



























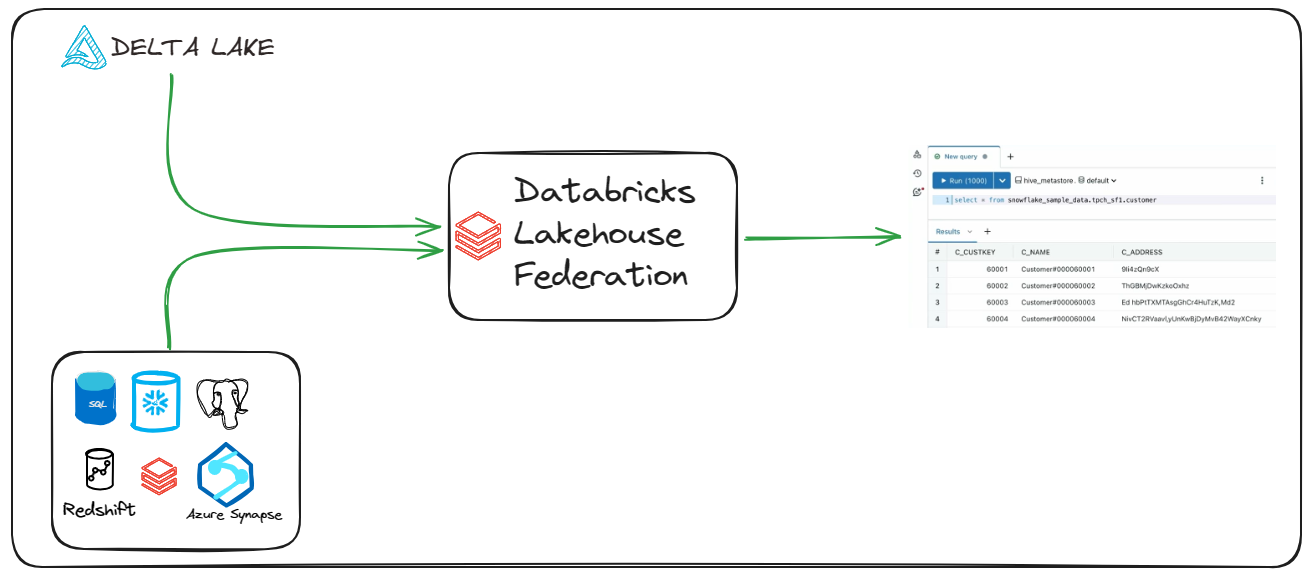
Managing data can be a real pain these days, with information spread across various systems such as databases, data warehouses, and different storage solutions. It's tough to get a clear picture of what's going on, which makes it really hard to make informed decisions. Fortunately, there's a solution: Databricks Lakehouse Federation. Introduced by Databricks at the Data+AI Summit in June 2023, this powerful query federation platform enables you to use Databricks to run queries against multiple external data sources, centralizing all your data in one place. This simplifies data analysis and allows you to extract valuable insights from data scattered across multiple platforms with ease.
In this article, we'll take a deep dive into Databricks Lakehouse Federation, exploring its key features, benefits, and practical use cases. We'll also walk you through the step-by-step process of querying data from Snowflake into Databricks using Lakehouse Federation.
What Is Databricks Lakehouse Federation?
Databricks Lakehouse Federation is a query federation platform that allows you to run queries against multiple external data sources directly from within the Databricks environment. It is built upon the concept of data virtualization, which allows users to access and analyze data from various sources without having to move or copy it.
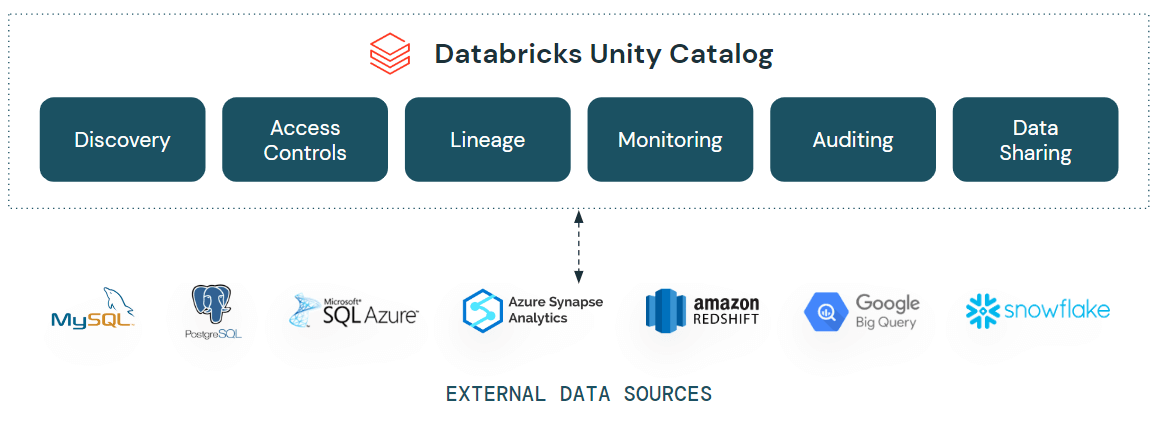
At the center of Lakehouse Federation is Unity Catalog, which is like a centralized metadata store that serves as the backbone for data governance and management. Unity Catalog maintains lists of external data sources, including their schemas, tables, and access permissions, enabling seamless integration and querying of these sources from within Databricks.
The architecture of Lakehouse Federation comprises several key components:
- Unity Catalog: As mentioned above, this is the brain of the operation, keeping track of all your external data sources and acting as a one-stop-shop for managing them.
- External Connections: These are like secret passageways to your external data sources, storing all the necessary credentials and configurations to access them securely. They are securely stored and managed within Unity Catalog.
- Foreign Catalogs: Foreign catalogs are virtual representations of external databases within Unity Catalog. They mirror the schema and table structures of the external data sources, enabling users to query and interact with them as if they were part of the Databricks environment.
- Query Optimizer: Query optimizer is responsible for analyzing and optimizing queries that span multiple data sources. It determines the most efficient execution plan by considering factors such as data locality, network bandwidth, and computational resources.
- Query Execution Engine: This is the muscle behind the operation, executing the optimized query plan and fetching data from external sources quickly and smoothly. It determines the most efficient execution plan by considering factors such as data locality, network bandwidth, and computational resources.
TL:DR; Lakehouse Federation is designed to give you a seamless experience when working with data from multiple sources, while leveraging the robust governance, security, and performance capabilities of the Databricks.
What Are the Key Features of Databricks Lakehouse Federation?
Databricks Lakehouse Federation offers a comprehensive set of features that enable organizations to effectively manage and analyze their distributed data.
Let's take a closer look at what it can do:
1) Federated Querying Across Multiple Data Sources
One of the most significant advantages of Databricks Lakehouse Federation is its ability to query data across multiple external sources seamlessly. Users can join and analyze data from various databases, data warehouses, and storage systems using a single query, without the need for complex data movement or integration processes.
2) Fine-grained Access Control and Data Governance
Thanks to Unity Catalog, you can set up and enforce access permissions at different levels, like catalogs, schemas, and tables. This keeps your data safe and helps you comply with regulations. Plus, you can track data usage across all sources.
3) Data Lineage and Search
Unity Catalog's data lineage capabilities extend to federated data sources, providing a comprehensive view of data lineage across the entire data landscape. Users can easily trace the origins and transformations of data, facilitating data discovery, impact analysis, and collaboration. Furthermore, Unity Catalog's powerful search capabilities allow users to quickly locate and access relevant data across all federated sources.
4) Query Optimization and Performance
Databricks Lakehouse Federation uses fancy techniques like predicate pushdown to make your queries run faster, and it also caches data to avoid repeated retrieval.
5) Wide Support for Data Formats and Sources
Databricks Lakehouse Federation works with lots of different data formats and sources, like MySQL, PostgreSQL, Amazon Redshift, Snowflake, Microsoft SQL Server, Azure Synapse, Google BigQuery, and even other Databricks workspaces.
6) Scalability and Elasticity
Databricks Lakehouse Federation can automatically adjust its computing power based on how much data you're working with, so you get optimal performance without wasting resources.
7) Smooth Integration with Databricks
Databricks Lakehouse Federation works seamlessly with Databricks, so you can use all of Databricks' data engineering, data science, and machine learning tools on your federated data.
Databricks Lakehouse Federation gives you the power to make the most of your data, no matter where it's stored.
Benefits and Use Cases of Databricks Lakehouse Federation
Databricks Lakehouse Federation offers numerous benefits and enables a wide range of use cases, making it a valuable addition to any organization's data and analytics strategy:
1) One View to Rule Them All
Databricks Lakehouse Federation gives you a single, unified view of data from various databases, data warehouses, and storage systems, without the hassle of complex data integration. You can say goodbye to complex manual data movement and replication!
2) Improved/Easy Data Discovery and Access
Finding and accessing data across your entire organization is a breeze with Databricks Lakehouse Federation. Unity Catalog's search and browsing features, along with data lineage, make it a really easy to locate and understand your data's context and origin.
3) No More Data Duplication
Databricks Lakehouse Federation eliminates the need for time-consuming data ingestion by querying data directly from external sources. This saves storage costs and ensures your analyses are always up-to-date.
4) Faster Insights and Reporting
Databricks Lakehouse Federation lets you quickly combine and analyze data from multiple sources, speeding up your time-to-insight and making ad-hoc reporting a piece of cake.
5) Scalability and Cost Savings
Databricks Lakehouse Federation uses Databricks' scalable and elastic compute resources to handle large-scale federated queries efficiently. You get optimal performance and cost-efficiency without sacrificing speed or resources.
6) Governance and Security
Unity Catalog's data governance and security features extend to federated data sources, giving you complete control and visibility over your data usage. This keeps you compliant and reduces risk.
7) Advanced Analytics and AI
Databricks Lakehouse Federation works seamlessly with the Databricks, so you can leverage advanced analytics and machine learning on your federated data. Build end-to-end data and AI workflows with ease!
8) Easier Data Lake Adoption
Databricks Lakehouse Federation makes transitioning to a data lake architecture smoother than ever. Gradually migrate data to the Databricks while still using your existing infrastructure.
9) Proof-of-Concept and Migration Made Simple
Databricks Lakehouse Federation is perfect for testing new data pipelines, reports, or analytics workflows without extensive data movement. Reduce risk and speed up your time-to-value!
So, there you have it! Databricks Lakehouse Federation offers incredible benefits and tackling various use cases with ease.
What Are the Supported Data Sources by Lakehouse Federation?
Databricks Lakehouse Federation supports a wide range of external data sources, which helps you to integrate and query data from various databases, data warehouses, and storage systems. The currently supported data sources are:
- MySQL
- PostgreSQL
- Amazon Redshift
- Snowflake
- Microsoft SQL Server
- Azure Synapse (SQL Data Warehouse)
- Google BigQuery
- Databricks
Just keep in mind that this list might grow as Databricks keeps improving Lakehouse Federation.
Step-by- Step Guide to Query Data From Snowflake into Databricks Using Lakehouse Federation
To illustrate the power and simplicity of Databricks Lakehouse Federation, let's walk through a step-by-step guide to query data from Snowflake—a popular cloud data platform—into Databricks using Lakehouse Federation.
Prerequisite:
Before you query data from Snowflake into Databricks using Lakehouse Federation. Make sure you have these prerequisites checked off:
- Databricks workspace with the Unity Catalog enabled
- Databricks cluster with a runtime version of 13.1 or above, configured in either a shared or single-user access mode
- Ensure network connectivity between your Databricks Runtime cluster or SQL warehouse and the target database systems.
- Have metastore admin privileges or the CREATE CONNECTION privilege on the Unity Catalog metastore in your workspace.
- Verify you have CREATE CATALOG permission on the metastore and either own the connection or have the CREATE FOREIGN CATALOG privilege on the connection.
Step 1—Create a Connection
The first step in leveraging Databricks Lakehouse Federation is to create a connection to the external data source, in this case, Snowflake.
1) In your Databricks workspace, navigate to the Unity Catalog by clicking on the "Catalog" icon in the left-hand sidebar.
2) Under the "External Data" section, click on "Connections".
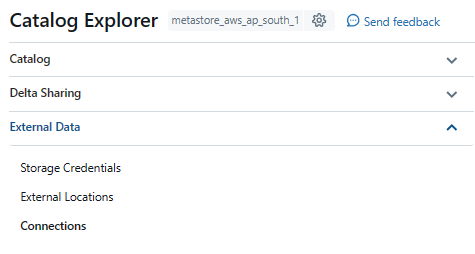
3) Click on the "Create Connection" button to initiate the connection creation process.
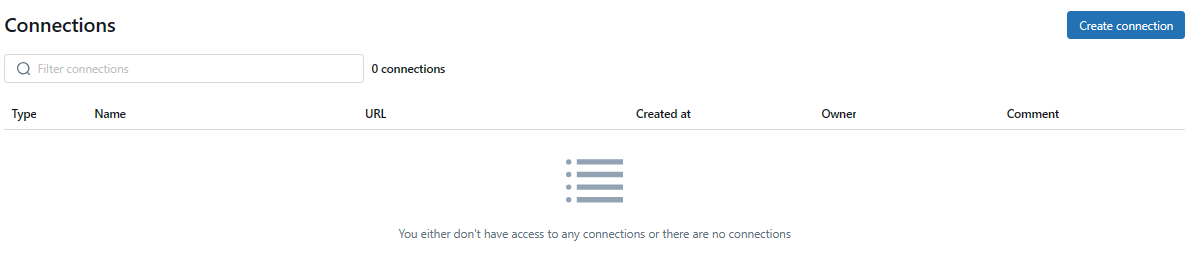
4) Provide a meaningful name for the connection, such as "Snowflake-Databricks-Connection"

5) Select the connection type as "Snowflake". You will be presented with a list of supported connection types such as MySQL, PostgreSQL, Amazon Redshift, Snowflake, Microsoft SQL Server, Azure Synapse (SQL Data Warehouse), Google BigQuery, and Databricks (for connecting to other Databricks workspaces).
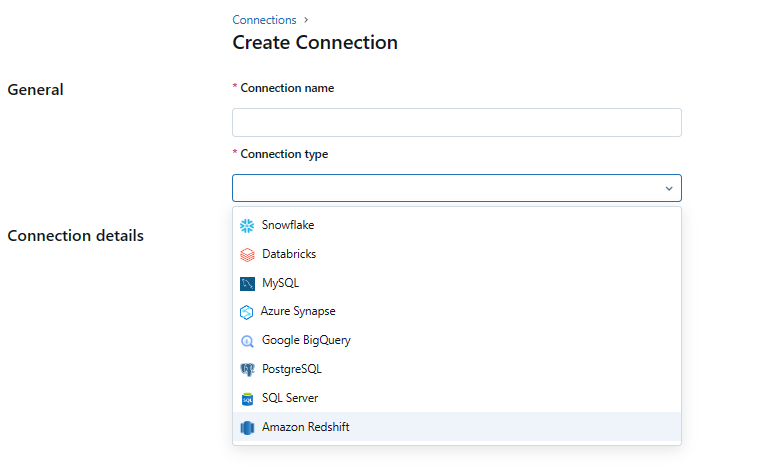
Step 2—Configure Snowflake Connection
Now let's set up the Snowflake connection.
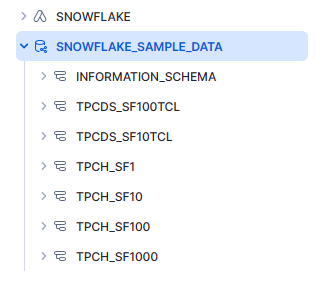
In your Snowflake workspace, go to the “Data” section and click "Databases" to make sure your data is ready for querying.
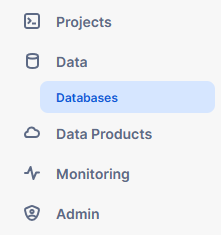
For this example, we'll use the Snowflake sample data database.
To set up the connection with Snowflake, you'll need your account URL. Follow these steps:
1) In Snowflake, go to the Admin section on the left-hand side.
2) Click the account menu and hover over the locator to find your account URL. Copy it.

Next, choose a warehouse:
1) Still in the Admin section, find the "Warehouses" menu.

2) Pick a warehouse for this example—we'll use the default "COMPUTE_WH".

Now, back in Databricks:
1) Go to the connection configuration page.
Enter the required Snowflake connection details:
- Host: Paste your Snowflake account URL.
- Port: Use the default port number (443) for Snowflake.
- Warehouse: Enter the name of the Snowflake warehouse you chose (e.g., "COMPUTE_WH").
- Snowflake username: Your Snowflake username.
- Password: Your Snowflake password.
Here is how your full connection configuration should look like:
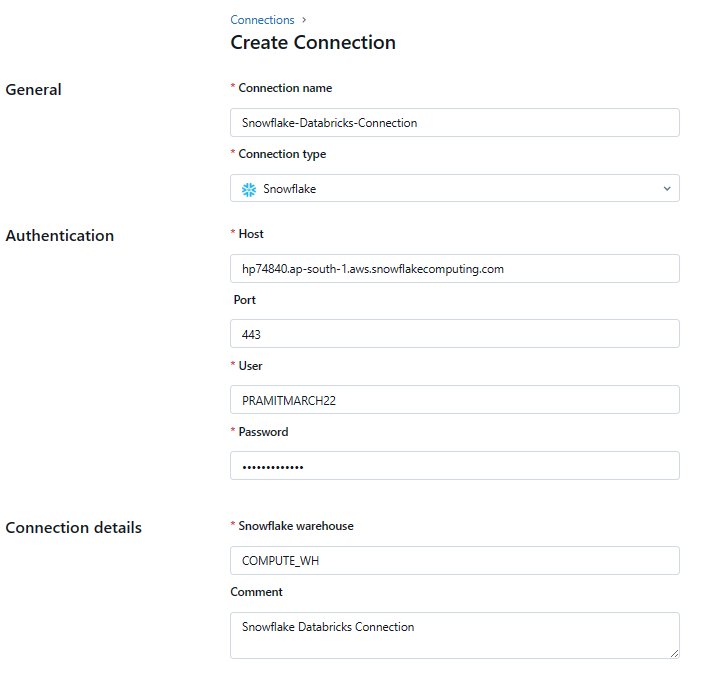
Optionally, you can add a comment or description for the connection to provide additional context.
2) Once you have entered all the required connection details, click the "Test Connection" button to verify that the connection is successful.
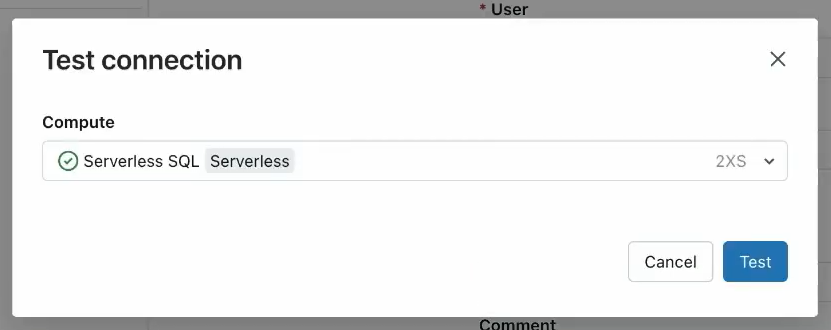
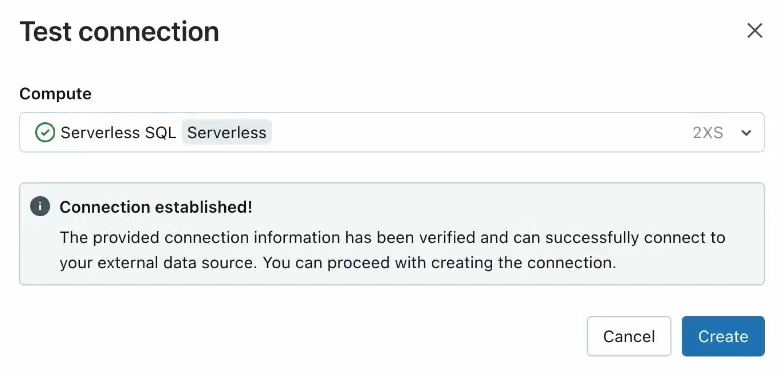
As you can see, the connection was successful.
3) Click "Create" to finalize the connection creation process.
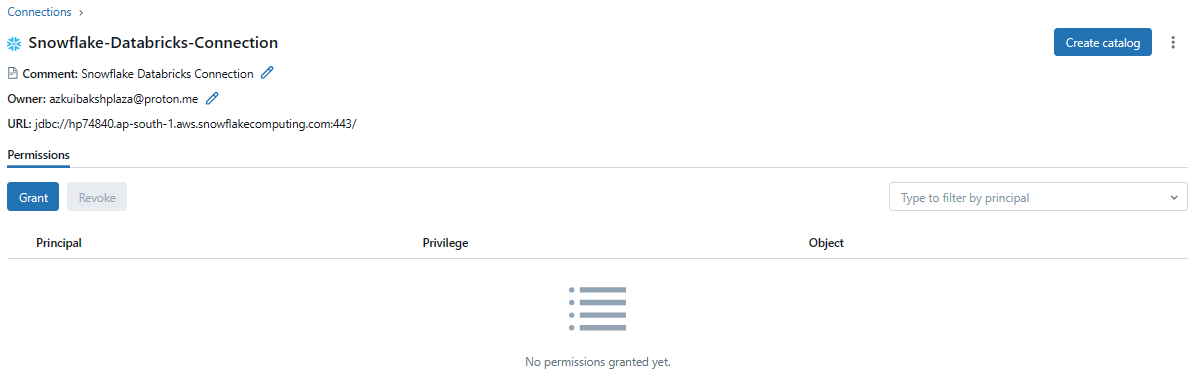
That's it! Your Snowflake connection is now successfully created and ready to go.
Step 3—Create a Foreign Catalog
With the connection to Snowflake established, the next step is to create a foreign catalog. A foreign catalog is a virtual representation of an external database within Unity Catalog, mirroring the schema and table structures of the external data source.
1) In the Databricks workspace, navigate to the "Catalog Explorer" section and then click on your recently created connection.

2) Click the "Create Catalog" button.

3) In the "Create a new catalog" dialog, provide a name for the catalog, such as "Snowflake-Databricks-Catalog"
4) Select the type as "Foreign"
5) From the "Connection" dropdown, select the connection you created in the previous step (e.g., "Snowflake-Databricks-Connection").
6) Enter the name of the Snowflake database you want to mirror as a catalog.
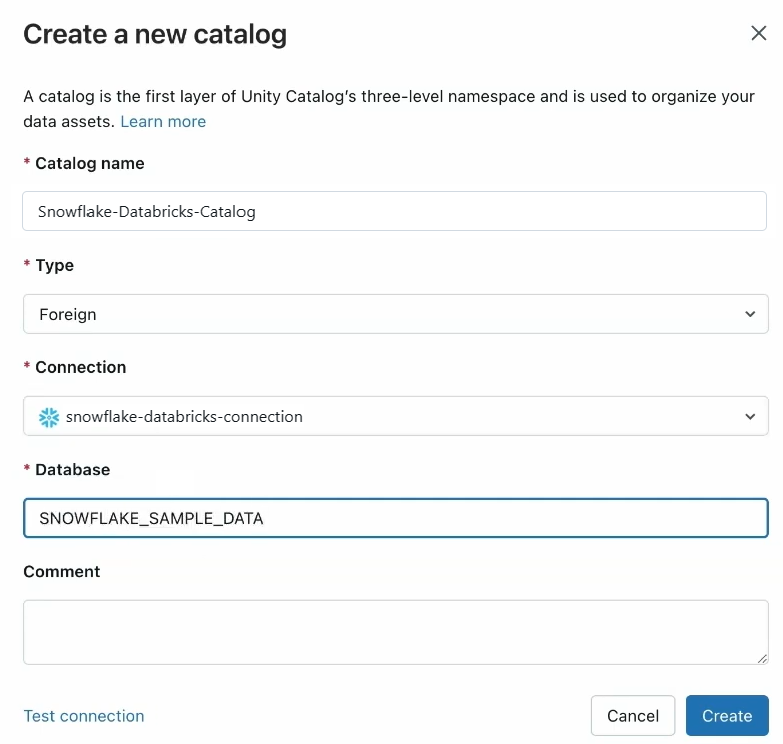
7) Click "Create" to finalize the creation of the foreign catalog.
Now that you've created the foreign catalog, you can see all the schemas and tables inside. In Snowflake, SNOWFLAKE_SAMPLE_DATA is a database, and tpds and tpch are schemas with tables inside. However, in Databricks, SNOWFLAKE_SAMPLE_DATA is the catalog, tpds and tpch are the databases and schemas, and the tables in Snowflake become data objects in Databricks.
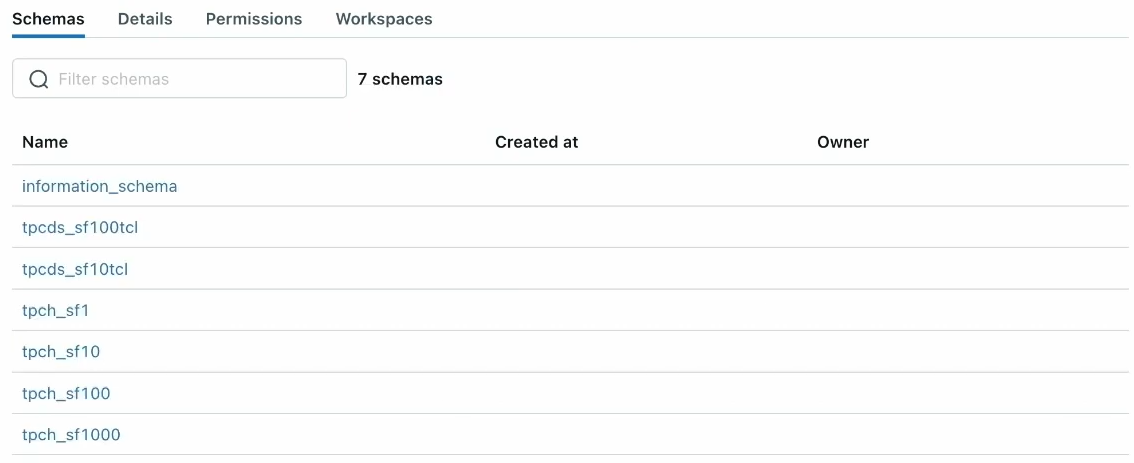
Step 4—Query the Data
With the foreign catalog set up, you can now query data from Snowflake directly within your Databricks workspace.
1) Open a new notebook or use the Databricks SQL query editor.
2) To query data from the Snowflake database, use the following SQL syntax:
SELECT * FROM <foreign_catalog_name>.<schema_name>.<table_name>;Replace <foreign_catalog_name> with the name of the foreign catalog you created (e.g., "Snowflake-Databricks-Catalog"), <schema_name>with the appropriate schema in your Snowflake database (e.g, TPCDS_SF100TCL), and <table_name> with the name of the table you want to query(e.g, Customer, Store, …).
For example:
SELECT * FROM snowflake-databricks-catalog.TPCDS_SF100TCL.store;Step 5—Manage Access (optional)
One of the powerful features of Databricks Lakehouse Federation is the ability to leverage Unity Catalog's fine-grained access control and data governance capabilities. You can manage access to the federated data sources, ensuring that only authorized users can access and query specific datasets.
1) In the Databricks workspace, navigate to the Unity Catalog by clicking on the "Catalog" icon.
2) Locate the foreign catalog you created for Snowflake (e.g., "Snowflake-Databricks-Catalog").
3) Select "Permissions" tab to manage access control.
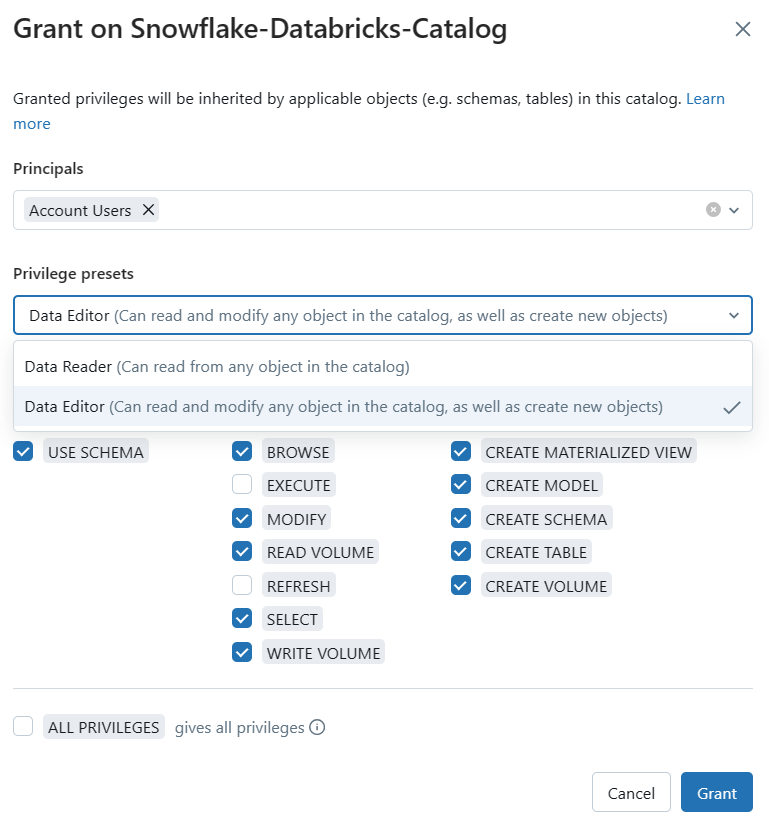
From here, you can grant or revoke permissions at the catalog, schema, or table level, controlling which users or groups can access and query specific datasets.
Unity Catalog's data lineage and search capabilities also extend to federated data sources, allowing you to track data usage, understand data provenance, and easily discover relevant datasets across your entire data landscape.
That's it! You've now connected Snowflake to Databricks, created a foreign catalog, queried data, and learned how to manage access and govern your federated data sources using Unity Catalog. Cheers!
What are the Limitations of Databricks Lakehouse Federation?
Databricks Lakehouse Federation offers numerous benefits and enables you to unlock the full potential of their distributed data, but it is important to be aware of its limitations and considerations:
1) Read-only Queries
One of the primary limitations of Lakehouse Federation is that queries against external data sources are read-only, meaning means that you can't modify or write data back to the external sources through this platform. If you need to make changes to the data, you'll have to do it directly within the external system.
2) Throttling and Concurrency Limits
The performance of federated queries is subject to the concurrency limits and throttling policies of the external data sources. If multiple users or applications are querying the same external source simultaneously, you may experience performance issues due to resource contention or throttling mechanisms implemented by the external system.
3) Network Latency
When you're pulling data from an external source over the network, the speed of your internet connection and the distance between the source and your Databricks cluster can affect how fast your queries run.
4) Data Freshness
Lakehouse Federation mirrors the schema and table structures of external data sources within Unity Catalog. While this mirroring process is generally real-time, there may be slight delays in reflecting changes made to the external sources, such as new tables or schema modifications. It is important to ensure that the data being queried is up-to-date.
5) Limited Support for Complex Data Types
Depending on the external data source, there may be limitations in terms of support for complex data types or nested data structures. Some data sources may have restrictions on the types of data that can be queried through Lakehouse Federation.
6) Vendor-specific Limitations
Each external data source may have its own set of limitations or restrictions when it comes to federated querying. These limitations can vary based on the specific database or data warehouse system being integrated with Lakehouse Federation.
7) Security and Compliance
It's important to review your organization's security and compliance requirements when connecting external data sources to ensure data privacy and adherence to regulations.
8) Naming Rules
If a table or schema name isn't compatible with Unity Catalog, it won't be included when creating a foreign catalog. Table names are converted to lowercase in Unity Catalog, so remember to use lowercase names when searching.
9) Private Link and Static IP Range
Serverless SQL warehouses don't support Private Link and static IP range.=
10) Subquery Handling
For each external table you reference, Databricks runs a subquery in the remote system to fetch a portion of the data, then sends it back to your Databricks task in a single stream.
11) Single-user Access
Single-user access mode is only available to users who own the connection.
Keep these limitations in mind when working with Databricks Lakehouse Federation to make the most of your data and maintain compliance with your organization's requirements.
Conclusion
Databricks Lakehouse Federation, a revolutionary solution that'll change the way you manage your distributed data! No more wasting time and money on data ingestion – Lakehouse Federation lets you query data across multiple sources without the hassle. Plus, you'll get a unified view of all your data in one place. Thanks to Unity Catalog, Lakehouse Federation has your back when it comes to data governance, access control, and data lineage tracking. Your data is secure and compliant, no matter where it's stored. And the best part of Databricks Lakehouse Federation is that it supports a ton of data sources, from relational databases to cloud data warehouses, and even other Databricks workspaces. So, you can keep using your current data infrastructure while reaping the benefits of the Databricks Platform.
In this article, we have covered:
- What Is Databricks Lakehouse Federation?
- What Are the Key Features of Databricks Lakehouse Federation?
- Benefits and Use Cases of Databricks Lakehouse Federation
- What Are the Supported Data Sources by Lakehouse Federation?
- Step-by- Step Guide to Query Data From Snowflake into Databricks Using Lakehouse Federation
- What are the Limitations of Databricks Lakehouse Federation?
…and so much more!
FAQs
What is Databricks Lakehouse Federation?
Databricks Lakehouse Federation is a query federation platform that enables organizations to run queries against multiple external data sources directly from within the Databricks environment, without the need for data ingestion or replication.
What is the purpose of Unity Catalog in Databricks Lakehouse Federation?
Unity Catalog acts as a centralized metadata store for managing external data sources, their schemas, tables, and access permissions, enabling seamless integration and querying from within Databricks.
Can Databricks Lakehouse Federation query data across multiple data sources?
Yes, one of the key features of Databricks Lakehouse Federation is its ability to query data across multiple external sources seamlessly using a single query.
What data sources are supported by Lakehouse Federation?
Databricks Lakehouse Federation supports a wide range of data sources, including MySQL, PostgreSQL, Amazon Redshift, Snowflake, Microsoft SQL Server, Azure Synapse (SQL Data Warehouse), Google BigQuery, and other Databricks workspaces.
Does Databricks Lakehouse Federation support data governance and access control?
Yes, Unity Catalog enables fine-grained access control and data governance for federated data sources, allowing you to set permissions at different levels and track data usage.
Can I modify or write data back to the external sources using Lakehouse Federation?
No, Databricks Lakehouse Federation currently supports read-only queries against external data sources. If data modification is required, it must be performed directly within the respective external system.
Does Databricks Lakehouse Federation require data duplication or ingestion?
No, it eliminates the need for data ingestion by querying data directly from external sources, reducing storage costs and ensuring analyses are always up-to-date.
Can Lakehouse Federation be used for incremental data migration?
Yes, Databricks Lakehouse Federation can facilitate a smoother transition towards a data lake architecture by allowing organizations to gradually migrate data from external sources to the Databricks.
What is a foreign catalog in Databricks Lakehouse Federation?
Foreign catalog is a virtual representation of an external database within Unity Catalog, mirroring the schema and table structures of the external data source.
Can Databricks Lakehouse Federation handle complex data types and nested data structures?
Depending on the external data source, there may be limitations in terms of support for complex data types or nested data structures.
Does Databricks Lakehouse Federation support advanced analytics and AI?
Yes, it works seamlessly with Databricks, allowing you to leverage advanced analytics and machine learning on your federated data.
Can Databricks Lakehouse Federation handle subqueries?
Yes, for each external table referenced, Databricks runs a subquery in the remote system to fetch a portion of the data, then sends it back to your Databricks task in a single stream.
Can you manage access to federated data sources in Databricks Lakehouse Federation?
Yes, you can leverage Unity Catalog's fine-grained access control and data governance capabilities to manage access to federated data sources.
Does Databricks Lakehouse Federation support Private Link and static IP range?
No, serverless SQL warehouses don't support Private Link and static IP range in Databricks Lakehouse Federation.















