



























Databricks is a powerful data analytics platform that excels at dealing with all sorts of data types. From simple integers and strings to complex structures like arrays and maps. Getting to know Databricks data types is super important if you want to make the most out of the platform. Choosing the right data types can not only give your analytics a performance boost but also help you maintain data compatibility and keep your data in perfect shape.
In this article, we will cover everything you need to know about Databricks data types, exploring the wide range of available types, their practical applications, and the best practices for implementation.
What are Databricks Data Types?
Databricks Data Types are classifications that define the nature and properties of the data stored within the platform. These data types provide structure and meaning to variables, columns, or fields, enabling Databricks to efficiently allocate memory, perform appropriate operations, and maintain data integrity. Think of them as different-sized containers that help Databricks understand what's inside, so it can effectively handle, organize, and analyze your data.
There are various types of these data types, like numeric, string, date & time, and complex for more intricate data structures. Each of these data types offers unique characteristics, allowing Databricks to process your data correctly and prevent any mix-ups. In the next section, we will explore each one of these types in detail.
Choosing the right Databricks data types for your data is super important in Databricks. It's like having the right tools for the job—it makes everything work better and smoother.
The importance of Databricks data types cannot be overstated. They play a crucial role in:
- Saving space: Databricks uses data types to optimize memory usage, allocating the right amount of storage space based on the characteristics and requirements of each data element.
- Accurate Data Processing: With the right data types in place, Databricks can perform operations such as arithmetic calculations, string manipulations, and date-time operations with precision and accuracy.
- Keeping Data Safe: Using the right data types helps Databricks catch mistakes and make sure the data stays correct and reliable.
- Speeding Things Up: Databricks works better when it knows the data types, so it can plan out tasks and be more efficient.
- Cross-Platform Compatibility: Understanding data type mappings across different programming languages (e.g., Scala, Python, R) and tools allows for seamless integration and data exchange within the Databricks ecosystem.
So, getting to know Databricks Data Types is a must if you want to be good at using Databricks. It helps you organize your data better, make Databricks run smoothly, and get more useful insights from your data!
What Data Types Are Supported by Databricks?
Databricks supports a comprehensive set of data types, allowing users to represent a wide range of data formats and structures. These data types are organized into 6 main categories:
- Numeric Data Types
- String Data Types
- Boolean Data Types
- Date and Time Data Types
- Binary Data Types
- Complex Data Types
Let's explore each of these categories in more detail.
1) Numeric—Databricks Data Types
Numeric Databricks data types are used to represent various types of numerical values, ranging from whole numbers to floating-point and precise decimal values. These data types are essential for performing mathematical operations, statistical analysis, and other numerical computations.
Databricks supports the following numeric data types:
a) Integral Numeric—Databricks Data Types:
The integral numeric types in Databricks include TINYINT, SMALLINT, INT, and BIGINT. These data types are used to represent whole numbers, with each offering a different range of values and memory footprint.
╰➤ TINYINT
TINYINT data type is a 1-byte signed integer that can represent values ranging from -128 to 127. It has a precision of 3 and a scale of 0, meaning it can store up to 3 digits with no decimal places.
Syntax:
To declare a TINYINT Databricks data type, use either TINYINT or BYTE:
{ TINYINT | BYTE }Both keywords are interchangeable, so you can choose the one that best suits your coding style.
Example:
Here's a simple example of using the TINYINT Databricks data type:
SELECT CAST(123 AS TINYINT); 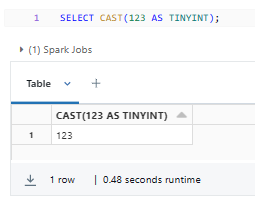
CREATE TABLE user_info (
user_id TINYINT,
is_admin TINYINT
);
INSERT INTO user_info (user_id, is_admin) VALUES
(1, 0), -- 0 = Not admin
(2, 1), -- 1 = Admin
(3, 0),
(4, 1),
(5, 0);
DESC TABLE user_info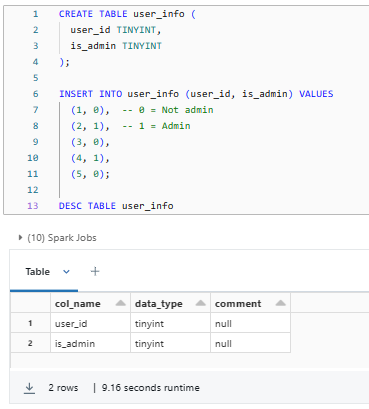
╰➤ SMALLINT
SMALLINT data type is a 2-byte signed integer that can represent values ranging from -32,768 to 32,767. It has a precision of 5 and a scale of 0, allowing for up to 5 digits with no decimal places.
Syntax:
To declare a SMALLINT Databricks data type, use either SMALLINT or SHORT. Both keywords serve the same purpose:
{ SMALLINT | SHORT }Example:
Here's a simple example of using the SMALLINT Databricks data type:
SELECT CAST(12345 AS SMALLINT);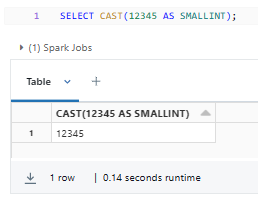
CREATE TABLE user_info_smallint_demo (
user_id SMALLINT,
is_admin SMALLINT
);
INSERT INTO user_info_smallint_demo (user_id, is_admin) VALUES
(1, 0), -- 0 = Not admin
(2, 1), -- 1 = Admin
(3, 0),
(4, 1),
(5, 0);
DESC TABLE user_info_smallint_demo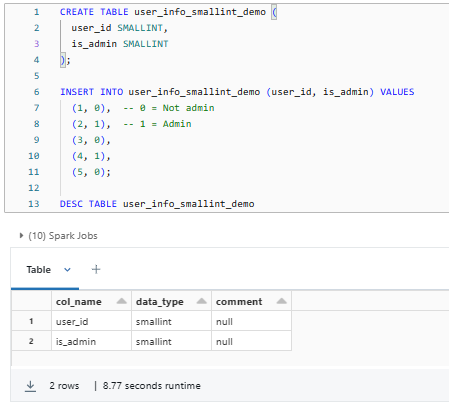
╰➤ INT
INT or INTEGER Databricks data type is a commonly used integral numeric type for representing whole numbers. It provides a balance between storage size and the range of values that can be represented for most common use cases. INT is a 4-byte signed integer that can represent values ranging from -2,147,483,648 to 2,147,483,647. It has a precision of 10 and a scale of 0, allowing for up to 10 digits with no decimal places.
Syntax:
To declare an INT Databricks data type, use either INT or INTEGER. Both keywords serve the same purpose:
{ INT | INTEGER }Example:
Here's a simple example of using the INT Databricks data type:
SELECT CAST(1234567890 AS INT);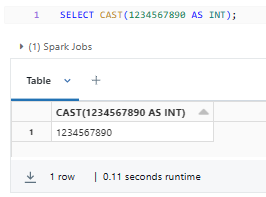
CREATE TABLE user_info_int_demo (
user_id INT,
is_admin INT
);
INSERT INTO user_info_int_demo (user_id, is_admin) VALUES
(1, 0), -- 0 = Not admin
(2, 1), -- 1 = Admin
(3, 0),
(4, 1),
(5, 0);
DESC TABLE user_info_int_demo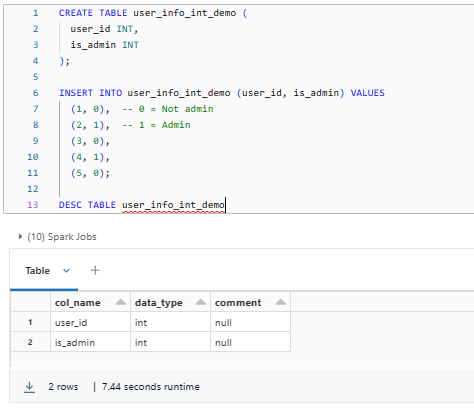
When a literal falls outside the range of an INT, Databricks will automatically convert it to a BIGINT.
For Example:
SELECT typeof(1234567890123);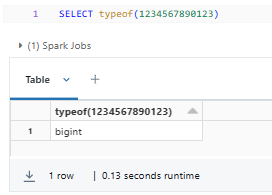
╰➤ BIGINT
BIGINT Databricks data type is an integral numeric type used to represent whole numbers. It provides the largest range of values among the integral numeric types but also has the largest storage size. BIGINT data type is an 8-byte signed integer that can represent values ranging from -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807. It has a precision of 19 and a scale of 0, allowing for up to 19 digits without decimal places.
Syntax:
To declare an BIGINT Databricks data type, use either INT or INTEGER. Both keywords serve the same purpose:
{ BIGINT | LONG }Example:
Here's a simple example of using the BIGINT Databricks data type:
SELECT CAST(9223372036854775807 AS BIGINT);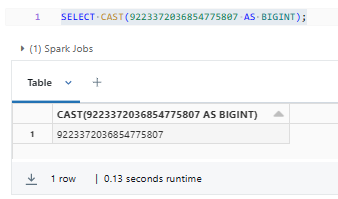
b) Exact Numeric—Databricks Data Types:
Databricks offers the DECIMAL data type, which represents exact numeric values with a fixed precision and scale. The DECIMAL data type is particularly useful for applications that require precise numerical calculations, such as financial transactions, scientific measurements, or accounting records—and so much more!
╰➤ DECIMAL
DECIMAL Databricks data type allows you to specify the precision (p) and scale (s) of the numeric value. The precision represents the total number of digits in the number, while the scale represents the number of digits after the decimal point.
The range of numbers that can be represented by the DECIMAL data type depends on the specified precision and scale. The range includes:
- Negative numbers: From -1E(p-s+1) to -1E-s
- Zero: 0
- Positive numbers: From 1E-s to 1E(p-1) - 1
Syntax:
To declare a DECIMAL Databricks data type, use the following syntax:
{ DECIMAL | DEC | NUMERIC } [ ( p [ , s ] ) ]Here's what each component means:
- DECIMAL, DEC, or NUMERIC: These keywords are used interchangeably to specify a decimal data type.
- p: This is an optional parameter that defines the maximum precision or the total number of digits in the number, with a range of 1 to 38. If not specified, the default precision is 10.
- s: This is an optional parameter that defines the scale or the number of digits to the right of the decimal point. The scale must be between 0 and p. If not specified, the default scale is 0.
Example:
Here's a simple example of using the DECIMAL Databricks data type:
SELECT CAST(123.454 AS DECIMAL(5,2));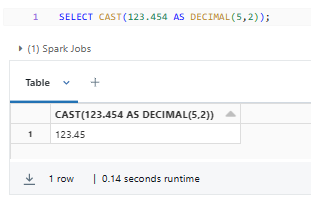
SELECT CAST(1.234 AS DECIMAL(3, 2));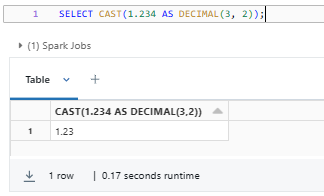
SELECT typeof(CAST(1.2345 AS DECIMAL));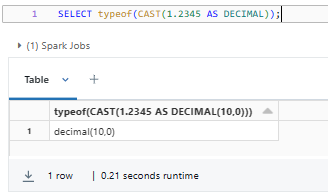
CREATE TABLE employee_salary_decimal_demo (
employee_id INT,
salary DECIMAL(10, 2),
bonus DECIMAL(8, 2)
);
INSERT INTO employee_salary_decimal_demo (employee_id, salary, bonus) VALUES
(1, 50000.00, 2500.00), -- Example values
(2, 60000.50, 9000.00),
(3, 55000.00, 6000.00);
DESC TABLE employee_salary_decimal_demo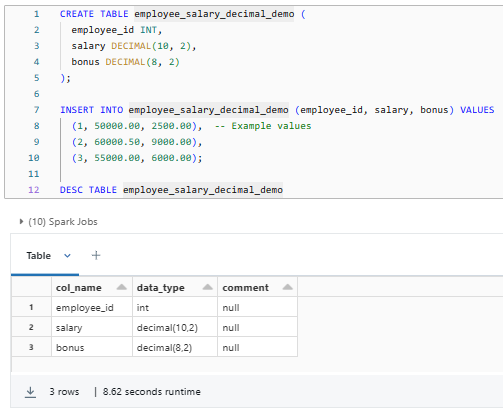
c) Approximate Numeric—Databricks Data Types:
On top of the exact numeric types, Databricks also provides approximate numeric types, specifically FLOAT and DOUBLE. These data types are used to represent floating-point numbers, which are suitable for scientific or mathematical calculations where a range of values is acceptable, and precision is not as critical as with the DECIMAL data type.
╰➤ FLOAT
FLOAT Databricks data type is a 4-byte single-precision floating-point representation for numeric values. This data type is useful for storing decimal numbers when you don't require the precise control over precision and scale offered by the DECIMAL data type.
The FLOAT Databricks data type covers the following range of values:
- Negative infinity (-∞)
- -3.402E+38 to -1.175E-37
- Zero (0)
- 1.175E-37 to 3.402E+38
- Positive infinity (+∞)
- Not a number (NaN)
Syntax:
To declare a FLOAT Databricks data type, use either FLOAT or REAL:
{ FLOAT | REAL }Example:
Here are some examples of using the FLOAT Databricks data type:
SELECT CAST(3.14159 AS FLOAT);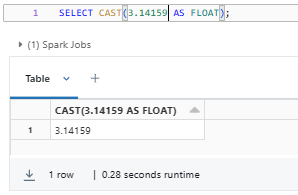
SELECT CAST(1.2345678 AS FLOAT);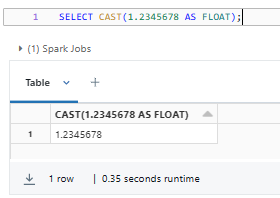
CREATE TABLE weather_float_demo (
city_id INT,
temperature FLOAT,
humidity FLOAT
);
INSERT INTO weather_float_demo (city_id, temperature, humidity) VALUES
(1, 25.5, 60.0),
(2, 18.2, 70.5),
(3, 20.0, 75.0);
DESC TABLE weather_float_demo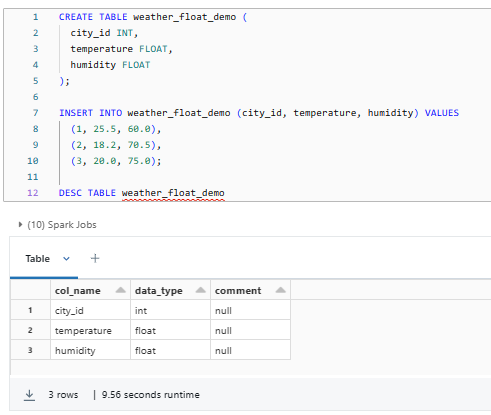
╰➤ DOUBLE
DOUBLE Databricks data type represents 8-byte double-precision floating-point numbers, suitable for cases where approximate values are acceptable, but higher precision is required compared to FLOAT, such as with scientific data or financial calculations.
The DOUBLE Databricks data type covers the following range of values:
- Negative infinity (-∞)
- -1.79769E+308 to -2.225E-307
- Zero (0)
- 2.225E-307 to 1.79769E+308
- Positive infinity (+∞)
- Not a number (NaN)
Syntax:
To declare a DOUBLE Databricks data type, use the keyword DOUBLE:
DOUBLEExample:
Here are some examples of using the DOUBLE Databricks data type:
SELECT CAST(3.14159265358979 AS DOUBLE);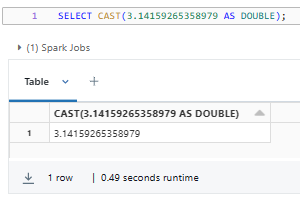
SELECT CAST(1.2345678901234 AS DOUBLE);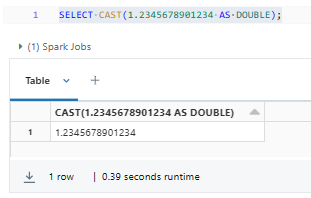
CREATE TABLE planet_data_double_demo (
planet_id INT,
distance_from_sun DOUBLE,
surface_gravity DOUBLE
);
INSERT INTO planet_data_double_demo (planet_id, distance_from_sun, surface_gravity) VALUES
(1, 5.8E+08, 9.8),
(2, 2.4E+11, 3.7),
(3, 2.3E+12, 1.6);
DESC TABLE planet_data_double_demo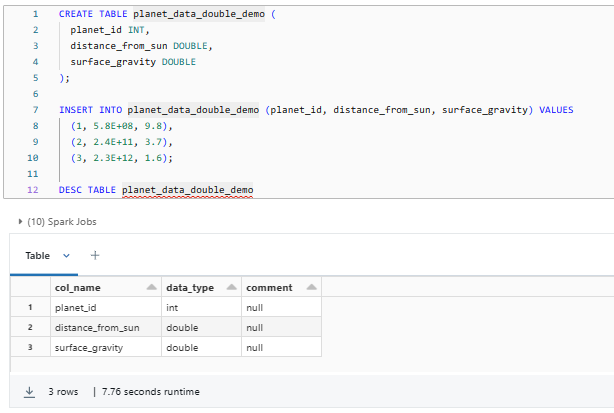
2) String—Databricks Data Types
STRING Databricks data type is used to represent textual data, such as names, addresses, descriptions, and other alphanumeric values. Strings are enclosed in single or double quotation marks and can contain letters, numbers, and special characters.
STRING Databricks data type is a variable-length character string that can supports character sequences of any length greater or equal to 0. It has no predefined precision or scale, and its length is determined by the content of the string.
Syntax:
To declare a STRING Databricks data type, use the keyword STRING:
STRINGExample:
Here's a simple example of using the STRING Databricks data type:
SELECT CAST(101 AS STRING);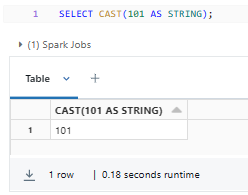
SELECT 'Hello there!';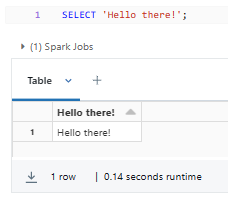
SELECT CONCAT('Data', 'bricks');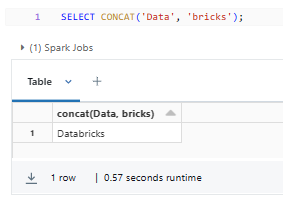
CREATE TABLE products_string_demo (
product_id INT,
product_name STRING,
description STRING
);
INSERT INTO products_string_demo (product_id, product_name, description) VALUES
(1, 'Laptop', 'High-performance laptop'),
(2, 'Smartphone', 'Best smartphone w/ 5G connectivity'),
(3, 'Headphones', 'Water proof noise-cancelling headphone');
DESC TABLE products_string_demo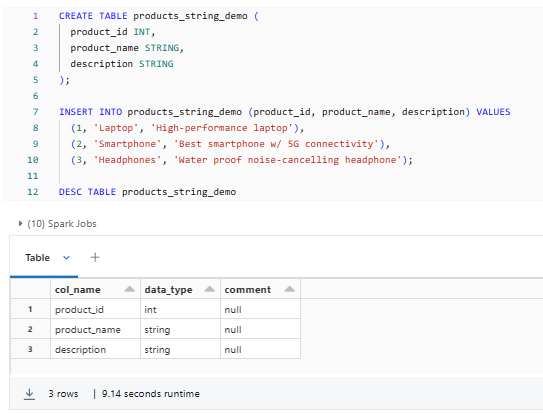
STRING Databricks data type is highly versatile, enabling you to handle a wide range of text-based information. It is essential for tasks like data cleaning, text mining, natural language processing, and other text-centric applications.
3) Binary—Databricks Data Types
Databricks also supports the BINARY data type, which is used to store raw binary data, such as images, audio files, or other types of unstructured data.
BINARY Databricks data type represents a sequence of bytes. It has no predefined precision or scale, and its length is determined by the size of the binary data.
Syntax:
To declare a BINARY Databricks data type, use the keyword BINARY:
BINARY[(length)]Example:
Here's a simple example of using the BINARY Databricks data types:
SELECT CAST('Databricks' AS BINARY);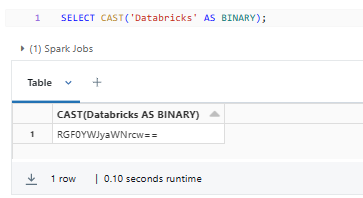
CREATE TABLE image_binary_demo (
image_id INT,
image_data BINARY
);
INSERT INTO image_binary_demo (image_id, image_data) VALUES
(1, CAST('binary_image_data_1' AS BINARY));
DESC TABLE image_binary_demo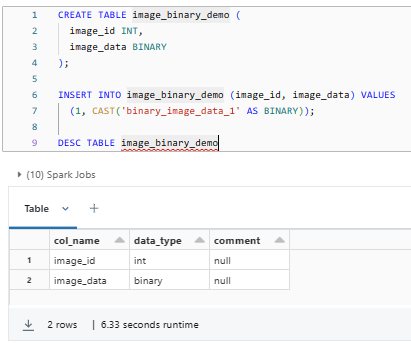
4) Date & Time—Databricks Data Types
Databricks offers several data types for handling date and time-related information, including DATE, TIMESTAMP, and TIMESTAMP_NTZ.
╰➤ DATE
DATE Databricks data type represents a calendar date, suitable for cases where only the date part (year, month, and day) is relevant. The DATE Databricks data type covers a range of dates between June 23 -5877641 CE to July 11 +5881580 CE.
Syntax:
To declare a DATE Databricks data type, use the keyword BINARY:
DATEExample:
Here's a simple example of using the DATE Databricks data type:
SELECT CAST('2023-04-08' AS DATE);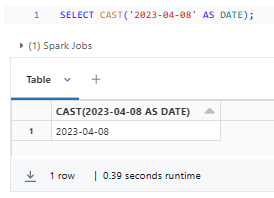
CREATE TABLE student_date_demo (
student_id INT,
birthdate DATE
);
INSERT INTO student_date_demo (student_id, birthdate) VALUES
(1, '1995-05-10'),
(2, '1998-02-20'),
(3, '1992-09-01'),
(4, '2001-07-05');
DESC TABLE student_date_demo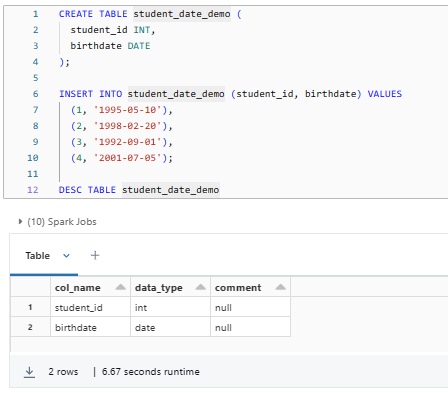
╰➤ TIMESTAMP
TIMESTAMP Databricks data type represents a point in time, suitable for cases where both the date and time parts are relevant. The TIMESTAMP Databricks data type covers a range of dates between -290308-12-21 BCE 19:59:06 GMT to +294247-01-10 CE 04:00:54 GMT.
Syntax:
To declare a TIMESTAMP Databricks data type, use the keyword TIMESTAMP:
TIMESTAMP[(p)]where: p is the precision (number of digits after the decimal point), ranging from 0 to 9
Example:
Here's a simple example of using the TIMESTAMP Databricks data type:
SELECT CAST('2023-04-08 12:34:56.789' AS TIMESTAMP); 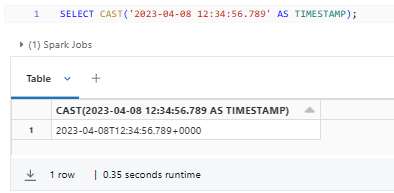
CREATE TABLE events_timestamp_demo (
event_id INT,
event_timestamp TIMESTAMP,
last_updated TIMESTAMP
);
INSERT INTO events_timestamp_demo (event_id, event_timestamp, last_updated) VALUES
(1, '2024-03-15 14:30:00', '2024-03-17 09:45:30'),
(2, '2024-03-16 20:15:00', '2024-03-18 12:00:00'),
(3, '2024-03-18 11:45:00', '2024-03-20 06:15:00');
DESC TABLE events_timestamp_demo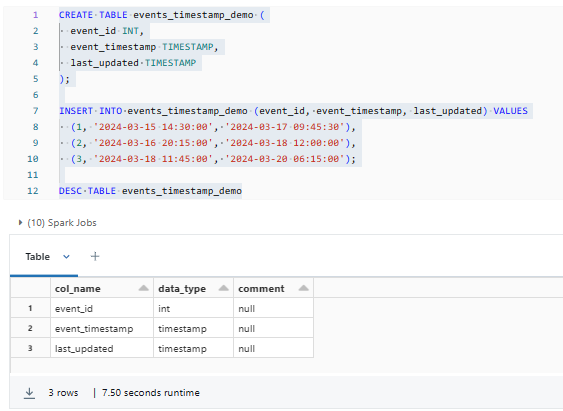
╰➤ TIMESTAMP_NTZ
TIMESTAMP_NTZ data type in Databricks represents a point in time, similar to the TIMESTAMP data type, but with a key difference: it does not contain time zone information. This can be useful when working with timestamps that are already normalized or when time zone information is not relevant. This feature is in Public Preview. TIMESTAMP_NTZ supports a timestamp range from -290308-12-21 BCE 19:59:06 to +294247-01-10 CE 04:00:54.
Note:
- TIMESTAMP_NTZ data type is not yet supported in Photon, Delta Sharing, Databricks data sources used in Power BI, Tableau, Databricks JDBC/ODBC drivers, or Databricks open-source drivers.
- While TIMESTAMP_NTZ is supported in file sources such as Delta, Parquet, ORC, Avro, JSON, and CSV, there is a limitation on schema inference for JSON/CSV files with TIMESTAMP_NTZ columns. For backward compatibility, the default inferred timestamp type from spark.read.csv(...) or spark.read.json(...) will be TIMESTAMP instead of TIMESTAMP_NTZ.
Syntax:
To declare a TIMESTAMP_NTZ Databricks data type, use the keyword BINARY:
TIMESTAMP_NTZ[(p)]where: p is the precision (number of digits after the decimal point), ranging from 0 to 9
Example:
Here's a simple example of using the TIMESTAMP_NTZ Databricks data type:
CREATE TABLE events_timestamp_ntz_demo (
event_id INT,
event_timestamp TIMESTAMP_NTZ,
last_updated TIMESTAMP_NTZ
);
INSERT INTO events_timestamp_ntz_demo (event_id, event_timestamp, last_updated) VALUES
(1, '2024-03-15 14:30:00', '2024-03-17 09:45:30'),
(2, '2024-03-16 20:15:00', '2024-03-18 12:00:00'),
(3, '2024-03-18 11:45:00', '2024-03-20 06:15:00');
DESC TABLE events_timestamp_ntz_demoThese date and time-related Databricks data types enable you to effectively manage and analyze temporal data, allowing for accurate event tracking, time-based calculations, and synchronization across different data sources.
5) Interval—Databricks Data Types
INTERVAL Databricks data type represents a fixed-length time interval, which can be useful for various time-based calculations and operations. INTERVAL values can be used to express durations, periods, or time spans between two specific points in time.
Note:
- Years and months are part of year-month intervals, while days, hours, minutes, seconds, and fractions of a second are part of day-time intervals.
- The maximum range for a year-month interval is +/- 178,956,970 years and 11 months.
- The maximum range for a day-time interval is +/- 106,751,991 days, 23 hours, 59 minutes, and 59.999999 seconds.
- Milliseconds (ms) and microseconds (us) are supported for fractions of a second.
Syntax:
To declare an INTERVAL Databricks data type, use the following syntax:
INTERVAL { yearMonthIntervalQualifier | dayTimeIntervalQualifier }Year-Month Intervals:
yearMonthIntervalQualifier
{ YEAR [TO MONTH] |
MONTH }Day-Time Intervals:
dayTimeIntervalQualifier
{ DAY [TO { HOUR | MINUTE | SECOND } ] |
HOUR [TO { MINUTE | SECOND } ] |
MINUTE [TO SECOND] |
SECOND }Example:
Here are some examples of using INTERVAL data types in Databricks SQL queries:
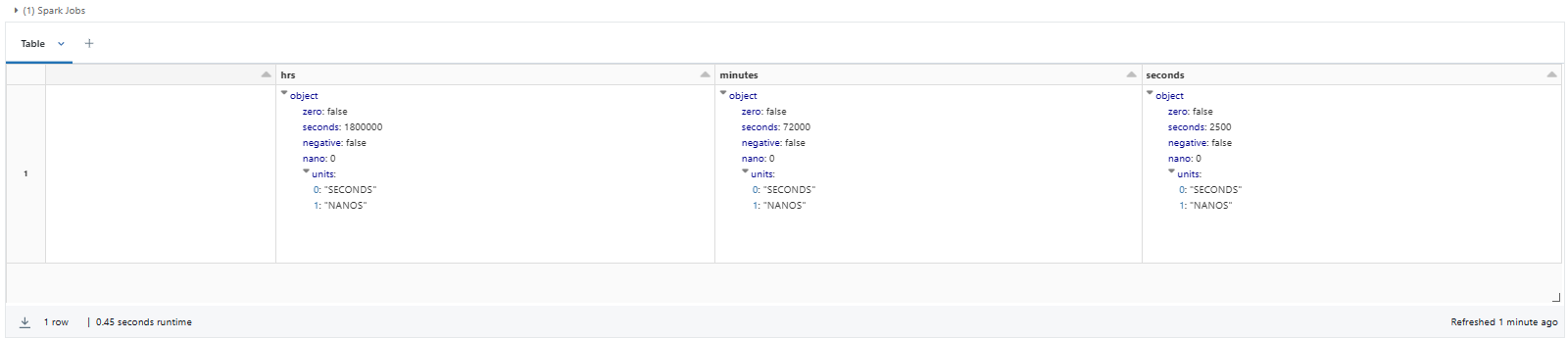
SELECT INTERVAL '1-2' YEAR TO MONTH AS year_month,
INTERVAL '10' MONTH AS months,
INTERVAL '150' DAY AS days,
INTERVAL '500' HOUR AS hrs,
INTERVAL '1200' MINUTE AS minutes,
INTERVAL '2500' SECOND AS seconds;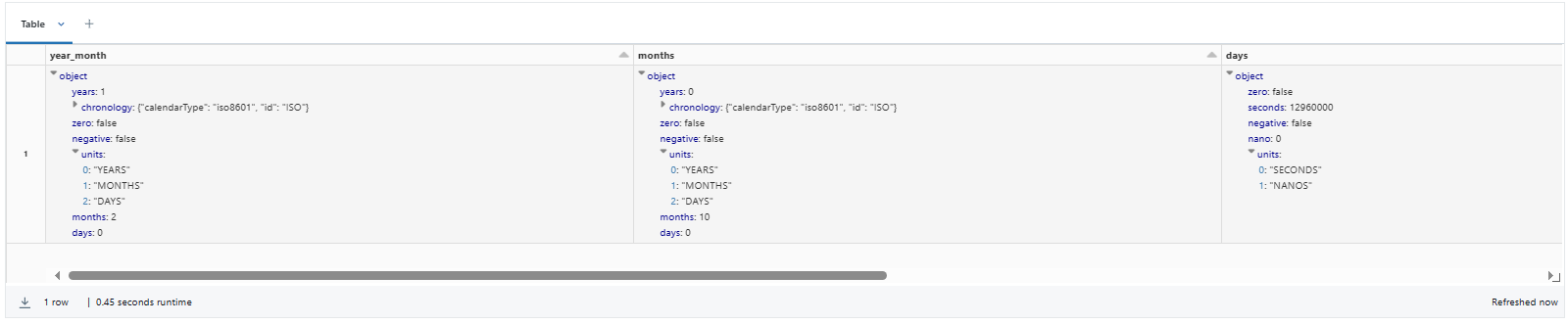
CREATE TABLE project_plan_interval_demo (
task_id INT,
task_duration_1 INTERVAL YEAR TO MONTH,
task_duration_2 INTERVAL DAY TO HOUR,
task_duration_3 INTERVAL DAY
);
INSERT INTO project_plan_interval_demo (task_id, task_duration_1, task_duration_2, task_duration_3) VALUES
(1, INTERVAL '1-2' YEAR TO MONTH, INTERVAL '10 12' DAY TO HOUR, INTERVAL '3' DAY),
(2, INTERVAL '3-4' YEAR TO MONTH, INTERVAL '15 18' DAY TO HOUR, INTERVAL '7' DAY),
(3, INTERVAL '5-6' YEAR TO MONTH, INTERVAL '20 22' DAY TO HOUR, INTERVAL '14' DAY);
DESC TABLE project_plan_interval_demo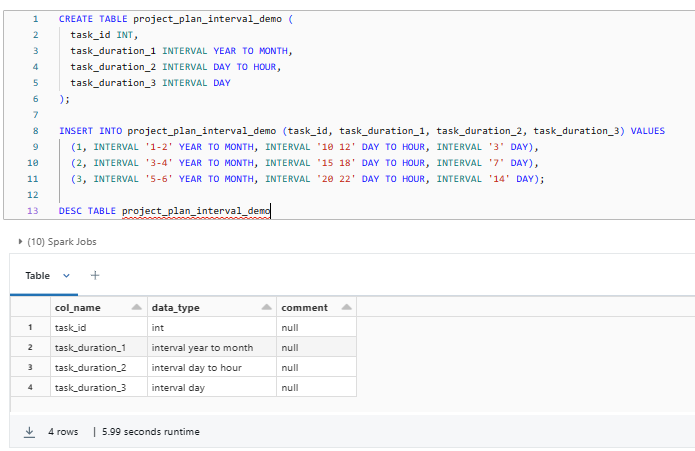
6) Complex—Databricks Data Types
Aside from the basic data types we've covered, Databricks also offers more advanced, complex data types to help you organize and represent your data in a more structured and hierarchical way. These complex Databricks data types are ARRAY, MAP, and STRUCT, which provide greater flexibility for handling intricate data relationships.
╰➤ ARRAY
ARRAY Databricks data type is a collection of ordered elements of the same data type. These elements can be of different primitive or complex data types, including strings, integers, and other complex types like arrays, maps, or structs.
Syntax:
To declare an ARRAY data type in Databricks, use the following syntax:
ARRAY<elementType>where: elementType is any data type defining the type of the elements of the array.
Example:
Here's a simple example of using the ARRAY Databricks data type:
SELECT ARRAY(1, 2, 3, 4, 5); 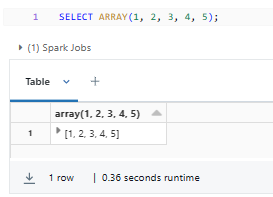
SELECT ARRAY('Databricks', 'Data', 'Types'); 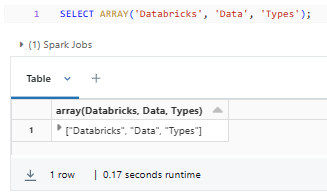
CREATE TABLE user_preferences_array_demo (
user_id INT,
favorite_colors ARRAY<STRING>,
interests ARRAY<STRING>,
scores ARRAY<INT>
);
INSERT INTO user_preferences_array_demo (user_id, favorite_colors, interests, scores) VALUES
(1, ARRAY('red', 'orange', 'green'), ARRAY('sports', 'music', 'arts'), ARRAY(85, 90, 95)),
(2, ARRAY('orange', 'red', 'purple'), ARRAY('movies', 'photography', 'travel'), ARRAY(80, 88, 92)),
(3, ARRAY('black', 'green', 'gray'), ARRAY('cooking', 'reading', 'gaming'), ARRAY(75, 85, 90));
DESC TABLE user_preferences_array_demo;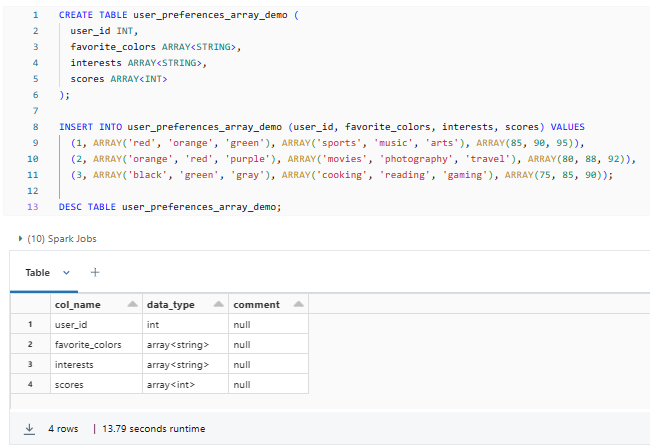
╰➤ MAP
MAP Databricks data type represents a collection of key-value pairs, where the keys are unique, and the values can be of any data type. Maps are useful for representing structured data with named attributes, such as customer information or product details.
Syntax:
To declare an MAP data type in Databricks, use the following syntax:
MAP<keyType, valueType>where: keyType refers to any data type other than MAP specifying the keys, and valueType denotes any data type specifying the values.
Example:
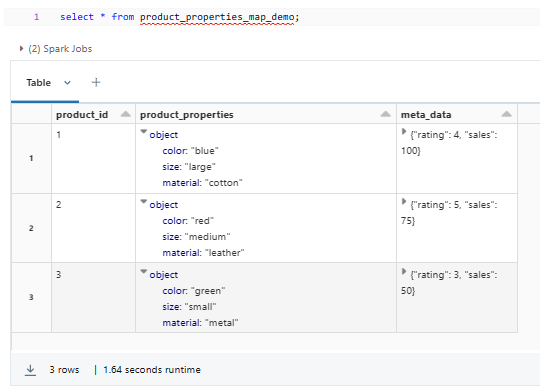
Here's a simple example of using the MAP Databricks data type:
SELECT MAP(1, 'one', 2, 'two', 3, 'three'); 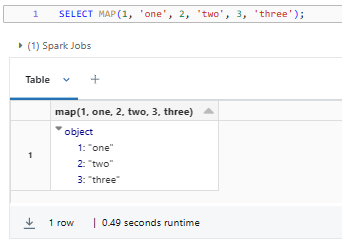
CREATE TABLE product_properties_map_demo (
product_id INT,
product_properties MAP<STRING, STRING>,
meta_data MAP<STRING, INT>
);
INSERT INTO product_properties_map_demo (product_id, product_properties, meta_data) VALUES
(1, MAP('color', 'blue', 'size', 'large', 'material', 'cotton'), MAP('rating', 4, 'sales', 100)),
(2, MAP('color', 'red', 'size', 'medium', 'material', 'leather'), MAP('rating', 5, 'sales', 75)),
(3, MAP('color', 'green', 'size', 'small', 'material', 'metal'), MAP('rating', 3, 'sales', 50));
DESC TABLE product_properties_map_demo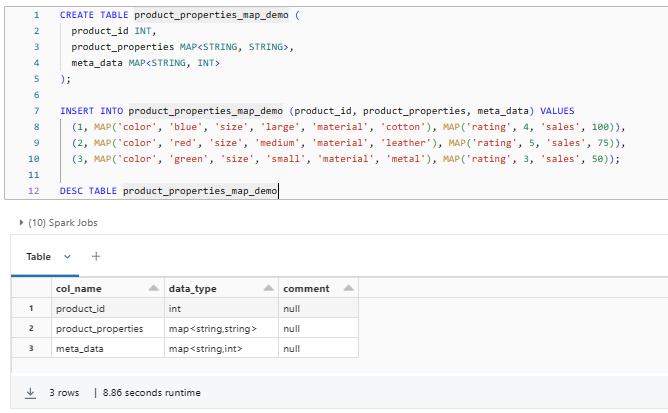
╰➤ STRUCT
STRUCT Databricks data type allows for the creation of complex, user-defined data structures, consisting of a sequence of named fields, each with its own data type. Structs are particularly valuable for modeling hierarchical or nested data, such as customer orders with line items or sensor data with multiple measurements.
Syntax:
To declare a STRUCT Databricks data type, use the keyword BINARY:
STRUCT<[fieldName : fieldType [NOT NULL][COMMENT str][, …]]>where: fieldName denotes an identifier naming the field, and fieldType represents any data type.
Example:
Here's a simple example of using the STRUCT Databricks data type:
SELECT STRUCT('Elon Musk' AS name, 50 AS age, TRUE AS is_billionaire);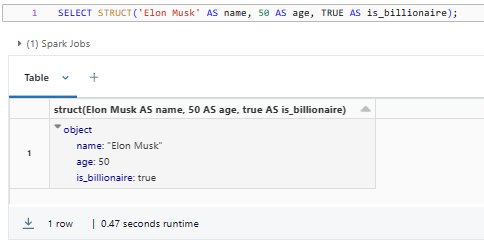
CREATE TABLE user_data_struct_demo (
user_id INT,
name STRUCT<first_name: STRING, last_name: STRING>,
contact_info STRUCT<email: STRING, phone: STRING>
);
INSERT INTO user_data_struct_demo (user_id, name, contact_info) VALUES
(1, NAMED_STRUCT('first_name', 'Elon', 'last_name', 'Musk'), NAMED_STRUCT('email', '[email protected]', 'phone', '123-456-7890')),
(2, NAMED_STRUCT('first_name', 'Jeff', 'last_name', 'Bezos'), NAMED_STRUCT('email', '[email protected]', 'phone', '111-111-1111')),
(3, NAMED_STRUCT('first_name', 'Mark', 'last_name', 'Zuck'), NAMED_STRUCT('email', '[email protected]', 'phone', '456-789-0123'));
DESC TABLE user_data_struct_demo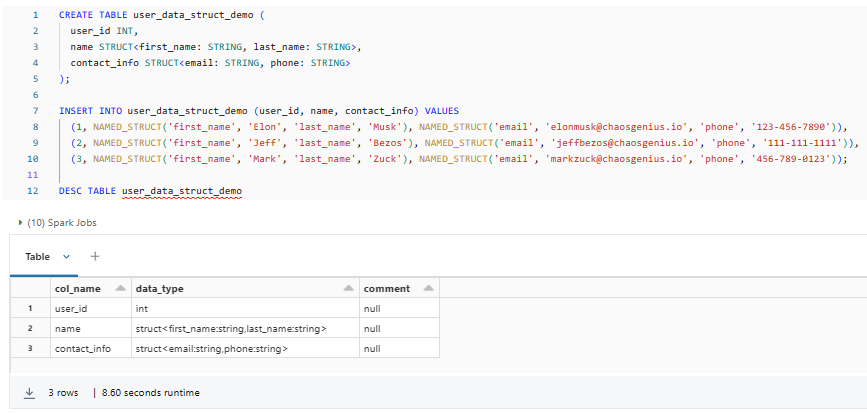
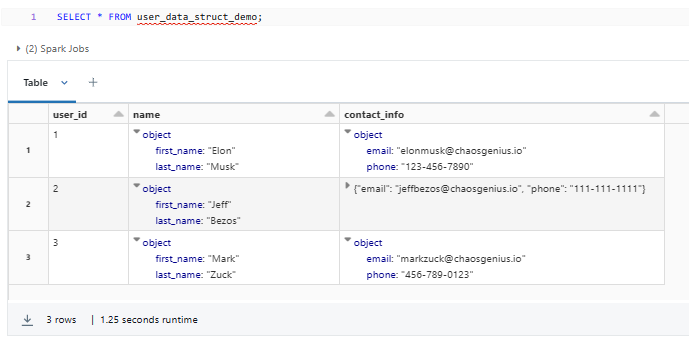
These complex Databricks data types provide a powerful way to handle and manipulate data that exhibits a more intricate structure, enabling you to capture the relationships and hierarchies within your data, leading to more meaningful insights and analysis.
Databricks Data Type Mappings and Conversions
Databricks, as a unified data analytics platform, supports various programming languages, including Scala, Java, Python, and R. However, each language has its own native data types, so understanding how Databricks data types map to these language-specific types is crucial for efficient data processing and manipulation.
Let's dive into the details of Databricks data type mappings for each of the supported languages:
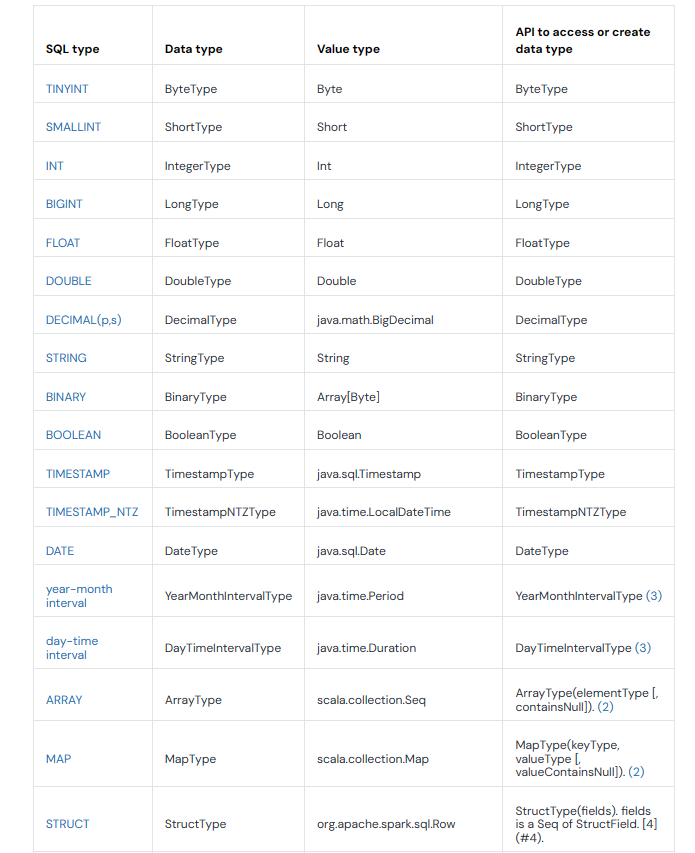
1) Scala Data Type Mappings
In Scala, Databricks data types are defined in the org.apache.spark.sql.types package. This package provides a comprehensive set of data types that closely align with the data types available in Databricks.
Here are some of the commonly used Scala data types and their corresponding Databricks data types:
- ByteType maps to the TINYINT Databricks data type
- ShortType maps to the SMALLINT Databricks data type
- IntegerType maps to the INT Databricks data type
- LongType maps to the BIGINT Databricks data type
- FloatType maps to the FLOAT Databricks data type
- DoubleType maps to the DOUBLE Databricks data type
- DecimalType maps to the DECIMAL Databricks data type
- StringType maps to the STRING Databricks data type
- BinaryType maps to the BINARY Databricks data type
- BooleanType maps to the BOOLEAN Databricks data type
- TimestampType maps to the TIMESTAMP Databricks data type
- DateType maps to the DATE Databricks data type
- ArrayType maps to the ARRAY Databricks data type
- MapType maps to the MAP Databricks data type
- StructType maps to the STRUCT Databricks data type
How to Access Databricks Data Types in Scala?
To access the Spark SQL data types in Scala, you need to import the org.apache.spark.sql.types package:
import org.apache.spark.sql.types._This allows you to directly reference and work with the various Databricks data types.
Example: Creating a Spark DataFrame with Databricks Data Types in Scala
Here's an example of how you can create a Spark DataFrame with a variety of Databricks data types in Scala:
%scala
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder().getOrCreate()
val schema = StructType(
StructField("id", IntegerType, nullable = false) ::
StructField("name", StringType, nullable = false) ::
StructField("age", IntegerType, nullable = false) ::
StructField("is_billionaire", BooleanType, nullable = false) :: Nil
)
val data = Seq(
Row(1, "Elon Musk", 55, true),
Row(2, "Bill Gates", 60, true),
Row(3, "Dwyane Johnson", 42, false)
)
val df = spark.createDataFrame(spark.sparkContext.parallelize(data), schema)
df.show()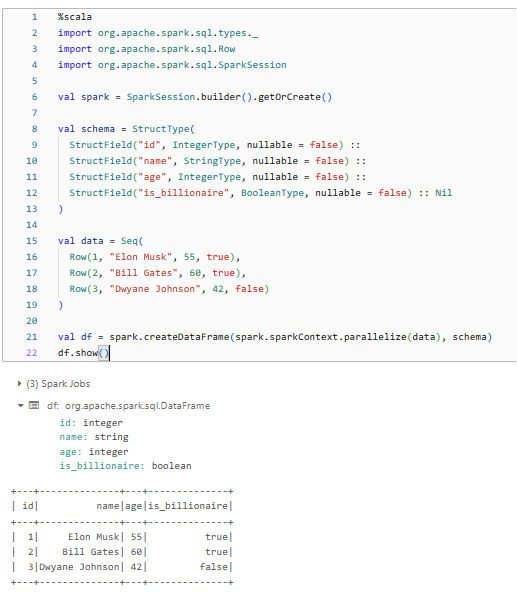
As you can see, we created a Spark DataFrame with various data types, including IntegerType, StringType, and BooleanType, which directly map to the corresponding Databricks data types.
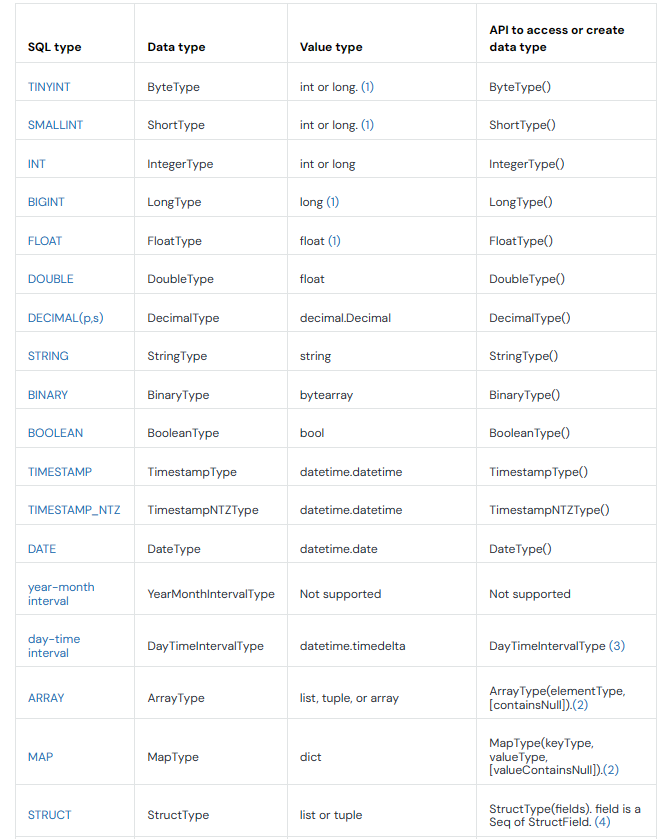
2) Python Data Type Mappings
Databricks also provides excellent support for the Python programming language, allowing you to seamlessly work with Spark SQL data types within the Python ecosystem.
The following are some of the commonly used Python data types and their corresponding Databricks data types:
- ByteType maps to the TINYINT Databricks data type
- ShortType maps to the SMALLINT Databricks data type
- IntegerType maps to the INT Databricks data type
- LongType maps to the BIGINT Databricks data type
- FloatType maps to the FLOAT Databricks data type
- DoubleType maps to the DOUBLE Databricks data type
- DecimalType maps to the DECIMAL Databricks data type
- StringType maps to the STRING Databricks data type
- BinaryType maps to the BINARY Databricks data type
- BooleanType maps to the BOOLEAN Databricks data type
- TimestampType maps to the TIMESTAMP Databricks data type
- DateType maps to the DATE Databricks data type
- ArrayType maps to the ARRAY Databricks data type
- MapType maps to the MAP Databricks data type
- StructType maps to the STRUCT Databricks data type
Note: The year-month interval data type is not supported in the Python API.
How to Access Databricks Data Types in Python?
To access the Spark SQL data types in Python, you need to import the pyspark.sql.types module:
from pyspark.sql.types import *Example:
Here's a simple example of how you can create a Spark DataFrame with a variety of data types in Python:
%python
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from pyspark.sql import Row
spark = SparkSession.builder.getOrCreate()
schema = StructType([
StructField("id", IntegerType(), False),
StructField("name", StringType(), False),
StructField("age", IntegerType(), False),
StructField("is_billionaire", BooleanType(), False)
])
data = [
Row(1, "Elon Musk", 55, True),
Row(2, "Bill Gates", 60, True),
Row(3, "Dwyane Johnson", 42, False)
]
df = spark.createDataFrame(data, schema)
df.show()
Check out this documentation to learn more in-depth about Java and R data type mappings and conversions
Knowing these data type mappingsgives you the confidence to convert data types accurately and guarantees precise processing, regardless of the language you're working with.
What Are the Best Practices for Choosing Databricks Data Types?
Proper data type selection is crucial when working with Databricks, as it can significantly impact performance, storage efficiency, and data integrity. In this section, we will guide you through the best practices for selecting the most appropriate data types for your Databricks pipelines and workloads.
1) Maintain Data Type Consistency
One of the fundamental best practices when working with Databricks data types is to maintain consistency across your data pipelines. Consistency in data type usage not only simplifies the management and maintenance of your data but also enhances the reliability of your applications.
When creating your data models, try to stick to standard data types for different data elements. Consistency helps keep data storage and processing predictable. This makes it simpler to perform operations, validate data, and maintain data quality.
Let's say you have a column for customer ages. It's better to stick to an integer data type, like INT or SMALLINT, instead of mixing it with strings. This way, you can easily perform age-based calculations, filter data, and aggregate information more accurately and efficiently.
2) Handle Null Values and Missing Data
In real-life datasets, you'll often find null values and missing data. How you deal with them can make a big difference in your Databricks applications' accuracy and reliability. So, when defining data types, think about how to handle these gaps.
Databricks offers the NULL data type for missing values, but it behaves differently depending on the data type and context. Make sure you understand how NULL values are treated in your workflows to avoid any issues.
3) Be Cautious When Converting Between Data Types
Occasionally, you may need to convert data types in your Databricks pipelines. Improper data type conversions can lead to data loss, precision issues, or unexpected behavior. Databricks supports both implicit and explicit data type conversions, but it's generally recommended to use explicit conversion functions like CAST and TRY_CAST for more controlled and predictable results.
When converting data types in Databricks, keep these tips in mind:
- Understand Databricks' data type precedence hierarchy to anticipate and manage potential conflicts.
- Pay close attention to precision and scale, especially when converting numeric data types, to avoid losing important decimal places or introducing rounding errors.
- Handle string conversions carefully, ensuring the data matches the expected format (e.g., converting strings to numbers or dates).
- Use explicit conversion functions like CAST and TRY_CAST to make your conversion logic more transparent and robust.
- Document your conversion strategies, including any known risks and mitigation measures, for better long-term data management.
4) Consider Precision and Scale Requirements for Numeric Data Types
When working with numeric data in Databricks, carefully consider the precision and scale requirements of your data to ensure optimal storage, performance, and accuracy.
Precision refers to the total number of digits that can be represented, while scale refers to the number of digits after the decimal point. Choose the smallest numeric data type (e.g., TINYINT, SMALLINT, INT, BIGINT, FLOAT, DOUBLE, DECIMAL) that can accommodate your data to optimize storage and performance.
Here are some best practices to consider when selecting the appropriate numeric data types:
- Choose the smallest data type that works for your data to optimize storage and performance.
- For precise calculations, use DECIMAL instead of FLOAT or DOUBLE to avoid rounding errors.(FLOAT and DOUBLE offer a wide range but may not be precise enough for some applications.)
- Specify the right precision and scale for your DECIMAL data types to balance storage, accuracy, and value representation.
- Examine your data's characteristics to determine the best data type.
- Regularly monitor and adjust your data types as needed to keep your applications efficient and reliable.
5) Handle Date and Timestamp Data Effectively
Databricks provides several data types for working with dates and timestamps, like DATE, TIMESTAMP, and TIMESTAMP_NTZ. Each of these data types has its own unique characteristics and use cases, and understanding the differences between them is crucial for ensuring the proper handling of your temporal data.
When working with date and timestamp data in Databricks, follow these best practices:
- Pick the right data type based on your needs, like whether you need time zone info or a specific date range.
- Use TIMESTAMP_NTZ for data that doesn't require time zones, and TIMESTAMP for data that does.
- Be cautious when performing time zone conversions and use Databricks' built-in date and time functions (e.g., date_format, to_date, to_timestamp, datediff) to handle temporal data effectively.
- Maintain consistency in the use of date and timestamp data types throughout your applications.
- Handle null values and missing data properly to maintain data quality
6) Use Struct or Array for Complex Nested Structures
Databricks provides the STRUCT and ARRAY data types for handling complex or nested data structures. STRUCT allows you to create custom data types with multiple fields and heterogeneous data types, while ARRAY is suitable for working with ordered collections of homogeneous data types.
When dealing with complex data types in Databricks, follow these tips:
- Analyze your data requirements and create appropriate complex data types like STRUCT and ARRAY to represent nested or hierarchical data accurately.
- Nest complex data types within each other to build complex data structures that reflect your data model.
- Optimize performance by designing efficient data models and queries when working with complex data types.
- Use consistent field names and data types to simplify data analysis and maintenance.
- Familiarize yourself with Databricks functions designed for complex data types, such as struct, array, get_field, and explode.
- Document your complex data structures to make sure long-term maintainability and understanding.
7) Understand Databricks Data Type Resolution Strategies
Databricks uses a well-defined set of data type resolution mechanisms to handle various data type scenarios and conflicts. These strategies include:
- Promotion: Databricks expands data types to accommodate all possible values, following a predefined type hierarchy (e.g., promoting TINYINT to INT if values are within the TINYINT range).
- Implicit Downcasting: Databricks automatically converts wider types to narrower ones. Be careful, though, as this can cause data loss if values don't fit the narrower type.
- Implicit Crosscasting: Databricks changes types for function compatibility, like turning a number into a string. This is helpful, but make sure it doesn't mess up your intended data processing.
Remember, knowing these rules will help you manage data types better and avoid errors in Databricks.
8) Use Databricks Data Type Conversion Functions
In addition to the automatic data type resolution mechanisms, Databricks provides several built-in functions for explicit data type conversions:
- CAST Function: Converts values to specific data types. Useful when you need to control types directly.
- TRY_CAST Function: Similar to CAST, but returns NULL instead of throwing errors if the conversion fails. Great for handling messy or inconsistent data.
Databricks also offers a bunch of additional built-in operators and functions to simplify data type conversions.
Getting to know these functions is a huge help in managing Databricks data types like a pro and making sure your data processing runs smoothly, just the way you want it.
Which datatype is not supported by Databricks?
Although Databricks provides a wide variety of data types for diverse processing needs, some types aren't supported natively. Knowing these unsupported types and their impact is essential to ensure smooth data workflow integration within Databricks.
1) CHAR and VARCHAR
While the official Databricks documentation does not explicitly mention support for VARCHAR and CHAR data types, these are in fact supported through the use of Delta Lake.
Delta Lake, which is integrated with Databricks, utilizes the Parquet file format as its underlying storage layer. Parquet's StringType is used to represent string data, and it includes metadata about the length of the string values.
Delta Lake leverages this Parquet StringType and its length metadata to effectively emulate the behavior of VARCHAR and CHAR data types. This ensures that length constraints are enforced, maintaining data integrity even when working with these traditional string types within the Databricks ecosystem.
So, while the support for VARCHAR and CHAR may not be obvious from the Databricks documentation, Delta Lake provides a seamless way to work with these data types as part of your Databricks data workflows.
2) BLOB and CLOB
Databricks does not natively support the BLOB (Binary Large Object) and CLOB (Character Large Object) data types, which are commonly used in relational databases to store large binary or text-based data, respectively.
If you have data that would typically be stored in BLOB or CLOB columns, you can consider the following approaches:
- Use the BINARY Data Type: BINARY Databricks data type can be used to store binary data, such as images, documents, or other files. But, it is important to note that the BINARY data type has some certain size limit, which may not be suitable for extremely large binary objects.
- Store Data Externally: For larger binary or textual data, you may have to store the data outside of Databricks, such as in a dedicated file storage system (e.g., Azure Blob Storage, Amazon S3, GCS)
- Use Structured Formats: Instead of storing raw binary or text data, you can consider converting your data to structured formats, such as Parquet or Avro, which are natively supported by Databricks, which can help you manage and process your data more efficiently within the Databricks ecosystem.
- Leverage External Tools or Libraries: Integrate custom pipelines or libraries for seamless BLOB/CLOB data handling.
3) ENUM and SET
Databricks does not provide direct support for the ENUM and SET data types, which are commonly used in relational databases to represent a predefined set of options or choices.
If you have data that would typically be stored in ENUM or SET columns, you can consider the following approaches:
- Instead of ENUM or SET, you can represent your data using STRING or INTEGER data types in Databricks.
- You can create custom data handling and validation logic within your Databricks applications to mimic the behavior of ENUM or SET data types.
- As with previous cases, you may need to integrate external tools or libraries that can bridge the gap between ENUM/SET-based data and the Databricks platform.
4) GEOMETRY and GEOGRAPHICAL Data Types
Databricks does not natively support the GEOMETRY and GEOGRAPHICAL data types, which are commonly used in geospatial applications to store and process spatial data, such as points, lines, or polygons.
To work with geospatial data in Databricks, you can consider the following approaches:
- Use specialized libraries that extend Apache Spark for geospatial analytics, like GeoSpark, GeoMesa, GeoTrellis, or Rasterframes. These frameworks offer multiple language options and perform better than improvised methods.
- Use UDFs (user-defined functions) to process data in a distributed way with Spark DataFrames by wrapping single-node libraries like GeoPandas, GDAL, or JTS. It's simpler but might affect performance.
- Index your data using grid systems like GeoHex, or H3 from Uber to do spatial operations more efficiently. It may involve some approximation, but it could be worth the trade-off for better scaling.
- Depending on how complex your spatial data is, try representing it with Databricks' complex data types like STRUCT or ARRAY to capture the spatial info you need. It might require some custom data handling and processing, but it's doable!
Conclusion
So there you have it – understanding data types in Databricks is key to getting the most out of its analytics capabilities. From integers to complex structures, using the right data types ensures better performance, compatibility, and data accuracy. It's the foundation for a solid data system. Take the time to master Databricks data types, and you'll be well on your way to effective data analysis.
In this article, we have covered:
- What are Databricks Data Types?
- What Data Types Are Supported by Databricks?
- Working with Databricks Data Type Mappings and Conversions
- What Are the Best Practices for Choosing Databricks Data Types?
- Which datatype is not supported by Databricks?
… and so much more!
FAQs
What are Databricks data types?
Databricks data types are classifications that define the nature and properties of the data stored within the Databricks platform.
What are the main categories of Databricks data types?
Databricks supports 6 main categories of data types: Numeric, String, Boolean, Date and Time, Binary, and Complex (ARRAY, MAP, STRUCT).
What are the numeric data types supported by Databricks?
Databricks supports the following numeric data types: TINYINT, SMALLINT, INT, BIGINT, DECIMAL, FLOAT, and DOUBLE.
What is the difference between FLOAT and DOUBLE data types in Databricks?
FLOAT is a 4-byte single-precision floating-point number, while DOUBLE is an 8-byte double-precision floating-point number. DOUBLE offers a larger range and more precision than FLOAT.
What is the BINARY data type used for in Databricks?
BINARY data type in Databricks is used to store raw binary data, such as images, audio files, or other types of unstructured data.
What are the date and time data types supported by Databricks?
Databricks supports the following date and time data types: DATE, TIMESTAMP, and TIMESTAMP_NTZ (timestamp without time zone).
What are the complex data types supported by Databricks?
The complex data types supported by Databricks are ARRAY, MAP, and STRUCT.
How do Databricks data types map to data types in Scala?
In Scala, Databricks data types closely map to the data types defined in the org.apache.spark.sql.types package.
Why is it important to handle null values and missing data when working with Databricks data types?
Handling null values and missing data is crucial to avoid issues like data loss, precision problems, or unexpected behavior in your Databricks applications.
What are some best practices for working with date and timestamp data in Databricks?
Best practices include choosing the right data type (DATE, TIMESTAMP, TIMESTAMP_NTZ) based on your requirements, using Databricks' built-in date and time functions, and maintaining consistency in how you handle temporal data.
What are some Databricks data types that are not natively supported?
Databricks does not natively support CHAR, VARCHAR, ENUM, SET, GEOMETRY, and GEOGRAPHICAL data types.















