



























Databricks optimization significantly improves the performance, efficiency and cost-effectiveness of data analytics and machine learning workloads running on the Databricks platform. Optimizing Databricks involves a range of techniques and best practices aimed at enhancing workload value while simultaneously reducing resource utilization and associated costs.
In this article, you will learn in-depth 10 techniques and best practices for Databricks optimization. Also, we will discuss how to optimize Databricks resource allocation and how to closely monitor its usage and spending over time.
Databricks Pricing Overview
Databricks operates on a pay-as-you-go pricing model where the core billing unit is the Databricks Unit (DBU), representing the computational resources utilized. The total cost is a product of the DBUs consumed and the DBU rate, which varies based on several factors including the cloud provider, region, Databricks edition, and compute type.
For a more detailed breakdown of Databricks pricing, refer to this article: Databricks Pricing Model Explained—What Drives Your Databricks Costs.
Now, without further ado, let's dive straight into the core of this article to explore the Cost Reduction Techniques for Databricks Optimization.
10 Practical Cost Reduction Techniques for Databricks Optimization
1. Choose Optimal Instance Types—Databricks Optimization
One of the biggest factors influencing Databricks’ cost is the choice of cloud virtual machine instance types used for running clusters. Databricks launches cloud compute instances for the driver and worker nodes in a cluster to run distributed workloads. The type of instance that you choose for each node will determine the amount of CPU, memory, and storage that is available to the cluster.
To maximize performance while controlling Databricks costs, you should choose instance types that are aligned with the computational needs of your workload. This is a crucial step to optimize Databricks. If you choose instance types that are too powerful for your workload, you will be overspending. On the other hand, if you choose instance types that are too weak for your workload, your clusters will not perform as well as they could.
Let's explore best practices for instance selection:
- Evaluate instance types/families: The major cloud providers i.e. AWS, Azure, and GCP offer a wide variety of instance families optimized for different types of workloads. For example, the M5 and C5 families are good general purpose and compute optimized options on AWS.
- Analyze memory-optimized types: For memory-intensive workloads like Spark streaming and machine learning training, choose instances that are optimized for higher memory over compute, such as the R5 instance type on AWS.
- Right-size driver nodes: Driver nodes manage workload execution but don't need as many resources as worker nodes. Therefore, you can reduce Databricks costs by right-sizing driver nodes to smaller instance types.
- Utilize spot and preemptible instances: Spot and preemptible VM instances are offered at a discounted price, but they can be terminated at any time by the cloud provider. If your workload is fault-tolerant, you can use spot and preemptible instances to optimize Databricks.
Note: You can use the Amazon Spot Instance Advisor to determine a suitable price for your instance type and region.
- Continuously assess and test new instance families: Cloud providers are constantly releasing new instance types/families with improved price-performance. It is important to keep evaluating and testing new instance families to ensure that you are using the most cost-effective options for your databricks workloads.
2. Schedule Auto-Termination—Databricks Optimization
Databricks clusters continue running indefinitely after a job is completed unless users manually terminate them or an auto-termination policy is configured, leading to substantial usage charges for forgotten clusters that remain idle over time.
Enabling auto-termination policies to automatically shut down clusters after periods of inactivity can mitigate this issue.
Some guidelines include:
- Configure all interactive development clusters to auto-terminate after 30 minutes to 1 hour of inactivity as a safety net against neglected resources.
- For batch workload clusters like ETL jobs, set auto termination shortly after the batch window completes.
- Use the Jobs REST API to programmatically spin up and terminate clusters around job runtimes to minimize databricks costs.
- Set auto-termination to 0 for dedicated, long-running production clusters where uptime is critical. Rely on auto-scaling instead to manage databricks costs.
- Monitor cluster runtime reports/metris to identify resources that may be candidates for more aggressive termination policies of 15-30 minutes.
Check out this documentation to learn more about how to manage and configure clusters properly
Auto-termination is a powerful tool for optimizing Databricks costs and achieving Databricks optimization. So if you carefully follow these guidelines, you can make sure that your clusters are only running when they are needed and that you are not wasting money on unused resources.
3. Implement Enhanced Auto-Scaling for Dynamic Resource Provisioning—Databricks Optimization
Databricks Enhanced Auto-scaling is a more advanced form of auto-scaling that can help you optimize Databricks cluster costs and performance even further.It does this by automatically allocating cluster resources based on workload volume, with minimal impact to the data processing latency of your pipelines.
To leverage enhanced auto-scaling effectively:
- Set appropriate minimum and maximum cluster sizes: The minimum cluster size is the number of workers that will always be available for your pipeline, even during low workloads. The maximum cluster size is the maximum number of workers that can be allocated for your pipeline, even during high workloads. It's important to set these values appropriately to avoid overspending on unused resources during low workloads or underprovisioning resources and experiencing performance issues during high workloads.
- Monitor your workload and adjust autoscale settings as needed: Since pipeline workloads can vary over time, it is important to monitor ‘em and adjust autoscale settings accordingly. You can use the event log to monitor Enhanced Autoscaling events and the Delta Live Tables UI to view backlog metrics.
- Use the appropriate autoscale mode: Enhanced Auto Scaling has two modes: Legacy and Enhanced. The Legacy mode uses the old cluster autoscaling logic. The Enhanced mode uses more advanced auto scaling logic. For streaming workloads or optimizing costs, use the Enhanced mode.
- Consider using maintenance clusters: Maintenance clusters are good for pipelines that do not need continuous running. With a maintenance cluster enabled, Enhanced Autoscaling will scale the default cluster down to 0 workers when the pipeline is idle, which can save significant resources when the pipeline is unused.
So by carefully following these tips, you can use auto-scaling to effectively control the cost of Databricks and achieve Databricks optimization.
4. Leverage Spot Instances—Databricks Optimization
One of the most impactful ways to reduce compute costs in Databricks is to utilize discounted spot instances for your cluster nodes. This cost cutting strategy is crucial for Databricks optimization. All major cloud providers, including AWS, Azure, and GCP, offer spot or preemptible instances, which allow you to access unused capacity in their data centers for up to 90% less than regular On-Demand instance pricing.
Spot instances work on a market-driven model where supply and demand determine pricing, which fluctuates based on current utilization levels. When providers have excess capacity, they make it available via spot instances, and you bid for access. As long as your bid exceeds the fluctuating spot price, your instances remain available. However, if capacity tightens again and spot prices increase above your bid, your instances may be reclaimed with as little as few minutes notice.
This introduces the risk of unexpected termination of nodes, which can disrupt Databricks workloads. So the key is to implement strategies to build resilience against spot interruptions:
- Use Spot primarily for non-critical workloads where some delays or failures have lower impact. Avoid using Spot for production ETL pipelines or user-facing services.
- Configure spot instances to fallback to On-Demand instances automatically in case of termination, to minimize disruption, even if at somewhat higher cost.
- Structure notebooks, jobs, and code to handle partial failures by leveraging checkpointing, fault tolerance timeouts, etc.
- For cluster stability, ensure at least the driver node remains On-Demand while workers use Spot. Driver restarts can cause job failures.
- Use multiple instance pools and Types — if one Spot Type is interrupted due to demand changes, others may still continue unimpacted.
- Use Spot Instances for non-critical workloads like development, testing, and analytics, where interruptions have lower impact. Avoid using them for production ETL or SLA-sensitive tasks.
- Configure Spot Instances to fallback to On-Demand instances
- Use Spot Instances primarily for worker nodes. Use On-Demand for the driver node to maximize cluster stability.
- Monitor Spot price fluctuations and instance reclamation rates in different regions and instance types to optimize your use of Spot Instances.
5. Leverage Databricks Photon for Query Acceleration—Databricks Optimization
Databricks Photon is a query acceleration engine that can significantly improve the performance of Spark SQL queries, aiding in achieving Databricks optimization. It is a new, blazing-fast query engine that is developed by Databricks team to supercharge Spark SQL performance. Photon accelerates compute-heavy workloads like scanning large datasets or doing complex data writes without requiring you to change any code. You just upgrade your cluster's runtime to Photon, and queries start running faster.
In real-world tests, Photon can reduce query times by over 20% for many common jobs. And when queries finish faster, you obviously need fewer resources like CPUs and memory to process the same amount of data. Since compute costs are the biggest part of the Databricks bill, this improved throughput drops your costs. Photon zaps the most expensive piece of Databricks workloads.
To leverage Databricks Photon for query acceleration, you need to:
- Make sure that your cluster is running Databricks Runtime 9.1 LTS or above.
- Enable Photon acceleration when you create your cluster. You can do this by selecting the "Use Photon Acceleration" checkbox.
- Once Photon is enabled, it will automatically accelerate all SQL queries that are run on the cluster. You do not need to make any changes to your code.
Photon aids in achieving Databricks optimization by minimizing the amount of compute resources required to run your workloads, thereby leading to significant cost savings, especially for organizations that run large, complex Spark jobs.
Here are some additional quick tips for using Photon to achieve Databricks optimization:
- Focus usage on analytical workloads involving large table scans and complex expressions, which benefit most from vectorization.
- Monitor query metrics before and after switching to Photon to quantify performance speedup and resulting cost savings.
- Be aware that some jobs may slow down on Photon if they don’t vectorize well. Test rigorously before deploying to production.
So if you follow these tips carefully, you can maximize the benefits of Databricks Photon and achieve significant Databricks cost optimization for your Databricks workloads.
6. Right-Size Cluster Resources—Databricks Optimization
The configuration of compute clusters is one of the largest factors affecting the cost of Databricks. Databricks utilizes a consumption-based pay-per-usage pricing model based on Databricks DBU. Larger cluster configurations with more nodes and powerful instance types consume more DBUs, driving up hourly usage costs.
Overprovisioning clusters by allocating more resources than required for a workload is a common pitfall that leads to wasted Databricks costs. The key is to right-size clusters by monitoring usage patterns and configuring auto-scaling policies that automatically adjust cluster sizes to closely match workload demands.
Some best practices for right-sizing cluster resources to achieve Databricks optimization include:
- Enable auto-scaling on all clusters to automatically scale up and down based on metrics like CPU, memory, and I/O utilization. Set appropriate minimum and maximum thresholds for worker nodes.
- Monitor cluster utilization periodically to identify overprovisioned resources. Adjust cluster sizes downward if usage is consistently below 50-60% of the overall capacity.
- Establish cluster usage policies and educate users on optimal node counts and instance sizes for different workloads based on performance benchmarks. Limit users through cluster policies.
- Use horizontal auto-scaling to add nodes before vertical scaling to larger instance types which have higher DBU costs. Monitor for memory pressure signals before vertically scaling.
- For predictable workloads, schedule cluster startup and shutdown around usage patterns to minimize overall runtime.
7. Use Delta Lake for Storage Optimization—Databricks Optimization
Delta Lake—a fully open source storage layer that provides optimized data storage and management for Databricks' Lakehouse Platform. It extends Parquet data files by adding a transaction log that enables ACID transactions and scalable handling of metadata. Utilizing Delta Lake helps optimize Databricks costs in a significant way.
Delta Lake is fully compatible with Apache Spark APIs and is designed to integrate tightly with Structured Streaming. This allows using the same data copy for both batch and streaming operations, enabling incremental processing at scale.
Delta Lake is the default storage format for all operations in Databricks. Unless specified otherwise, all Databricks tables are Delta tables. Databricks originally developed Delta Lake and continues contributing actively to the open source project.
Many optimizations and products in Databricks' Platform leverage the guarantees of Apache Spark and Delta Lake. Delta Lake's transaction log has an open protocol that any system can use to read the log.
Now, let's talk about how using Delta Lake for storage optimization helps optimize costs in Databricks:
- Data Skipping: Delta Lake uses data skipping, leveraging statistics and metadata to skip unnecessary data during queries. Avoiding excess reads reduces data processed, accelerating performance and lowering costs.
- Compaction: Delta Lake automatically compacts, combining small files into larger ones. This reduces file numbers, improving read/write performance and reducing storage costs by minimizing small file overhead.
- Z-Ordering: Delta Lake supports Z-Ordering, organizing data files based on column values. Ordering data improves performance by reducing storage reads, saving costs.
- Schema Evolution: Delta Lake enables easy schema evolution over time without expensive, time-consuming migrations. This flexibility reduces costly transformations and simplifies data management.
- Time Travel: Delta Lake provides time travel, allowing access to historical data versions. This aids auditing, debugging, and error recovery without extra storage or duplication, which helps to achieve Databricks cost optimization.
8. Generate, Analyze and Monitor Usage Reports—Databricks Optimization
Generating, analyzing, and monitoring usage reports—that's a crucial strategy for Databricks optimization. By doing this, users can gain valuable insights into their Databricks usage patterns and can identify areas to optimize Databricks costs.
Here's how it helps:
- Identifying Costly Workloads: Usage reports provide the nitty-gritty on workloads running on Databricks, including costs. Analyzing these reports allows users to pinpoint workloads gobbling up their budget. This lets them focus on optimizing those specific workloads to trim costs.
- Resource Allocation Optimization: Usage reports illuminate how resources get allocated across workloads. Analyzing this info helps users to spot instances where resources are underutilized or overprovisioned. Right-sizing resources ensures organizations pay only for what they truly need.
- Monitoring Cost Trends: Usage reports provide historical data on Databricks costs over time. Tracking cost trends helps users/organizations to detect sudden spikes or oddities in usage patterns, enabling investigating the root causes of cost variations and taking corrective actions to optimize expenses.
- Chargeback and Showback: Usage reports can implement chargeback or showback within an organization. Providing detailed cost info to teams and departments builds awareness about the cost implications of Databricks usage. This motivates teams to mind their resource consumption and promotes Databricks cost optimization at a granular level.
- Cost Attribution: Usage reports enable attributing costs to specific projects, teams, or departments—helping understand the cost distribution across the organization, facilitating better cost management by identifying key cost drivers. Organizations can then work with stakeholders to optimize Databricks costs and allocate resources more efficiently.
9. Make Use of Databricks DBU Calculator to Estimate Costs—Databricks Optimization
Databricks DBU pricing calculator is super handy! Think of it like having your own personal cost simulation machine.
As we already mentioned, Databricks DBU is the core unit that Databricks uses to measure resource consumption and charge users. So the DBU pricing calculator allows you to estimate what a workload on Databricks might cost under different conditions.
For example, say your data team wants to analyze some user data to generate insights. You may start by testing out the workload on a small lite compute type and small instance. But how can you figure out the most cost-effective way to run this in production with much larger datasets?
Well, you can model different scenarios in the DBU pricing calculator by tweaking parameters — the instance types, plans (Standard, Premium and Enterprise), Cloud providers, number of nodes—and a whole lot more!! You can instantly see how your estimated DBU usage changes based on the configuration. And you can multiply this by DBU rate to get a cost estimate.
By simulating different DBU pricing configurations, you can answer questions like:
- Is it cheaper to select a compute type with lower DBU rate or use a Pro one with higher DBU rates?
- What is the cost impact of using spot instances instead of On-Demand ones?
- How does moving to a different region affect the estimated costs?
- Is it worth using the new M5 instances over the M4 ones considering the price difference?
- How many DBUs would a 100 node cluster for this workload use in production?
So by carefully modeling these scenarios, you can make decisions on the most cost-optimal configurations for your specific workloads.
The best part is that you can tinker and simulate to your heart's content since it's just estimates at this stage! You don't have to take on the risk of directly tweaking production clusters.
So in summary, the DBU calculator is an extremely useful tool to experiment and answer your "what-if" questions on Databricks costs.
10. Carefully Monitor Databricks Costs with Chaos Genius—Databricks Optimization
Juggling multiple cloud services or big data platforms can make your head spin, especially when it comes to cost optimization. It's hard enough tracking one vendor, let alone having visibility across Snowflake, Databricks and more!! Suddenly that small cluster you spun up is costing a fortune without you even realizing it. Before you know it, your budget has exploded and your entire team is asking tough questions. Sound familiar?
This is exactly where Chaos Genius comes in. Think of it as your trusty co-pilot, giving you an aerial view of your entire Databricks environment. It lets you seamlessly monitor your Databricks costs alongside your other big data warehouse costs like Snowflake. The key is that Chaos Genius provides granular visibility – you can drill down into specific costs like clusters, regions, usage over time. You can track things like how much an avg production job is costing on Databricks.
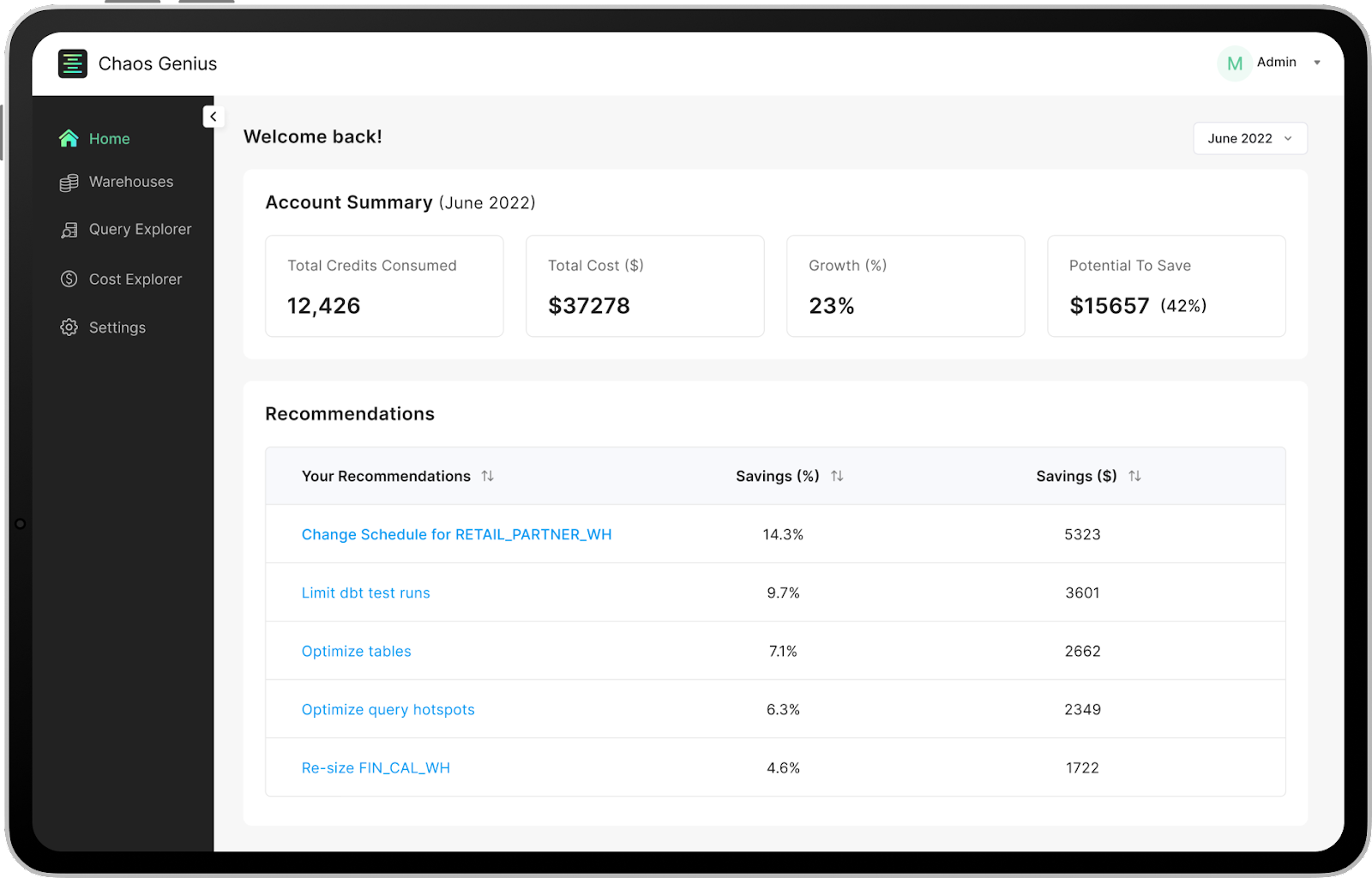
Beyond just visibility, Chaos Genius also makes it easy to set spending policies, notifications and alerts. You can set a threshold for the maximum monthly Databricks spend. Chaos Genius will then send you an alert via email or Slack as soon as that threshold is crossed, giving you the full opportunity to quickly take action when costs are unexpectedly high.
Chaos Genius also makes recommendations to optimize your costs. It can analyze your workloads and suggest right-sizing cluster recommendations to save massive costs. The system can also identify usage patterns and expensive queries that could be also improved.
Welp! The bottom line is that a tool like Chaos Genius gives you a complete bird's eye view of your overall usage. Moree importantly, it gives you the power to stay on top of Databricks spend by tracking it closely, setting guardrails, getting alerts, and identifying key Databricks optimization areas.
Therefore, instead of getting blasted with surprises in your monthly Databricks costs, you can effectively use Chaos Genius to manage your Databricks environment and reduce massive costs. No more surprises, no more scrambling. Just smooth flying with Chaos Genius by your side. Tldr; Chaos Genius is your trusty co-pilot for Databricks cost management, providing granular visibility and recommendations to optimize Databricks costs. Pretty awesome, right?
Bonus—Regularly Review and Optimize Databricks costs
Databricks costs piling up endlessly without scrutiny is a certain way to get nasty surprises. The key is to make Databricks optimization a continuous process rather than a one-time initiative.
This is where doing quarterly reviews and tuning of your Databricks environment can be invaluable.
Here are some tips that you can follow to achieve Databricks cost optimization:
- Conduct quarterly reviews: Hold Databricks optimization reviews every quarter to discuss usage, costs, trends, initiatives, and roadmaps.
- Assign owners: Have data teams or the data engineers take ownership of optimizing high-cost Databricks workloads identified during reviews by deploying frequent improvements.
- Develop optimization roadmap: Create a roadmap focused on Databricks optimization opportunities like storage migration, autoscaling adoption, reserved instance planning etc…
- Track progress via Key metrics: Establish robust Databricks optimization goals and metrics like reducing cost-per-production-job, lowering query latency, etc.
- Report progress: Have regular check-ins on Databricks optimization progress. Share successes and best practices across team members.
- Incentivize and reward engineers: Consider incentivizing developers and engineers for contributing Databricks optimizations that deliver material cost savings.
So that's it! If you follow these strategies for Databricks cost optimization in a structured manner, you can build a comprehensive framework to manage your Databricks spending efficiently.
Conclusion
Databricks provides powerful big data analytics capabilities, but ineffective optimization can lead to massively inflated costs. In this article, we covered crucial techniques for optimizing your Databricks workload and controlling costs to achieve Databricks optimization.
In this article, we've outlined 10 practical cost reduction strategies for Databricks Optimization. Here's a summary of what we covered:
- Selecting optimal instance types
- Scheduling auto-termination of idle resources
- Implementing auto-scaling for dynamic provisioning
- Leveraging spot instances
- Utilizing Databricks Photon for query acceleration
- Right-sizing cluster resources
- Optimizing storage with Delta Lake
- Generating, analyzing, and monitoring usage reports
- Estimating costs with the DBU calculator
- Monitoring and optimizing Databricks costs with Chaos Genius
So, with the help of these strategies, you can fully harness Databricks' power to accelerate business insights while keeping your spending firmly under control. Consider these optimization best practices in your flight training; with enough practice, you'll master Databricks cost management and unlock its full potential.
FAQs
How can you estimate Databricks costs?
Databricks provides a DBU Calculator tool to model hypothetical workloads and estimate likely DBU usage. This projected DBU usage can be multiplied by DBU rates to estimate overall costs.
How does instance type selection impact Databricks costs?
Choosing optimal instance types aligned to workload needs minimizes costs. Overpowered instances waste money while underpowered ones hurt performance.
How can auto-scaling help to achieve Databricks optimization?
Auto-scaling adjusts cluster sizes based on metrics like CPU usage, reducing overprovisioning. Setting min and max thresholds avoids under/over-provisioning.
How do Spot instances help lower Databricks costs?
Spot instances provide discounted compute capacity, with cost savings of 60-90%. Use fault tolerance and multiple instance types to minimize disruption.
How does Photon helps to achieve databricks optimization?
Photon accelerates Spark SQL query performance, reducing compute resources needed. Faster queries mean lower DBU usage and costs.
How can right-sizing clusters cut Databricks costs?
Monitoring usage and configuring optimal clusters sized to match workloads avoids over provisioning waste.
Why analyze Databricks usage reports?
Reports provide insights into usage patterns, helping identify costly workloads to optimize and improve resource allocation.
Should you use Chaos Genius to monitor Databricks costs?
Yes, it provides granular visibility into usage and Databricks costs. Alerts notify on thresholds and it recommends key areas to achieve Databricks optimizations.
How often should you review Databricks costs?
Conduct monthly/quarterly cost reviews to identify optimization opportunities. Track progress on savings initiatives.
When should you enable auto-termination for Databricks clusters?
Configure auto-termination shortly after job completion to avoid forgotten clusters accruing charges.
How can you minimize disruption from Spot instance termination?
Use multiple instance types and enable auto-fallback to On-Demand. Keep driver node On-Demand for reliability.
Should you use Spot instances for critical workloads?
No, use Spot primarily for non-critical workloads where failures have lower impact.
How does scheduling cluster start/stop help cut costs?
For predictable workloads, schedule cluster launch and shutdown around usage patterns to minimize runtime.
When should you vertically scale clusters to larger instances?
Vertically scale only when metrics indicate sustained memory pressure. Horizontal scaling is preferred.















