




























Over the past few years, the surge in AI and ML technologies has been extraordinarily remarkable, largely driven by the availability of vast datasets, powerful computing resources, and advanced algorithms. A significant breakthrough in this field is the development of large language models (LLMs), which have significantly enhanced natural language processing capabilities. But note that deploying these complex models at scale poses a significant challenge, including the need for specialized hardware and a large amount of computational resources. Here's where Databricks Model Serving comes in. Announced as generally available back in 2023, it provides a seamless, serverless solution for deploying and managing AI models efficiently at scale. Integrated deeply with the Databricks Platform, it allows users to manage the complete ML lifecycle—from data ingestion and training to deployment and monitoring—through a unified interface. Databricks Model Serving supports a wide range of model types, including custom-built, open-source, external, and pre-trained models, and makes deployment easier with automated container builds and infrastructure management.
In this article, we will cover everything you need to know about Databricks Model Serving—its features, pricing, limitations, how it addresses the challenges of building real-time machine learning systems, and a step-by-step guide to deploying LLMs using it.
What Is Model Serving?
Deploying machine learning models can be difficult since it sometimes requires managing distinct serving infrastructures such as Kubernetes and various orchestration tools, which may not be readily accessible to all ML developers. One key complexity is model versioning, which involves ensuring that the serving system uses the most recent model versions as they are generated and accurately routing requests to the relevant versions.
Databricks Model Serving streamlines this process by integrating directly with the Databricks MLflow Model Registry. This registry supports models from multiple machine learning libraries allowing you to manage multiple model versions efficiently. Within the registry, you can easily maintain multiple versions of a model, review them, and promote them to different lifecycle stages such as Staging and Production.
Simplified ML Deployments—Through Databricks Model Serving
Databricks Model Serving provides a unified interface to deploy, govern, and query AI models, making it easier to handle the complexities of model serving. Each model you serve is accessible as a REST API, which can be seamlessly integrated into web or client applications. The service guarantees high availability and low latency and automatically scales to meet changes in demand, optimizing infrastructure costs while maintaining performance.
Is the Databricks Model Serving Serverless?
Yes, Databricks Model Serving is a serverless offering, which means that users do not need to provision or manage any underlying infrastructure. The service automatically scales up or down to meet the demand, eliminating the overhead of infrastructure management and allowing users to focus solely on their ML models and applications.
What are the Key Features of Databricks Model Serving?
Databricks Model Serving offers a comprehensive suite of features that streamline the deployment and management of AI models, enhancing operational efficiency and performance.
1) Elimination of Management Overhead with Serverless Deployment. As a serverless solution, Databricks Model Serving eliminates the need to provision, manage, and scale infrastructure resources. Users can deploy machine learning models without worrying about underlying infrastructure, reducing operational complexity and accelerating time-to-market.
2) High Availability and Reliability. Designed for high availability and reliability, Databricks Model Serving guarantees that models are always accessible and responsive. The service includes automated failover and recovery mechanisms, minimizing downtime and ensuring continuous service.
3) Simplified Deployment for All AI Models. Databricks Model Serving provides a unified interface for deploying and querying various types of AI models—custom models, open-source models, and pre-trained models through Foundation Model APIs. This approach simplifies deployment processes, enabling users to leverage a diverse range of models without needing separate deployment pipelines.
4) Unified Management for All Models. Organizations can manage all deployed models from a single, centralized interface, including monitoring model performance, setting usage limits, and controlling access permissions. This central management makes sure effective governance and oversight of all models.
5) Governance and Access Control. Databricks Model Serving provides complete governance and access control capabilities. Organizations can manage permissions and enforce access limitations in accordance with their security and compliance standards, assuring that critical models and data are only accessible to authorized users and applications.
7) Automatic Scaling to Handle Heavy Demand. One of the primary benefits of Databricks Model Serving is its ability to autonomously scale up or down in response to incoming traffic and workload needs. This guarantees that models are available and responsive during periods of high traffic, eliminating the need for manual intervention or over-provisioning resources.
8) Data-Centric Models with Integration with Databricks Feature Store. Databricks Model Serving integrates seamlessly with the Databricks Feature Store, enabling organizations to build and deploy data-centric models that leverage up-to-date feature data. This integration makes it easier to incorporate real-time data into models, resulting in greater accuracy and relevance.
9) Very Cost-Effective. As a serverless offering, Databricks Model Serving has a pay-as-you-go pricing approach, allowing enterprises to pay only for the resources they use. This cost-effective method removes the need for over-provisioning resources, lowering the overall operational expenses involved with deploying and operating AI models.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

What Are the Hurdles in Building Real-Time Machine Learning Systems?
Real-time machine learning (ML) systems are revolutionizing how businesses operate—enabling immediate predictions and actions based on live data. Applications like chatbots, fraud detection, and personalized recommendations rely on these systems to deliver instant, accurate responses, thereby improving customer experiences, increasing revenue, and limiting risk.
However, building and maintaining real-time ML systems presents several significant challenges:
1) Latency and Throughput Requirements
Real-time systems demand low latency and high throughput. Any delay can degrade user experience or lead to missed opportunities. Achieving this requires sophisticated, high-performance infrastructure capable of processing and responding to data in milliseconds.
2) Scalable Serving Infrastructure
The infrastructure must scale seamlessly to handle varying loads. This includes not just the model serving layer but also the data pipelines that feed real-time features into the models. Ensuring scalability while maintaining low latency is a complex balancing act.
3) Feature Engineering in Real-Time
Features must be computed and updated in real time to reflect the latest state of the system. This involves stream processing frameworks and real-time databases, which can be intricate to design and manage. Ensuring consistency and accuracy of features in a real-time context adds another layer of complexity.
4) Monitoring and Logging
Continuous monitoring is essential to detect anomalies, drift, or degradation in model performance. Setting up effective monitoring for real-time systems is challenging because it requires fine-grained, real-time insights into both the data and model predictions.
5) Automated Deployment and CI/CD Pipelines
Real-time ML systems need automated deployment mechanisms to ensure models are updated frequently and reliably without downtime. Implementing robust CI/CD pipelines for ML models that handle real-time data streams adds to the operational complexity.
6) Model Retraining and Versioning
Models must be retrained regularly to adapt to new data patterns. Automating this process—while ensuring seamless integration and minimal disruption to the live system—is a significant challenge. Effective versioning and rollback strategies are also crucial to maintain system stability.
7) Data Quality and Governance
Maintaining the quality of incoming data is critical. Real-time systems frequently consume data from numerous sources, which can vary in quality. To make sure that the model's predictions remain accurate, robust data validation and governance methods must be implemented.
8) Integration with Existing Systems
Real-time ML systems need to integrate seamlessly with existing business systems and workflows. This requires careful planning and often custom solutions to bridge gaps between legacy systems and modern ML infrastructure.
Databricks addresses these challenges with Databricks Model Serving—the first serverless real-time serving solution developed on a unified data and AI platform. By leveraging Databricks, businesses can build scalable, low-latency ML systems with integrated feature engineering, automated deployment, robust monitoring, and seamless model retraining, all while maintaining high data quality and governance standards.
Databricks Model Serving Pricing
Databricks Model Serving and Feature Serving pricing varies based on the cloud provider (AWS, Azure, or Google Cloud Platform) and the chosen plan (Premium or Enterprise).
AWS Databricks Pricing (US East (N. Virginia)):
Premium plan:
- Model Serving and Feature Serving: $0.070 per DBU (Databricks Unit), including cloud instance cost
- GPU Model Serving: $0.07 per DBU, includes cloud instance cost
Enterprise plan:
- Model Serving and Feature Serving: $0.07 per DBU, including cloud instance cost
- GPU Model Serving: $0.07 per DBU, includes cloud instance cost
Azure Databricks Pricing (US East region):
Premium Plan(Only plan available):
- Model Serving and Feature Serving: $0.07 per DBU, including cloud instance cost
- GPU Model Serving: $0.07 per DBU, includes cloud instance cost
GCP Databricks Pricing:
Premium Plan (Only plan available):
- Model Serving and Feature Serving: $0.088 per DBU, including cloud instance cost
Model Serving: Allows you to serve any model with high throughput, low latency, and autoscaling. The pricing is based on concurrent requests.
Feature Serving: Enables you to serve features and functions with low latency. The pricing is also based on concurrent requests.
GPU Model Serving: Provides GPU-accelerated compute for lower latency and higher throughput on production applications. The pricing is based on GPU instances per hour.
GPU Model Serving DBU Rate
| Instance Size | GPU configuration | DBUs / hour |
|---|---|---|
| Small | T4 or equivalent | 10.48 |
| Medium | A10G x 1GPU or equivalent | 20.00 |
| Medium 4X | A10G x 4GPU or equivalent | 112.00 |
| Medium 8x | A10G x 8GPU or equivalent | 290.80 |
| XLarge | A100 40GB x 8GPU or equivalent | 538.40 |
| XLarge | A100 80GB x 8GPU or equivalent | 628.00 |
It's important to note that Databricks Model Serving automatically scales up or down based on the incoming traffic and workload demands. This means that you only pay for the resources you consume, ensuring cost-effectiveness and eliminating the need for over-provisioning resources.
For more detailed pricing information and to explore various pricing scenarios, see Databricks Pricing article.
Why Use Databricks Model Serving?
While there are several reasons to consider using Databricks Model Serving, here are some of the key advantages and benefits it offers:
1) Unified Interface to Deploy Machine Learning model and Manage it
Databricks Model Serving provides a unified interface for managing and querying all models from one location. Whether your models are hosted on Databricks or externally, you can query them with a single API.
2) Securely Customize Models with Private Data
Built on a robust Data Intelligence Platform, Databricks Model Serving integrates seamlessly with the Databricks Feature Store and Databricks Vector Search. This integration simplifies the process of incorporating features and embeddings into your models. You can fine-tune models with proprietary data for enhanced accuracy and contextual understanding, and deploy them effortlessly.
3) Govern and Monitor Models
The Databricks Model Serving UI provides centralized management for all model endpoints, including those hosted externally. This allows you to manage permissions, set usage limits, and monitor model quality from a single interface. These features ensure secure and controlled access to both SaaS and open LLMs within your organization while maintaining necessary guardrails.
4) Cost-effective and Scalable
Databricks has implemented numerous optimizations to guarantee optimal throughput and low latency for large models. The endpoints automatically scale up or down in response to demand, reducing infrastructure costs and optimizing performance. This dynamic scaling ensures that you only pay for the resources you use, providing a cost-effective solution for model serving.
5) Ensure Reliability and Security
Designed for high-availability and low-latency production use, Databricks Model Serving can support over 25,000 queries per second with an overhead latency of less than 50 milliseconds. Multiple layers of security protect serving workloads, ensuring a secure and reliable environment for even the most sensitive tasks. This strong security framework makes sure your models and data are secure and comply with regulatory requirements.
How to Enable Model Serving for Your Databricks Workspace?
To use Databricks Model Serving, serverless compute must be enabled in your workspace. This process requires account admin access. Here’s a step-by-step guide to make sure your workspace is ready for Model Serving.
Step 1—Verify Serverless Compute
If your Databricks account was created after March 28, 2022, serverless compute should be enabled by default. You can verify this in your account settings.
Step 2—Access the Account Console
As an account admin, navigate to the account console settings in your Databricks workspace.
Step 3—Enable Serverless Compute
In the account console, go to the "Feature Enablement" tab.
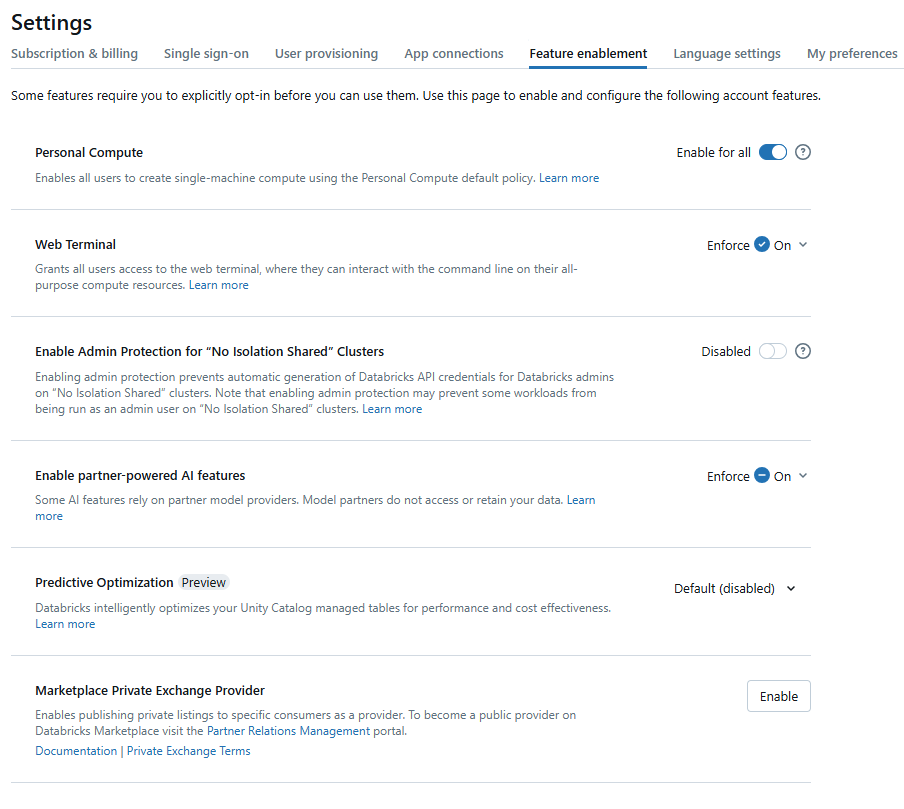
If serverless compute are not yet enabled, you will see a banner at the top of the page prompting you to accept the additional terms and conditions.
- Read the Terms: Carefully read the terms and conditions presented in the banner.
- Accept the Terms: Click "Accept" to enable serverless compute.
Step 4—Confirm Enablement
Once you have accepted the terms, serverless compute will be enabled for your workspace. There are no additional steps required to start using Databricks Model Serving.
Step-by-step guide to Deploy Large Language Models using Databricks Model Serving
Deploying large language models (LLMs) using Databricks Model Serving is straightforward. Here are the steps on how you can do that:
Prerequisite Requirements:
- Model Serving: Databricks account with Model Serving enabled.
- Registered Model: Make sure your model is registered in the Unity Catalog or the Workspace Model Registry.
- Permissions: Confirm you have the necessary permissions on the registered models.
- Databricks MLflow 1.29 or Higher: Ensure your environment is set up with Databricks MLflow version 1.29 or higher.
Step 1—Log in to Your Databricks Workspace
Navigate to the Databricks login page and enter your credentials and log in to your workspace.
Step 2—Enable Model Serving
Follow the steps that we covered earlier to enable Databricks Model Serving. As a reminder:
- Your account admin needs to read and accept the terms and conditions for enabling serverless compute in the account console.
If your account was created after March 28, 2022, serverless compute is enabled by default.
- As an account admin, go to the "Feature Enablement" tab of the account console settings page.
- Accept the additional terms as prompted.
Step 3—Register Your Model
You need to first register your model before you proceed to the next step. You can register pre-trained, open-source, or fine-tuned models to Databricks MLflow, which can be done using the Databricks MLflow APIs or the Databricks MLflow user interface. Here’s how to do it:
Using Databricks MLflow API:
First—Import necessary libraries
import mlflow
import numpy as np
from transformers import pipelineSecond—Initialize the Databricks MLflow registry URI
mlflow.set_registry_uri('databricks-unity-catalog')Third—Define and configure your model and tokenizer
model_name = '<model_name>' # Replace with your model name
pad_token_id = <token_id> # Replace with the appropriate token ID
text_generation_pipeline = pipeline('text-generation', model=model_name, pad_token_id=pad_token_id, device_map="auto")Fourth—Define model components
components = {
"model": text_generation_pipeline.model,
"tokenizer": text_generation_pipeline.tokenizer
}Fifth—Specify the inference configuration
inference_config = {
"max_tokens": 75,
"temperature": 0.0
}Sixth—Input example for the model
input_example = {
"prompt": np.array(["Explain Databricks Model Serving"]),
"max_tokens": np.array([75]),
"temperature": np.array([0.0])
}Seventh—Model signature (optional but recommended)
signature = mlflow.models.infer_signature(input_example, components["model"](**input_example))Eighth—Metadata
metadata = {
"task": "llm/v1/completions"
}Ninth—Log the model to MLflow
artifact_path = '<artifact_path>' # Replace with your desired artifact path
registered_model_name = '<registered_model_name>' # Replace with your registered model name
with mlflow.start_run():
mlflow.transformers.log_model(
transformers_model=components,
artifact_path=artifact_path,
signature=signature,
registered_model_name=registered_model_name,
input_example=input_example,
metadata=metadata
)Using MLflow UI:
There are two ways to register a model in the Workspace Model Registry: register an existing model that has been logged to Databricks MLflow, or create and register a new, empty model and then assign a previously logged model to it.
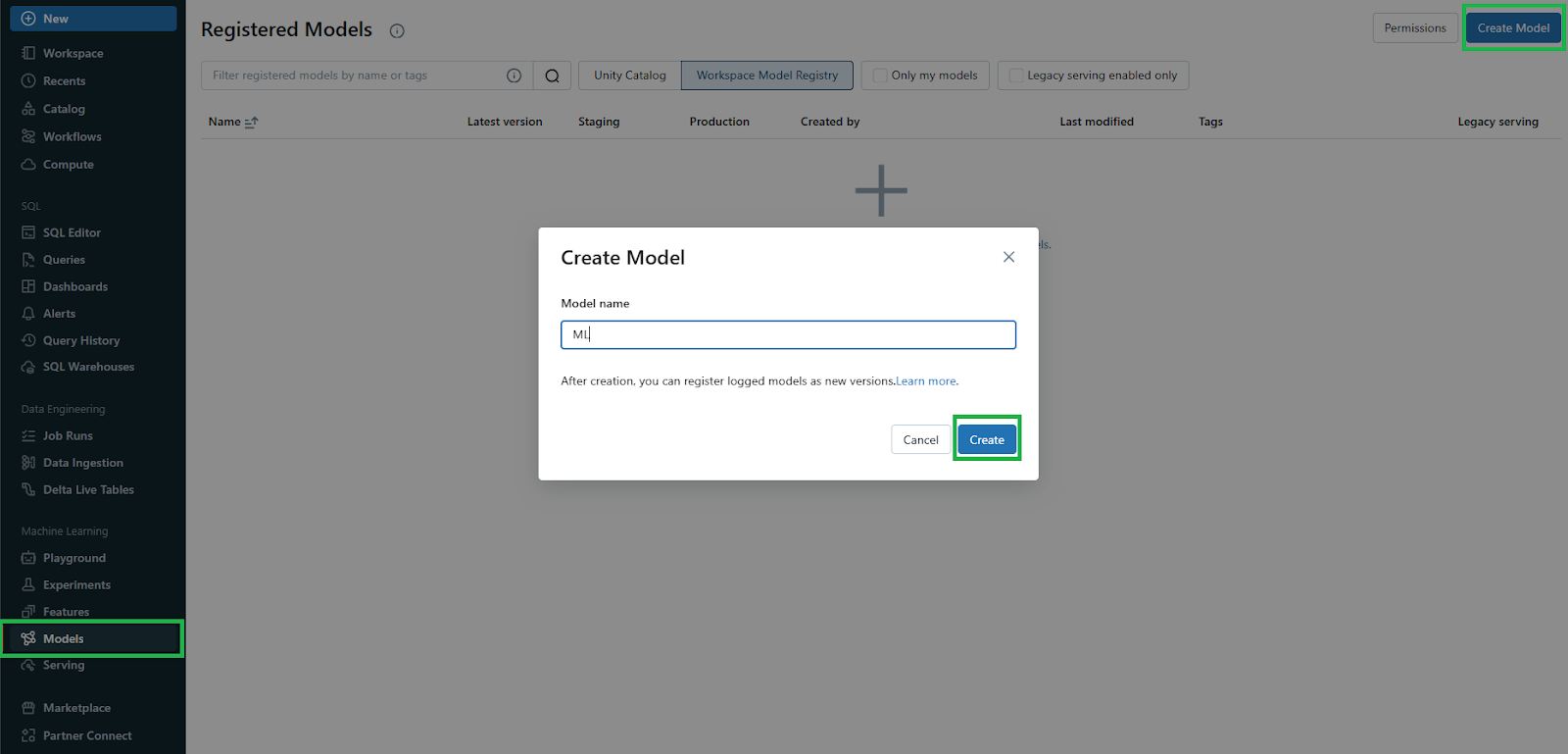
1) Create a New Registered Model and Assign a Logged Model to It
First—Create a New Registered Model
In the Databricks workspace, click the Models icon in the sidebar to navigate to the registered models page. Click Create Model, enter a name for the new model, and click Create.
Second—Identify the Databricks MLflow Run
Now, in the workspace, locate the Databricks MLflow run containing the model you want to assign to the newly created registered model. Click the Experiment icon in the notebook’s right sidebar to open the Experiment Runs sidebar.
Third—Navigate to the MLflow Run Page
In the Experiment Runs sidebar, click the External Link icon next to the date of the run to open the Databricks MLflow Run page, displaying the run details.
Fourth—Select the Model Artifact
In the Artifacts section of the Databricks MLflow Run page, click the directory named after your model.
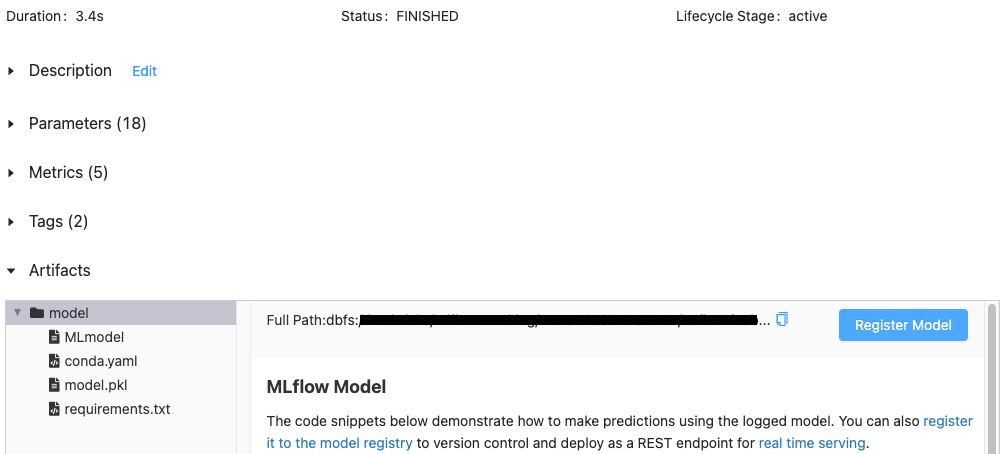
Fifth—Register the Logged Model
Click the Register Model button on the right. In the Register Model dialog, select the name of the model you created in Step 1 from the drop-down menu and click Register.
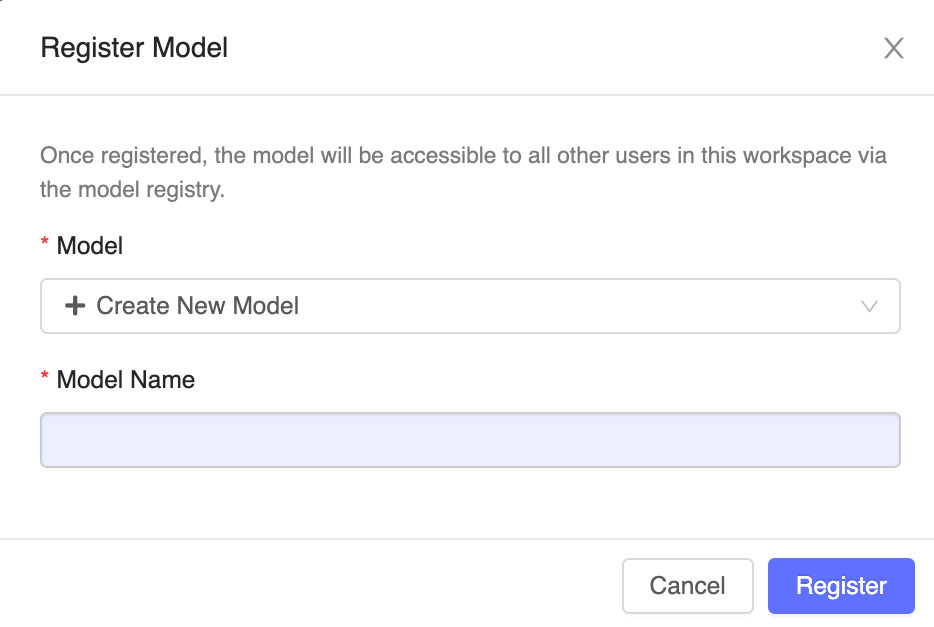
Sixth—Complete the Assignment
This action registers the model with the specified name, copies the model into a secure location managed by the Workspace Model Registry, and creates a new model version.
After registration, the Register Model button changes to a link to the new registered model version. You can now access this model from the Models tab in the sidebar or through the Databricks MLflow Run UI.
2) Register an Existing Logged Model from a Notebook
First—Identify the Databricks MLflow Run
Just as we covered in the earlier step, head over to your Databricks workspace and locate the Databricks MLflow run containing the model you want to register. Click the Experiment icon in the notebook’s right sidebar to open the Experiment Runs sidebar.
Second—Navigate to the Databricks MLflow Run Page
In the Experiment Runs sidebar, click the External Link icon next to the date of the run. This opens the MLflow Run page, which displays details of the run including parameters, metrics, tags, and a list of artifacts.
Third—Select the Model Artifact
In the Artifacts section of the Databricks MLflow Run page, click the directory named after your model.
Fourth—Register the Model
Click the Register Model button on the right. In the dialog box, click in the Model field and choose one of the following options:
- Create New Model: Enter a model name, such as scikit-learn-power-forecasting.
- Select an Existing Model: Choose an existing model from the drop-down menu.
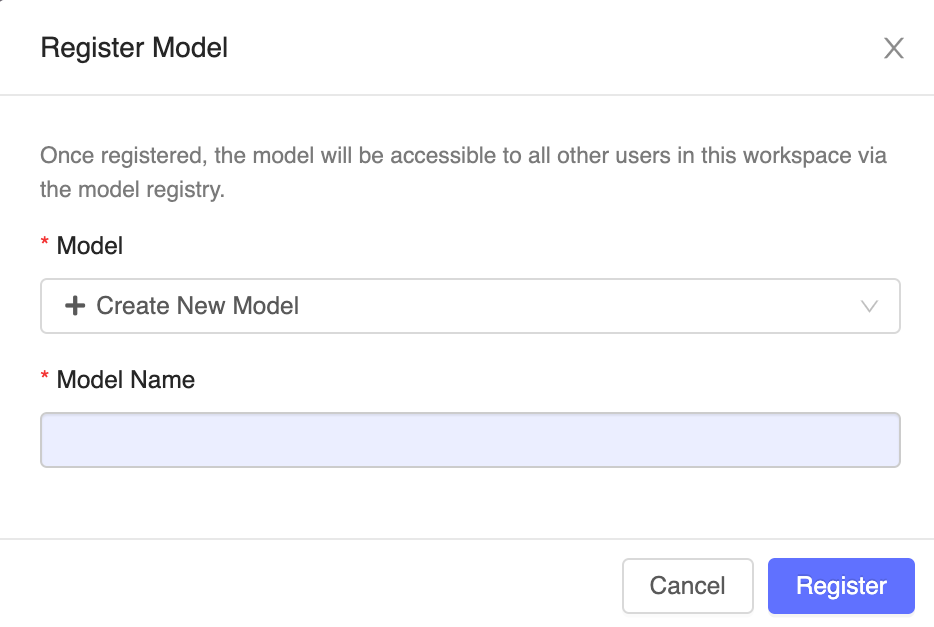
Fifth—Complete the Registration
Click Register. If you select Create New Model, this action will create a new registered model with the specified name and a new version of the model in the Workspace Model Registry. If you select an existing model, a new version of the chosen model will be registered.
Sixth—Access the Registered Model
After registration, the Register Model button changes to a link to the new registered model version. Click the link to open the new model version in the Workspace Model Registry UI.
You can also access the model from the Models tab in the sidebar.
Step 4—Accessing the Serving UI
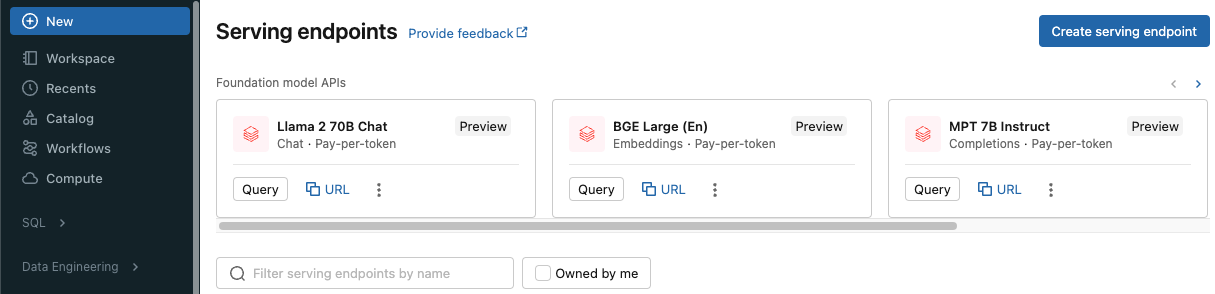
Navigate to the Serving tab in the Databricks sidebar and click "Create Serving Endpoint". Databricks Model Serving is directly integrated with the Databricks Unity Catalog, allowing you to deploy machine learning models across multiple workspaces and manage all your data and AI assets in a centralized location. This integration streamlines the process of deploying and governing models, providing a unified interface for all your data and AI needs. On top of that, you can also serve models externally or from the model registry.
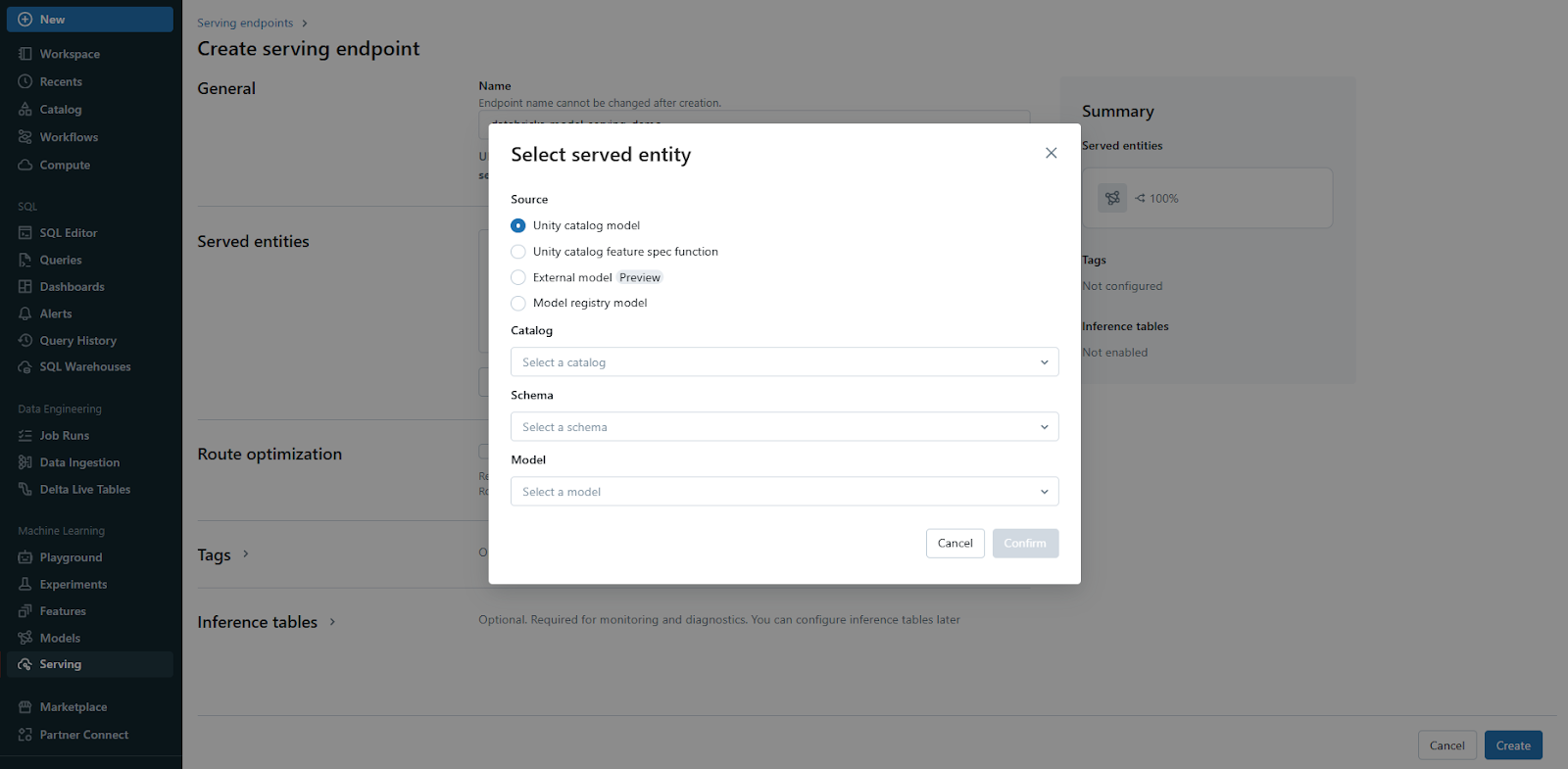
Step 5—Optimized Large Language Model (LLM) Serving
Choose the appropriate compute type (CPU or GPU) and configure the model serving endpoint for optimized performance.
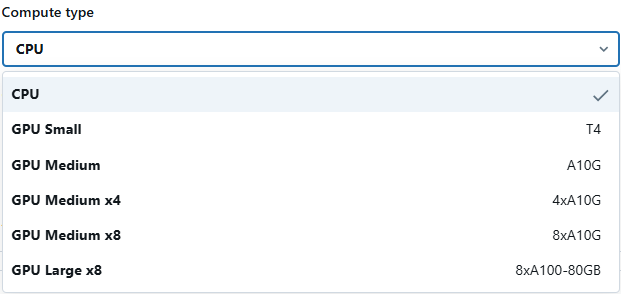
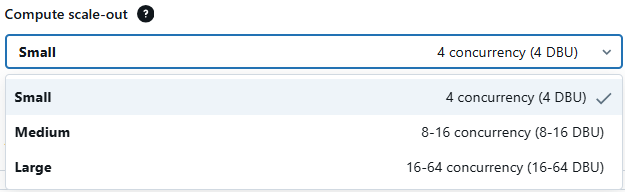
Databricks Model Serving also provides optimal model serving for select large language models, denoted by the purple lightning indicator in the UI. This feature allows you to deploy LLMs with 5 to 10 times reduced latency and costs. Using optimized LLM serving requires no additional work—simply provide the model, and Databricks will handle the rest to ensure the model is served with optimal performance.
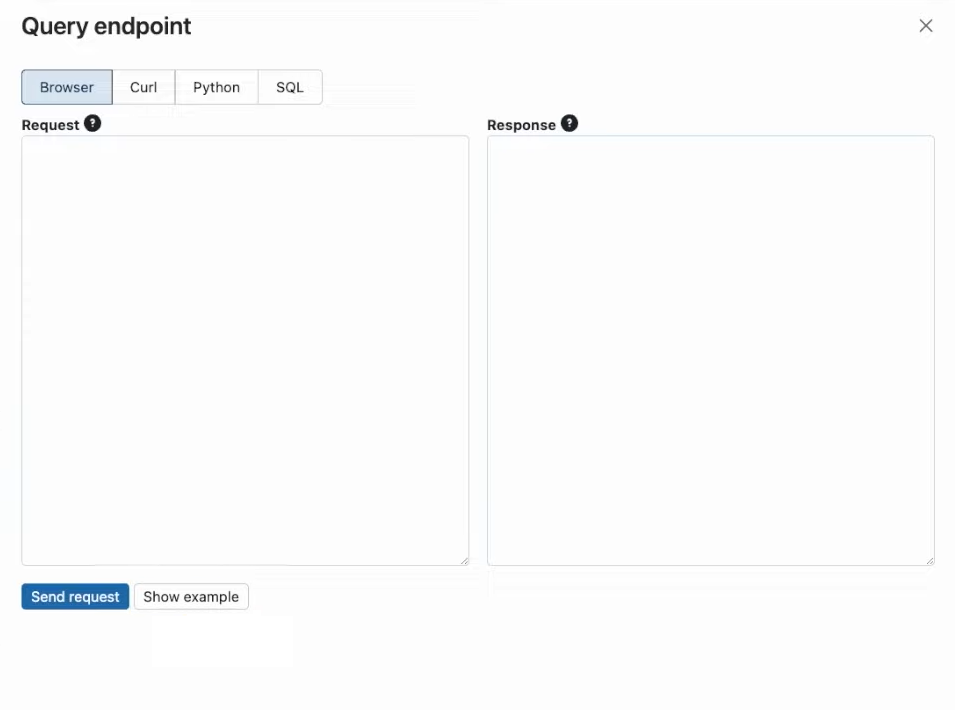
Step 6—Querying the Endpoint
When your endpoint is ready to use, you can easily query it using the REST API to make sure everything is working as expected. You can then leverage the power of the newly deployed LLM in your website or application through the API. This integration comes with the added benefit of automatically scaling to meet traffic patterns, ensuring consistent performance regardless of demand.

Step 7—Logging Model Requests and Responses
To log model requests and responses, you can easily enable logging with just one click. Databricks allows you to log these interactions to a Delta table managed by the Databricks Unity Catalog. This integration enables you to use existing data tools to query and analyze your data.

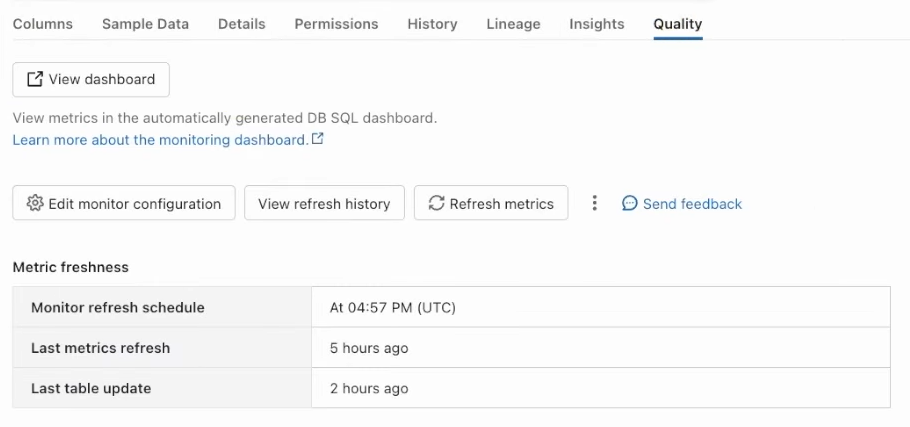
Step 8—Enabling Model Monitoring to Track Performance
Finally, you can enable model monitoring to track performance and detect drifts. Databricks Model Serving allows you to compute specific metrics for large language models (LLMs) such as toxicity and perplexity. This comprehensive monitoring capability helps ensure that your models remain accurate and reliable over time, enabling you to detect and address any issues promptly.
What Are the Limitations of Databricks Model Serving?
While Databricks Model Serving offers a powerful and efficient solution for deploying and managing AI models, it is essential to be aware of its limitations to ensure optimal performance and compliance with your organizational requirements. Here are some of the key limitations to keep in mind:
1) Resource and Payload Limitations
Payload Size—Maximum of 16 MB per request.
Queries per Second (QPS)—Default limit of 200 per workspace, which can be increased to 25,000 or more by contacting your Databricks account team.
Model Execution Duration—Limited to 120 seconds per request.
CPU Endpoint Model Memory Usage—Limited to 4 GB.
GPU Endpoint Model Memory Usage—Depends on the assigned GPU memory and the workload size.
Provisioned Concurrency—Limited to 200 concurrent requests per workspace.
Overhead Latency—Less than 50 milliseconds per request.
2) Foundation Model APIs Rate Limits (pay-per-token)
For Foundation Model APIs (pay-per-token), there are specific rate limits in place.
DBRX Instruct Model—1 query per second.
Other Chat and Completion Models—2 queries per second.
Embedding Models—300 embedding inputs per second.
3) Foundation Model APIs Rate Limit (Provisioned Throughput)
For provisioned throughput workloads using Foundation Model APIs, the default rate limit is 200 queries per workspace.
4) Access Control and Networking
Databricks Model Serving endpoints are protected by access control mechanisms and respect networking-related ingress rules configured on the workspace, such as IP allowlists and PrivateLink. However, by default, Databricks Model Serving does not support PrivateLink to external endpoints. Support for this functionality is evaluated and implemented on a per-region basis.
5) Region-Specific Limitations
Certain features and capabilities of Databricks Model Serving may have region-specific limitations or availability. For example, if your workspace is deployed in a region that supports model serving but is served by a control plane in an unsupported region, the workspace may not support model serving.
6) Init Scripts Limitation
Databricks Model Serving currently does not support the use of init scripts, which are commonly used for customizing the runtime environment.
7) Foundation Model APIs Compliance and Governance
Data Processing Location—As part of providing the Foundation Model APIs, Databricks may process your data outside of the region and cloud provider where your data originated.
Governance Settings—For Foundation Model APIs endpoints, only workspace admins can change governance settings, such as rate limits. Here is how you can change the rate limit:
Step 1—Open the Serving UI
Log in to your Databricks workspace and navigate to the Serving UI. On the left sidebar, click on "Workspace" and then find and click on "Serving" to open the Serving UI.
Step 2—Locate Your Serving Endpoints
Now within the Serving UI, you will see a list of serving endpoints available in your workspace. Identify the Foundation Model APIs endpoint for which you want to change the rate limits.
Step 3—View Endpoint Details
Next to the Foundation Model APIs endpoint you want to edit, click on the kebab menu (three vertical dots) to open a dropdown menu. From the dropdown menu, select "View details".
Step 4—Change Rate Limit
On the endpoint details page, find the kebab menu on the upper-right side of the page. Click on the kebab menu to open the dropdown menu and select "Change rate limit" from the dropdown options.
8) Region Availability
Core Model Serving
- Asia Pacific (Seoul)
- EU (London)
- EU (Paris)
- South America (São Paulo)
- US West (Northern California)
Foundation Model APIs (Provisioned Throughput)
- Asia Pacific (Seoul)
- Asia Pacific (Singapore)
- EU (London)
- EU (Paris)
- South America (São Paulo)
- US West (Northern California)
Foundation Model APIs (Pay-Per-Token)
- Asia Pacific (Tokyo)
- Asia Pacific (Seoul)
- Asia Pacific (Mumbai)
- Asia Pacific (Singapore)
- Asia Pacific (Sydney)
- Canada (Central)
- EU (Frankfurt)
- EU (Ireland)
- EU (London)
- EU (Paris)
- South America (São Paulo)
External Models
- Asia Pacific (Seoul)
- EU (London)
- EU (Paris)
- South America (São Paulo)
Advantages of Using Databricks Model Serving for LLM Deployment
Deploying Large Language Models (LLMs) using Databricks model serving offers several significant advantages, making it a powerful platform for this purpose:
1) Simplifies the Ease of Deployment
Databricks Model Serving simplifies the deployment of large language models (LLMs). Instead of writing complex libraries for model optimization, you can focus on integrating the LLM into your applications seamlessly. This streamlined process allows data scientists and developers to deploy machine learning models without needing deep expertise in infrastructure management.
2) Highly Scalable
Databricks offers automatic scaling for its model serving service meaning, the system can scale up or down based on demand, guaranteeing optimal latency performance and cost efficiency. Whether you have a sudden spike in usage or a drop, the infrastructure adapts automatically, saving on unnecessary resource allocation.
3) Security
Security is a critical aspect of Databricks' offering. Models are deployed within a secure network boundary, utilizing dedicated compute resources that terminate when the model is scaled down to zero or deleted. This ensures that your models are both secure and efficient, with no lingering compute resources consuming unnecessary costs.
4) Integration
Databricks Model Serving integrates natively with the Databricks MLflow Model Registry. This integration allows for fast and straightforward deployment of models, leveraging MLflow's capabilities to manage the model lifecycle from experimentation to production.
5) Performance
Performance optimizations are built into Databricks Model Serving, reducing latency and cost significantly. These optimizations can lead to performance improvements of 3-5x, making the deployment of LLMs more efficient and cost-effective.
6) Compliance
Databricks meets the compliance needs of highly regulated industries by implementing several controls. This is particularly important for industries such as finance, healthcare, and government, where regulatory compliance is non-negotiable.
Further Reading:
- Databricks Unity Catalog 101: A Complete Overview
- Model serving with Databricks
- Data protection in Model Serving
- Log, load, register, and deploy MLflow models
- Deploy custom models
- Create custom model serving endpoints
- Query serving endpoints for custom models
- Databricks Foundation Model APIs
- Query foundation models
- Manage model lifecycle in Unity Catalog
- Manage model lifecycle using the Workspace Model Registry
- Serving endpoint ACLs
- ML lifecycle management using MLflow
- Get started with MLflow experiments
- External models in Databricks Model Serving
- Create external model endpoints to query OpenAI models
Save up to 50% on your Databricks spend in a few minutes!


Conclusion
Databricks Model Serving simplifies AI model deployment and management, offering a scalable, high-performance, and cost-effective solution. Its seamless interaction with Databricks tools, as well as support for custom, pre-trained, and external models, make it an excellent alternative for enterprises aiming to speed up AI and ML adoption.
In this article, we have covered:
- What Is Model Serving?
- What Is Databricks Model Serving?
- Is the Databricks Model Serving Serverless?
- What Are the Hurdles in Building Real-Time Machine Learning Systems?
- Databricks Model Serving Pricing
- Why Use Databricks Model Serving?
- How to Enable Model Serving for Your Databricks Workspace?
- Step-by-step guide to Deploy Large Language Models using Databricks Model Serving
- What Are the Limitations of Databricks Model Serving?
…and so much more!
FAQs
What is Databricks Model Serving?
Databricks Model Serving is a unified service for deploying, governing, querying, and monitoring AI models.
Is Databricks Model Serving serverless?
Yes, Databricks model serving offers a serverless deployment option that eliminates the need for infrastructure management.
What are the limitations of Databricks Model Serving?
Limitations include payload size, queries per second, model execution duration, and specific region availability.
Can I deploy custom models with Databricks Model Serving?
Yes, you can deploy both custom and pre-trained models using Databricks Model Serving.
How do you enable Model Serving for your Databricks workspace?
As an account admin, you need to navigate to the account console settings, go to the "Feature Enablement" tab, and accept the additional terms to enable serverless compute.
How do you register a model before deploying it with Databricks Model Serving?
You can register pre-trained, open-source, or fine-tuned models using either the MLflow APIs or the MLflow user interface in the Databricks workspace.
How do you query a deployed model endpoint?
You can easily query the endpoint using the provided REST API to integrate it with your website or application.
Can you log model requests and responses in Databricks Model Serving?
Yes, you can enable logging with one click to log interactions to a Delta table managed by the Databricks Unity Catalog.
How do you change the rate limit for Foundation Model APIs endpoints?
Only workspace admins can change rate limits for Foundation Model APIs endpoints through the Serving UI.
How are security and governance managed in Model Serving?
Model Serving integrates with Databricks' security features, including encryption of data at rest and in transit. It also supports fine-grained access control, monitoring, and governance through Unity Catalog, ensuring compliance with organizational policies.
What are the requirements to use Databricks Model Serving?
To use Model Serving, you need a registered model in either the Unity Catalog or the Databricks MLflow Model Registry. Additionally, you must have the necessary permissions and use MLflow version 1.29 or higher.
In which regions is Databricks Model Serving available?
- Core model serving: Asia Pacific (Seoul) , EU (London), EU (Paris), South America (Sao Paulo), US West (Northern California)
- Foundation Model APIs : Asia Pacific (Seoul), Asia Pacific (Singapore), EU (London), EU (Paris), South America (Sao Paulo), US West (Northern California)
- Foundation Model APIs (pay-per-token): Asia Pacific (Tokyo), Asia Pacific (Seoul), Asia Pacific (Mumbai), Asia Pacific (Singapore), Asia Pacific (Sydney), Canada (Central), EU (Frankfurt), EU (Ireland), EU (London), EU (Paris), South America (Sao Paulo)
- External models: Asia Pacific (Seoul), EU (London), EU (Paris), South America (Sao Paulo)
What are the advantages of using Databricks Model Serving for LLM deployment?
Advantages include simplified deployment, high scalability, security, integration with MLflow Model Registry, performance optimizations, and regulatory compliance.
How does Databricks Model Serving integrate with other Databricks tools?
It integrates natively with the MLflow Model Registry, Databricks Feature Store, and Databricks Unity Catalog, allowing for end-to-end ML lifecycle management.
Can you deploy external models using Databricks Model Serving?
Yes, Databricks Model Serving supports deploying and querying external models, including those from OpenAI.
Can I serve multiple models behind a single endpoint?
Yes, you can deploy multiple models behind a single endpoint and configure traffic distribution among them.















