



























Delta Lake is an open source storage layer that brings ACID transactions, scalability, and performance to Apache Spark and big data workloads. It is designed to work hand-in-hand with Spark APIs, providing a more reliable and performant data lake. At the very core of Delta Lake are Delta Tables—these provide reliable structured data storage with rock-solid features like schema enforcement, data versioning, and time travel capabilities. As data keeps piling up, working directly with these large Delta Tables can get a bit messy and error-prone. This is where Delta Views come to the rescue—they enable creating virtual views over Delta Tables without modifying the underlying data. Delta Views offer a flexible layer for accessing and presenting data with operations like filtering, transforming, joining tables while ensuring integrity of the base Delta Tables, allowing real-time data access, controlled access management, and simplified data governance.
In this article, we will cover everything you need to know about Delta Views; we will deep dive into what they are, their benefits, and how to create, use, and manage them effectively. And then we will also compare Delta Views with traditional database views and Delta tables, and provide step-by-step examples to help you get started with this powerful feature.
What Are Delta Views?
Delta Views are logical views created over Delta tables, and they function similarly to traditional database views. They are virtual tables that do not store data themselves but represent the result set of an SQL query executed over one or more Delta tables. Delta Views contain rows and columns, and the fields in a view are derived from the fields of the underlying Delta tables.
Unlike Delta tables, Delta Views do not store data themselves. Instead, they pull data from the underlying Delta tables they are based on, meaning that any changes made to the underlying Delta tables are immediately reflected in the corresponding views.
While Delta Views share some similarities with traditional database views, they also offer unique advantages due to their tight integration with Delta Lake and Apache Spark.
Here are some of the key benefits of using Delta Views:
- Delta Views allow you to provide users with access to a subset of data, safeguarding sensitive information by hiding specific columns or rows from certain users or groups.
- Delta Views can be used to apply consistent transformations to your data, ensuring that users have access to a unified and pre-processed representation of the data, regardless of the underlying table structure.
- Delta Views can hide the complexity of your data by abstracting the underlying table structure, making it easier for users to work with and understand the data.
- Delta Views can be optimized for particular workloads or queries, which can enhance performance and efficiency.
- Delta Lake's schema evolution capabilities extend to Delta Views, allowing you to modify the view's schema without impacting the underlying Delta tables.
What Is the Difference Between Delta Views and Delta Tables?
Delta Views and Delta Tables are both part of the Delta Lake ecosystem, they serve different purposes and have distinct characteristics. Here's a comparison between the two of ‘em:
| Delta Views | Delta Tables |
| Delta Views do not store data; they pull data from underlying Delta tables | Delta tables store data directly on the object store in a columnar format optimized for analytics workloads |
| Delta Views are defined by SQL statements or DataFrame transformations | Tables are defined by a physical schema and the actual data they contain |
| Delta Views provide a virtual representation of data, allowing for real-time and dynamic querying. | Delta Tables store the actual, physical data that can be queried directly. |
| Automatically reflect changes made to the underlying Delta Tables. | Support direct data manipulation through insert, update, and delete operations. |
| Delta Views inherit schema changes from underlying tables | Tables can have their schema evolved using Delta Lake's schema evolution capabilities |
| Delta Views can be used to control access to specific subsets of data | Access control can be applied at the table level |
| Delta Views can be optimized for specific workloads or queries | Tables store data in a columnar format optimized for analytical workloads |
Step-By-Step Guide to Create and Manage Delta Views
Delta Views can be created and managed using either SQL or the Spark DataFrame. In this guide, we'll provide step-by-step examples for both approaches, using a sample student data table as our reference.
Step 1—Creating Delta Views in Delta Lake
Before we can create Delta Views, we need to have an existing Delta table. Let's start by creating a Delta table named student_information with the following schema:
- student_id: Unique ID for each student
- name: Student's name
- age: Student's age
- grade: Student's curr. grade
- address: Student's home address
We can create this Delta table using SQL or the DataFrame.
Let’s create student_information Delta table and insert some dummy data into it:
Using SQL:
CREATE TABLE student_information(
student_id INT,
name STRING,
age INT,
grade INT,
address STRING
)
USING DELTA
PARTITIONED BY (grade)
LOCATION '/user/hive/warehouse/studet_information';
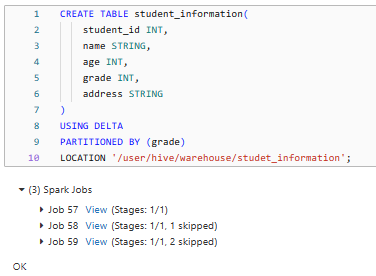
First we created the student_information Delta table with the specified schema and partition it by the grade column and then we specify the location where the Delta table will be stored (/path/to/….).
INSERT INTO student_information VALUES
(1, 'Elon Musk', 20, 10, 'Small st'),
(2, 'Jeff Bezos', 21, 9, 'Elm Ave'),
(3, 'Mark Zuck', 22, 11, 'Oak Rd'),
(4, 'Larry Page', 12, 10, 'Cityville'),
(5, 'Sergey Bin', 27, 8, 'Banglore'),
(6, 'Sarah Conor', 20, 12, 'Delhi'),
(7, 'Christopher Nolan', 35, 9, 'Hyderabad'),
(8, 'Bruce Wayne', 90, 11, 'Walnut Rd'),
(9, 'Chris Pratt', 26, 10, 'Aspen St'),
(10, 'Tony Stark', 25, 9, 'New York');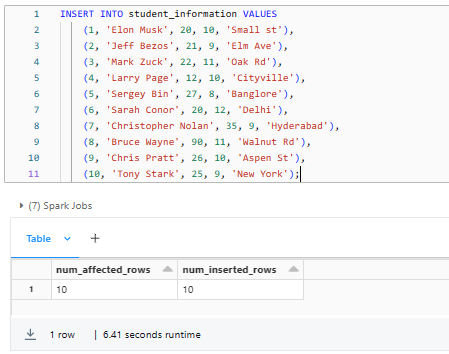
Next, we inserted 10 rows of dummy data into the student_information table.
Once you execute these SQL statements, you will have a Delta table named student_information with 10 rows of sample data, partitioned by the grade column.
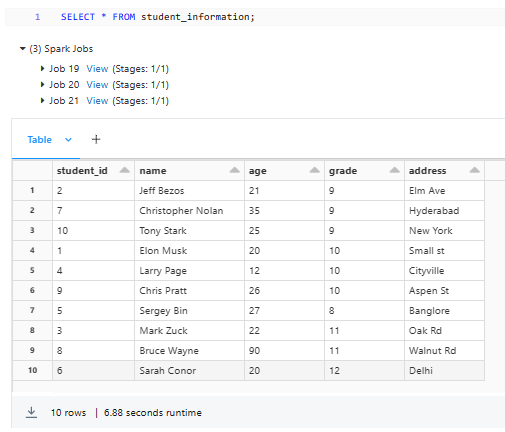
This is how your student_information table should look:
Alternatively, you can also create the same Delta table and insert dummy data using the Spark DataFrame. To do so:
%python
from pyspark.sql.types import StructType, StructField, IntegerType, StringType
# Define the schema
schema = StructType([
StructField("student_id", IntegerType(), False),
StructField("name", StringType(), False),
StructField("age", IntegerType(), False),
StructField("grade", IntegerType(), False),
StructField("address", StringType(), False)
])
# Create the DataFrame with dummy data
data = [
(1, 'Elon Musk', 20, 10, 'Small st'),
(2, 'Jeff Bezos', 21, 9, 'Elm Ave'),
(3, 'Mark Zuck', 22, 11, 'Oak Rd'),
(4, 'Larry Page', 12, 10, 'Cityville'),
(5, 'Sergey Bin', 27, 8, 'Banglore'),
(6, 'Sarah Conor', 20, 12, 'Delhi'),
(7, 'Christopher Nolan', 35, 9, 'Hyderabad'),
(8, 'Bruce Wayne', 90, 11, 'Walnut Rd'),
(9, 'Chris Pratt', 26, 10, 'Aspen St'),
(10, 'Tony Stark', 25, 9, 'New York')
]
student_information_df = spark.createDataFrame(data, schema)
# Write the DataFrame to a Delta table
student_information_df.write.format("delta").partitionBy("grade").save("/user/hive/warehouse/student_information_dataframe")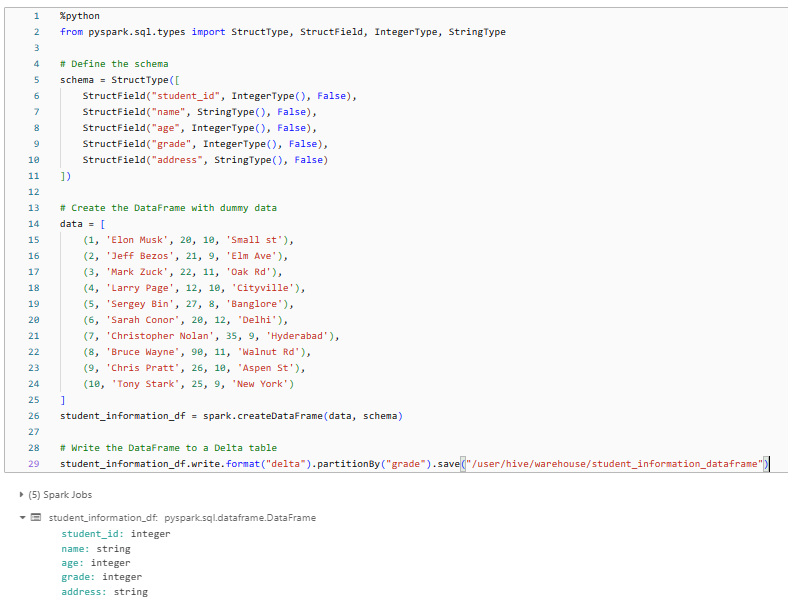
As you can see, we first define the schema for the table using the StructType and StructField classes from pyspark.sql.types. Then, we create a list of tuples containing the dummy data.
Next, we create a Spark DataFrame, student_information_df, from the list of tuples and the defined schema using spark.createDataFrame.
Finally, we write the student_information_df DataFrame to a Delta table using the write.format("delta").partitionBy("grade").save("/path/to/….") method, which creates the Delta table and partitions it by the grade column.
Once you execute this Python code, you will have the Delta table with sample data, partitioned by the grade column.
This is how your delta table should look:
%python
student_information_df = spark.read.format("delta").load("/user/hive/warehouse/student_information_dataframe")
display(student_information_df)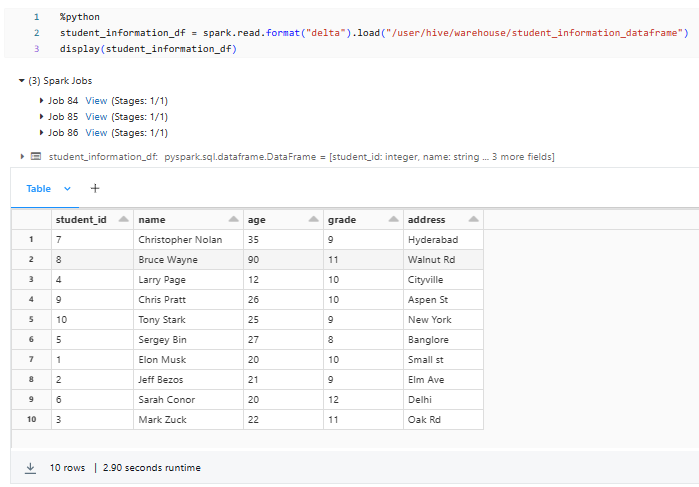
Now that you have finished creating the Delta table, you can proceed to the steps below, where we will create Delta Views.
Creating a Delta View Using SQL
To create a Delta View using SQL, you can use the CREATE VIEW statement. For example, let's create a view called student_grades that shows the student's name, grade (greater than or equal to 5), and age, ordered by grade descending:
CREATE VIEW student_grades AS
SELECT name, grade
FROM student_information
WHERE grade >= 9
ORDER BY grade DESC;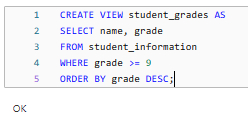
This SQL statement creates a view called student_grades that selects the name, grade, and age columns from the student_information Delta table.
Creating a Delta View Using the Spark DataFrame
Alternatively, you can create a Delta View using the Spark DataFrame. First, we need to load the student_information_dataframe Delta table into a DataFrame:
%python
student_information_df = spark.read.format("delta").load("/user/hive/warehouse/student_information_dataframe")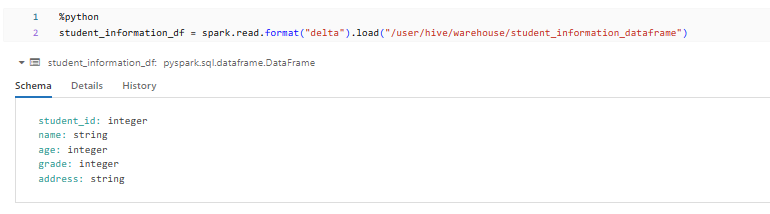
Next, we filter for grades >= 9, select only the name and grade columns, order them by grade in descending order, and finally create a Delta View called student_grades_df_view from the filtered DataFrame.
%python
from pyspark.sql.functions import desc, col
filtered_grade = (
student_information_df
.filter(col("grade") >= 9)
.select("name", "grade")
.orderBy(desc("grade"))
)
filtered_grade.createOrReplaceTempView("student_grades_df_view")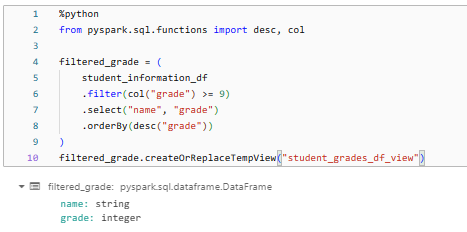
Step 2—Using/Querying Delta Views in Delta Lake
Now that you've created a Delta View, you can query it just like you would query a regular Delta table. This means you can use SQL or the DataFrame to retrieve data from the Delta view.
Querying a Delta View Using SQL
To query a Delta View using SQL, you can execute a SELECT statement against the view:
SELECT *
FROM student_grades
WHERE grade = 10;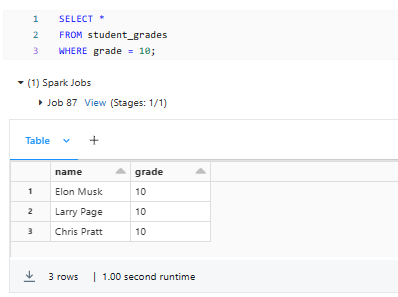
As you can see, this SQL statement retrieves all rows from the student_grades view where the grade column is equal to 10.
Querying a Delta View Using the DataFrame
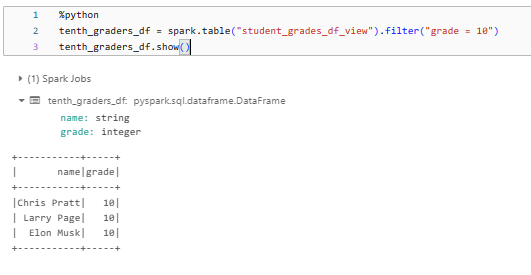
To query a Delta View using the DataFrame, you first need to access the Delta View using spark.table("view_name"). This retrieves a DataFrame from the Delta View. You can then apply standard DataFrame operations like filtering and selecting columns on this DataFrame. The following code gets a Delta View named "student_grades_df_view", filters for 10th grade students.
%python
tenth_graders_df = spark.table("student_grades_df_view").filter("grade = 10")Finally, we can use show() method on the tenth_graders_df DataFrame, which prints the contents of the DataFrame to the console, which allows you to preview the data for the 10th-grade students from the original "student_grades_df_view" Delta View.
%python
tenth_graders_df.show()
Step 3—Modifying/Altering Delta Views in Delta Lake
Delta Views can be modified or altered to change their structure or definition. This can be done using the ALTER VIEW statement in SQL or the Spark DataFrame.
Altering a Delta View Using SQL
To alter a Delta View using SQL, you can execute the ALTER VIEW statement. For example, let's add the address column to the student_grades view:
ALTER VIEW student_grades AS
SELECT name, grade, age, address
FROM student_information;This is how your student_grades should look:
SELECT * FROM student_grades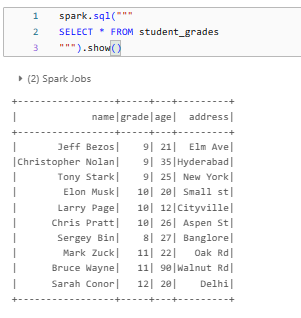
As you can see, this SQL statement modifies the student_grades view to include the address column from the student_infromation Delta table.
Altering a Delta View Using the DataFrame
To alter a Delta View using the DataFrame, you first need to create a new DataFrame with the desired schema or transformations. The provided code snippet does the following:
new_student_grades_df = student_information_df.select("name", "grade", "age", "address")First we start with an existing DataFrame student_information_df and then we use the select method to create a new DataFrame new_student_grades_df that contains only the specified columns: "name", "grade", "age", and "address".
Next, we call the createOrReplaceTempView method on the new_student_grades_df DataFrame to create (or replace if it already exists) a temporary view named "student_grades_df_view" based on the schema and data of the new_student_grades_df DataFrame.
new_student_grades_df.createOrReplaceTempView("student_grades_df_view")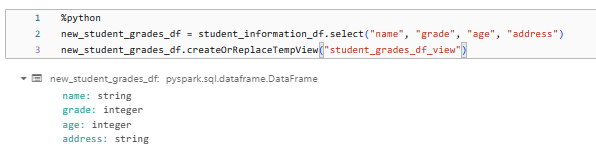
Step 4—Dropping Delta Views in Delta Lake
If you no longer need a Delta View, you can drop it using the DROP VIEW statement in SQL or the DataFrame.
Dropping a Delta View Using SQL
To drop a Delta View using SQL, you can execute the DROP VIEW statement:
DROP VIEW student_grades;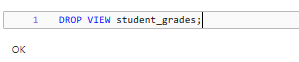
This SQL statement drops the student_grades view from the Delta Lake.
Dropping a View Using the Spark DataFrame
To drop a Delta View using the Spark DataFrame, you can use the spark.catalog.dropTempView() method. But, this method only drops temporary views created within the current Spark session. If you want to drop a global, persistent view, you'll need to use SQL instead.
Here's an example of dropping a temporary view using the DataFrame:
spark.catalog.dropTempView("student_grades_df_view")
This above code will drop/delete the temporary view named student_grades_df__view from the current Spark session.
Note: Dropping a delta view does not affect the underlying Delta table. It only removes the view definition, and the data in the Delta table remains intact.
Always be very cautious when dropping views, especially if they are being used by other applications or processes. Make sure that the Delta view is no longer needed before dropping it to avoid any unintended consequences.
Conclusion
Delta Views are a powerful feature of Delta Lake that provide a flexible and efficient way to structure and control access to your data stored in Delta tables. Think of it like having a assistant who knows exactly where to find the specific details you need from that big messy table. You can ask your assistant ( Delta View) to only show you certain columns of data, or to filter out irrelevant rows based on some criteria. That way, you don't have to sort through everything yourself—the view does everything for you.
In this article, we have covered:
- What Are Spark Delta Views?
- What Is the Difference Between Delta Views and Delta Tables?
- Step-By-Step Guide to Create and Manage Delta Views
…and so much more!
Imagine you have a huge dataset stored in a Delta table, kind of like a massive pile of information. Delta Views help you organize and access that information in a user-friendly way. Instead of digging through the entire pile every time you need something, you can create custom "views" that give you a filtered and structured look at just the pieces of data you're interested in.
FAQs
How is a Delta View different from a Delta Table?
Unlike Delta Tables that store data directly, Delta Views do not store data themselves. Instead, they pull data from underlying Delta tables.
What are the benefits of using Delta Views?
Delta Views provide data access control, apply consistent transformations, hide complexity, optimize for workloads, and support schema evolution.
Can Delta Views be used to modify data in underlying Delta tables?
No, Delta Views are read-only and cannot be used to modify data in the underlying Delta tables directly.
How are Delta Views created in Delta Lake?
Delta Views can be created using SQL's CREATE VIEW statement or via the Spark DataFrame.
Can Delta Views be created over multiple Delta tables?
Yes, Delta Views can be created over one or more underlying Delta tables.
How are Delta Views queried?
Delta Views can be queried using SQL or the Spark DataFrame, just like querying a regular Delta table.
Can Delta Views be altered or modified?
Yes, Delta Views can be altered or modified using SQL's ALTER VIEW statement
How are Delta Views dropped or deleted?
Delta Views can be dropped using SQL's DROP VIEW statement or via the Spark DataFrame API's dropTempView() method.
Do changes in underlying Delta tables get reflected in Delta Views?
Yes, any changes made to the underlying Delta tables are immediately reflected in the corresponding Delta Views.
Can Delta Views inherit schema changes from underlying tables?
Yes, Delta Views inherit schema changes from the underlying Delta tables they are based on.
Are Delta Views persisted or temporary?
Delta Views can be either persisted (global) or temporary (session-scoped), depending on how they are created.
Can access control be applied to Delta Views?
Yes, Delta Views allow controlling access to specific subsets of data by granting view-level permissions.
Are Delta Views optimized for specific workloads?
Yes, Delta Views can be optimized for specific workloads or queries to improve performance and efficiency.
How do Delta Views compare to traditional database views?
Delta Views share some similarities with traditional database views but offer unique advantages due to their integration with Delta Lake and Apache Spark.
Can Delta Views be partitioned or bucketed?
Yes, Delta Views inherit partitioning and bucketing from the underlying Delta tables they are based on.
Are Delta Views supported in all Apache Spark language APIs?
Yes, Delta Views can be created and managed using Scala, Python, Java, and R Spark APIs.
Can Delta Views be nested (i.e., can a view be based on another view)?
Yes, Delta Views can be nested. You can create a view based on the result set of another view, allowing you to build complex logical representations of your data.
Can Delta Views be created over non-Delta data sources?
No, Delta Views can only be created over Delta tables, not other data sources.
Do Delta Views support time travel queries?
Yes, Delta Views inherit Delta Lake's time travel capabilities and can query historical snapshots of data.
Can Delta Views be used in Spark Structured Streaming applications?
Yes, Delta Views can be used as sources or sinks in Spark Structured Streaming applications.
Can Delta Views be partitioned or bucketed?
No, Delta Views cannot be partitioned or bucketed directly. But, if the underlying Delta tables are partitioned or bucketed, the views will inherit those properties.















