


























Data engineering is the process of designing, building, maintaining, and running systems and infrastructure for storing, processing, and analyzing large, complex datasets. It is a field that has recently become much more important because of the growth of “big data” and the growing reliance on business models that are driven by data. In fact, according to a report by Gensigma, demand for data engineers has grown so quickly that an organization needs at least 10 data engineers for every three data scientists. The global market for big data and data engineering services is also seeing significant growth, with estimates ranging from a whopping 18% to 31% increase on a per-year basis from 2017 to 2025. This shows how important it is to learn and improve data engineering skills since it can be a rewarding, high-paying, and in-demand field in the tech industry right now.
This particular innovation was primarily driven by the FAANG (now MAANGO) companies (Facebook (Meta), Amazon, Apple, Netflix, Google, and Oracle), who have adopted data-driven business models and built advanced data infrastructure to support them. These companies have put a lot of money and time into hiring and developing data engineering talent and technologies. They have also helped create new tools and ways to manage and analyze data at a large scale.
So, nowadays, companies and businesses rely heavily on data to improve their products and services by understanding user actions and behavior. Because of this, they “have to” heavily rely on data engineers to design + build + maintain the infrastructure and systems that enable the collection, storage, and analysis of large and complex data sets. Data engineering has therefore become a crucial field, with skilled data engineers playing a key role in driving data-driven innovations. In this article, we’ll look into the different parts and processes involved in data engineering, including DataOps, and how they help companies and businesses use the power of data to make their products and services better.
Collecting and Storing Data
In today’s digital world, virtually every online action you perform generates information that is collected and held onto by businesses, companies, or corporations. This includes visiting web apps and websites, ordering products or merchandise, using apps, and more. The MAIN question is, where do these companies keep all of this data? The answer is in a database management system (DBMS).
There are two main types of DBMS:
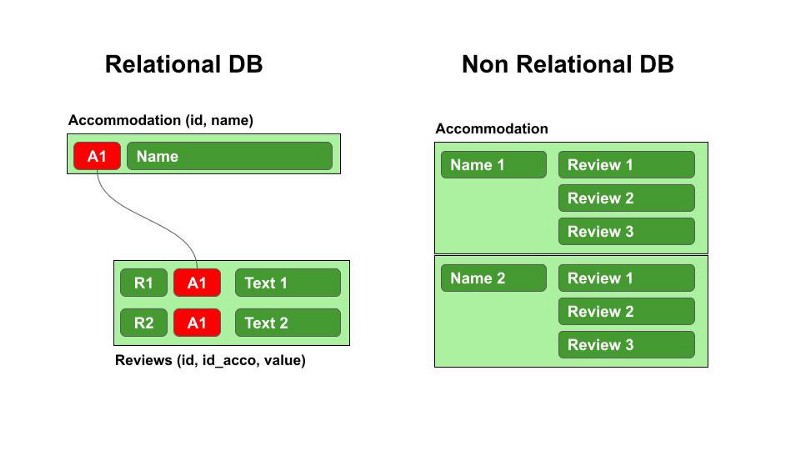
Relational databases
Relational databases store data in a way that looks like a spreadsheet format, with rows + columns. These are often used to store structured data, such as customer orders/inventory. A few perfect examples of a relational databases are MySQL, PostgreSQL, MariaDB, Microsoft SQL Server, and Oracle Database. To build a relational database, we need to make a “data model” that shows how the different tables work together. This helps to understand the entire picture and makes it easier to analyze the data which would make the analysis a great deal and a whole lott!! less complicated and difficult to do so.
Non-relational databases (also referred to as NoSQL databases)
On the other hand, NoSQL (non-relational) databases store data in varied formats, like key-value pairs, documents, and graphs. It is often used for handling large amounts of unstructured or semi-structured data, such as that generated by social media + online giants. They are also well-suited for applications that require high levels of flexibility and scalability.
“The type of database a company uses depends on its specific needs. There are many different companies that make use of both relational and non-relational db to store and manage their data. For example, Amazon uses both relational and non-relational database(like cassandra + DynamoDB) to store customer, product catalog, and order, and ads info. Google also uses both types of databases, with relational databases (like MySQL) and non-relational databases (like Bigtable and Cloud Datastore). Facebook, Twitter, Netflix, Uber, Airbnb, LinkedIn, Indeed and Dropbox are also among the other companies that make use both relational and non-relational databases to store and manage their data. These databases are used to store and manage a wide variety of data, including user data, product and service data, and business-critical information.”
Using SQL to Communicate with Databases
We can make use of a scripting language like Structured Query Language(SQL) to extract all the necessary information from a database. SQL allows us to communicate with the database easily and helps to retrieve the desired data by passing very simple commands.
For example(as shown in the screenshot below), we can use commands like:
SELECT * FROM table_name LIMIT 5
This particular command retrieves the first five rows from a table(of 91 rows). SQL also allows us to perform various different kinds of operations, such as inserting, updating, and deleting data directly from the database itself.
Learn more about SQL form here.
Using Programming Languages with Databases
In addition to Structured Query Language(SQL), we can also use a variety of different programming languages, such as Python, Java, JavaScript, R, Julia, Scala, or any other programming language as long as it supports a basic database connection and functions to perform all of those operations, to connect to databases and perform more advanced query operations on the data. This gives us greater flexibility and allows us to apply custom-created logic to the data.
The Data Engineering Process
Once the data is stored in a database, the next step is to use it to solve complex business problems. This can be achieved by creating dashboard metrics, machine learning models, and various other types of solutions. The process of going from raw data in a database to a final solution is known as “data engineering.” This “data engineering” process, also known as DataOps, usually may consist of several steps and can be different from company to company depending on its specific needs as well as requirements.
Essential Role of OLTP and OLAP in Data Engineering
Let’s skip ahead to the earlier section now that you understand what “data engineering” is.
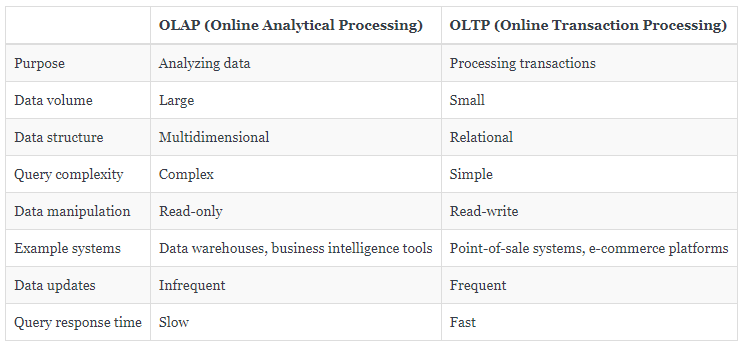
Relational databases are designed for faster reading, writing, and updating of data, rather than in-depth analysis. This means that if you try to run a large analytics query on a relational database, it may not be able to handle the workload and could potentially crash. In order to gain insights from data, we need a different type of system that is optimized for analytics work. This is where OLAP (Online Analytical Processing) comes in. But wait!! So what is OLTP and OLAP??
Online Transaction Processing (OLTP)
Online Transaction Processing (OLTP) is a type of database system that is designed to support high-concurrency, data-intensive transactions. It is typically used to handle large volumes of data that are constantly being inserted + updated + deleted, such as in a retail or financial application. OLTP systems are typically implemented using a Relational Database Management System and use Structured Query Language (SQL) for data manipulation and query processing. Learn more from here.
Online Analytical Processing (OLAP)
On the other hand, Online Analytical Processing (OLAP) is a type of database system that is designed for fast querying and analysis of data. It is typically used to support business intelligence(BI) and decision-making activities, such as data mining, data analysis, statistical analysis, and reporting. OLAP systems are designed to support complex queries and calculations on large data sets, often involving aggregations and roll-ups of data across multiple dimensions. Learn more from here.
Moving Data from OLTP to OLAP: ETL
To analyze the data that is stored in an OLTP system, such as a Postgres or MySQL database, we need to transfer it to an OLAP system or a Data Warehouse like Snowflake.

This exact process is called ETL (extract, transform, load).

ETL involves extracting data from one or multiple sources, transforming it based on business logic or the data warehouse design, and then loading it onto a one specific target location.

Learn more about ETL from here.
Traditional and Modern “ETL” Approaches
Traditionally, ETL pipelines were developed through the laborious process of writing them from absolutely scratch. However, newer approaches and tools are constantly being developed, released, and made easily available for purchase on the market. So, for instance, rather than developing a complete ETL pipeline from scratch, you can use a platform and tools like AWS Glue and Fivetran which provides a fully managed environment to Extract, load, and transform data in the data warehouse based on your specific requirements.

These particular tools are designed to save you the time and effort of having to manually write an entire ETL pipeline from absolute scratch. There are numerous tools available on the market, but it is important not to become TOO attached to any one of them because they may come and go. However, the fundamental concepts, such as understanding query languages and data processing systems like OLTP and OLAP, will remain the same forever.
The Data Processing Dilemma: Batch vs. Real-Time Processing
Different businesses, companies, and people have different requirements. Some of them — those businesses and companies — want to view that data in real time, while others want to view their data only once (depending upon their use cases and requirements); Therefore, it is becoming increasingly important to carefully select the right processing system to manage and make use of that particular data. So in general, we have two processing techniques:
1). Batch processing
2). Real-time processing

Batch processing involves persisting data as it comes in through events. For example, let's say A company named “Awesome” operates a simple e-commerce website that sells merchandise. The company uses batch processing to periodically extract data from its transactional DB and load it into a data warehouse. The data warehouse is used to perform data analysis and generate reports on customer behavior, sales, trends, and other business metrics; this is the perfect example of batch processing.
Whereas, Real-time processing involves persistently storing data as it comes in through events in real-time. For example, Companies like Uber and In-Drive use GPS trackers in their fleets of vehicles. Every vehicle’s location, speed, and other data are constantly being sent to a centralized server by the GPS units installed in them. So, the real-time processing system set up by these companies analyzes the data from the GPS units in near real-time. This information is used to give passengers up-to-date updates on things like vehicle locations and expected arrival times.
Processing Large Amounts of Data
For small amounts of data, it is possible to process it on a single computer. However, when dealing with HUGE amounts of data, multiple computers(processing powerhouse) are needed to divide and process the data in chunks and combine the final output.
There are several frameworks available for batch processing, such as Hadoop, Apache Storm, and DataTorrent RTS.

For real-time streaming, we have other frameworks and tools like Apache Kafka, ActiveMQ, and AWS Kinesis.

Choosing the right processing system depends on the specific needs and requirements. So, by understanding the difference between OLTP and OLAP and the options for batch and real-time processing, you can select the right tools and technology to build a solution that meets your exact requirements.
Big data landscape and cloud computing
The big data landscape is filled with various tools/technology for multiple different types of work they do and issues they solve. However, processing large amounts of data requires a powerful system, such as big data-crunching machines like supercomputers. In the past, companies and businesses would build their own servers and maintain them in a local data center. This often resulted in multiple hardware failures and issues requiring maintenance and software upgrades.
Benefits of Moving to the Cloud
Many businesses and companies are moving and transitioning their entire operations to the cloud to escape headaches associated with hardware breakdowns and regular software updates (as we mentioned earlier). Because of this, companies only have to pay for the resources that they really use, and they can scale their servers to meet any demand. Cloud service providers also provide several different kinds of services to manage large amounts of data and ease the process of storing and processing data, making the entire process much more manageable. According to a Gartner cloud computing infrastructure ranking, the top three cloud platform providers are Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure.

Modern Data Stack and Data Engineering Industry
Once a business or company has its architecture running on a cloud platform and has established ETL pipelines and a data warehouse, they can use this data for analytics and machine learning applications. After that, data engineers + AI/ML engineers will be able to create and implement machine learning models in production, allowing the company to develop and obtain deep insights.

Problems and Solutions in the Data Engineering Industry (The Emergence of the Modern Data Stack)
The field of data engineering is growing rapidly and with it comes a wide range of MASSIVE challenges. One common issue is the difficulty of migrating data from local(on-premise) systems to cloud warehouses, which can get very complex and time-consuming. Many businesses encounter problems during this process and try to create solutions for them. When one company faces a problem, it is likely that other companies might encounter the same kind of issues and difficulties. This creates opportunities for companies/businesses to identify gaps in the market and develop new tools to address these needs. This is exactly what led to the development of the “Modern Data Stack”.


Conclusion
Data engineering is a very important field that plays a VITAL role in helping out businesses, companies, startups, and organizations break down valuable insights from the data they have. By mastering the skills of data gathering, storage, and analysis skills, data engineers can solve real-world business challenges and drive business growth by an order of magnitude!! Whether you’re just starting in data engineering or looking to advance your career, it’s important to continuously learn and improve your skills to stay competitive in this rapidly evolving field. You can become a top-performing engineer and make a meaningful contribution to the world if you have the correct tools, resources, and right mindset.
FAQs
What is meant by data engineering?
Data engineering refers to the process of designing, building, and managing systems and infrastructure that enable the collection, storage, processing, and analysis of large and complex datasets, which involves tasks such as data ingestion, data transformation, data modeling, and data integration to ensure the availability of high-quality data for various business purposes.
What exactly does a data engineer do?
Data engineer is responsible for designing, building, and maintaining the systems and infrastructure required for storing, processing, and analyzing large and complex datasets. They work on data pipelines, data warehouses, and other data solutions to ensure data quality, reliability, and accessibility for data-driven decision-making.
How to become a good data engineer?
To become a good data engineer, it is important to have a strong foundation in computer science, programming, and data management.
Here are some steps to consider:
- Gain a solid understanding of databases, SQL, and data modeling.
- Learn programming languages commonly used in data engineering, such as Python or Java.
- Familiarize yourself with big data technologies, tools and frameworks.
- Gain hands-on experience with ETL processes, data pipelines, and data integration.
- Stay updated with industry trends and continuously learn new tools and technologies in the data engineering field.
What is ETL in data engineering?
ETL stands for Extract, Transform, Load. It is the process of extracting data from one or multiple sources, transforming it based on business logic or data warehouse design, and loading it into a target location, such as an OLAP system or a data warehouse.
What is the difference between OLTP and OLAP in data engineering?
OLTP (Online Transaction Processing) is designed for high-concurrency, data-intensive transactions, while OLAP (Online Analytical Processing) is optimized for fast querying and analysis of data. OLTP is used for transactional data, while OLAP is used for business intelligence and decision-making activities.
What are the options for batch and real-time processing in data engineering?
Batch processing involves persisting data as it comes in through events, while real-time processing involves persistently storing data as it comes in through events in real-time.
Why are businesses moving to the cloud for data engineering?
Moving to the cloud offers benefits like scalability, cost-efficiency, and ease of data storage and processing.
What is the Modern Data Stack?
Modern Data Stack is a collection of modern tools and technologies used in data engineering to address the challenges of migrating data to cloud warehouses and enable analytics and AI/ML applications.
What are some common challenges in the data engineering industry?
Common challenges in data engineering include complex data migration processes, managing large volumes of data, and staying up-to-date with rapidly evolving technologies. The development of the Modern Data Stack aims to address these challenges.
How can I excel in data engineering?
To excel in data engineering, continuous learning and skill improvement are essential. Stay updated with the latest tools, resources, and technologies in the field and develop a strong understanding of data gathering, storage, and analysis.
Will AI replace Data Engineering in the future?
While AI is still evolving and automating various aspects of data processing and analysis, it is very unlikely that AI will completely replace data engineering. Data engineering involves complex tasks such as data infrastructure design, data pipeline development, and ensuring data quality and reliability. While AI can assist in certain areas, data engineers play a critical role in designing and maintaining the systems that enable AI applications.
















