


























Snowflake MERGE is an extremely useful and versatile command that allows you to insert, update, and delete values in a table based on values in another table or a subquery. It is one of the most powerful Snowflake commands, but why is Snowflake MERGE so important and useful? Because it simplifies and streamlines data integration and transformation tasks, which are essential for building and maintaining data pipelines. With the help of Snowflake MERGE, you can perform multiple data manipulation operations all at once in a single statement, instead of writing separate INSERT, UPDATE, and DELETE statements, reducing the complexity and the risk of data conflicts and improving the performance and efficiency of your queries.
In this article, we will cover everything you need to know about the Snowflake MERGE statement. We'll start with its syntax and a simple example, then explore advanced practical examples/use cases and the top 5 best techniques for optimizing Snowflake MERGE Queries.
What is a Snowflake MERGE Statement?
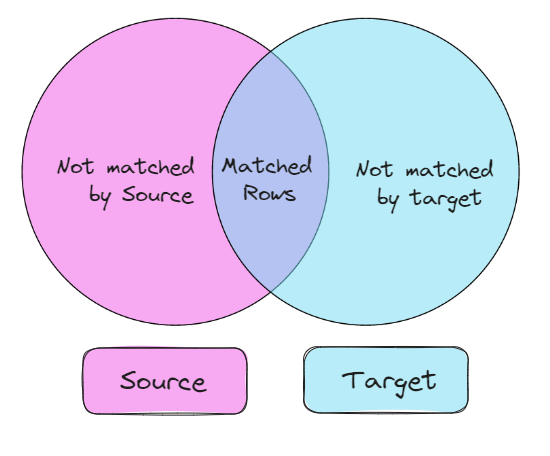
Snowflake MERGE is a powerful data manipulation statement that combines the functionalities of INSERT, UPDATE, and DELETE into a single atomic operation. It allows you to efficiently update or insert data into a target table based on the existence or condition of matching rows in a source table or subquery. This makes it particularly valuable for:
- Incremental data loading: Snowflake MERGE is very good at efficiently adding new data to existing tables, especially in scenarios with large datasets and frequent updates. It eliminates the need for costly and time-consuming full table refreshes.
- Data synchronization: Snowflake MERGE simplifies the process of synchronizing data between tables by enabling conditional updates and inserts based on specific criteria, which can be helpful for maintaining consistency between source and target.
- Upsert operations: Snowflake MERGE elegantly handles "upsert" scenarios, where you need to insert new rows if they don't exist and update existing rows if they do, eliminating the need for manual checks and separate INSERT/UPDATE statements.
…and more!
We will delve into various other use cases in detail in the later sections of this article.
Now, let's explore the syntax and parameters of Snowflake MERGE.
Syntax of the Snowflake MERGE statement is straightforward:
MERGE INTO <target_table> USING <source> ON <join_expr> { matchedClause | notMatchedClause } [ ... ]
Where:
matchedClause ::=
WHEN MATCHED [ AND <case_predicate> ] THEN { UPDATE SET <col_name> = <expr> [ , <col_name2> = <expr2> ... ] | DELETE } [ ... ]
notMatchedClause ::=
WHEN NOT MATCHED [ AND <case_predicate> ] THEN INSERT [ ( <col_name> [ , ... ] ) ] VALUES ( <expr> [ , ... ] )
Let’s look at each parameter in detailed explanations.
1) target_table
Specifies the table to merge into. It can be a permanent table, a temporary table, or a transient table. The target_table must have a primary key or a unique key constraint to ensure that each row can be uniquely identified by the join expression.
2) source
Specifies the table or subquery to merge from. It can be any valid table name or subquery expression that returns a result set. The source must have at least one column that can be joined with the target_table on the join expression.
3) join_expr
Specifies the expression on which to join the target and source tables. It can be any valid SQL expression that evaluates to a boolean value. The join_expr must be able to uniquely identify each row in the target and source tables, otherwise Snowflake MERGE statement may produce unpredictable or nondeterministic results.
4) matchedClause
Specifies the action to perform when the join expression evaluates to true (i.e. when the values match). It can include either an UPDATE statement, allowing modifications to specific columns, or a DELETE statement to remove the matched rows.
5) notMatchedClause
notMatchedClause parameter specifies the action to perform when the join expression evaluates to false (i.e. when the values do not match). In this case, only an INSERT statement is permitted. This allows the addition of new rows to the target table based on the unmatched values from the source.
TL;DR:
- target_table: Table to merge into.
- source: Table or subquery to merge from.
- join_expr: Expression for joining the target and source tables.
- matchedClause: Action for true match (UPDATE or DELETE).
- notMatchedClause: Action for false match (INSERT).
Now that we have explained the syntax and parameters of the Snowflake MERGE statement, let’s look at a simple example of how to use it.
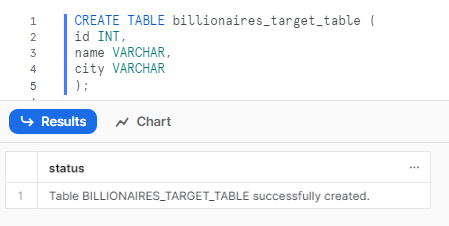
First, let’s create a target table called billionaires_target_table
CREATE TABLE billionaires_target_table (
id INT,
name VARCHAR,
city VARCHAR
);Snowflake MERGE Example
Now populate it with some dummy data
INSERT INTO billionaires_target_table VALUES
(1, 'Elon Musk', 'Texas'),
(2, 'Jeff Bezos', 'Chicago');Snowflake MERGE Example
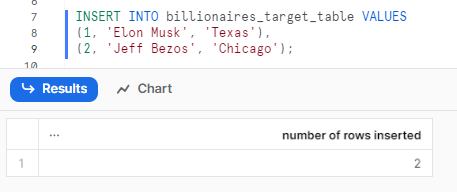
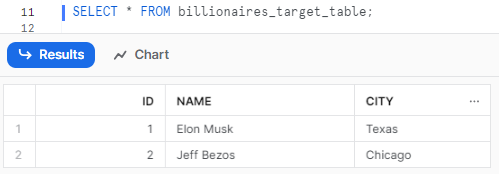
Let's check whether the data has been populated or not. To do so, you can use the "SELECT *" statement on that particular table.
SELECT * FROM billionaires_target_table;Snowflake MERGE Example
Now, let's create another table; this one will be the source table. To do that, you can execute the query below.
CREATE TABLE billionaires_source_table (
id INT,
name VARCHAR,
city VARCHAR
);Snowflake MERGE Example
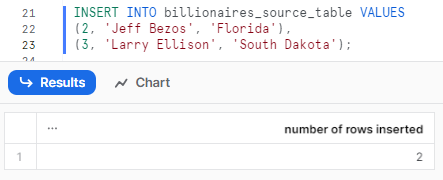
Again let’s populate it with some dummy data
INSERT INTO billionaires_source_table VALUES
(2, 'Jeff Bezos', 'Florida'),
(3, 'Larry Ellison', 'South Dakota');Snowflake MERGE Example
Finally, let’s MERGE the source into the target using Snowflake MERGE command
MERGE INTO billionaires_target_table tgt
USING billionaires_source_table src
ON tgt.id = src.id
WHEN MATCHED THEN
UPDATE SET tgt.city = src.city
WHEN NOT MATCHED THEN
INSERT (id, name, city) VALUES (src.id, src.name, src.city);Snowflake MERGE Example
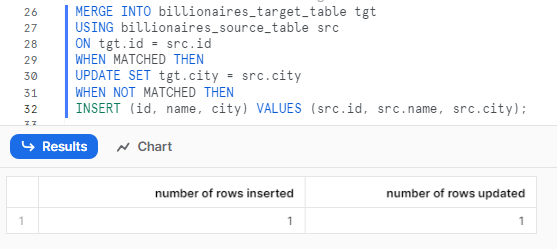
Let’s verify results and check whether the data has been MERGEd or not. To do so, you can use the "SELECT *" statement on that particular table.
SELECT * FROM billionaires_target_table;Snowflake MERGE Example
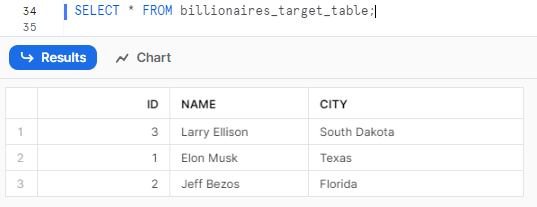
As you can see, we have successfully merged the table using the Snowflake MERGE statement, which updated Jeff Bezos's city from Chicago to Florida and inserted the new record for Larry Ellison into the target table.
Now, let's move on to the next section where we will discuss the difference between Snowflake MERGE and Snowflake UPDATE.
What Is the Difference Between UPDATE and Snowflake MERGE?
Both the UPDATE and Snowflake MERGE statements are designed to modify data in one table based on data from another, but Snowflake MERGE can do so much more—whereas UPDATE can only modify column values, Snowflake MERGE can synchronize all data changes, such as insertion, deletion, and modification of rows.
let's dive into the main difference between Snowflake MERGE and UPDATE. Here is a table that quickly summarizes the differences between the Snowflake MERGE and UPDATE.
|
Snowflake MERGE |
Snowflake UPDATE |
|
Snowflake MERGE can insert new rows into the target table when the values do not match in the source table |
Snowflake UPDATE can only modify existing rows |
|
Snowflake MERGE can delete existing rows from the target table when the values match in the source table |
It can only modify existing rows |
|
Snowflake MERGE can handle multiple matching and not matching conditions in a flexible and efficient way |
Can only handle one condition at a time |
|
Snowflake MERGE can perform all data changes in a single atomic statement |
Snowflake UPDATE may require multiple statements to achieve the same result. |
|
Syntax: MERGE INTO <target_table> USING <source> ON <join_expr> { matchedClause | notMatchedClause } [ ... ] |
Syntax: UPDATE <target_table> |
Practical Examples of Snowflake MERGE
In this section, we will dive into some practical examples of how to use Snowflake MERGE to perform data integration and transformation tasks. We will follow a step-by-step in-depth guide to create the target and source tables, insert some data, and merge the records from the source table to the target table.
First, we need to create a target table that we want to merge into. For this sample example, we will create a table called students_target and insert some dummy data into it. You can execute the following statement to create the students_target table:
CREATE OR REPLACE TABLE student_target (
id INT PRIMARY KEY,
name VARCHAR,
subject_id INT,
subject VARCHAR,
grade DECIMAL(10,2)
);
INSERT INTO student_target
VALUES
(1, 'Clark Kent', 101, 'Math', 91.5),
(2, 'Bruce Wayne', 102, 'Science', 85.0);Snowflake MERGE Example
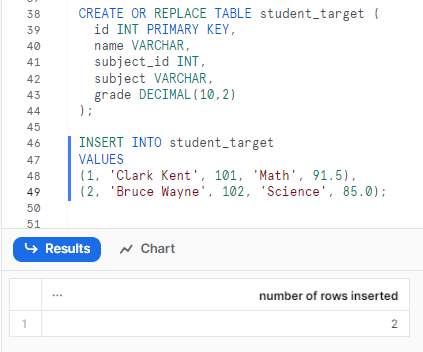
Let’s imagine this table contains our current student data. Now, we've got some new student updates that we need to merge in.
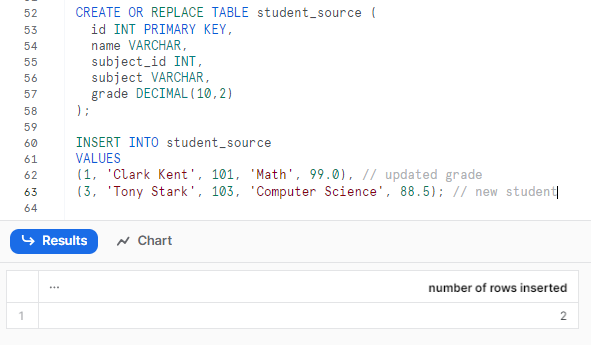
Next, we need a source table containing the new data. Let’s create the source table and insert the new student data.
CREATE OR REPLACE TABLE student_source (
id INT PRIMARY KEY,
name VARCHAR,
subject_id INT,
subject VARCHAR,
grade DECIMAL(10,2)
);
INSERT INTO student_source
VALUES
(1, 'Clark Kent', 101, 'Math', 99.0), // updated grade
(3, 'Tony Stark', 103, 'Computer Science', 88.5); // new studentSnowflake MERGE Example
First Up - Snowflake MERGE with Updates
Now, let’s MERGE this change into the target using Snowflake MERGE statement
MERGE INTO student_target tgt
USING student_source src
ON tgt.id = src.id
WHEN MATCHED THEN
UPDATE SET tgt.grade = src.grade;Snowflake MERGE Example
Let's check whether the table is merged or not. To do so, you can use the "SELECT *" statement on that particular table.
SELECT * FROM student_target;Snowflake MERGE Example
Boom! As you can see, WHEN MATCHED clause finds Clark Kent by id and updates his grade. Nice and simple.
Next Up - Snowflake MERGE with Updates and Inserts
Now let's add some inserts and updates in one Snowflake MERGE statement.
First, let’s insert a few records into the source table:
INSERT INTO student_source VALUES
(4, 'Harvey Dent', 105, 'History', 99),
(5, 'Scott Lang', 106, 'Quantum Physics', 85);Snowflake MERGE Example
Before proceeding with the merge, let's check and verify both our student_source and student_target table.
SELECT * FROM student_source;Snowflake MERGE Example
SELECT * FROM student_target;Snowflake MERGE Example
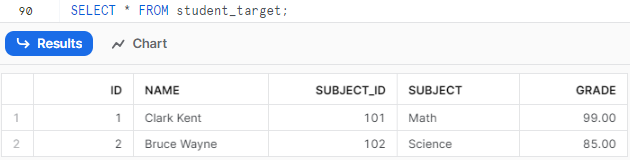
Time to perform a MERGE using the Snowflake MERGE statement.
MERGE INTO student_target tgt
USING student_source src
ON tgt.id = src.id
WHEN MATCHED THEN
UPDATE SET
tgt.grade = src.grade
WHEN NOT MATCHED THEN
INSERT (id, name, subject_id, subject, grade)
VALUES(src.id, src.name, src.subject_id, src.subject, src.grade);Snowflake MERGE Example
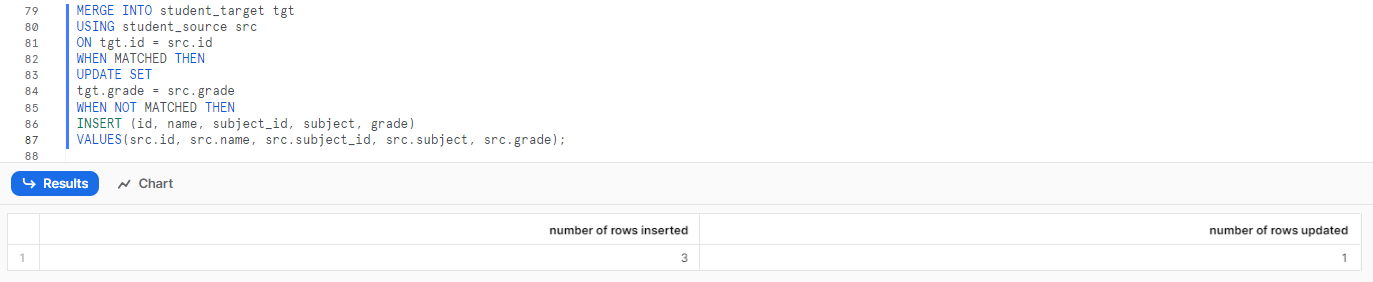
SELECT * FROM student_target;Snowflake MERGE Example
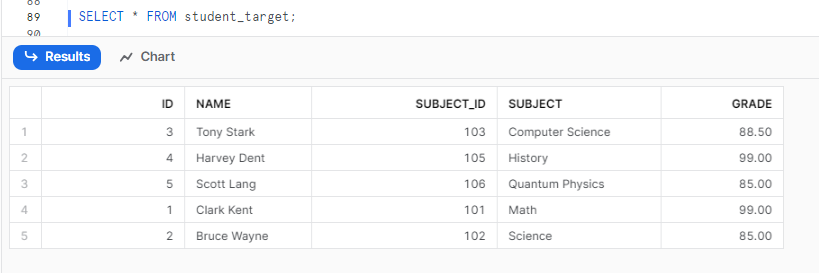
As you can see, the WHEN MATCHED clause identifies Clark Kent by ID and updates his grade, while the WHEN NOT MATCHED clause will insert two new rows into the target table since the new IDs are not present.
Finally - Snowflake MERGE with Updates, Inserts, and Deletes
Finally, let's look at a more advanced example using Snowflake MERGE to insert, update, and delete data in one shot. First, let's truncate the entire record from the student_source table and insert some new data into it.
TRUNCATE table student_source;Snowflake MERGE Example
Let’s add two more rows to the target table so we have some data to delete:
INSERT INTO student_source VALUES
(4, 'Harvey Dent', 105, 'History', 95),
(5, 'Scott Lang', 106, 'Quantum Physics', 100),
(6, 'Another Name1', 105, 'Some Subject1111', 70),
(7, NULL, NULL, NULL, NULL),
(8, NULL, NULL, NULL, NULL),
(9, NULL, NULL, NULL, NULL),
(10, 'Another Name2', 106, 'Some Subject2222', 80);Snowflake MERGE Example
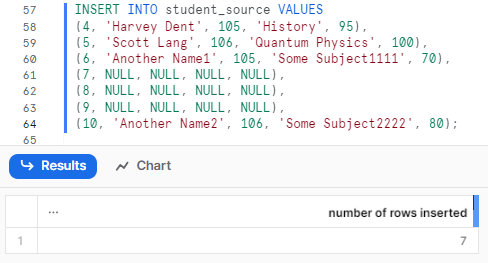
Finally, use Snowflake MERGE to MERGE these changes into the target table in one go:
MERGE INTO student_target tgt
USING student_source src
ON tgt.id = src.id
WHEN MATCHED AND src.grade IS NULL THEN DELETE
WHEN MATCHED THEN UPDATE SET tgt.grade = src.grade
WHEN NOT MATCHED THEN
INSERT (id, name, subject_id, subject, grade)
VALUES (src.id, src.name, src.subject_id, src.subject, src.grade);Snowflake MERGE Example
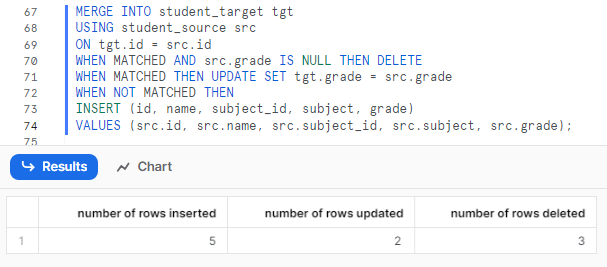
Finally, let's test and verify how our student source and target tables looks like:
SELECT * FROM student_source ORDER BY id ASC;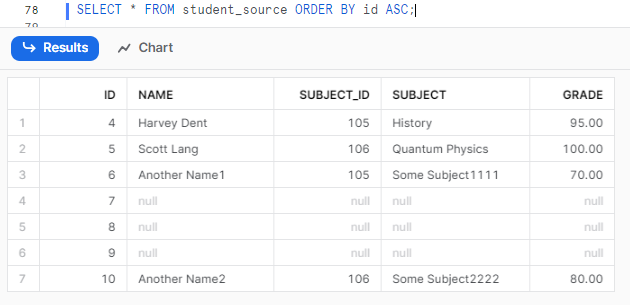
SELECT * FROM student_target ORDER BY id ASC;Snowflake MERGE Example
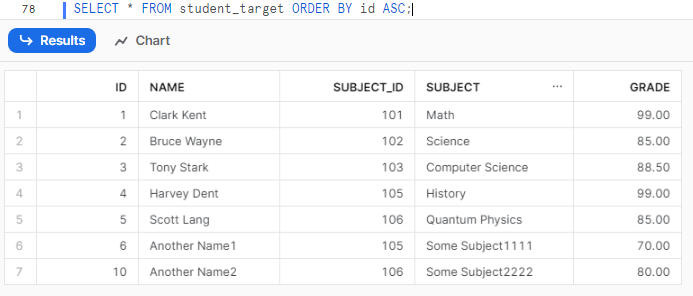
As you can see, we have successfully merged all the data from the source table to the target table. We inserted 5 new, fresh data points, removed all the null data, and updated 3 new data points, all by using a single statement, without having to perform manual insertions, updates, or deletions.
Advanced Snowflake MERGE Examples
Now, in this section, we will show you an advanced example of how to use Snowflake MERGE to perform data integration and transformation tasks using the sample data sets provided by Snowflake.
For this example, we will use the TPCH_SF1 schema, which contains tables for a business scenario based on the TPC-H benchmark. The TPCH_SF1 schema has eight tables, with different sizes and data types. You can find more information about the TPCH_SF1 schema and its tables from here.
First, we will create a permanent table called orders_target that we want to merge into. We will use the ORDERS table from the TPCH_SF1 schema as the base table for the target table. The ORDERS table contains the orders placed by the customers, with columns such as:
- order key
- order date
- customer key
- order status
- order total price
- order priority
- Clerk
- ship priority
- Comment
Let's create the orders_target table and order it by order priority, order status, and total price. By doing so, the orders_target table will be clustered by these columns.
CREATE OR REPLACE TABLE orders_target AS
SELECT * FROM
snowflake_sample_data.tpch_sf1.orders
ORDER BY o_orderpriority, o_orderstatus, o_totalprice;Snowflake MERGE Example
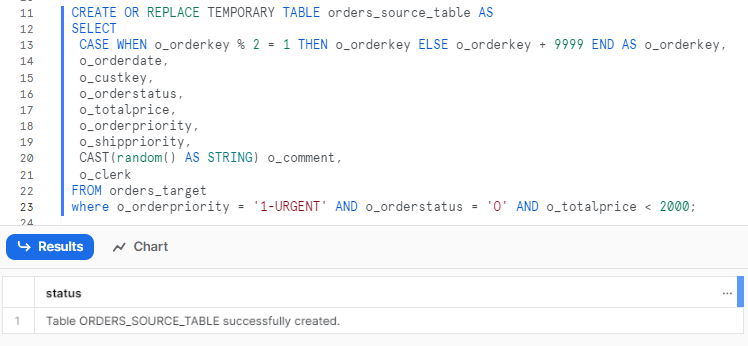
Now, create a temporary table called orders_source_table that you want to merge from. This table will contain orders with the order priority "1-URGENT", order status "O" and order total price less than (<) 2000, with some modifications. The order key column will be altered to either the original value or the original value plus 9999, depending on whether it is odd or even. This is to simulate some new records that do not exist in the target table. The comment column will be changed to a random string to simulate updated records with different values from the target table.
CREATE OR REPLACE TEMPORARY TABLE orders_source_table AS
SELECT
CASE WHEN o_orderkey % 2 = 1 THEN o_orderkey ELSE o_orderkey + 9999 END AS o_orderkey,
o_orderdate,
o_custkey,
o_orderstatus,
o_totalprice,
o_orderpriority,
o_shippriority,
CAST(random() AS STRING) o_comment,
o_clerk
FROM orders_target
where o_orderpriority = '1-URGENT' AND o_orderstatus = 'O' AND o_totalprice < 2000;Snowflake MERGE Example
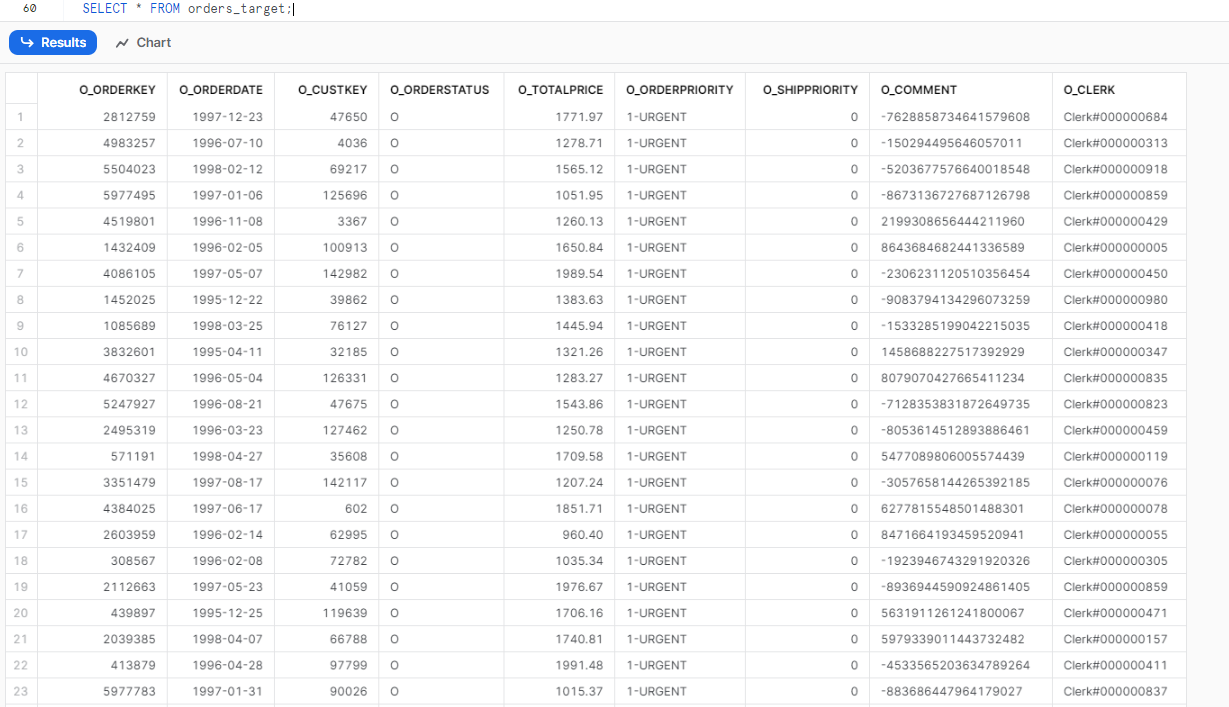
Here is how your orders_source_table should look like:
SELECT * FROM orders_target;Snowflake MERGE Example
Finally, we need to merge the records from the source table to the target table using the Snowflake MERGE statement. For this example, we will use the following logic:
- Update the O_COMMENT column of the target table with the value from the source table when the O_ORDERKEY values match.
- Insert the row from the source table into the target table when the O_ORDERKEY values do not match.
We can use the following Snowflake MERGE statement to achieve this:
MERGE INTO orders_target tgt
USING orders_source_table src
ON tgt.o_orderkey = src.o_orderkey
WHEN MATCHED THEN
UPDATE SET
tgt.o_comment = src.o_comment
WHEN NOT MATCHED THEN
INSERT (
o_orderkey,
o_custkey,
o_orderstatus,
o_totalprice,
o_orderdate,
o_orderpriority,
o_clerk,
o_shippriority,
o_comment
)
VALUES (
src.o_orderkey,
src.o_custkey,
src.o_orderstatus,
src.o_totalprice,
src.o_orderdate,
src.o_orderpriority,
src.o_clerk,
src.o_shippriority,
src.o_comment
);Snowflake MERGE Example
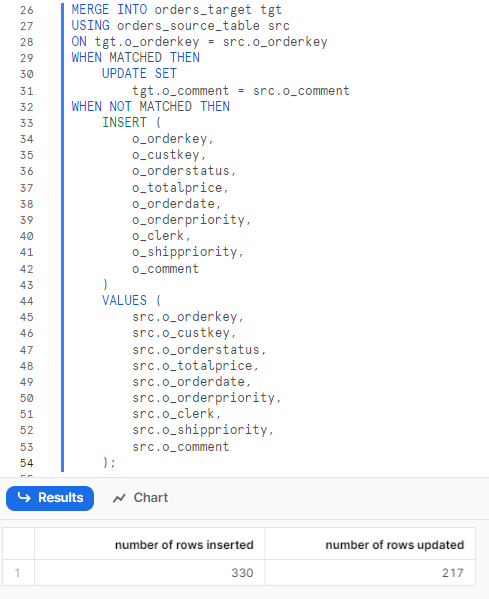
You will see that the target table will contain the merged orders from the source table, with updated and inserted rows based on the specified logic.
Check out this practical, real-world example of the Snowflake MERGE command in action.
5 Advanced Techniques for Optimizing Snowflake MERGE Queries
Snowflake MERGE operations can become complex and resource-intensive, particularly when handling large tables. Therefore, optimizing Snowflake MERGE queries is essential to get optimal performance and prevent errors. Here are 5 advanced optimization techniques for optimizing Snowflake MERGE queries:
Technique 1 — Examine Query Plan and Query Profile to Identify Bottlenecks
The first technique for optimizing MERGE queries is to examine the query plan and the query profile to identify bottlenecks and opportunities for improvement.
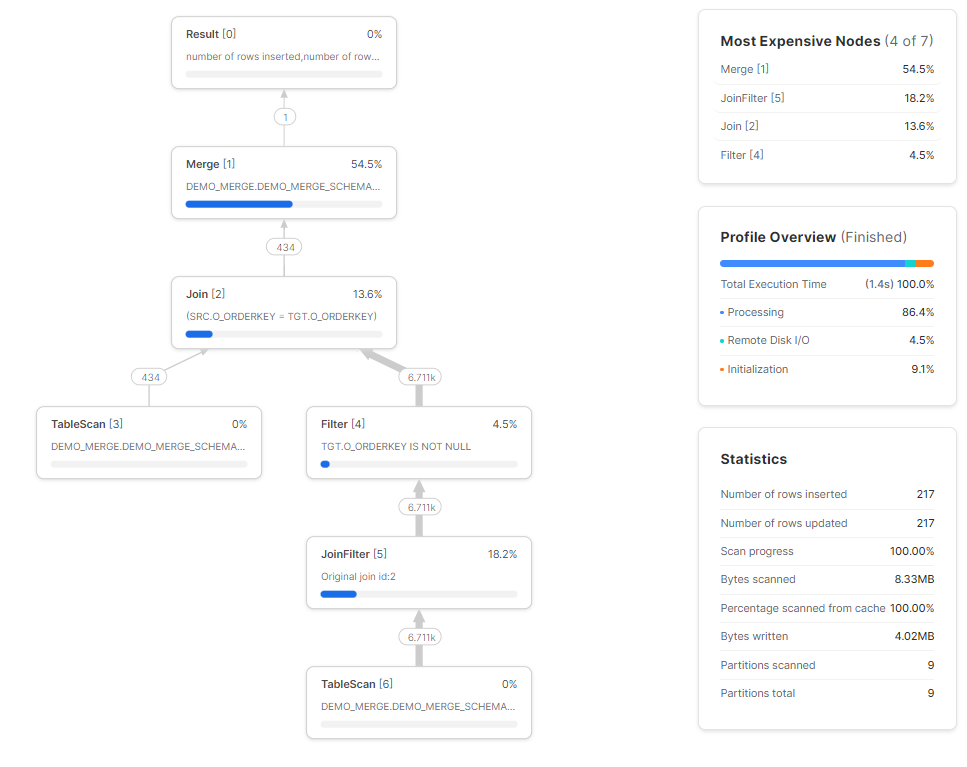
The query profile displays the physical execution of the query plan. Thus, by examining both the query plan and the query profile, you can gain insights into the performance and cost of your MERGE query. Let’s analyze it with our previous Snowflake MERGE example. As you can see from the above query profile screenshot, when initially executing Snowflake MERGE, one of the most expensive steps is often scanning the target table to find matching rows. This scan can take a substantial amount of time, proportional to the target table size.
To reduce this scan cost, you can leverage clustering on the target table so the query only accesses relevant partitions.
As you can see in the query profile, before the MERGE operation is even carried out, tables are joined via LEFT OUTER JOIN (for the NON-MATCHED clause) or INNER JOIN (for MATCHED).
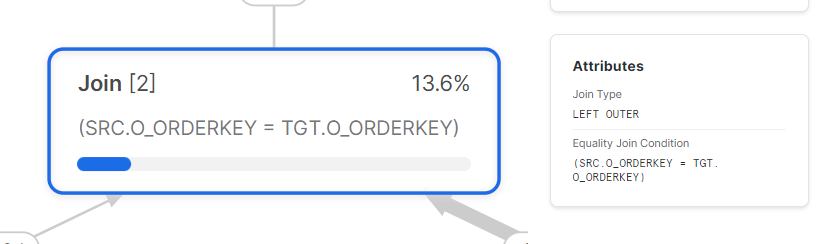
The JOIN between the target and source tables is an extremely crucial factor to consider. An inefficient join strategy can result in significant data shuffling between compute nodes. Carefully examine the join type and ordering chosen by the optimizer. In some cases, manually optimizing the join logic can yield substantial performance benefits.
Finally, pay close attention to any spilled data in the query profile. Data spilling to disk indicates extreme memory usage during processing. Complex joins are often a leading cause of spills. So, by tuning join logic and reducing shuffling, spills can usually be avoided, boosting performance.
Technique 2 — Understanding Duplicate Join Behaviors
Another crucial aspect of optimizing Snowflake MERGE performance is handling duplicate values correctly during the join between target and source tables. In this section, we will explore how duplicate join behaviors can affect the outcome of a Snowflake MERGE query—and how to avoid or handle ‘em.
Nondeterministic Results for UPDATE and DELETE
Nondeterministic results occur when a merge operation joins a row in the target table against multiple rows in the source. This can lead to ambiguity as Snowflake is unable to determine which source value should be used to update or delete the target row. This situation arises in two scenarios:
- A target row is selected to be updated with multiple values
- A target row is selected to be both updated and deleted
The outcome of the merge in these cases depends on the value specified for the ERROR_ON_NONDETERMINISTIC_MERGE session parameter. If set to TRUE (which is the default value), the merge operation returns an error. If set to FALSE, one row from among the duplicates is selected to perform the update or delete, but the selection is not defined.
Deterministic Results for UPDATE and DELETE
On the other hand, deterministic merges always complete without error. A merge is considered deterministic if it meets the following conditions for each target row:
- One or more source rows satisfy the WHEN MATCHED ... THEN DELETE clauses, and no other source rows satisfy any WHEN MATCHED clauses.
- Exactly one source row satisfies a WHEN MATCHED ... THEN UPDATE clause and no other source rows satisfy any WHEN MATCHED clauses.
These conditions make the MERGE operation semantically equivalent to the UPDATE and DELETE commands.
To avoid errors when multiple rows in the data source (i.e., the source table or subquery) match the target table based on the ON condition, it is recommended to use GROUP BY in the source clause. This ensures that each target row joins against one row (at most) in the source.
Deterministic Results for INSERT
Deterministic merges always complete without error. If the MERGE operation contains a WHEN NOT MATCHED ... THEN INSERT clause, and if there are no matching rows in the target, and if the source contains duplicate values, then the target gets one copy of the row for each copy in the source.
Check out this Snowflake documentation to learn more in-depth about it.
Technique 3 — Handle errors and exceptions when using Snowflake MERGE
As powerful as Snowflake MERGE is, a lot can go wrong during insert, update, and delete operations on large tables.
Let's discuss some common errors and how to handle ‘em:
1) Handling Duplicate Row
One frequent issue is duplicate key values causing non-deterministic MERGE errors. As discussed earlier, make sure that source tables are aggregated to provide unique keys.
Also, wrap the Snowflake MERGE in a TRY/CATCH block to catch any errors and handle them. Log the rows causing the issue while allowing the overall MERGE to continue.
2) Data Type Mismatches
If the target and source columns used in Snowflake MERGE don't match data types, you'll encounter a type conversion error during insertion or updating.
Define table columns properly upfront to avoid mismatches. Also, add explicit conversions in the Snowflake MERGE statement as needed to safely cast values.
3) Constraint Violations
Snowflake MERGE statements may violate constraints like PRIMARY KEY or UNIQUE on the target table during inserts or updates. Use NOT NULL constraints to prevent null errors.
Catch constraint violation errors in TRY/CATCH blocks and handle ‘em accordingly. For example, skip insertion for new rows that conflict with a primary key.
4) Timeouts
Complex Snowflake MERGE queries on large tables can encounter query timeouts and never finish. Increase timeouts for critical merges or break operations into smaller chunks.
Schedule merges during maintenance windows and test merges at scale to identify potential timeout risks early on.
Technique 4 — Using Dynamic Partition Pruning
Another advanced technique for slow Snowflake MERGE queries is enabling dynamic partition pruning to avoid scanning irrelevant data.
For example, say we need to update a few records on a large table.
Without pruning, the query has to scan all partitions to find the rows to update based on the key. But if the table is clustered, we can modify the query to prune unnecessary partitions.
By adding a join condition on the cluster key, Snowflake will scan only those partitions containing the data needed for the merge.
This is known as dynamic pruning — Snowflake determines at query runtime which partitions to scan based on the join values versus scanning everything upfront.
TLDR;
- Add predicates on cluster keys to enable partition pruning
- Let Snowflake dynamically skip scanning irrelevant data
- Result is faster query times by minimizing scanned partitions
Therefore, utilize dynamic partition pruning to dramatically improve Snowflake merge performance by avoiding expensive full table scans.
Technique 5 — Snowflake Merge vs Update/Insert
So we've covered a ton of optimizations for Snowflake MERGE queries. But sometimes it's worth stepping back and asking—is using Snowflake MERGE even the best approach?
The main tradeoff is Snowflake MERGE gives you atomicity by handling upserts in one go. But you pay massive cost for the additional logic to stitch the update and insert operations together.
If you have a large table always try to test MERGE side by side with dedicated UPDATE and INSERT queries.
If your updates and inserts are hitting different parts of the table, separate statements may allow more parallelism and smaller transactions.
The optimal approach depends on your data size, table design, and transaction needs. But it's worth experimenting to see if breaking apart MERGE into more focused update/insert chunks works better.
Always carefully select the techniques covered here to make sure the most efficient synchronization and transformation of your data. Use these strategies to maximize the benefits of Snowflake MERGE.
Use Cases for Snowflake MERGE
On top of the examples and optimization techniques we've discussed thus far, here are some other common use cases of Snowflake MERGE:
1) Data Synchronization
If you have two tables that need to be in sync, Snowflake MERGE can help you do that. For instance, you might have a table with customer information and another table with order information. Snowflake MERGE enables you to update the customer table with the latest order details from the order table. It can also be used to delete any rows from the customer table that are not in the order table. This way, you can make sure that both tables have the same and accurate data.
2) Data Deduplication
Snowflake MERGE is effective in removing duplicate rows from your table. For example, if you have a table containing web traffic data from different sources, you can use Snowflake MERGE to identify and remove duplicate rows based on the IP address, date, and time of the visit. Also, you can define criteria for updating or deleting duplicate rows, keeping only the most recent or relevant data.
3) Incremental Updates
Snowflake MERGE supports incremental updates to a table, allowing seamless and effortless insertions or modifications of data from a source table or subquery. This is particularly useful for keeping historical or transactional tables up-to-date.
4) Staging Table Integration
Snowflake MERGE can also help you integrate data from a staging table into a production table. This is useful for validating, cleaning, and transforming data before loading it into the final table. For example, you might have a staging table that loads data from an external source and a production table that stores the final data. You can use Snowflake MERGE to check, fix—and modify the data in the staging table before merging it into the production table and also use it to handle any conflicts between the staging table and the production table.
5) Incremental Update for Slowly Changing Dimension Table
Snowflake MERGE is also great for maintaining slowly changing dim tables, where you need to keep track of the historical changes. It can help you update existing records or insert new ones based on the changing data. Let’s say, for example; you might have a table with employee info and another table with employee salary history. You can use Snowflake MERGE to update the employee table with the latest salary info from the salary history table. You can also use it to insert a new row in the employee table with the previous salary info, preserving the history of the changes.
6) Change Data Capture (CDC)
Implementing change data capture (CDC) is simplified with Snowflake MERGE, allowing for real-time synchronization of changes from a source table to a target table, which makes sure that the target table stays updated with the latest changes.
7) Data Merging from Multiple Sources
Snowflake MERGE can help you combine data from different sources into one table, giving you a comprehensive view of the data. For instance, you might have different tables with customer data, such as their name, address, phone number, what they bought, and how many points they have. You can use Snowflake MERGE to bring all the data from these tables into one table, making a full customer profile. You can decide how to match, update, or insert records from different sources to the main table based on your needs.
8) Batch Processing
Snowflake MERGE can also help you process large tables quickly and easily. It lets you apply changes from one table to another table in one go, making sure the data is correct and consistent.
Snowflake MERGE is extremely powerful for any situation requiring synchronized insert, update, and delete capabilities. Once you get the hang of these tips and techniques, you'll be a real pro at using it.
Conclusion
And that’s a wrap! Snowflake MERGE is a command that lets you change values in a table using another table or a subquery.It is very handy because it simplifies and speeds up data integration and transformation. You can do many things with just one Snowflake MERGE statement, instead of having to write multiple DML statements, saving resources, time and helping you avoid errors.
In this article, we have covered:
- What is a Snowflake MERGE Statement?
- What Is the Difference Between UPDATE and Snowflake MERGE?
- Practical Advanced Examples of Snowflake MERGE
- 5 Advanced Techniques for Optimizing Snowflake MERGE Queries
- Use Cases for Snowflake MERGE
…and so much more!
Boom! If you follow these Snowflake MERGE tips and techniques that we have outlined in this article, you can synchronize large datasets in Snowflake efficiently. So go ahead, start merging—and take your Snowflake game to a whole new level!!!
FAQs
What is Snowflake MERGE?
A single statement for performing inserts, updates, and deletes in a single transaction, based on conditions applied to source and target data.
What are the advantages of using MERGE?
Improved performance, data consistency, and transactionality compared to multiple DML statements.
How is Snowflake MERGE different from UPDATE?
Unlike UPDATE, Snowflake MERGE can insert new rows and delete rows. MERGE handles multiple match and non-match conditions efficiently in one statement.
When should I use MERGE instead of INSERT, UPDATE, and DELETE?
Complex data operations involving conditional inserts, updates, and deletes on large data sets.
What actions can you perform in the WHEN MATCHED clause?
WHEN MATCHED clause can perform UPDATE or DELETE actions on rows that match between the source and target.
What actions can you perform in the WHEN NOT MATCHED clause?
WHEN NOT MATCHED clause can only perform INSERT actions to add new rows from the source to the target.
What causes non-deterministic errors in Snowflake MERGE?
Joining duplicate key values in the source can cause nondeterministic errors when updating/deleting target rows.
Can I use Snowflake MERGE for Change Data Capture (CDC)?
Yes, MERGE facilitates CDC by tracking changes in a source table and applying them to a target table in real-time.
When is Snowflake MERGE preferred over INSERT/UPDATE?
MERGE is preferred when atomic upsert capability is needed. It synchronizes changes in one step versus separate INSERT/UPDATE statements.
What causes spilled data during Snowflake MERGE?
Complex joins between large source and target tables can cause spilled data due to memory pressure. Tuning joins helps avoid spills.
Can Snowflake MERGE queries cause non-error failures?
Yes, complex MERGE queries can hit timeouts on large tables. Increase timeouts or break operations into smaller chunks.
Can I combine MERGE with other performance optimization techniques?
Yes, using materialized views, clustering, and semi-structured data formats can further enhance Snowflake MERGE efficiency.
Should I always use Snowflake MERGE for large data updates?
While Snowflake MERGE is good in complex scenarios, simpler updates on smaller datasets might benefit from separate INSERT, UPDATE, and DELETE statements.
Can MERGE access data outside of Snowflake?
Yes, Snowflake MERGE can retrieve data from external stages, databases and cloud storage via cloud provider connectors.
Are there any tools or services for monitoring and managing Snowflake MERGE performance?
Yes, tools like Chaos Genius can track Snowflake MERGE execution times, resource consumption, and potential bottlenecks.









