

























Last week, Databricks launched DBRX—a groundbreaking state-of-the-art open large language model that sets a new standard in the field. DBRX represents a breakthrough in open LLM technology, pushing the boundaries of what's possible with open source AI models. DBRX's capabilities are not just incremental; they are transformative, perfectly aligning with Databricks' mission to democratize data intelligence and empower users or businesses to take charge of their AI future. Remarkably, this cutting-edge model outperforms nearly all established open source models and even rivals closed-source LLM giants like GPT-4, Gemini, and Mistral across various benchmarks.
In this article, we'll cover everything you need to know about DBRX: its unique features, development process, performance comparisons with open and closed-source models, and a step-by-step guide to install it on your local machine—and so much more!
What is a Large Language Model (LLM)?
Large Language Models, or LLMs for short, are advanced machine learning models trained on massive datasets containing vast amounts of text data. They are capable of generating, predicting, and analyzing human-like language, as well as performing various natural language processing tasks, such as:
- Text Generation: Creating coherent and contextually relevant text based on input prompts.
- Language Translation: Translating text from one language to another while maintaining the original meaning.
- Question Answering: Providing answers to questions by understanding the context and content of the query.
- Sentiment Analysis: Determining the sentiment or emotional tone behind a piece of text.
Recent progress in deep learning, especially with transformer-based architectures, has significantly enhanced the performance of LLMs. Transformers use self-attention mechanisms to weigh the importance of different parts of the input data, which is particularly beneficial for tasks involving natural language understanding and generation.
LLMs have a wide range of applications across various industries, such as:
- Content Creation: Assisting in writing articles and stories and generating creative content like poetry.
- Virtual Assistants: Powering conversational agents that can interact with users in a natural way.
- Chatbots: Providing customer support and engaging users through messaging platforms.
- Language Translation Services: Offering real-time translation services for global communication.
…and so much more!
So, when you interact with an AI system capable of processing and generating text in a way that feels intuitive and human-like, it's very likely powered by a Large Language Model!
These days, a bunch of Large Language Models (LLMs) have been making waves and getting widespread recognition and adoption, both in the closed-source and open source worlds. Let's take a look at some of the big names:
Closed Source LLMs:
- GPT-3 (Generative Pre-trained Transformer 3): Developed by OpenAI, this autoregressive language model has been trained on a massive amount of text data. As part of the GPT family of language models, it uses the Transformer architecture to generate human-like text.
- GPT-4: Also developed by OpenAI, GPT-4 is the successor to GPT-3, released in March 2023. It is a multimodal model capable of accepting both text and image inputs, generating text outputs that demonstrate human-level performance across various benchmarks.
- Claude (Anthropic): Developed by Anthropic, Claude is known for its strong performance in coding, math, and reasoning tasks. With the latest versions like Claude 3, you can expect improved performance, longer responses, and easy accessibility via API.
- Gemini (1.0/1.5): Google's large language model, known for its exceptional understanding and reasoning capabilities. Gemini has demonstrated strong performance on tasks such as the Massive Multitask Language Understanding (MMLU) benchmark, outperforming human experts.
Open Source LLMs:
- LLaMA (Large Language Model Meta AI): Developed by Meta AI, LLaMA is a family of large language models designed for versatile natural language processing tasks, such as text generation, question answering, and language translation.
- Grok-1: Developed by xAI, a company founded by Elon Musk. It's a mixture-of-experts (MoE) model with 314 billion parameters and is designed to be more efficient than traditional LLMs.
- Mixtral 8x7B: A Sparse Mixture of Experts (SMoE) language model by Mistral AI, Mixtral demonstrates strong capabilities in mathematical reasoning, code generation, and multilingual tasks.
- DBRX: Developed by Databricks, DBRX is an open, general-purpose LLM that has set new benchmarks for open LLMs and is particularly strong as a code model. It uses a fine-grained mixture-of-experts architecture for efficient training and inference. Stick around because we'll dive deeper into this in the next section!
Databricks and its Language Model—DBRX
Databricks is renowned for its cloud-based platform that revolutionizes data engineering and analytics. It provides a unified environment designed to handle vast datasets with ease. Originating from the creators of Apache Spark, Databricks enables users to leverage the full capabilities of Spark alongside other state-of-the-art technologies within a collaborative ecosystem. Databricks is at the forefront of data intelligence and AI innovation. Their mission? To democratize data, analytics, and AI, making these technologies accessible to everyone.
The latest masterpiece of Databricks' innovation is DBRX—a super-advanced, cutting-edge, state-of-the-art language model that truly showcases Databricks' commitment to pushing the boundaries of technology and fostering open-source collaboration. DBRX is a transformer-based, decoder-only large language model, boasting a total of 132 billion parameters. Of these, 36 billion parameters are actively utilized during inference, thanks to its unique fine-grained mixture-of-experts (MoE) architecture. This innovative approach enables DBRX to selectively activate a subset of its parameters in response to the input it receives, thereby enhancing both efficiency and performance.
What Makes Databricks DBRX Unique?
Databricks DBRX is a state-of-the-art language model that distinguishes itself from other large language models (LLMs) with its advanced architecture and innovative training process.
Training Process and Architecture
DBRX was trained using next-token prediction, a popular technique employed in training transformer-based models. It uses a fine-grained mixture-of-experts (MoE) architecture with a whopping 132 billion total parameters, of which 36 billion parameters are active/live on any given input. Unlike other open MoE models like Mixtral and Grok-1, which use 8 experts and choose 2, DBRX uses 16 experts and selects 4 of them for any given input. This fine-grained approach provides a staggering ~65 times more possible combinations of experts, enhancing the model's overall quality and performance.
Advance Innovative Features/Techniques
DBRX uses several innovative techniques that enhance its capabilities:
- Rotary Position Encodings (RoPE): RoPE provides the model with a more nuanced understanding of token positions in the input sequence, crucial for generating coherent and contextually relevant text.
- Gated Linear Units (GLU): GLUs introduce a gating mechanism into the model's architecture, enabling it to control information flow and learn complex patterns more effectively.
- Grouped Query Attention (GQA): GQA enhances the model's efficiency and performance by partitioning the attention mechanism into smaller groups.
- GPT-4 Tokenizer (tiktoken): DBRX uses the GPT-4 tokenizer, which helps in processing input text efficiently and accurately.
Pre-training Data
DBRX was pre-trained on an impressive 12 trillion tokens of carefully curated text and code data, with a maximum context length of 32,000 tokens. Databricks estimates that this dataset is at least twice as effective token-for-token compared to the data used to pre-train their previous MPT family of models. The dataset was developed using a suite of various Databricks tools (which we will delve into in the next section).
How Was Databricks DBRX Built?
Databricks DBRX was built using a combination of powerful hardware infrastructure, advanced software tools, and deep expertise in large language model development.
1) Hardware Infrastructure
The training process of DBRX required significant computational resources, which were provided by 3072 NVIDIA H100s connected via 3.2Tbps Infiniband.
2) Software Tools
Various Software and internal Databricks tools were used throughout the building process of DBRX, they are:
- Data Management and Governance: Unity Catalog was used for managing and governing the vast amounts of training data required for the DBRX model.
- Data Exploration: Databricks' newly acquired Lilac AI platform was utilized to facilitate data exploration and analysis, providing insights into the dataset and enabling informed decisions during the pre-training phase.
- Data Processing and Cleaning: Apache Spark and Databricks notebooks were used for efficient data processing and cleaning tasks, ensuring high-quality input for the model training process.
- Model Training Libraries: Optimized versions of open source training libraries, including MegaBlocks, LLM Foundry, Composer, and Streaming, were used, which played a crucial role in the model's development and training.
- Large-Scale Model Training: The Mosaic AI Training service was instrumental in managing large-scale model training across thousands of GPUs, streamlining the process and ensuring efficient resource utilization.
- Results Logging: MLflow was used for logging and tracking the results of various experiments and training runs, providing valuable insights for iterative model refinement.
- Human Feedback Collection: Mosaic AI Model Serving and Inference Tables were used to collect human feedback on the model's performance, particularly regarding quality and safety improvements.
- Manual Experimentation: Databricks Playground was used to help developers to manually experiment with the model, allowing for hands-on fine-tuning and assessment of the model's capabilities.
Development Process and Timeline
The development process of building DBRX, including pre-training, post-training, evaluation, red-teaming, and refining, took three months. However, this was the continuation of months of science, dataset research, scaling experiments, and years of LLM development at Databricks, including the MPT and Dolly projects.
How Does DBRX Performance Compare Against Popular "Open" Models?
Databricks has introduced two models—DBRX Base and DBRX Instruct. DBRX Instruct is a general-purpose model that excels in various benchmarks, particularly in programming and mathematics. Let's delve into the technical details of how DBRX Instruct compares against popular open models and explore its strong points.
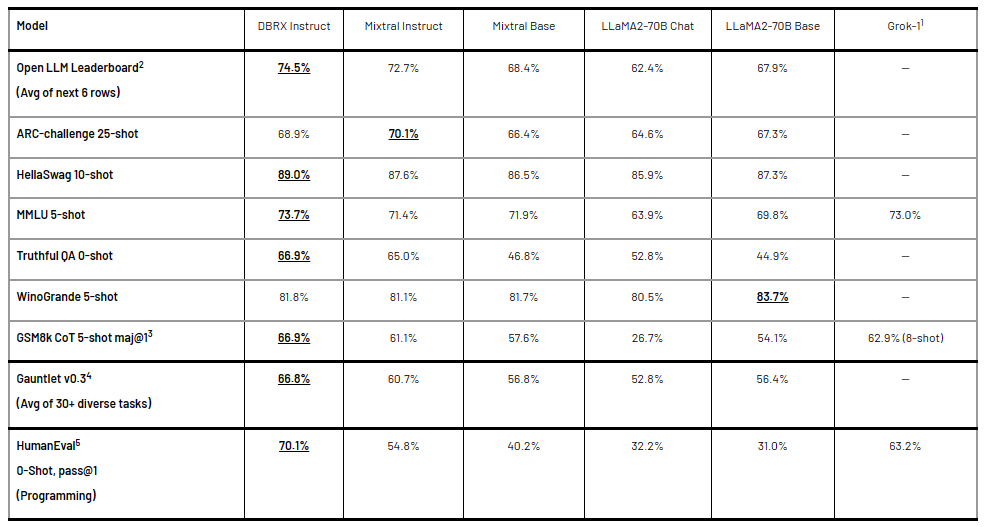
DBRX vs. Mixtral Instruct
Let's dive into the comparison between DBRX and Mixtral Instruct across various benchmarks:
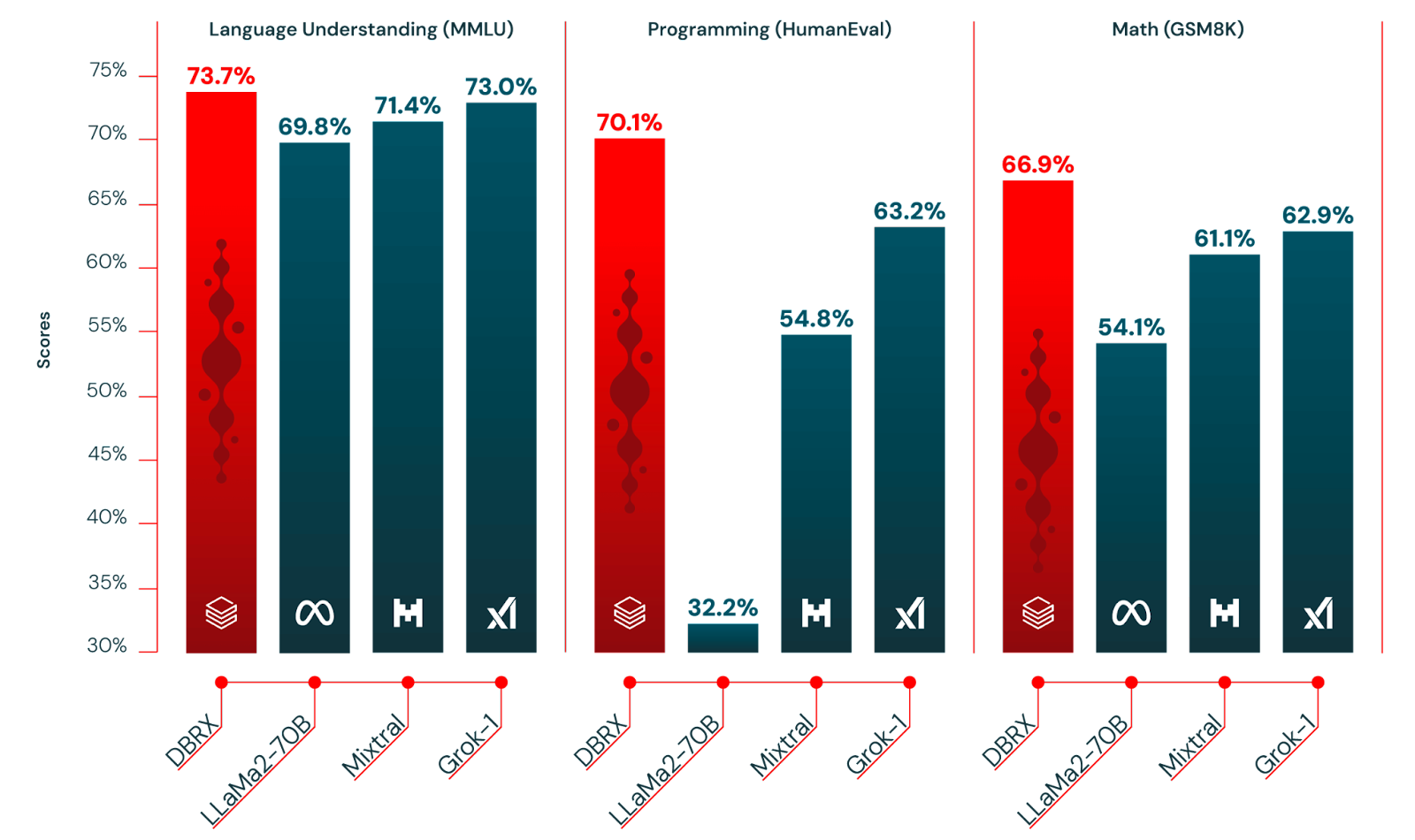
1) General Knowledge: On the MMLU (Multiple-choice Model-Linguistic Understanding) benchmark:
- MMLU score: 73.7% (DBRX Instruct) vs. 71.4% (Mixtral Instruct)
2) Commonsense Reasoning: DBRX Instruct showcases exceptional performance on benchmarks like HellaSwag and WinoGrande:
- HellaSwag score: 89.0% (DBRX Instruct) vs. 87.6% (Mixtral Instruct)
- WinoGrande score: 81.8% (DBRX Instruct) vs. 81.1% (Mixtral Instruct)
3) Databricks Gauntlet: Gauntlet, a novel technique for evaluating pretrained foundation models, demonstrates:
- Databricks Gauntlet score: 66.8% (DBRX Instruct) vs. 60.7% (Mixtral Instruct)
4) Programming and Mathematical Reasoning: DBRX Instruct shines in programming and mathematical reasoning, as evidenced by benchmarks like HumanEval and GSM8k:
- HumanEval score: 70.1% (DBRX Instruct) vs. 54.8% (Mixtral Instruct)
- GSM8k score: 66.9% (DBRX Instruct) vs. 61.1% (Mixtral Instruct)
DBRX vs. Mixtral Base
Let's take a closer look at DBRX vs. Mixtral Base
1) General Knowledge: On the MMLU (Multiple-choice Model-Linguistic Understanding) benchmark:
- MMLU score: 73.7% (DBRX Instruct) vs. 71.9% (Mixtral Base)
2) Commonsense Reasoning: DBRX Instruct showcases exceptional performance on benchmarks like HellaSwag and WinoGrande:
- HellaSwag score: 89.0% (DBRX Instruct) vs. 86.5% (Mixtral Base)
- WinoGrande score: 81.8% (DBRX Instruct) vs. 81.7% (Mixtral Base)
3) Databricks Gauntlet score: 66.8% (DBRX Instruct) vs. 56.8% (Mixtral Base)
4) Programming and Mathematical Reasoning: DBRX Instruct shines in programming and mathematical reasoning, as evidenced by benchmarks like HumanEval and GSM8k:
- HumanEval score: 70.1% (DBRX Instruct) vs. 40.2% (Mixtral Base)
- GSM8k score: 66.9% (DBRX Instruct) vs. 57.6% (Mixtral Base)
DBRX vs. LLaMA2-70B
Let's take a closer look at DBRX vs. LLaMA2-70B
1) General Knowledge: On the MMLU (Multiple-choice Model-Linguistic Understanding) benchmark:
- MMLU score: 73.7% (DBRX Instruct) vs. 63.9% (LLaMA2-70B)
2) Commonsense Reasoning: DBRX Instruct showcases exceptional performance on benchmarks like HellaSwag and WinoGrande:
- HellaSwag score: 89.0% (DBRX Instruct) vs. 85.9% (LLaMA2-70B)
- WinoGrande score: 81.8% (DBRX Instruct) vs. 80.5% (LLaMA2-70B)
3) Databricks Gauntlet score: 66.8% (DBRX Instruct) vs. 52.8% (LLaMA2-70B)
4) Programming and Mathematical Reasoning: DBRX Instruct shines in programming and mathematical reasoning, as evidenced by benchmarks like HumanEval and GSM8k:
- HumanEval score: 70.1% (DBRX Instruct) vs. 32.2% (LLaMA2-70B)
- GSM8k score: 66.9% (DBRX Instruct) vs. 26.7% (LLaMA2-70B)
DBRX vs. Grok-1
Let's take a closer look at DBRX vs. Grok-1
1) General Knowledge: On the MMLU (Multiple-choice Model-Linguistic Understanding) benchmark:
- MMLU score: 73.7% (DBRX Instruct) vs. 73.0% (Grok-1)
2) Programming and Mathematical Reasoning: DBRX Instruct shines in programming and mathematical reasoning, as evidenced by benchmarks like HumanEval and GSM8k:
- HumanEval score: 70.1% (DBRX Instruct) vs. 63.2% (Grok-1)
- GSM8k score: 66.9% (DBRX Instruct) vs. 62.9% (Grok-1)
Check out the following table to get deeper insights into the benchmark performance differences between DBRX and other open source models.
How Does DBRX Performance Compare Against Popular "Closed" Models?
Now in this section, we dive into the benchmark performance comparison of DBRX Instruct against some of the popular closed models, including GPT-3.5, Gemini 1.0 Pro, Mistral Medium, Claude 3 Haiku.
DBRX vs. ChatGPT 3.5
Let's take a closer look at DBRX vs. ChatGPT 3.5
1) General Knowledge: On MMLU (Multiple-choice Model-Linguistic Understanding) benchmark:
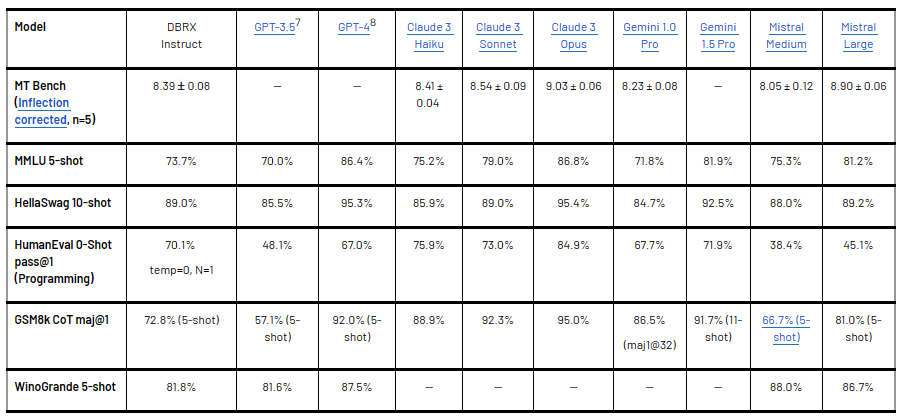
- MMLU score: 73.7% (DBRX Instruct) vs. 70.0% (GPT-3.5)
2) Commonsense Reasoning: DBRX Instruct demonstrates exceptional performance on HellaSwag and WinoGrande benchmarks.
- HellaSwag score: 89.0% (DBRX Instruct) vs. 85.5% (GPT-3.5)
- WinoGrande score: 81.8% (DBRX Instruct) vs. 81.6% (GPT-3.5)
3) Programming and Mathematical Reasoning: HumanEval and GSM8k benchmarks demonstrate DBRX Instruct's strength in programming and mathematical reasoning, with scores:
- HumanEval score: 70.1% (DBRX Instruct) vs. 48.1% (GPT-3.5)
- GSM8k score: 72.8% (DBRX Instruct) vs. 57.1% (GPT-3.5)
DBRX vs. Mistral Medium
Let's take a closer look at DBRX vs. Mistral Medium
1) General Knowledge: On MMLU (Multiple-choice Model-Linguistic Understanding) benchmark:
- MMLU score: 73.7% (DBRX Instruct) vs. 75.3% (Mistral Medium)
2) Commonsense Reasoning (HellaSwag and WinoGrande benchmarks):
- HellaSwag score: 89.0% (DBRX Instruct) vs. 88.0% (Mistral Medium)
- WinoGrande score: 81.8% (DBRX Instruct) vs. 88.0% (Mistral Medium)
3) Programming and Math Reasoning (HumanEval and GSM8k benchmarks):
- HumanEval score: 70.1% (DBRX Instruct) vs. 38.4% (Mistral Medium)
- GSM8k score: 72.8% (DBRX Instruct) vs. 66.7% (Mistral Medium)
DBRX vs. Gemini 1.0 Pro
Let's take a closer look at DBRX vs. Gemini 1.0 Pro
1) General Knowledge: On MMLU (Multiple-choice Model-Linguistic Understanding) benchmark:
- MMLU score: 73.7% (DBRX Instruct) vs. 71.8% (Gemini 1.0 Pro)
2) Commonsense Reasoning (HellaSwag benchmark):
- HellaSwag score: 89.0% (DBRX Instruct) vs. 84.7% (Gemini 1.0 Pro)
3) Programming and Math Reasoning (HumanEval and GSM8k benchmarks):
- HumanEval score: 70.1% (DBRX Instruct) vs. 67.7% (Gemini 1.0 Pro)
- GSM8k score: 72.8% (DBRX Instruct) vs. 86.5% (Gemini 1.0 Pro)
DBRX vs. Claude 3 Haiku
Let's take a closer look at DBRX vs. Claude 3 Haiku
1) General Knowledge: On MMLU (Multiple-choice Model-Linguistic Understanding) benchmark:
- MMLU score: 73.7% (DBRX Instruct) vs. 75.2% (Claude 3 Haiku)
2) Commonsense Reasoning (HellaSwag benchmark)
- HellaSwag score: 89.0% (DBRX Instruct) vs. 85.9% (Claude 3 Haiku)
3) Programming and Math Reasoning (HumanEval and GSM8k benchmarks)
- HumanEval score: 70.1% (DBRX Instruct) vs. 75.9% (Claude 3 Haiku)
- GSM8k score: 72.8% (DBRX Instruct) vs. 88.9% (Claude 3 Haiku)
As you can see, the benchmark tests conducted across various parameters, such as general knowledge, commonsense reasoning, programming, mathematical reasoning, and language understanding, show that DBRX Instruct either surpasses or matches these closed-source models across most of these parameters.
Check out the following table to get deeper insights into the benchmark performance differences between DBRX and various other closed models.
How Does DBRX Perform on Long-Context Tasks and RAG?
One of the standout features of DBRX is its ability to process and generate text over extended context lengths. DBRX Instruct was trained with up to a 32K token context window. This capability is particularly valuable for tasks that require processing and reasoning over large volumes of information, such as long-form question answering, document summarization, and information retrieval. To evaluate its performance on long-context tasks, the Databricks team used the KV-Pairs dataset from the "Lost in the Middle" paper and HotpotQAXL, a modified version of HotPotQA.
Long-Context Benchmarks:
The following compares DBRX Instruct's performance with Mixtral Instruct, Anthropic's GPT-3.5 Turbo, and Anthropic's GPT-4 Turbo on the KV-Pairs dataset at varying context lengths.
DBRX vs. Mixtral Instruct
Let’s take a closer look at DBRX vs. Mixtral Instruct
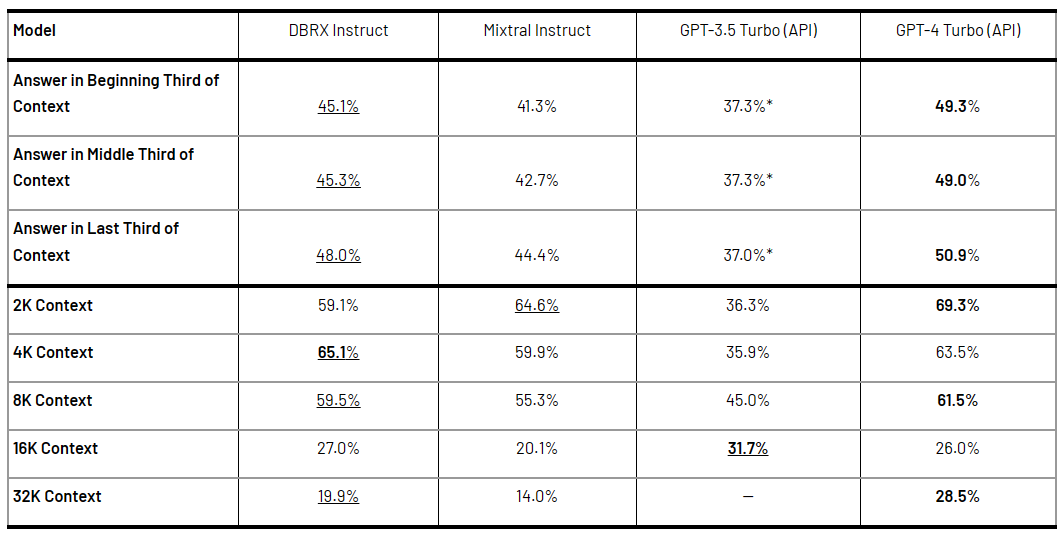
- At 2K Context: DBRX Instruct achieved 59.1%, while Mistral Medium scored 64.6%.
- At 4K Context: DBRX Instruct achieved 65.1%, while Mistral Medium scored 59.9%.
- At 8K Context: DBRX Instruct achieved 59.5%, while Mistral Medium scored 55.3%.
- At 16K Context: DBRX Instruct achieved 27.0%, while Mistral Medium scored 20.1%.
- At 32K Context: DBRX Instruct achieved 19.9%, while Mistral Medium scored 14.0%.
DBRX vs. GPT-3.5 Turbo (API)
Let's take a closer look at DBRX vs. GPT-3.5 Turbo (API)
- At 2K Context: DBRX Instruct achieved 59.1%, while GPT-3.5 Turbo scored 36.3%.
- At 4K Context: DBRX Instruct achieved 65.1%, while GPT-3.5 Turbo scored 35.9%.
- At 8K Context: DBRX Instruct achieved 59.5%, while GPT-3.5 Turbo scored 45.0%.
- At 16K Context: DBRX Instruct achieved 27.0%, while GPT-3.5 Turbo scored 31.7%.
Note: GPT-3.5 Turbo include only contexts up to 16K
DBRX vs. GPT-4 Turbo (API)
Let's take a closer look at DBRX vs. GPT-4 Turbo (API)
- At 2K Context: DBRX Instruct achieved 59.1%, while GPT-4 Turbo scored 69.3%.
- At 4K Context: DBRX Instruct achieved 65.1%, while GPT-4 Turbo scored 63.5%.
- At 8K Context: DBRX Instruct achieved 59.5%, while GPT-4 Turbo scored 61.5%.
- At 16K Context: DBRX Instruct achieved 27.0%, while GPT-4 Turbo scored 26.0%.
- At 32K Context: DBRX Instruct achieved 19.9%, while GPT-4 Turbo scored 28.5%.
Check out the following table to get deeper insights into the long form conbtext benchmark performance differences between DBRX and other models.
As the benchmarks demonstrate, GPT-4 Turbo typically outperforms the other models across these tasks. However, DBRX Instruct consistently surpasses GPT-3.5 Turbo in all context lengths and context positions. Notably, DBRX Instruct's overall performance is similar to Mixtral Instruct.
Retrieval Augmented Generation (RAG) Benchmark:
DBRX also shines when it comes to retrieval augmented generation (RAG) tasks, which are like supercharged question-answering. In RAG, models don’t just generate answers based on your prompt, they actually find related content from a database and use it to give you better, more accurate responses.
DBRX was put to the test on two RAG benchmarks, Natural Questions and HotPotQA, to see how well it performed. The test provided the models with the top 10 passages from a Wikipedia database using the bge-large-en-v1.5 embedding model. Here is the benchmark result:
DBRX vs. Mixtral Instruct
Let's take a closer look at DBRX vs. Mixtral Instruct
- Natural Questions: 60.0% (DBRX Instruct) vs. 59.1% (GPT-4 Turbo)
- HotPotQA: 55.0% (DBRX Instruct) vs. 54.2% (GPT-4 Turbo)
DBRX vs. LLaMa2-70B Chat
Let's take a closer look at DBRX vs. LLaMa2-70B
- Natural Questions: 60.0% (DBRX Instruct) vs. 56.5% (LLaMa2-70B)
- HotPotQA: 55.0% (DBRX Instruct) vs. 54.7% (LLaMa2-70B)
DBRX vs. GPT 3.5 Turbo (API)
Let's take a closer look at DBRX vs. GPT 3.5 Turbo (API)
- Natural Questions: 60.0% (DBRX Instruct) vs. 57.7% (GPT 3.5 Turbo)
- HotPotQA: 55.0% (DBRX Instruct) vs. 53.0% (GPT 3.5 Turbo)
DBRX vs. GPT 4 Turbo (API)
Let's take a closer look at DBRX vs. GPT 4 Turbo (API)
- Natural Questions: 60.0% (DBRX Instruct) vs. 63.9% (GPT-4 Turbo)
- HotPotQA: 55.0% (DBRX Instruct) vs. 62.9% (GPT-4 Turbo)
On the RAG benchmarks, GPT-4 Turbo outperformed DBRX Instruct.
Check out the following table to gain deeper insights into the RAG benchmark performance differences between DBRX and other closed models.

Check out Databricks' technical article on DBRX for a deep dive into its training and inference efficiency, along with other in-depth details.
Step-By-Step Guide to Setup Databricks DBRX Locally
If you're excited to try out Databricks' DBRX model for yourself, Databricks has made it relatively easy to set up the model on your local machine. But, keep in mind that running a large language model like DBRX can be resource-intensive, requiring significant processing power and memory.
Prerequisites:
Before diving into the setup process, make sure that you have the following prerequisites in place:
- Python environment with pip installed: DBRX relies on Python and its package management system, pip, for installation and execution.
- Hugging Face account and access token: Access to DBRX's weights and tokenizer is managed through Hugging Face, so you'll need an account and a valid access token.
- At least 320GB of memory (recommended): While the exact memory requirements may vary, Databricks recommends having at least 320GB of available memory to run DBRX flawlessly.
Step 1—Clone the DBRX Repository
First, you'll need to clone the DBRX repository from Github:
git clone https://github.com/databricks/dbrx.gitStep 2—Install Required Python Packages
Navigate to the cloned repository and install the required packages by running:
pip install -r requirements.txt Alternatively, if you want to leverage GPU acceleration and use flash attention, install the GPU-specific requirements:
pip install -r requirements-gpu.txtStep 3—Log in to Hugging Face
Next, authenticate with Hugging Face by running the following command and entering your access token when prompted:
huggingface-cli loginStep 4—Accept the License for DBRX
Before you can download DBRX's weights and tokenizer, you'll need to visit the DBRX Hugging Face page and accept the license agreement.
Note: Access to the Base model requires manual approval from the Databricks team.
Step 5—Download Weights and Tokenizer
Once you've accepted the license, you can proceed to download DBRX's weights and tokenizer. The exact steps may vary depending on the version of the model you wish to use (DBRX Base or DBRX Instruct).
Step 6—Make Sure to Verify Hardware Requirements
Before running DBRX, make sure that your system meets the hardware requirements, particularly in terms of memory and computational power, as DBRX is a resource-intensive model.
Step 7—Run Quickstart Script (Optional)
If you'd like to quickly test DBRX's capabilities, you can run the provided quickstart script:
python generate.pyOptional—Explore Advanced Usage
For more advanced use cases, refer to LLM Foundry for chat scripts , batch generation, and other resources.
Step 8—Use Inference (Optional)
If you plan to run optimized inference with DBRX, you have several options available:
- TensorRT-LLM: Support for DBRX is currently being added. Once the relevant PRs are merged, you can follow the instructions in the repository's README to build and run DBRX TensorRT engines.
- vLLM: Refer to the vLLM documentation for instructions on running DBRX with the vLLM engine.
- MLX: If you have an Apple laptop with a sufficiently powerful M-series chip, you can run a quantized version of DBRX using MLX. Follow the instructions provided for running DBRX on MLX.
Step 9—Use the Docker Image
If you encounter any issues with package installation or compatibility, Databricks recommends using their provided Docker image:
docker pull mosaicml/llm-foundry:2.2.1_cu121_flash2-latestThis Docker image includes all the necessary dependencies and configurations to run DBRX smoothly.
Where to Explore DBRX—Integrations and Platforms
If you want to experience Databricks DBRX's capabilities but prefer a more straightforward approach than setting it up locally, you're in luck! Databricks has made the model accessible through various user-friendly platforms and third-party integrations, catering to a wide range of users and use cases. Let's dive into the available options.
Databricks Platform
For Databricks users, it offers two main ways to explore and use DBRX:
Third-Party Integrations
Several third-party providers have also embraced DBRX's potential, integrating the model into their services and expanding its accessibility even further:
1) You.com

As DBRX gains popularity, we can expect even more third-party providers to follow suit, broadening the ecosystem of platforms and services powered by the model.
Customization and Tailored Models
For users or businesses with specific requirements or unique datasets, Databricks offers the option to fine-tune DBRX or develop custom models tailored to their specific needs. For this, you need to contact them directly.
Conclusion
And that's a wrap! The rise of Large Language Models (LLMs) is revolutionizing the world as we know it. As these models advance, it's crucial to ensure that everyone can benefit from their potential. Open LLMs play a pivotal role in democratizing AI by providing accessible tools for users to innovate and push the boundaries of what's possible. DBRX is a prime example of a state-of-the-art open LLM with the goal of helping the community explore new frontiers in natural language processing. As more and more people start using DBRX and come up with new ways to apply it, we can expect even more exciting developments in the world of natural language processing and understanding. Get ready to see what amazing things Databricks DBRX can do!
In this article, we have covered:
- What is a Large Language Model (LLM)?
- What is DBRX?
- What makes Databricks DBRX unique?
- How was Databricks DBRX built?
- How does DBRX performance compare against Popular open models?
- How does DBRX performance compare against Popular closed models?
- How does DBRX perform on long context tasks and rag?
- Step-by-step guide to set up Databricks DBRX locally
- Where to explore DBRX—integrations and platforms
FAQs
What is a Large Language Model (LLM)?
Large Language Model (LLM) is an advanced machine learning model trained on massive datasets containing vast amounts of text data. LLMs are capable of generating, predicting, and analyzing human-like language, as well as performing various natural language processing tasks.
What is DBRX?
DBRX is a state-of-the-art, open source, general-purpose large language model developed by Databricks, boasting 132 billion parameters and using a fine-grained mixture-of-experts (MoE) architecture.
What makes DBRX unique?
DBRX's unique features include its fine-grained MoE architecture with 16 experts and the ability to select 4 of them for any given input, providing a staggering ~65 times more possible combinations of experts compared to other open MoE models.
How was DBRX trained?
DBRX was pre-trained on an impressive 12 trillion tokens of carefully curated text and code data, with a maximum context length of 32,000 tokens.
What hardware infrastructure was used to train DBRX?
The training process of DBRX required significant computational resources, provided by 3072 * NVIDIA H100s connected via 3.2Tbps Infiniband.
How does DBRX compare to other open models on general knowledge benchmarks?
On the MMLU (Multiple-choice Model-Linguistic Understanding) benchmark, DBRX Instruct achieved a score of 73.7%, outperforming models like Mixtral Instruct (71.4%) and LLaMA2-70B (63.9%).
How does DBRX perform on programming and mathematical reasoning benchmarks?
DBRX Instruct excels in programming and mathematical reasoning, scoring 70.1% on HumanEval and 66.9% on GSM8k, surpassing most open models.
How does DBRX compare to closed models like GPT-4 on general knowledge benchmarks?
On the MMLU benchmark, DBRX Instruct (73.7%) performs comparably to GPT-4 Turbo (75.2%) and outperforms GPT-3.5 (70.0%).
How does DBRX perform on long-context tasks?
DBRX Instruct was trained with up to a 32K token context window, demonstrating strong performance on long-context tasks like the KV-Pairs dataset and HotpotQAXL.
How does DBRX compare to other models on Retrieval Augmented Generation (RAG) benchmarks?
On RAG benchmarks like Natural Questions and HotPotQA, DBRX Instruct performs competitively, outperforming models like GPT-3.5 Turbo and LLaMa2-70B while trailing behind GPT-4 Turbo.
What are the minimum hardware requirements for running DBRX locally?
Databricks recommends having at least 320GB of available memory to run DBRX flawlessly.
How can users access DBRX on the Databricks platform?
Databricks users can access DBRX through Mosaic AI Model Serving for integrating DBRX into applications and workflows, or through the Mosaic AI Playground for an interactive chat-based experience.
Can DBRX be fine-tuned or customized for specific use cases?
Databricks offers the option to fine-tune DBRX or develop custom models tailored to specific requirements or unique datasets by contacting them directly.
Is DBRX truly open source, or are there any restrictions on its use?
Yes, DBRX is 100% open source and available under Databricks Open Model License. Databricks has made the model's code and weights freely available, enabling anyone to use, modify, and build upon DBRX without restrictions.















