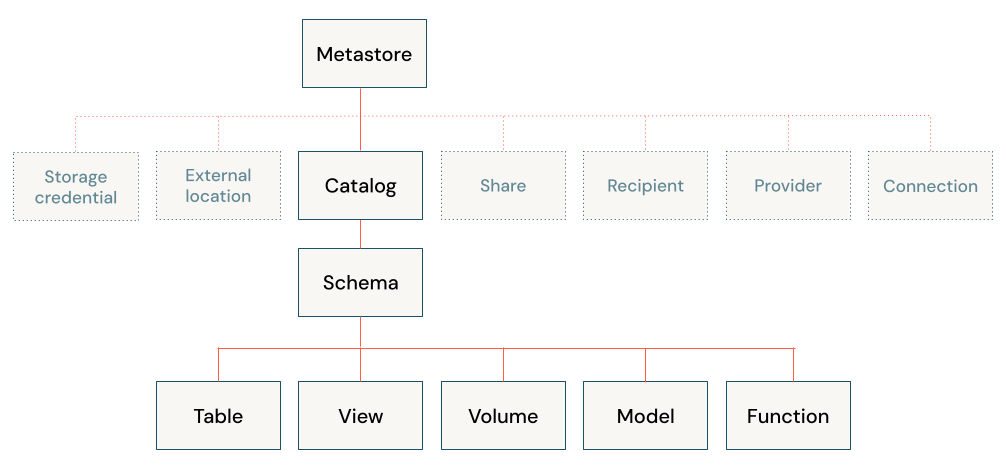
Databricks Unity Catalog organizes your data and AI assets into a hierarchical structure: Metastore ► Catalog ► Schema ► Tables, Views, Volumes, and Models. At the top level, you have the metastore, which contains your schemas. Within each schema, you can have tables, views, or volumes (for unstructured data). To reference any asset, you use a three-part naming convention: <catalog>.<schema>.<asset>. We will dive deeper into the object model in Unity Catalog in next section
7) Operational Intelligence
Databricks Unity Catalog provides AI-powered monitoring and observability capabilities that give you deep insights into your data and AI assets. You can set up active alerts, track data lineage at the column level, and gain comprehensive visibility into how your assets are being used and managed.
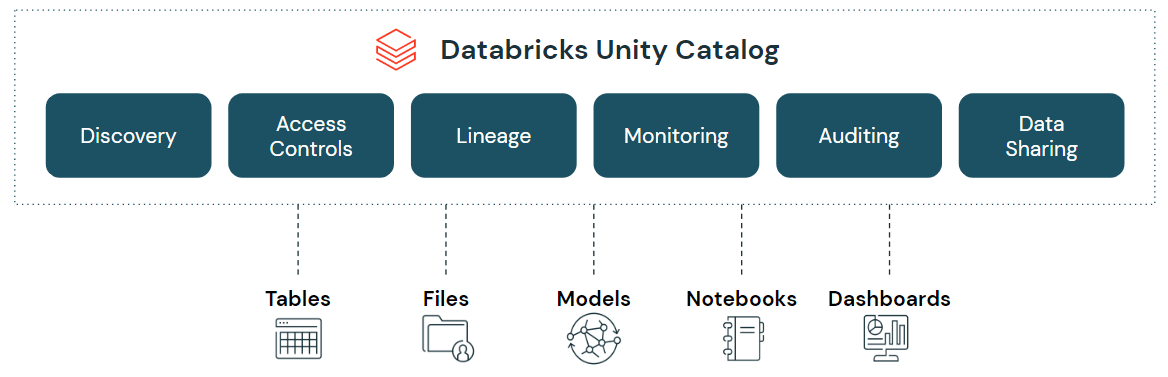
Databricks Unity Catalog (Source: databricks.com)
Databricks Unity Catalog Object Model
Databricks Unity Catalog follows a hierarchical architecture with the following components: Metastore ► Catalog ► Schema ► Tables, Views, Volumes, and Models.
- Metastore: The top-level container for metadata, exposing a three-level namespace (catalog.schema.table) to organize data assets.
- Catalog: The first layer of the object hierarchy, used to organize data assets logically, often aligned with organizational units or data domains.
- Schema: Also known as databases, schemas are the second layer of the object hierarchy, containing tables, views, and volumes.
- Tables, Views, and Volumes: The lowest level in the data object hierarchy, where:
- Table: A structured data asset that represents a collection of rows with a defined schema.
- View: A virtual table that is defined by a query.
- Volume: A container for unstructured (non-tabular) data files.
- Models: Machine learning models registered in the MLflow Model Registry can also be managed within Databricks Unity Catalog.
What Are the Supported Compute and Cluster Access Modes of Databricks Unity Catalog?
To fully leverage the capabilities of Unity Catalog, clusters must operate on compatible Databricks Runtime versions and be configured with appropriate access modes.
Databricks Unity Catalog is supported on clusters running Databricks Runtime 11.3 LTS or later. All SQL warehouse compute versions inherently support Unity Catalog, ensuring seamless integration with the latest data governance features. Clusters running on earlier Databricks Runtime versions may not provide support for all Databricks Unity Catalog features and functionality.
Unity Catalog is secure by default, meaning that if a cluster is not configured with one of the Unity Catalog-capable access modes, it cannot access data in Unity Catalog. Not all access modes are compatible with Unity Catalog. Here's a breakdown of the supported modes:
Supported Access Modes:
- Shared Access Mode: This is recommended for sharing clusters among multiple users. It provides a balance between isolation and collaboration.
- Single User Access Mode: This mode is ideal for automated jobs and machine learning workloads where a single user is responsible for the computations. It offers the highest level of isolation.
Unsupported Modes:
- No-Isolation Shared Mode: This is a legacy mode that doesn't meet Unity Catalog's security requirements.
Databricks recommends using compute policies to simplify configuration for managing Unity Catalog access on clusters. There are certain limitations associated with using Databricks Unity Catalog in different access modes. These limitations can affect aspects like init scripts, libraries, network access, and file system access.
Check out this article for compute access mode limitations for Databricks Unity Catalog
What Are the Supported Regions and Data File Formats of Databricks Unity Catalog?
Databricks Unity Catalog is designed to be region-agnostic, meaning it adapts to the specific region where your Databricks workspace is located. Given that Databricks provides workspaces across a range of cloud service providers, Unity Catalog can be conveniently leveraged wherever your workspace is deployed.
Check out this official documentation on the list of supported Databricks clouds and regions.
When it comes to data formats, Databricks Unity Catalog offers distinct options for managed and external tables:
Here are the Supported Data File Formats of Databricks Unity Catalog:
- Managed Tables: Managed tables in Databricks Unity Catalog must use the Delta table format.
- External (Unmanaged) Tables: External tables in Databricks Unity Catalog can use various file formats, including Delta, CSV, JSON, Avro, Parquet, ORC, and Text.
What Is the Difference Between Unity Catalog and Hive Metastore?
Databricks Unity Catalog and Hive Metastore are both metadata management systems, but they serve different purposes and have distinct functionalities within their respective ecosystems. Here's a table that highlights the key differences between Databricks Unity Catalog and Hive Metastore:
| Databricks Unity Catalog | Hive Metastore |
| Databricks Unity Catalog is a centralized service for managing data governance and access control across workspaces in the Databricks | Hive Metastore is central repository for storing metadata about Hive databases, tables, partitions, and other objects in the Apache Hive data warehousing system |
| Databricks Unity Catalog supports a wide range of data sources, including Apache Spark tables, Delta Lake tables, AWS S3, Azure Blob Storage, HDFS, and more. | Hive Metastore is primarily designed for Hive tables and databases, but can also store metadata for external data sources like HDFS or cloud storage |
| Databricks Unity Catalog provides APIs and tools for managing and updating metadata, enabling automated metadata capture and synchronization with external metadata sources | Metadata management is primarily done through Hive commands or directly interacting with the underlying database |
| Databricks Unity Catalog offers fine-grained access control and data lineage tracking, allowing administrators to define and enforce policies for data access and modification | Access control is typically handled through Hadoop permissions or external tools like Apache Ranger |
| Databricks Unity Catalog is designed specifically for Databricks, offering seamless integration and collaboration within the platform | Hive Metastore is primarily designed for Hadoop-based environments, but can be used with other systems that support the Hive Metastore interface |
| Databricks Unity Catalog facilitates data sharing and collaboration by allowing users to grant and revoke access to data assets across different environments and teams | In Hive Metastore data sharing is typically achieved through Hadoop permissions or external tools like Apache Ranger |
| Databricks Unity Catalog is tightly integrated with the Databricks Unified Analytics Platform and other components of the Databricks ecosystem | Hive Metastore integrates with the Apache Hive ecosystem and can be used with other tools like Apache Spark, Apache Impala, and Apache Ranger |
| Databricks Unity Catalog is designed to handle large-scale data and metadata operations with high performance and scalability | In Hive meta store scalability and performance can vary depending on the underlying database and configuration |
| Databricks Unity Catalog provides a searchable interface for data discovery and exploration | Metadata management is typically done through Hive commands or directly interacting with the underlying database |
How to Create Unity Catalog Metastore (AWS)
To create a Unity Catalog metastore in the AWS cloud environment, follow these prerequisites and steps:
Prerequisites
- Databricks account with Admin privileges (Premium plan or above)
- Make sure you have the necessary permissions and IAM roles to create resources in your AWS account.
- Determine the AWS region where you want to create the Databricks Unity Catalog metastore.
- Decide on a unique name for your Unity Catalog metastore.
- Prepare an AWS S3 bucket location to store managed data for the metastore (optional).
Step 1—Configure Storage
Before creating a Databricks Unity Catalog metastore, you may want to create an S3 bucket to store data that is managed at the metastore level. This is optional, as you can use the default bucket provided by Databricks.
Follow the Create your first S3 bucket guide if needed.
Step 2—Create an IAM Role to Access the Storage Location
Next, create an AWS IAM role to allow Databricks to access the S3 bucket you created in Step 1. This role should have the necessary permissions to read and write data to the bucket.
Follow the Creating IAM roles guide if needed.
Step 3—Create the Metastore and Attach a Workspace
Finally, create the Unity Catalog metastore in the Databricks account console. To do so:
1) Log in to the Databricks console and navigate to the Data option.
2) Click "Create Metastore".

3) Provide a name and choose the region for the metastore (same region as your workspaces).
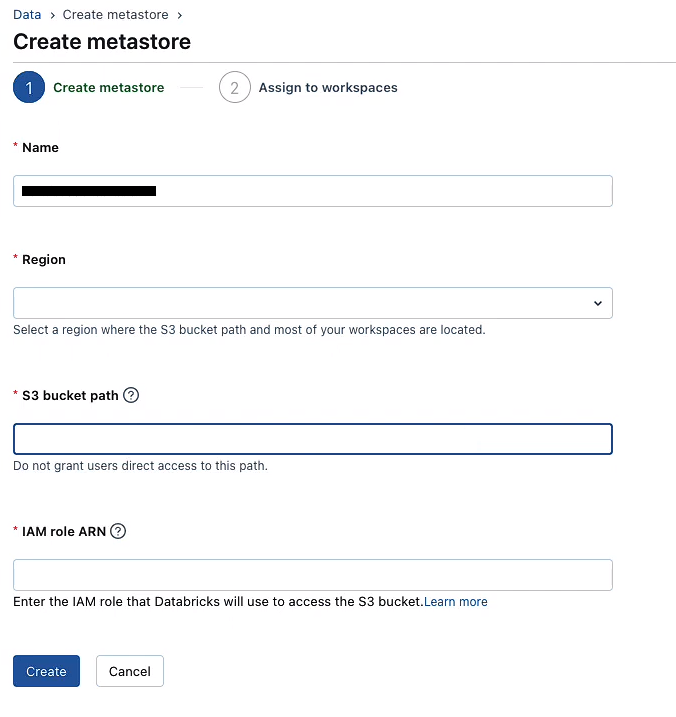
4) Optionally, attach the storage location you created in step 1.
5) Assign the metastore to your workspace.

Check out this documentation for a full guide on creating a Databricks Unity Catalog metastore in AWS.
Step-By-Step Guide to Enable Your Workspace for Databricks Unity Catalog
Enabling Databricks Unity Catalog on your workspace is a straightforward process that can be done through the Databricks account console or during workspace creation. Follow these step-by-step instructions to enable Databricks Unity Catalog:
Step 1—Log in to the Databricks Account
Log in to the Databricks account console as an account admin.
Step 2—Click on “Data” Option
Click on the "Data" option in the left-hand navigation panel.
Step 3—Access the Metastore
Access the metastore by clicking on the metastore name.

Step 4—Navigate to the Workspaces Tab
Within the metastore, head over to the "Workspaces" tab.

Step 5—Assign to Workspaces
Click the "Assign to workspaces" button to enable Databricks Unity Catalog on one or more workspaces.
Step 6—Choose One or More Workspaces to Enable
In the "Assign Workspaces" dialog, select one or more workspaces you want to enable for Databricks Unity Catalog.
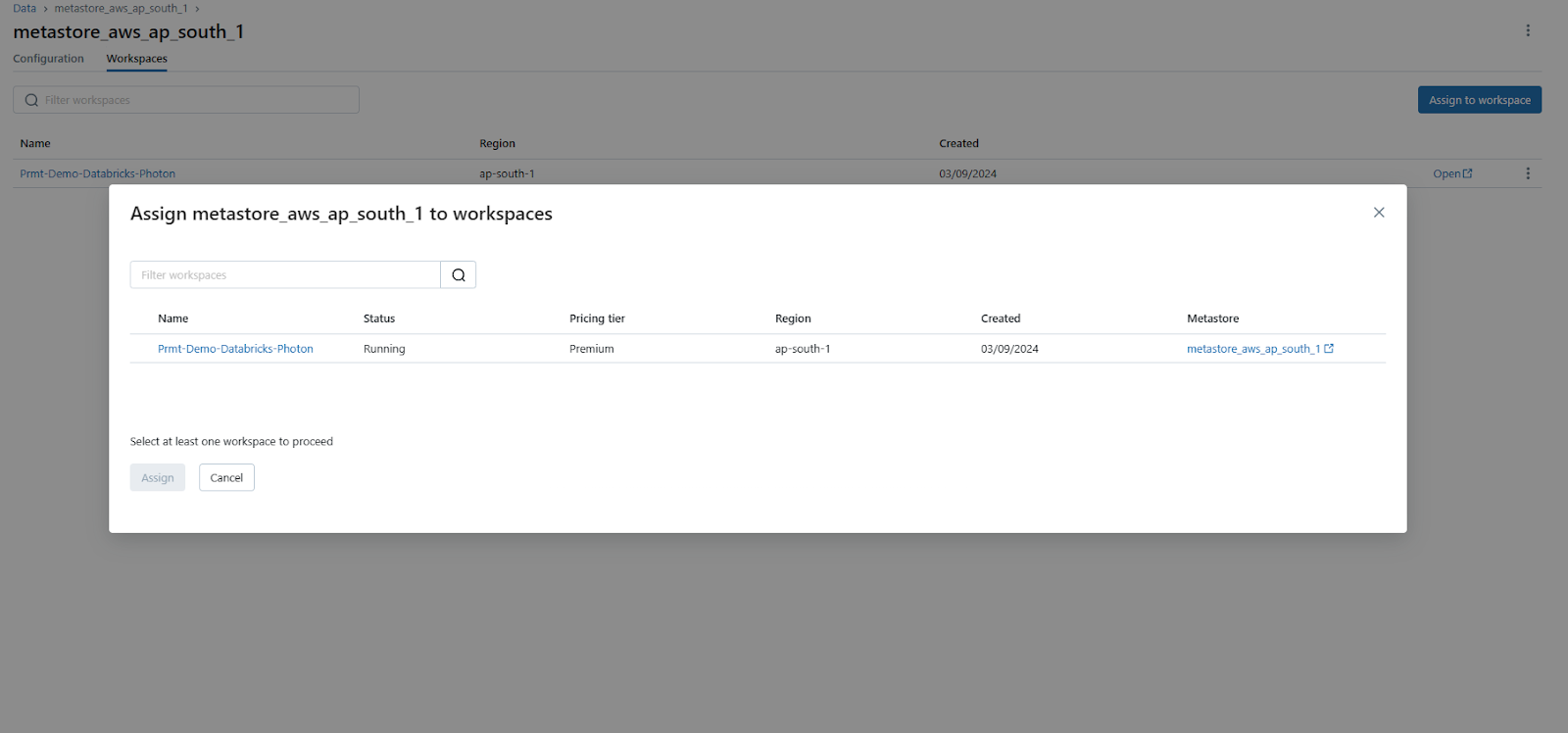
Step 7—Assign and Confirm
Click "Assign", and then confirm by clicking "Enable" on the dialog that appears.
Optional—Enable Databricks Unity Catalog When Creating a Workspace
If you are creating a new workspace, you can enable Databricks Unity Catalog during the workspace creation process:
1) Toggle the "Enable Unity Catalog" option
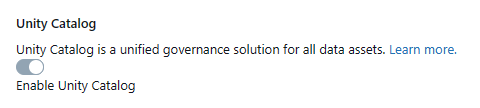
2) Select the metastore you want to associate with the new workspace
3) Confirm by clicking "Enable"
4) Complete the process by providing the necessary configuration settings and clicking "Save"
Step 8—Confirm the workspace assignment
Confirm the workspace assignment by checking the "Workspaces" tab within the metastore. The workspace(s) you enabled should now be listed.

If you follow these steps thoroughly, you have successfully enabled Databricks Unity Catalog for your workspace(s), allowing you to take advantage of its governance capabilities within the Databricks ecosystem.
Step-By-Step Guide to Set up and Manage Unity Catalog
Setting up and managing Databricks Unity Catalog involves several steps to ensure proper configuration, access control, and object management. Here's a step-by-step guide to help you through the process:
Prerequisites
- Databricks account with Admin privileges (Premium plan or above)
- Unity Catalog metastore already created and associated with your workspace(s)
- Familiarity with SQL and data management concepts
- Appropriate roles and privileges, depending on the workspace enablement status (account admin, metastore admin, or workspace admin).
Step 1—Check That Your Workspace Is Enabled for Unity Catalog
To verify if your Databricks workspace is enabled for Databricks Unity Catalog, sign in to your Databricks account as an account admin. Click on the Workspaces icon and locate your workspace. Check the Metastore column—if there's a metastore name listed, your workspace is connected to a Databricks Unity Catalog metastore, indicating Unity Catalog is enabled.

Alternatively, run a quick SQL query in the SQL query editor or a notebook connected to a cluster:
SELECT CURRENT_METASTORE();If the query result shows a metastore ID, your workspace is attached to a Unity Catalog metastore.
Step 2—Add Users and Assign Roles
As a workspace admin, you can add and invite users, assign admin roles, and create service principals and groups. Account admins can manage users, service principals, and groups in your workspace and grant admin roles.
Check out this documentation for more information on managing Databricks users.
Step 3—Set up Compute Resources for Running Queries and Creating Objects
Unity Catalog workloads require compute resources like SQL warehouses or clusters. These resources must meet certain security requirements to access data and objects within Unity Catalog. SQL warehouses are always compliant, but cluster access modes may vary.
As a workspace admin, decide whether to restrict compute resource creation to admins or allow users to create their own SQL warehouses and clusters. To ensure compliance, set up cluster policies that guide users in creating Unity Catalog-compliant resources.
See “Supported Compute and Cluster Access Modes of Databricks Unity Catalog” section above for more details.
Step 4—Grant User Privileges
To create and access objects in Databricks Unity Catalog catalogs and schemas, users must have proper permissions. Let's discuss default user privileges and how to grant additional privileges.
Default User Access:
- If your workspace launched with an auto-provisioned workspace catalog, all workspace users can create objects in the default schema of that catalog by default.
- If your workspace was manually enabled for Unity Catalog, it has a main catalog. Users have the USE CATALOG privilege on this main catalog by default, allowing them to work with objects but not create new ones initially.
- Some workspaces have no default catalogs or user privileges set up.
Default Admin Privileges:
- If auto-enabled for Databricks Unity Catalog, workspace admins can create new catalogs, objects within them, and grant access to others. There's no designated metastore admin initially.
- If manually enabled, workspace admins have no special Unity Catalog privileges by default. Metastore admins must exist and have full control.
Granting More Access:
To allow a user group to create new schemas in a catalog you own, run this SQL command:
GRANT CREATE SCHEMA ON <my-catalog> TO `data-consumers`;or for the auto-provisioned workspace catalog:
GRANT CREATE SCHEMA ON <workspace-catalog> TO `data-consumers`;You can also manage privileges through the Catalog Explorer UI.
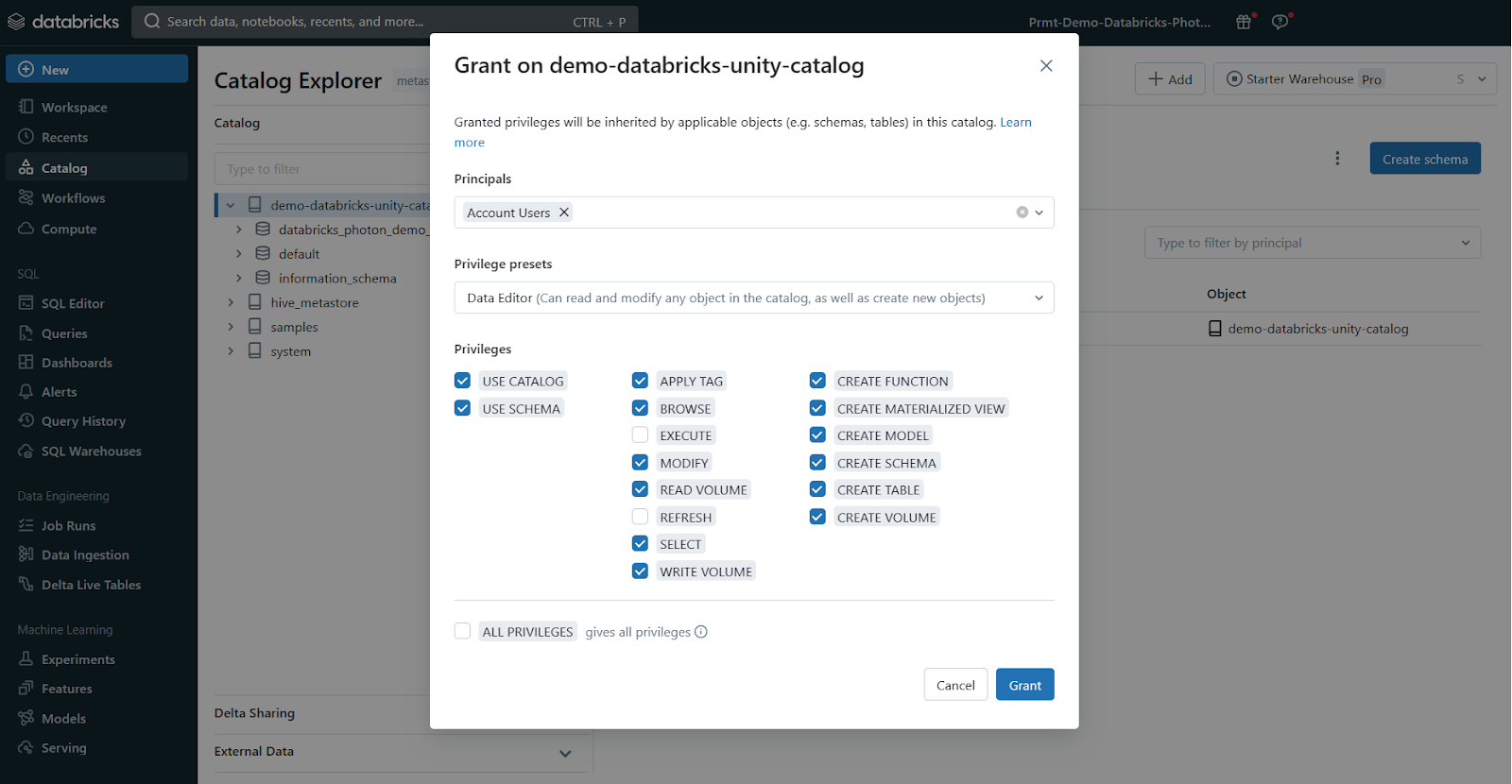
Note: You can only grant privileges to account-level groups, not the workspace-local admin/user groups.
Step 5—Create Catalogs and Schemas
To start using Unity Catalog, you need at least one catalog, which is the primary way to organize and isolate data in Unity Catalog. Catalogs contain schemas, tables, volumes, views, and models. Some workspaces don't have an automatically-provisioned catalog, and in these cases, a workspace admin must create the first catalog.
Other workspaces have access to a pre-provisioned catalog that users can immediately use, either the workspace catalog or the main catalog, depending on how Unity Catalog was enabled for your workspace. As you add more data and AI assets to Databricks, you can create additional catalogs to logically group assets, simplifying data governance.
If you follow these steps, you'll have a well-configured Unity Catalog environment with users, computing resources, and a data organization structure ready to go.
How to Control Access to Data and Other Objects in Databricks Unity Catalog?
Databricks Unity Catalog provides a comprehensive access control model for governing data and objects within the Lakehouse Platform. Let's explore key concepts and approaches for managing access privileges in Databricks Unity Catalog.
1) Understanding Admin Privileges
At the highest level, Databricks account admins, workspace admins, and designated metastore admins have full control over the Unity Catalog environment. These admin roles can manage the entire catalog hierarchy as well as configure security settings.
2) Object Ownership Model
Every securable object (e.g. catalogs, schemas, tables, views, functions) in Unity Catalog has an assigned owner. By default, the creator of an object becomes its owner. Object owners have complete privileges over that asset, including the ability to grant access to other users or groups.
3) Privilege Inheritance Hierarchy
Databricks Unity Catalog leverages a privilege inheritance model, where access permissions propagate from higher to lower levels. For instance, granting a privilege at the catalog level automatically applies it to all schemas, tables, and views within that catalog. Similarly, schema-level privileges apply to all contained objects.
4) Basic Object Privileges
You can grant or revoke fundamental privileges like SELECT, INSERT, DELETE, and ALTER on securable objects using standard SQL syntax (GRANT, REVOKE statements). Metastore admins, object owners, or owners of the parent catalog/schema can execute these statements.
5) Transferring Ownership
If needed, you can transfer ownership of a catalog, schema, table, or view to another user or group. This can be done via SQL commands or the Catalog Explorer UI.
6) Managing External Locations and Storage Credentials
For datasets in external storage systems like AWS S3 or Azure Blob Storage, configure external locations and storage credentials within Unity Catalog. This enables secure access to those data sources.
7) Dynamic Views for Row/Column-Level Security
Going beyond object-level permissions, dynamic views in Unity Catalog allow you to filter or mask data at the row or column level based on the accessing user's identity. This ensures that users only see the subset of data they are authorized to view.
If you leverage these key capabilities, you can implement a comprehensive data access control strategy tailored to your organization's security policies and compliance requirements.
Step-By-Step Guide for Getting Started With Databricks Unity Catalog
Prerequisites
- Databricks workspace enabled for Unity Catalog.
- Access to compute resources (SQL warehouse or cluster) that support Unity Catalog.
- Appropriate privileges on Databricks Unity Catalog objects (USE CATALOG, USE SCHEMA, and CREATE TABLE).
- Users and groups added to the workspace.
Namespace Overview:
Now, let's talk about Unity Catalog's three-level namespace. It organizes your data into catalogs, schemas (databases), and tables or views. Think of it like a filing cabinet with drawers (catalogs), folders (schemas), and documents (tables or views).
When referring to a table, you'll use this format:
<catalog>.<schema>.<table>If you have data in your Databricks workspace's local Hive metastore or an external Hive metastore, it becomes a catalog called hive_metastore, and you can access tables like this:
hive_metastore.<schema>.<table>Step 1—Create a New Catalog
Create a new catalog using the CREATE CATALOG command with spark.sql. To create a catalog, you must be a metastore admin or have the CREATE CATALOG privilege on the metastore.
CREATE CATALOG IF NOT EXISTS <catalog>;If your workspace was enabled for Databricks Unity Catalog by default, you might need to specify a managed location for the new catalog.
CREATE CATALOG IF NOT EXISTS <catalog> MANAGED LOCATION '<location-path>';Step 2—Select and Grant Permissions on the Catalog
Once your catalog is created, select it as the current catalog and grant permissions to other users or groups as needed.
-- Set the current catalog
USE CATALOG <catalog>;
-- Grant permissions to all users
GRANT CREATE SCHEMA, CREATE TABLE, USE CATALOG
ON CATALOG <catalog>
TO `account users`;Step 3—Create and Manage Schemas
Next, let's create schemas (databases) to logically organize tables and views.
-- Create a new schema
CREATE SCHEMA IF NOT EXISTS <schema>
COMMENT "A new Unity Catalog schema called <schema>";
-- Show schemas in the selected catalog
SHOW SCHEMAS;
-- Describe a schema
DESCRIBE SCHEMA EXTENDED <schema>;Step 4—Create a Managed Table
Managed tables are the default way to create tables with Unity Catalog. The table is created in the managed storage location configured for the metastore, catalog, or schema.
-- Set the current schema
USE <schema>;
-- Create a managed Delta table and insert records
CREATE TABLE IF NOT EXISTS <table>
(columnA Int, columnB String) PARTITIONED BY (columnA);
INSERT INTO TABLE <table>
VALUES
(1, "one"),
(2, "two"),
(3, "three"),
(4, "four"),
(5, "five"),
(6, "six"),
(7, "seven"),
(8, "eight"),
(9, "nine"),
(10, "ten");
-- View all tables in the schema
SHOW TABLES IN <schema>;
-- Describe the table
DESCRIBE TABLE EXTENDED <table>;Step 5—Query the Table
Access your tables using the three-level namespace:
-- Query the table using the fully qualified name
SELECT * FROM <catalog>.<schema>.<table>;
-- Set the default catalog and query using the schema and table name
USE CATALOG <catalog>;
SELECT * FROM <schema>.<table>;
-- Set the default catalog and schema, and query using the table name
USE CATALOG <catalog>;
USE <schema>;
SELECT * FROM <table>;Step 6—Drop a Table
Drop a managed table using the DROP TABLE command. This removes the table and its underlying data files. For external tables, dropping the table removes the metadata but leaves the data files untouched.
-- Drop the managed table
DROP TABLE <catalog>.<schema>.<table>Step 7—Manage Permissions on Data (Optional)
Lastly, use GRANT and REVOKE statements to manage access to your data. Unity Catalog is secure by default, so access isn't automatically granted. Metastore admins and data object owners can control access for users and groups.
-- Grant USE SCHEMA privilege on a schema
GRANT USE SCHEMA
ON SCHEMA <schema>
TO `account users`;
-- Grant SELECT privilege on a table
GRANT SELECT
ON TABLE <schema>.<table>
TO `account users`;
-- Show grants on a table
SHOW GRANTS
ON TABLE <catalog>.<schema>.<table>;
-- Revoke a privilege
REVOKE SELECT
ON TABLE <schema>.<table>
FROM `account users`;Well, that's all for now! I hope this guide has given you a good starting point for exploring Databricks Unity Catalog. Don't forget to check the official documentation for more advanced topics and scenarios.
Databricks Unity Catalog Best Practices
To maximize the benefits of Databricks Unity Catalog and ensure efficient and secure data governance, follow these best practices:
1) Catalogs as Isolation Units
Use catalogs as the primary unit of isolation in your data governance model. Separate catalogs for production vs non-production data, sensitive vs non-sensitive information, and data belonging to different organizational units or domains.
2) Storage Isolation
In addition to catalog isolation, you can further segregate data by configuring separate cloud storage locations at the catalog or schema level. This physical separation is crucial when regulatory or corporate policies mandate storage boundaries for specific data categories.
3) Workspace Boundaries
Bind catalogs to specific Databricks workspaces to restrict data access to authorized compute environments only.
4) Access Control Model
Utilize the flexible, inheritance-based model provided by Databricks Unity Catalog for granular permissions.
5) Use Group Ownership
Always designate groups, not individuals, as owners of catalogs, schemas, tables, and other objects. This enables consistent access management using your identity provider's group membership.
6) Leverage Inheritance
Grant coarse permissions at higher catalog and schema levels, allowing automatic propagation of privileges to child objects like tables and views.
7) Implement Attribute-Based Access
Use dynamic views with the is_account_member() function for advanced access scenarios, filtering data access based on a user's group membership or other attributes from the authentication provider.
8) Column and Row Security
Implement column-level and row-level data masking and filtering using dynamic views to secure sensitive data while providing higher-privileged users with full access when needed.
9) External Location Boundaries
Grant external location creation privileges only to a limited set of administrators. This prevents indiscriminate data access bypassing Unity Catalog controls while maintaining secure, audited bridges between cloud storage and Unity Catalog.
10) Cluster Security
Configure compute clusters with an appropriate access mode to integrate with Unity Catalog's security model.
11) Access Mode Policies
Implement cluster policies to enforce standardized cluster configurations, allowing only the necessary access modes based on the use case (e.g., shared access for multi-tenant workloads, single user for jobs/ML workloads).
12) Least Privilege Clusters
Create dedicated private clusters bound to your secure data catalogs via workspace-catalog bindings for highly sensitive data processing.
13) Auditing and Monitoring
Comprehensive auditing of data access events enables security reviews, troubleshooting of issues, and detection of abuse or data exfiltration attempts.
14) Integrate Audit Logs
Configure log delivery of Databricks audit logs (including Unity Catalog audit events) to your centralized security monitoring solution. Make sure to establish monitoring processes to analyze these logs for anomalies.
15) Metadata Operations
In addition to data access, monitor for excessive or suspicious levels of create/alter/delete operations on securables such as catalogs, schemas, and tables.
16) Delta Sharing for Secure Collaboration
Use Delta Sharing for secure data sharing between isolated domains or external entities, rather than direct access methods that bypass governance controls.
That’s it! If you follow these best practices, you can ensure secure and efficient data governance within your organization using Databricks Unity Catalog.
What Are the Limitations of Databricks Unity Catalog?
Databricks Unity Catalog offers comprehensive data management capabilities, but it's essential to understand its limitations to plan your implementation accordingly. Here are some key limitations:
1) Compatibility with Older Databricks Runtimes
Databricks Runtime versions below 11.3 LTS may not fully support Unity Catalog functionalities. Upgrade to Databricks Runtime 11.3 LTS or later for complete functionality.
2) Row-level and Column-level Security for R Workloads
Databricks Unity Catalog does not support dynamic views for row-level or column-level security with R workloads. Plan accordingly if your organization relies on R for data analysis.
3) Shallow Clones Limitations
Shallow clones for creating managed tables are supported in Databricks Runtime 13.1 and above, but not in Databricks Runtime 13.0 and below.
4) Bucketing Limitations
Databricks Unity Catalog does not support bucketing for its tables. Attempting to create a bucketed table will throw an exception.
5) Writing from Multiple Regions
Writing to the same path or Delta Lake table from workspaces in multiple regions can cause unreliable performance if some clusters access Unity Catalog and others do not. Always maintain consistency across workspaces to avoid issues.
6) Custom Partition Schemes
Unity Catalog does not support custom partition schemes created using commands like ALTER TABLE ADD PARTITION. However, you can still access tables that use directory-style partitioning.
7) Overwrite Mode for DataFrame Write Operations
Overwrite mode for DataFrame write operations is only supported for Delta tables and not other file formats. Users must have CREATE privileges on the parent schema and be the object owner or have MODIFY privileges.
8) Python UDFs Limitations
In Databricks Runtime 13.2 and above, Python scalar UDFs are supported. In Databricks Runtime 13.1 and below, Python UDFs (including UDAFs, UDTFs, and Pandas on Spark) are not supported.
9) Scala UDFs on Shared Clusters Limitations
Scala scalar UDFs are supported on shared clusters in Databricks Runtime 14.2 and above, but not in Databricks Runtime 14.1 and below.
10) Workspace-level Groups in GRANT Statements
Workspace-level groups cannot be used in Unity Catalog GRANT statements. Create groups at the account level for consistency, and update automation to reference account endpoints instead of workspace endpoints.
11) Object Name Limitations
There are several limitations regarding object names in Unity Catalog:
- Object names cannot exceed 255 characters.
- Special characters such as periods (.), spaces, forward slashes (/), ASCII control characters (00-1F hex), and the DELETE character (7F hex) are not allowed.
- Unity Catalog stores all object names in lowercase.
- Use backticks to escape names with special characters, such as hyphens (-), when referencing Unity Catalog names in SQL.
12) Column Name Limitations
Column names can use special characters, but the name must be escaped with backticks (`) in all SQL statements if special characters are used. Databricks Unity Catalog preserves column name casing, but queries against Unity Catalog tables are case-insensitive.
13) Write Privileges on External Locations
Grant write privileges on a table backed by an external location in S3 only if the external location is defined in a single metastore. Concurrent writes to the same S3 location from multiple metastores may cause consistency issues. Reading data from a single external S3 location using multiple metastores is safe.
Source: Databricks
If you thoroughly understand these limitations, it will enable you to better navigate Unity Catalog and ensure smooth operation when working with your data.
Conclusion
And that's a wrap! We've covered the ins and outs of Databricks Unity Catalog, exploring its architecture, features, and how it fits into the world of data governance. Unity Catalog serves as a powerful tool for centralizing and managing data assets, making data discovery, access control, and collaboration a breeze for organizations.
In this article, we have covered:
- What is Databricks Unity Catalog?
- What are the supported compute and cluster access modes?
- What are the supported regions and data file formats?
- What is the difference between Unity Catalog and Hive Metastore?
- Step-by-step guide to enable Databricks Unity Catalog
- How to create a Unity Catalog metastore (AWS)
- Step-by-step guide to set up and manage Unity Catalog
- How to control access to data and other objects in Unity Catalog
- Step-by-step guide to create a table in Unity Catalog
- Databricks Unity Catalog best practices
- Limitations of Databricks Unity Catalog
FAQs
What is Databricks Unity Catalog?
Databricks Unity Catalog is a unified governance layer for structured and unstructured data, machine learning models, notebooks, dashboards, tables, and files across any cloud or platform within the Databricks ecosystem.
How does Databricks Unity Catalog differ from Hive Metastore?
Databricks Unity Catalog offers a centralized data governance model, supports external data access, data isolation, and advanced features like column-level security, while Hive Metastore has limited governance capabilities.
What are the supported compute and cluster access modes for Databricks Unity Catalog?
Supported access modes are Shared Access Mode and Single User Access Mode. No-Isolation Shared Mode is not supported.
What data file formats are supported for managed and external tables in Databricks Unity Catalog?
Managed tables must use the Delta table format, while external tables can use Delta, CSV, JSON, Avro, Parquet, ORC, and Text formats.
How do you enable your workspace for Databricks Unity Catalog?
You can enable Unity Catalog during workspace creation or assign an existing metastore to your workspace through the Databricks account console.
How do you control access to data and objects in Databricks Unity Catalog?
You can use admin privileges, object ownership, privilege inheritance, basic object privileges (GRANT/REVOKE), dynamic views for row/column security, and manage external locations and credentials.
What is the Databricks Unity Catalog object model?
The object model follows a hierarchical structure:
Metastore ► Catalog ► Schema ► Tables, Views, Volumes, and Models.
Can you transfer ownership of objects in Unity Catalog?
Yes, you can transfer ownership of catalogs, schemas, tables, and views to other users or groups using SQL commands or the Catalog Explorer UI.
How do you create a new catalog in Unity Catalog?
You can use the CREATE CATALOG SQL command, specifying a name and managed location if needed. You must have CREATE CATALOG privileges on the metastore.
How do you grant permissions on a catalog or schema?
Use the GRANT statement with the desired privileges (e.g., CREATE SCHEMA, CREATE TABLE) and the catalog or schema name, followed by the user or group to grant access to.
What is the syntax for referring to a table in Unity Catalog?
Use the three-part naming convention:
<catalog>.<schema>.<table>
How do you create a managed table in Unity Catalog?
Use the CREATE TABLE statement, specifying the table name, columns, and partitioning if needed. Managed tables are created in the managed storage location.
Can you access data in the Hive Metastore through Unity Catalog?
Yes, data in the Hive Metastore becomes a catalog called hive_metastore, and you can access tables using the hive_metastore.<schema>.<table> syntax.
How do you drop a table in Databricks Unity Catalog?
You can use the DROP TABLE statement followed by the fully qualified table name (e.g., DROP TABLE <catalog>.<schema>.<table>).















