


























Second part of the Snowflake search optimization series is here! 🔥 This two-part series will guide you through everything you need about Snowflake search optimization. In the previous Part (Part 1), we discussed what Snowflake search optimization service is, how to implement it, the associated costs, strategies for cost management, factors affecting the cost, and a hands-on example of a performance comparison between Optimized vs. Non-Optimized Tables.
In this article (part 2), we have much to cover; we will dive into the benefits of Snowflake search optimization, the types of queries that can benefit from it, the difference between Snowflake Clustering vs Search Optimization Service—and a lot more!!
Let's get started!
What is Snowflake Clustering?
Before we dive into when to use Snowflake clustering, let's first understand what Snowflake clustering is.
Snowflake clustering is a performance optimization technique where related rows of table data are automatically co-located together within the same Snowflake micro-partitions. By organizing rows that are frequently accessed together into the same micro-partitions, Snowflake can avoid scanning irrelevant data during queries.
Clustering works by continuously reorganizing table data in the background based on the clustering key(s) defined on a table. The Snowflake query optimizer leverages metadata about the distribution of values across micro-partitions to precisely prune and only access partitions that contain relevant rows for each query.
This automatic co-location of related rows improves query performance by minimizing the number of micro-partitions and volume of data that need to be scanned. Scanning less data allows queries to execute faster with lower compute resource requirements.
Here are some key things to know about Snowflake clustering:
- The syntax is straightforward:
ALTER TABLE table_name CLUSTER BY column_name;- Can cluster on one column or multiple columns together
- Clustering happens automatically in the background
- The main benefit is improving range query performance
- Helps minimize scanned micro-partitions for range filters
- Adds additional compute cost for the clustering operations
- Most useful for large tables with many micro-partitions
To learn exactly when to use Snowflake clustering, check out this article and understand more in-depth. We have broken down everything you need to know about Snowflake clustering.
Difference between Snowflake Clustering vs Search Optimization Service?
For users who are seeking lightning-fast query speeds on massive datasets, Snowflake offers these two powerful performance enhancers. While both utilize Snowflake's micro-partition architecture under the hood, they take different approaches to slicing and dicing data for blazing queries. Clustering works by automatically co-locating related data within micro-partitions to minimize scanning. Search optimization generates metadata about value ranges in micro-partitions to precisely prune scanning at query time.
Here of key differences between Snowflake clustering vs search optimization services:
Snowflake Clustering:
- Automatically groups related rows of table data together within Snowflake micro-partitions.
- Organizes data based on clustering key(s) defined on the table (one or more columns).
- Improves query performance by co-locating related data to minimize scanned partitions.
- Works continuously in the background to re-organize table data as it changes.
- Only one clustering key can be defined on a table.
- Mainly optimizes equality, range predicates, and sort operations.
Snowflake Search Optimization Service:
- Creates search access path metadata to enable pruning of micro-partitions.
- Tracks value ranges for columns in each micro-partition.
- Allows skipping irrelevant partitions and columns during queries.
- Can be configured on a per-column basis using ALTER TABLE commands.
- Optimizes very selective point lookups and analytic queries.
- Improves performance for equality, IN, substring, regular expression, VARIANT, and geospatial queries.
- Incurs storage costs for search access paths and compute costs for maintaining them.
- Provides finer-grained control over optimized columns than clustering.
When to Use Snowflake Search Optimization Service?
Snowflake's Search Optimization Service (SOS) is an automated background process available in Enterprise Edition that pre-computes and stores optimized metadata to enable fast lookups and queries on large tables. SOS scans table micro-partitions to record distinct values for each column and creates an access path used by the optimizer to construct performant point query access plans that retrieve a small subset of rows.
Check out this article to learn more in-depth about Snowflake Search Optimization Service.
What are the types of Queries that can benefit from Snowflake search optimization?
Snowflake search optimization can improve the performance of these kinds of queries:
1) Equality(“=”) or “IN” Predicates
Queries that use equality or IN predicates on columns with high cardinality can benefit from Snowflake Snowflake search optimization.
You can enable Snowflake search Snowflake search optimization service for all columns of a table that support lookup queries using the "=" or "IN" clauses.
To enable a Snowflake search Snowflake search optimization service for a table, you can use the following command:
ALTER TABLE table_name ADD SEARCH OPTIMIZATION;This above ALTER TABLE command with the ADD SEARCH OPTIMIZATION clause will enable Snowflake search optimization service for a table.
Now, to check the list of columns for which Snowflake search optimization service is enabled, we can use the following command to do so:
DESCRIBE SEARCH OPTIMIZATION ON table_name;2) Substrings and Regular Expressions
To enable Substring search optimization service for a particular column, we can use the following command:
ALTER TABLE table_name ADD SEARCH OPTIMIZATION ON SUBSTRING(column_name);To enable Substring search optimization service for all columns in a table that support substring and regular expression predicates, we can use the following command:
ALTER TABLE table_name ADD SEARCH OPTIMIZATION ON SUBSTRING(*);Make sure to check out the list of supported Substrings and Regular Expressions predicates.
To check the list of columns for which Substring search optimization service is enabled, we can use the same command as for Equality or IN Predicates:
DESCRIBE SEARCH OPTIMIZATION ON table_name;3) Fields in VARIANT Columns
To improve the performance of point lookup queries on semi-structured data stored in Snowflake tables (i.e., data in VARIANT, OBJECT, and ARRAY columns), we can enable search optimization service for a matching data type column in a table.
To enable search optimization service for a variant, array, object data type column in a table, we can use the following command:
ALTER TABLE table_name ADD SEARCH OPTIMIZATION ON EQUALITY(column_name);To check the list of columns for which VARIANT search optimization service is enabled, we can use the same command as for Equality or IN Predicates:
DESCRIBE SEARCH OPTIMIZATION ON table_name;Check out the following link for additional information on:
4) Geospatial Functions
To enable GEO search optimization service for a particular column, we can use the following command:
ALTER TABLE table_name ADD SEARCH OPTIMIZATION ON GEO(column_name);To enable GEO search optimization service for all columns in a table, we can use the following command:
ALTER TABLE table_name ADD SEARCH OPTIMIZATION ON GEO(*);Check out the list of supported predicates with geospatial functions.
5) Conjunctions of Supported Predicates (AND)
To optimize search performance for queries that use conjunctions of predicates (i.e., AND), any predicate that returns only a few rows can benefit from search optimization.
For example, consider a query that contains:
where condition_x or condition_y
If either condition returns only a few rows (i.e., condition_x or condition_y), search optimization can enhance the query performance.
Furthermore, if condition_x returns a small number of rows but condition_y returns many rows, search optimization can still benefit the query performance.
To enable search optimization for conjunctions of supported predicates (AND), the query must contain multiple conditions joined by the AND operator. For example,
SELECT id, name, address FROM customers WHERE name='Pramit AND address='123'6) Disjunctions of Supported Predicates (OR)
Consider a query that contains:
where condition_x or condition_y
If each condition returns only a few rows (i.e., condition_x and condition_y), search optimization can enhance the query performance.
However, if condition_x returns only a few rows but condition_y returns many rows, search optimization does not improve the query performance.
In the case of disjunctions, each predicate alone is not sufficient to determine the query's outcome. The other predicates must be evaluated to determine if search optimization can enhance performance.
To enable search optimization for disjunctions of supported predicates (OR), the query must contain multiple conditions joined by the OR operator. For example:
SELECT id, name, address FROM customers WHERE name='Pramit OR address='123'Check out this official Snowflake documentation to learn everything you need to know about search optimization service.
Practical Example—Snowflake Clustering vs Search Optimization Service
The example below shows the differences between Snowflake search optimization service and Snowflake clustering. Let’s first create a table with 100 million customer records from SNOWFLAKE_SAMPLE_DATA.TPCDS_SF100TCL.CUSTOMER
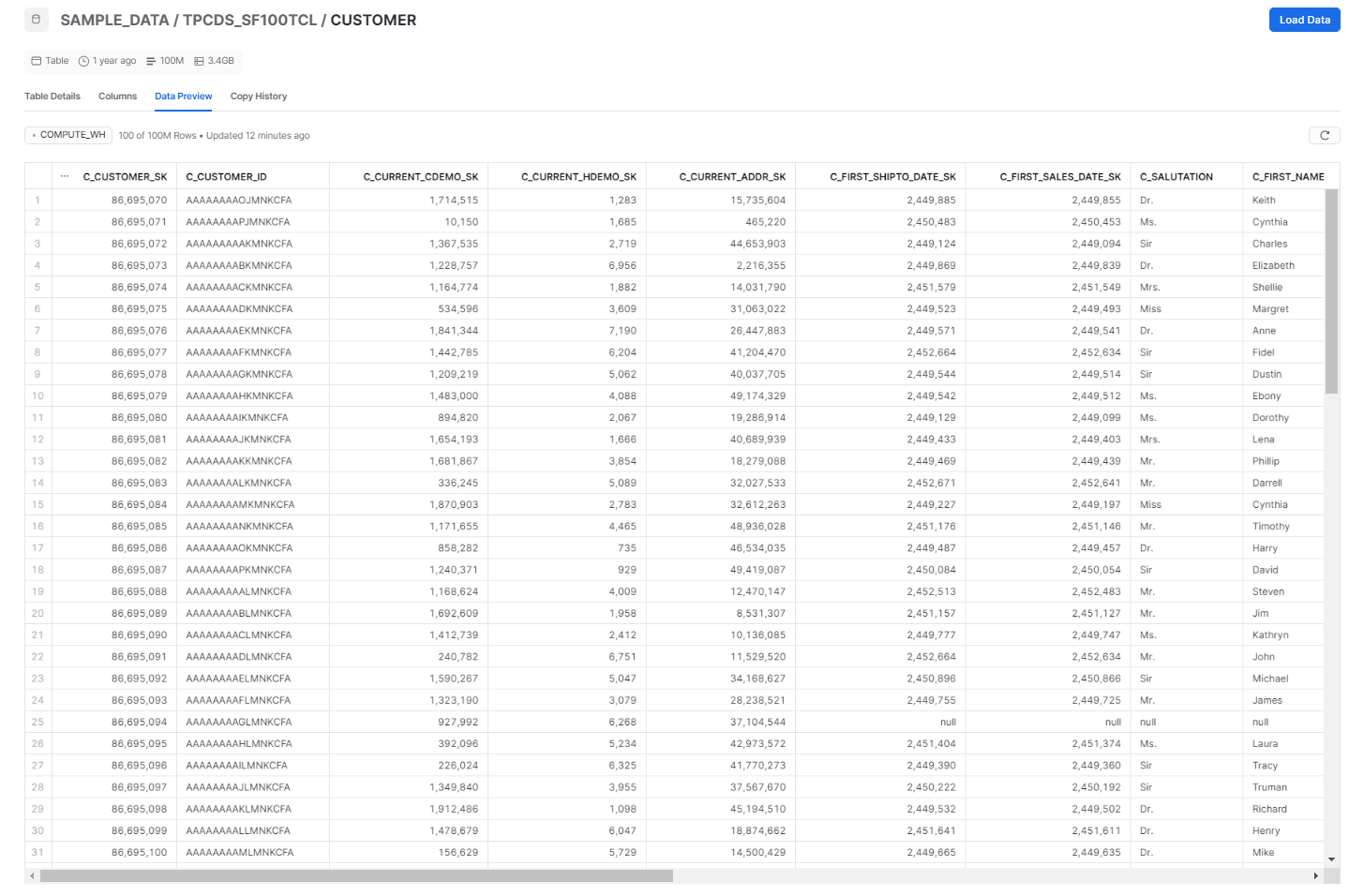
Step 1—Create a Customer Table
We will start by creating a large table called CUSTOMER in our database using the Snowflake sample TPCDS data. This table will contain 100 million rows of customer data:
create table CUSTOMER as select * from SAMPLE_DATA.TPCDS_SF100TCL.CUSTOMER;
Step 2—Clone Table for Clustering and Search Optimization
Next, we will make two copies of the CUSTOMER table so we can apply clustering and search optimization separately:
create table customer_SOS clone CUSTOMER;
create table customer_clustered clone customer;
Step 3—Enable Clustering and Search Optimization
On customer_clustered, we will enable clustering on the c_birth_year column. This will physically reorder the rows based on birth year values:
ALTER TABLE customer_clustered CLUSTER BY (c_birth_year);
On customer_sos we will enable search optimization, which scans and indexes metadata for fast equality searches:
ALTER TABLE customer_SOS ADD search OPTIMIZATION;
Step 4—Verify Completion of Background Processes
We can verify that the clustering and search optimization have been completed by the background processes by querying the table information:
show tables like '%customer_SOS%';
show tables like '%customer_clustered%';
Step 5—Verify clustering is complete.
To check weather clustering is complete, you need to fire the command mentioned below:
select system$clustering_information('customer','(C_CUSTOMER_ID)');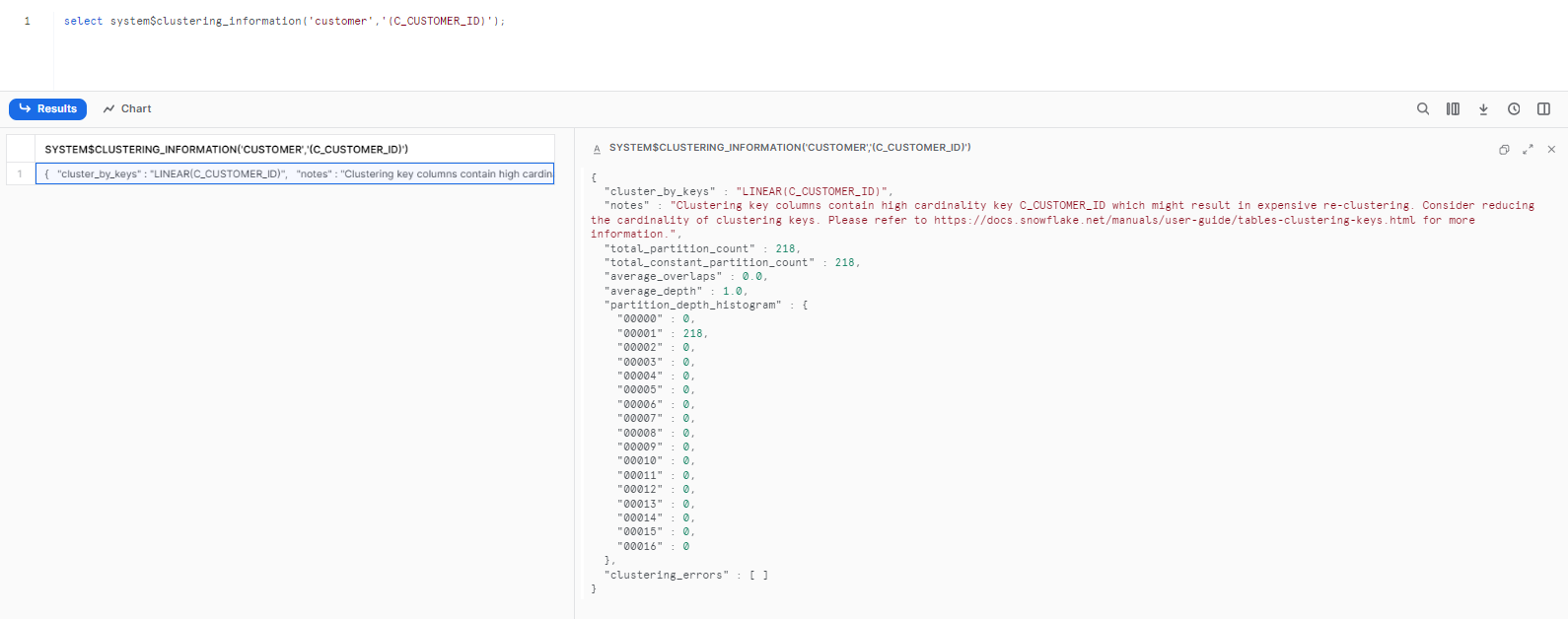
select system$clustering_information('customer_clustered','C_CUSTOMER_ID');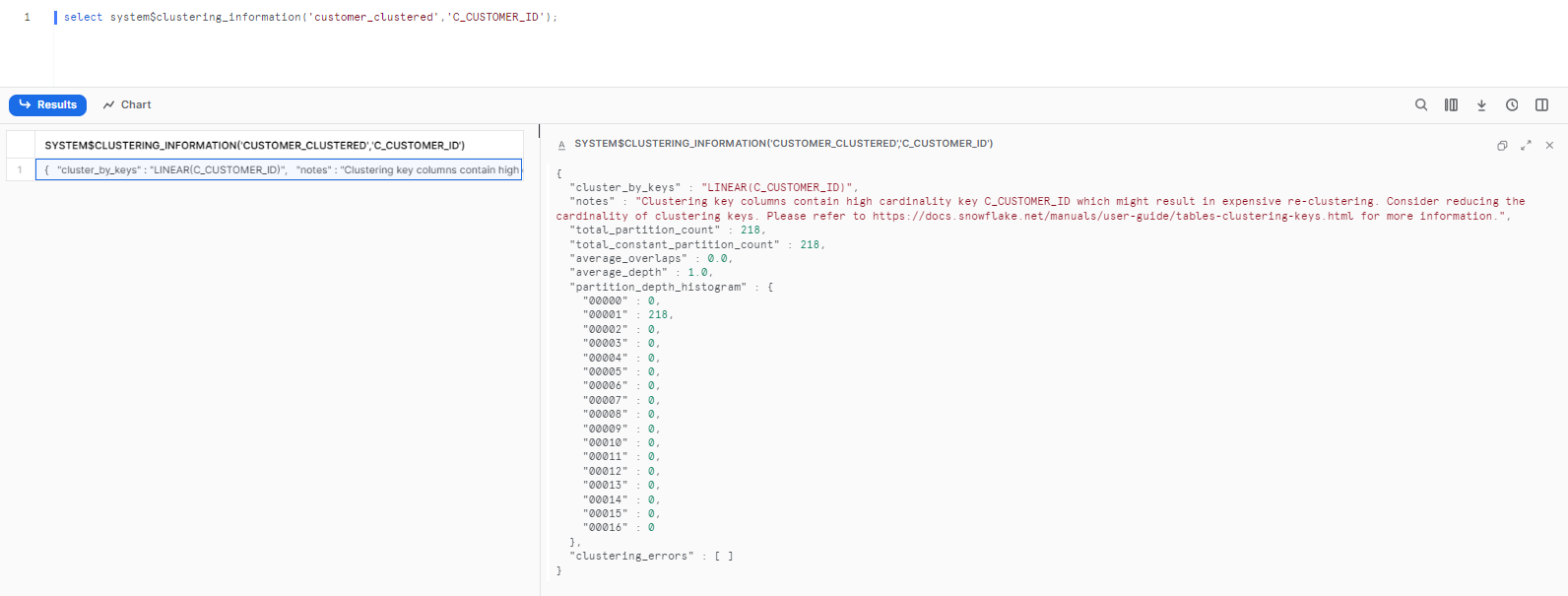
Step 6—Now, run queries to demonstrate the differences
We will now run a simple point query filtering on c_birth_year on each table:
select * from CUSTOMER where c_birth_year='1972';
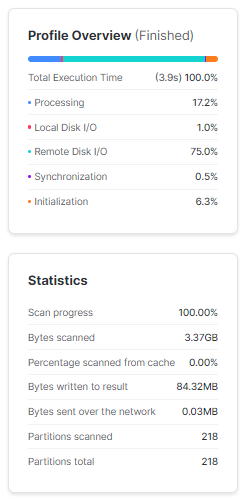
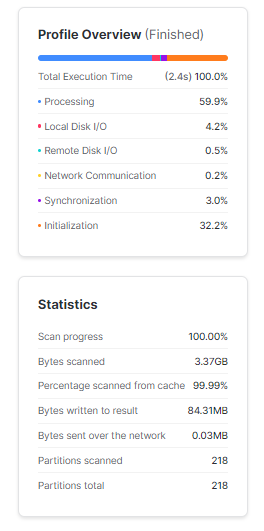
As you can see, the query profile above shows that the query profiler had to scan all the micro partitions to get the required result in ~3.9 seconds.
Now, as if you fire the same query on the clustered customer_clustered table takes ~2.4 seconds—improved because it filters on the clustered column:
select * from customer_clustered where c_birth_year='1972';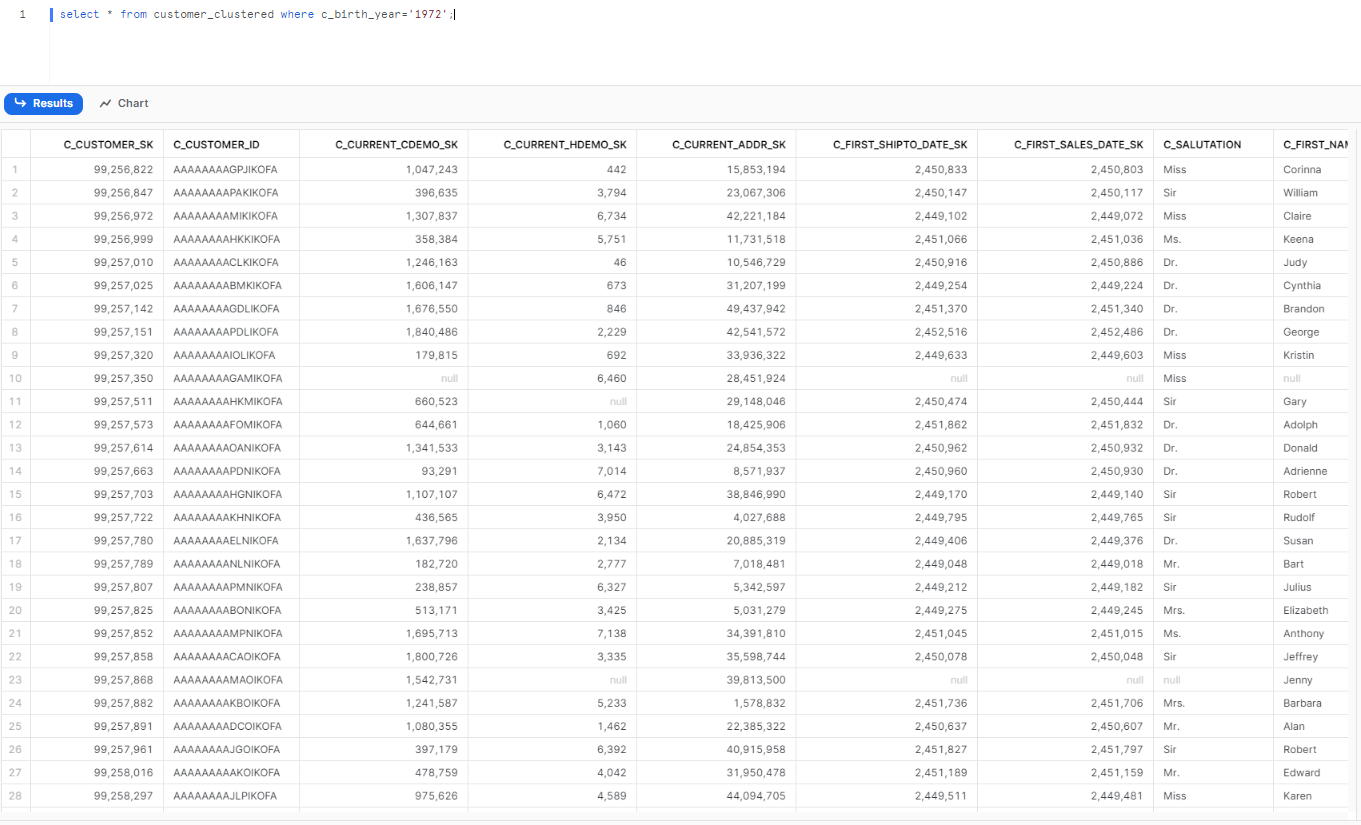
When we modify the query on the clustered table to filter on the c_birth_year cluster key in addition to c_customer_id, the Snowflake query optimizer is able to utilize the sorted data from clustering to dramatically improve performance. Rather than scanning all micro-partitions, it only needs to scan the specific micro-partitions that contain the relevant values for c_birth_year, as the table has been physically sorted by that column. This allows the query engine to prune partitions effectively and reduce the amount of data scanned. As a result of scanning less data, the runtime is reduced significantly compared to the unclustered table.
select * from customer_clustered where c_birth_year between '1900' and '2023' and c_customer_id='AAAAAAAAKMNKCFCA';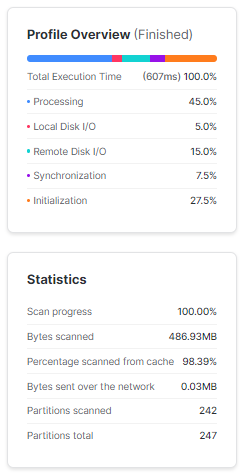
Step 7—Finally…
While clustering can provide performance improvements for queries that filter on the clustered columns, it does not accelerate point lookups or equality searches that filter on non-clustered columns.
Finally, when we executed the exact same point lookup query on the customer_SOS table with search optimization enabled, we observed a dramatic improvement in performance.
select * from customer_SOS where c_customer_id='AAAAAAAAKMNKCFCA';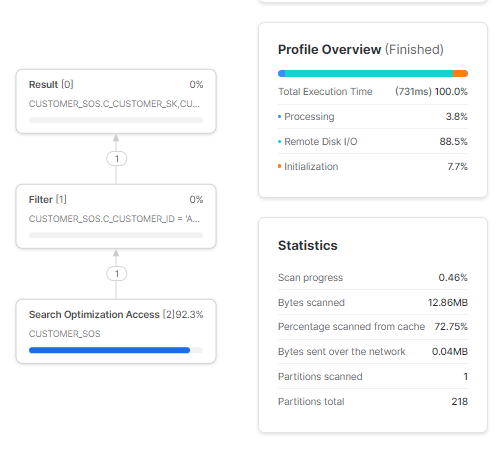
As you can see, Snowflake search optimization service pre-computed and stored optimized metadata and access paths for fast equality lookups on every column in the table. This allowed the Snowflake query engine to precisely pinpoint only the rows needed based on c_customer_id without scanning any irrelevant data.
As a result, response times were reduced from seconds on the other tables down to sub-seconds on the search-optimized table. The profiler execution plans clearly showed the search optimization metadata being leveraged for accelerated access.
Conclusion
Snowflake clustering vs search optimization provides complementary performance enhancements that can be combined for greater query speedups. Clustering co-locates related data to minimize scanned partitions for range predicates and sorting, whereas the search optimization service generates metadata for optimizing highly selective point lookups and equality searches. While clustering physically reorganizes table data, search optimization creates virtual access paths.
In the first part of this two-part article on Snowflake search optimization, we delved into the service's practical applications and step-by-step implementation. In this follow-up (Part 2), we examine the finer details of Snowflake search optimization and the differences between Snowflake Search optimization service and clustering. Here's a recap of the key topics we covered:
- What is Snowflake clustering and when to use it?
- What is Snowflake Search optimization service and when to use it?
- Differences between Snowflake Clustering vs Search Optimization Service
- Practical Example—Snowflake Clustering vs Search Optimization Service
FAQs
What is Snowflake clustering?
Snowflake clustering automatically groups related rows of table data together within the same micro-partitions. It continuously reorganizes data in the background based on a defined clustering key to improve range query performance.
How does Snowflake clustering work?
Clustering in Snowflake works by leveraging metadata about the distribution of values across micro-partitions to only access and scan partitions containing relevant values for range-based queries. This minimizes scanned data.
What queries can benefit from Snowflake clustering?
Queries with range filters, equality predicates, and sorting operations on the clustered column(s) see performance gains from Snowflake clustering. It improves data locality for these types of access patterns.
Can I cluster a Snowflake table on multiple columns?
Yes, Snowflake clustering allows defining a compound clustering key made up of one or more columns.
What is the Snowflake search optimization service?
Snowflake search optimization service creates and maintains metadata about value distributions across micro-partitions. This enables optimized pruning for lightning-fast point lookups and analytic queries.
How do I enable Snowflake search optimization for a table?
Use the command: ALTER TABLE table_name ADD SEARCH OPTIMIZATION.
How can I check which columns have search optimization enabled?
Use the command: DESCRIBE SEARCH OPTIMIZATION ON table_name.
What are the disadvantages of Snowflake Search Optimization?
Snowflake Search Optimization may not provide significant benefits for queries that return a large number of rows or have less selective filters.
How does the Snowflake search optimization service work?
It scans table data to build persistent search access paths that track value ranges and distinct values per column in each micro-partition. These are used at query runtime to skip scanning irrelevant data.
Can search optimization improve query performance on all types of queries?
No, search optimization is specifically designed to improve performance on selective point lookup queries and may not affect other types of queries
Does the search optimization service physically reorganize data like clustering?
No, search optimization is a virtual metadata layer that enables pruning. It does not reorganize the physical data placement like clustering does.
Is it possible to use both clustering and search optimization in Snowflake?
Yes, it is possible to use both, but they serve different purposes and are optimized for different types of queries within Snowflake
Will enabling both Auto Clustering and Search Optimization consume more credits?
Yes, tables with both Auto Clustering and Search Optimization enabled will consume more credits.
Does enabling search optimization incur additional costs?
Yes, the search optimization service requires added storage for metadata and computing for background maintenance. The costs scale based on usage, so thoughtful configuration is recommended.
How can search optimization costs be managed?
Carefully selecting tables for optimization, monitoring usage, and batching DML can help manage search optimization costs.
Does search optimization improve join performance?
Directly no, but it can accelerate filter predicates applied before joins, improving overall join query performance.
Can search optimization handle data with frequent changes?
Yes, the service automatically maintains metadata as data changes, but high update volumes increase compute costs. Clustering may be better for rapidly changing data.
Does clustering reorganize a copy of the table?
No, clustering directly reorganizes the base table data in place based on the defined clustering key.
Can search optimization be used on external tables?
No, search optimization only works on native Snowflake tables, not external tables.
Do I need a separate warehouse for search optimization?
No dedicated warehouse is required. The service runs fully managed in the background without user warehouse management.
How do I decide whether to use clustering or search optimization in Snowflake?
It depends. Clustering is recommended for large tables with queries on specific keys, while search optimization is beneficial for tables with frequent point lookup queries.









