



























Feeling overwhelmed trying to pick the perfect storage format for your open data lakehouse? You're not alone! With great options like Delta Lake, Apache Iceberg, and Apache Hudi, each offering its unique set of features and capabilities, it can be hard to decide. These storage formats are great for data democratization and interoperability—definitely better than getting trapped in a proprietary format. But choosing just one can be tough. Luckily, there's Delta UniForm (short for Delta Lake Universal Format)! It is designed to help you maintain a single copy of your data while simultaneously supporting multiple connector ecosystems, eliminating the need for costly and complex data migrations.
In this article, we will cover everything you need to know about Delta UniForm. And then, we'll discuss the benefits it brings to the table and a step-by-step guide through the process of integrating it into your existing Delta Table.
Before we jump into the depth of understanding what Delta Uniform is, let's first understand what Delta Lake, Apache Iceberg, and Hudi are, along with the features they provide, in brief detail.
What is Delta Lake?
Databricks Delta Lake is an open source storage layer that brings ACID transactions, data versioning, schema enforcement, and efficient handling of batch and streaming data to data lakes. Developed by Databricks and now a project under the Linux Foundation, Delta Lake brings the reliability and performance of data warehouses to data lakes, enabling organizations to unlock the full potential of their data.
Delta Lake Architecture
The Delta Lake architecture consists of three core components:
- Delta Tables: Delta tables store data in a columnar Parquet format, organized into files in the Cloud Object Storage Layer. This columnar format enables lightning-fast querying for large-scale data analysis. Delta tables are transactional, meaning every change is recorded in the Delta Log in chronological order, ensuring data consistency even as schemas evolve over time.
- Delta Log: The Delta Log is a digital ledger that meticulously records every change made to Delta tables, such as additions, deletions, and updates. It guarantees data integrity and enables easy rollbacks if any issues arise. The Delta Log also tracks the locations of the Parquet files in the Cloud Object Storage Layer.
- Cloud Object Storage Layer: This layer is responsible for durably storing the Parquet files containing the actual data in Delta tables. It is compatible with various object storage systems, such as HDFS, S3, or Azure Data Lake, ensuring scalability and eliminating the need to manage complex infrastructure.
Delta Lake Operations
During write operations, data is first written to the Cloud Object Storage Layer as Parquet files representing the changes. References to these files are then added to the Delta Log. During read operations, Delta Lake consults the Delta Log to identify the relevant Parquet files and retrieve the requested data.
Delta Lake efficiently handles concurrent writes and compaction for better performance. Compaction periodically merges smaller Parquet files into larger ones, reducing metadata overhead and improving query performance.
See Databricks Delta Lake 101 guide for more information.
What is Apache Iceberg?
Apache Iceberg is an open source, high-performance table format designed for large-scale data analytics in data lake environments. It was developed to address the limitations of traditional table formats like Apache Hive when working with big data.
Iceberg provides a number of features that make it well-suited for use in data lakes and other large-scale data analytics applications. Here are some key features of Apache Iceberg:
- ACID Transactions: Apache Iceberg supports atomic, consistent, isolated, and durable (ACID) transactions, which ensures that data remains accurate and consistent even when multiple users are accessing and modifying it simultaneously.
- Schema Evolution: Apache Iceberg allows users to easily modify the schema of a table, even after data has been written to it, making it easy to adapt to changing data requirements over time.
- Partitioning: Iceberg supports partitioning of tables, which can improve query performance by allowing users to scan only the parts of the table that are relevant to their query.
- Time Travel: Iceberg allows users to query historical snapshots of a table, which can be useful for debugging and auditing purposes.
- Fast Query Performance: Iceberg is designed to provide fast query performance, particularly for large-scale data analytics workloads.
- Support for Multiple Engines: Iceberg is compatible with a variety of data processing engines, including Apache Spark, Trino, and Apache Flink.
- Metadata Management: Iceberg provides a centralized metadata store that makes it easy to manage large-scale data lakes.
What is Apache Hudi?
Apache Hudi (Hadoop Upserts and Incremental Data) is an open source data management framework designed to simplify incremental data processing and data pipeline development. Originally developed by Uber, Hudi is now an Apache Software Foundation project. Its primary goal is to bring database-like capabilities to data lakes, making it easier for organizations to manage and analyze large datasets in a more performant, scalable, and reliable manner.
Key features of Apache Hudi are:
- Upsert Support: Hudi allows you to perform updates, inserts, and deletes on data stored in a data lake.
- Fast Indexing: Hudi provides fast indexing capabilities, which makes it easier to search and retrieve data from a data lake.
- Atomic Publishing with Rollback: Hudi provides atomic publishing capabilities, which ensures that updates are either committed or rolled back as a single unit of work.
- Snapshot Isolation: Hudi provides snapshot isolation between writers and readers, which ensures that readers always see a consistent view of the data.
- Savepoints for Data Recovery: Hudi allows you to create savepoints, which makes it easier to recover data in the event of a failure.
- Async Compaction of Row and Columnar Data: Hudi provides asynchronous compaction capabilities, which helps to optimize the storage and retrieval of data in a data lake.
- Timeline Metadata to Track Lineage: Hudi provides timeline metadata, which helps to track the lineage of data over time.
- Clustering: Hudi provides clustering capabilities, which helps to optimize the layout of data in a data lake.
Now, as you can see, each of these table formats has its own unique strengths and features, offering distinct advantages in different scenarios. However, selecting the ideal format for an open data lakehouse can pose challenges, such as vendor lock-in and complex benchmarking. So the question is, is there a more effective approach to addressing these challenges? Yes, Delta UniForm aims to address this issue.
What is Delta UniForm?
The vision of an open data lakehouse involves unification (eliminating data silos), scalability (growing without refactoring), and openness (freedom to use any tool).
But, when attempting to build an open data lakehouse, users might face a dilemma: which table format should they choose? Should they go with Apache Hudi, Apache Iceberg, or Delta Lake? This decision often leads to lengthy benchmarking processes and feature comparisons, which can be an inefficient approach. This is where Delta UniForm comes into play! Delta UniForm aims to provide a universal format for Delta Lake, enabling users to leverage the advantages of the Iceberg and Hudi ecosystems while using Delta Lake.

At their very core, Delta Lake, Apache Iceberg, and Apache Hudi all implement multi-version concurrency control through a metadata layer. This metadata layer points to the underlying Parquet files containing the actual data and stores statistics for optimized query processing.
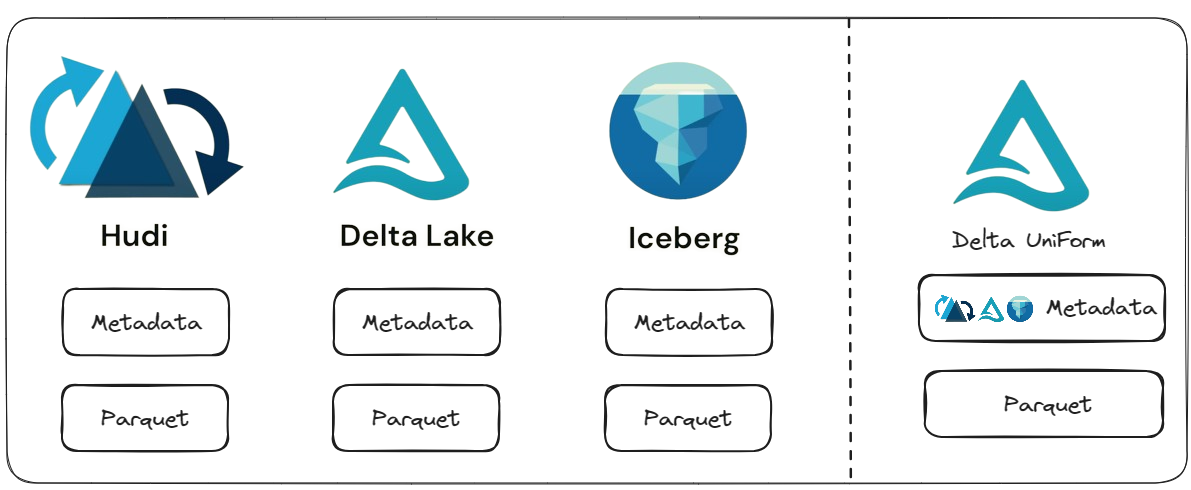
BUT, the main challenge lies in the fragmented ecosystem, where each format has varying levels of support across different data platforms and engines. For example, Delta Lake has support for Azure Synapse and Microsoft Fabric, while Apache Iceberg is supported by Google BigQuery and Snowflake.
Delta UniForm solves this fragmentation by enabling seamless interoperability. Whenever you write data to a Delta table, Delta UniForm will incrementally generate this layer of metadata to spec for Apache Hudi, Iceberg and Delta. This means that any Delta table you create can be easily read by any tool or engine that supports the Iceberg, Hudi and Delta ecosystem, without being locked into a specific vendor or platform.
Features and Benefits of Delta UniForm
Delta UniForm offers a myriad of benefits that empower organizations to unlock the full potential of their data while embracing the open data lakehouse architecture:
- Access data as Hudi or Iceberg: Delta UniForm allows accessing the same data as either Hudi or Iceberg format from any Hudi or Iceberg reader.
- Single copy of data: Delta UniForm eliminates the need for redundant data storage, allowing organizations to maintain a single copy of their data in the lakehouse. This approach not only optimizes storage costs but also simplifies data management, reducing the complexity associated with maintaining multiple data silos.
- Set and forget: Delta UniForm is set up once on a table, and then it operates automatically, without requiring any further action.
- Automated process: The process of writing data in multiple formats (Delta, Iceberg, and eventually Hudi) is completely automated.
- No additional cost: Delta UniForm seamlessly generates the necessary metadata for Iceberg and Hudi without incurring any additional costs.
- Open source: Delta UniForm is an open-source solution.
- Available in Delta 3.0: Delta UniForm is available in the preview version of Delta 3.0, announced recently.
- Unity Catalog support (for Databricks): If using Databricks, Delta UniForm has support for the Unity Catalog.
- Iceberg REST API implementation: Delta UniForm implements the Iceberg REST API, which is the preferred way for the Iceberg community to read the Iceberg format. This API is implemented in the Unity Catalog.
Performance and Scalability of Delta UniForm
One of the key strengths of Delta UniForm lies in its exceptional performance and scalability. Delta UniForm has been designed to have negligible performance and resource overhead, ensuring optimal utilization of computational resources. Even for petabyte-scale tables, the metadata generated by Delta UniForm is typically a tiny fraction of the actual data file size. This minimalistic metadata footprint ensures that Delta UniForm does not introduce any significant overhead or impact on overall system performance.
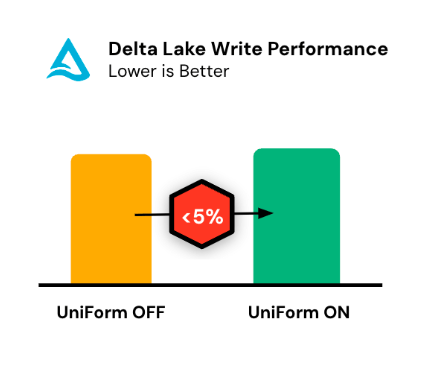
Delta UniForm is capable of incrementally generating metadata. This approach further contributes to the high performance and scalability of Delta UniForm, as it avoids redundant processing and minimizes the computational resources required for metadata generation, especially in scenarios where only a small portion of the data has changed.
Step-by-Step Guide to Create a New Delta Table with Delta UniForm
To leverage the power of Delta UniForm and create a new Delta table with multi-format support, follow these steps:
Prerequisites
- Delta Lake version 3.0.0 or later: The Delta UniForm feature is available in Delta Lake 3.0.0 and later versions. Ensure that you have the latest version of Delta Lake installed on your Spark environment.
- Databricks Runtime 14.3 LTS or higher: If you're using Databricks, you'll need a runtime version of 14.3 or higher, as Delta UniForm is currently in preview on Unity Catalog tables.
- Table registered in Unity Catalog: To use UniForm with Databricks, your table should be registered in the Unity Catalog.
- Delta table must have a
minReaderVersion >= 2andminWriterVersion >= 7
Step 1—Creating a New Catalog
The first step in creating a new Delta table with Delta UniForm is to create a new catalog in Unity Catalog. This catalog will serve as a centralized repository for your data assets, enabling seamless governance and access control. Run the following SQL command to create a new catalog:
CREATE CATALOG IF NOT EXISTS catalog_name;See Databricks Unity Catalog 101
Step 2—Selecting and Granting Permissions on the Catalog
Once the catalog is created, you'll need to grant the appropriate permissions to ensure secure and controlled access to your data assets. This step is crucial for maintaining data governance and compliance within your organization.
CREATE SCHEMA my_schema;See Databricks Unity Catalog 101.
Step 3—Creating and Managing Schemas
Within the newly created catalog, you can organize your data assets into schemas. Schemas provide a logical grouping of related tables, enabling better organization and easier navigation of your data assets.
See Databricks Unity Catalog 101.
Step 4—Creating a New Delta Table with Delta UniForm
Now that you have a catalog and a schema set up, you can create a new Delta table with the Delta UniForm feature enabled. To do so, you need specific table properties that instruct Delta Lake to generate the necessary metadata for Iceberg and Hudi (coming soon).
The two key table properties to enable Delta UniForm are:
delta.universalFormat.enabledFormats: This property specifies the table formats for which UniForm should generate metadata. In this case, we're enabling it for the Iceberg format.delta.enableIcebergCompatV2: This property is an optional setting that enables the Iceberg compatibility mode V2. If you set this property to true, Delta Lake will generate Iceberg metadata using the latest V2 format, which is more efficient and provides better performance compared to the V1 format.
Here's an example SQL statement to create a new Delta table with Delta UniForm enabled for Iceberg:
CREATE TABLE students (
Name STRING,
Age INT
)
TBLPROPERTIES (
'delta.universalFormat.enabledFormats' = 'iceberg',
'delta.enableIcebergCompatV2' = 'true'
);
Step 5—Inserting Data into the Table
After creating the Delta table with UniForm enabled, you can insert data into the table using standard SQL INSERT statements. Here's an example:
INSERT INTO my_table
VALUES ('Elon musk', 35), ('Jeff bezos', 42), ('Mark Zuck', 27);
Step 6—Verifying Table Properties
After creating the Delta table and inserting data, it's essential to verify that the table properties are correctly set and that Delta UniForm is enabled. You can verify the table properties by running the following SQL command:
%sql
SHOW TBLPROPERTIES students;
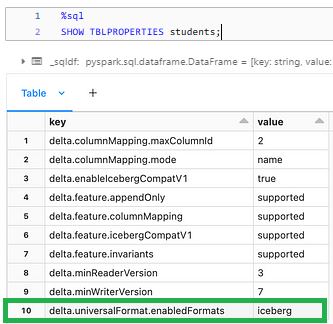
This command will display detailed information about the table, including the set table properties. You should see the delta.universalFormat.enabledFormats property listed with the value 'iceberg'.
Step 7—Explore the Directory Structure
Delta Lake stores its data and metadata in a specific directory structure. With Delta UniForm enabled, you'll see additional directories and files related to the Iceberg format. You can explore the directory structure using the Databricks user interface or by running shell commands on the underlying file system.
First—you need to identify the location of the Delta table on the underlying file system. In Databricks, you can find the table location by running the following SQL command:
DESCRIBE TABLE EXTENDED students;This command will display detailed information about the table, including the location of the table files on the file system. The location will typically be a path in the format dbfs:/path/to/table/.
Once you have the table location, you can use the magic command %fs command in a Databricks notebook to navigate and list the contents of the directory. Here's an example:
%fs ls </path/to/table/>Replace </path/to/table/> with the actual location of your table.
This command will list the contents of the table directory, including the _delta_log directory for Delta metadata and the metadata directory for Iceberg metadata.
To explore the Iceberg metadata directory further, you can use the following command:
%fs ls </path/to/table/metadata/>This will list the contents of the metadata directory.
If you want to view the contents of a specific file, you can use the head or cat command:
%fs head </path/to/table/metadata/<version-number>-<uuid>.metadata.json>Replace </path/to/table/metadata/<version-number>-<uuid>.metadata.json> with the actual name of the file you want to view.
OR
There's another way to find the metadata path for your Delta UniForm table. Simply go to the Databricks Data Explorer, locate your table, and click on the “Details” tab. Once you're there, look for the “Delta UniForm Iceberg” row, which will show you the path to the metadata.
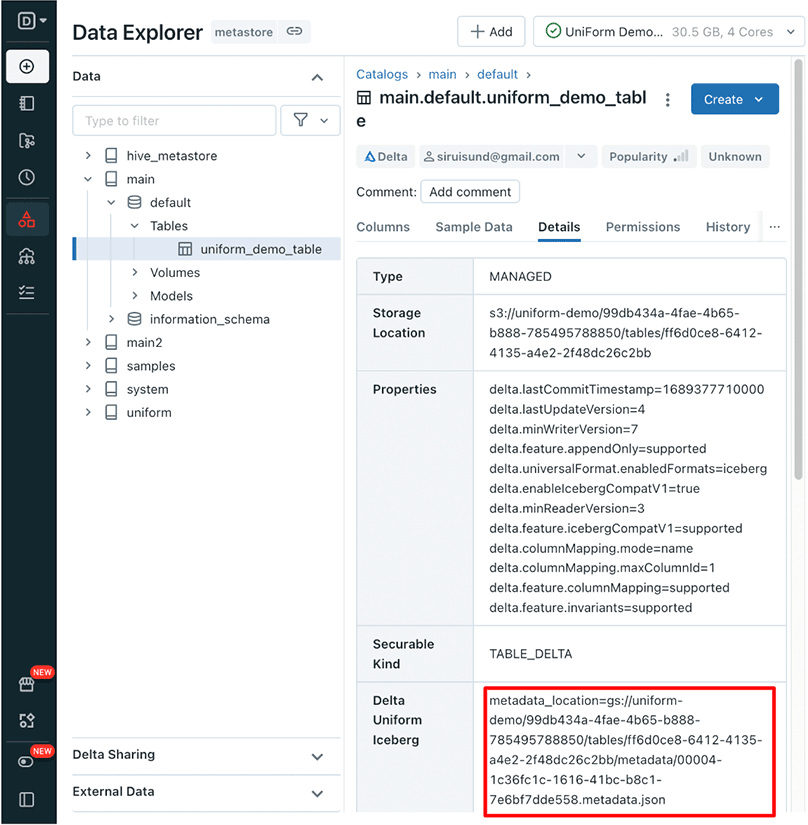
If you follow these steps carefully, you can gain insights into how Delta Lake organizes its data and metadata, and how the Iceberg metadata is generated and stored when Delta UniForm is enabled.
Optional—Converting an Existing Delta Table to Delta UniForm
If you have an existing Delta table that you want to convert to support UniForm, you can do so by altering the table properties. Here's an example SQL command:
ALTER TABLE new_students
SET TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.minReaderVersion' = '2',
'delta.minWriterVersion' = '5',
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
);This command sets the necessary table properties to enable UniForm compatibility with the Iceberg format for the existing new_students table.
Check out these blogs, videos, and documentation to learn more in-depth about Delta UniForms:
- Delta Lake (Delta UniForm) documentation
- Universal Format (UniForm) for Iceberg compatibility with Delta tables
- Introducing Universal Format: Iceberg and Hudi Support in Delta Lake
- Delta UniForm: a universal format for lakehouse interoperability
Limitations and Drawback of Delta UniForm
Although Delta UniForm has some great perks, let's not ignore the other side of the coin. Like any tool, it has its drawbacks, and being aware of them helps you make informed decisions. Here are some limitations you might want to keep in mind:
- Delta UniForm does not work on tables with deletion vectors enabled, which can be a problem for some use cases.
- Delta tables with UniForm enabled do not support VOID types, which can limit the flexibility of your data models.
- Iceberg clients can only read from UniForm, so writes are not supported, which can be a major limitation for some applications.
- Iceberg reader clients might have individual limitations, regardless of UniForm, so it's important to test your specific use case to ensure compatibility.
Delta UniForm brings a number of benefits, yet understanding its limitations is crucial when considering its integration in your data lakehouse architecture.
Conclusion
And that's a wrap! Delta Universal Format (UniForm) is an extremely valuable feature that automatically unifies table formats, without creating additional copies of data or more data silos. No matter if you're using Iceberg, Hudi, or Delta, you can access the data you need without any extra effort. It's like having a universal translator for data formats, which saves time and hassle. And when it comes to data management, that's a huge win! This means users/organizations can stay flexible and adapt to changes in the data world more easily, without worrying about being locked into one specific format.
In this article, we have covered:
- What is Delta Lake?
- What is the Apache iceberg?
- What is Apache Hudi?
- What is Delta UniForm?
- Features and benefits of Delta UniForm
- Performance and scalability of Delta UniForm
- Step-by-step guide to create a new Delta Table with Delta UniForm
…and so much more!
FAQs
What is Delta Lake?
Delta Lake is an open source storage layer that brings ACID transactions, data versioning, schema enforcement, and efficient handling of batch and streaming data to data lakes.
What is Apache Iceberg and what are its key features?
Apache Iceberg is an open source, high-performance table format with features like hidden partitioning, time travel, ACID transactions, and schema evolution.
What is Apache Hudi and what are its key capabilities?
Apache Hudi is an open source data management framework enabling incremental processing, ACID transactions, schema evolution, and time travel for data lakes.
What is the vision of an open data lakehouse?
An open data lakehouse vision revolves around unification, scalability, and openness - eliminating data silos, scaling without refactoring, and freedom to use any tool.
What is Delta UniForm?
Delta UniForm is a universal format, enabling Delta Lake to support multiple connector ecosystems like Iceberg and Hudi without data duplication.
What is the main challenge that Delta UniForm aims to solve?
The main challenge is the fragmented ecosystem where each format has varying tool/engine support, leading to vendor lock-in.
What are the key features and benefits of Delta UniForm?
Key benefits include single copy of data, automated multi-format metadata generation, open source, available in Delta 3.0, and Unity Catalog support.
How does Delta UniForm ensure high performance and scalability?
Delta UniForm has negligible overhead, incremental metadata generation, and minimal resource utilization even at petabyte scale.
What are the prerequisites for creating a new Delta table with Delta UniForm?
Prerequisites are Delta 3.0+, Databricks 13.2+, table in Unity Catalog, and minReaderVersion>=2, minWriterVersion>=7.
What are the steps to create a new catalog in Unity Catalog?
To create a catalog: CREATE CATALOG IF NOT EXISTS catalog_name;
How do you grant permissions on the created catalog?
Grant permissions using GRANT commands on the created catalog/schema.
What are the two key table properties to enable Delta UniForm?
The two key table properties to enable Delta UniForm are: 'delta.universalFormat.enabledFormats'='iceberg' and 'delta.enableIcebergCompatV2'='true'
How do you verify if Delta UniForm is enabled after creating a table?
Verify using SHOW TBLPROPERTIES <table_name>;
Does Delta UniForm work on tables with deletion vectors enabled?
No, Delta UniForm does not work on tables with deletion vectors enabled.
Can Iceberg clients write data to a Delta UniForm enabled table?
No, Iceberg clients can only read from a Delta UniForm enabled table, not write.
Why is Delta UniForm an exciting development for open data lakehouses?
It enables easy interoperability and eliminates data duplication across formats in open data lakehouses.















