



























Tired of manually running the same SQL scripts day after day? Struggling to orchestrate complex ELT workflows that ingest, transform, and load data on schedule? Automating repetitive and routine data tasks is crucial for efficiently managing modern data pipelines. Snowflake Tasks provides a powerful automation framework to simplify scheduling and managing Snowflake SQL execution, enabling you to build automated, continuous ETL processes that run like clockwork.
In this article, we will walk through how to create, schedule, monitor, and manage Snowflake Tasks for automating Snowflake SQL execution. We will cover key concepts like Snowflake task types, scheduling mechanisms, task dependencies—and a whole lot more!!
Let's dive right in!
Definition and Purpose of Snowflake Tasks—An Overview
Snowflake tasks allow you to automate the execution of Snowflake SQL statements, stored procedures, and UDFs on a scheduled basis. They are useful for automating repetitive data management and ELT processes in Snowflake. Snowflake tasks provide a framework for scheduling multi-step data transformations, loading data incrementally, maintaining data pipelines, and ensuring downstream data availability for analytics and applications.
Snowflake tasks are decoupled from specific users, so they can continue to run even if the user who created them is no longer available. They are also serverless, so Snowflake only provisions the compute resources needed to run the task, and then releases those resources when the task is finished. This can help save costs.
Here are some key things to know about Snowflake Tasks:
- Snowflake tasks allow you to automate Snowflake SQL statements, stored procedures, data load operations—and a whole lot more.
- Only one Snowflake SQL statement is allowed per Snowflake tasks.
- Snowflake tasks support dependencies, so you can chain together a sequence of operations.
- Snowflake tasks can be monitored in real-time as they execute. You can view Snowflake tasks history, status, and results within Snowflake.
- Permissions on Snowflake tasks allow you to control who can create, modify, run, or view them.
- Snowflake handles all task dispatching, parallelism, queuing, and retry handling.
- Snowflake tasks auto-scale across your Snowflake compute.
- Common use cases for Snowflake tasks include ELT processes/pipelines, refreshing materialized views, schedule queries to update dashboards, and orchestrating multi-step workflows.
Save up to 30% on your Snowflake spend in a few minutes!


Step-by-Step Process of creating a Snowflake Tasks
Snowflake Tasks provide a simple way to schedule and automate the Snowflake SQL execution of SQL statements, stored procedures, and UDFs. Tasks remove the need to rely on external schedulers, orchestration tools or external or third-party workflow tools/engines.
Here is a step-by-step process for creating a Snowflake task:
Step 1: Log in to your Snowflake account.
Step 2: Create a new schema to store your Snowflake tasks.
CREATE SCHEMA task_demo;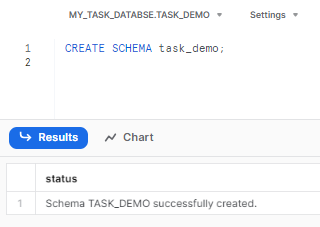
Step 3: Create a new Snowflake tasks using the CREATE TASK statement. Define the Snowflake tasks by providing a name, warehouse, frequency schedule, and the Snowflake SQL statement to execute:
The following is an example of a CREATE TASK statement:
CREATE TASK task_demo.ingest_data
WAREHOUSE = MY_WH
SCHEDULE = '60 minute'
AS
-- SQL statement
INSERT INTO my_table VALUES (1, ‘Hello World’);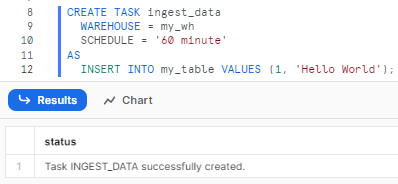
This will create a Snowfglake task named ingest_data that runs every 60 minute on my_wh warehouse and inserts values into my_table.
Step 4: Make sure to specify the virtual warehouse to use for running the task. This should have sufficient resources for the Snowflake Tasks operation.
Types of Snowflake Tasks:
Snowflake provides two types of task compute models:
1) Serverless Snowflake Tasks
With serverless Snowflake tasks, Snowflake automatically manages the compute resources required. You don't have to specify a warehouse.
Snowflake scales the resources up and down based on workload requirements.
To create a serverless Snowflake task:
CREATE TASK my_serverless_task
SCHEDULE = '60 minute'
AS
-- Snowflake SQL statement (Automate SQL)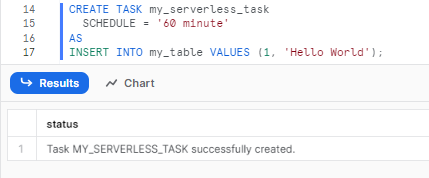
You can control initial warehouse size using the USER_TASK_MANAGED_INITIAL_WAREHOUSE_SIZE parameter.
CREATE TASK my_serverless_task
USER_TASK_MANAGED_INITIAL_WAREHOUSE_SIZE = 'XSMALL'
SCHEDULE = '60 MINUTE'
AS
-- Snowflake SQL statement (Automate SQL)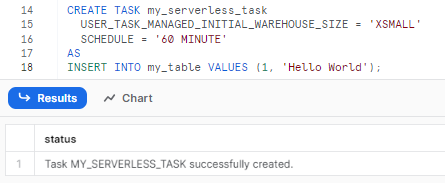
2) User Managed Tasks
With user managed Snowflake tasks, you specify an existing virtual warehouse when creating the task. This allows you full control over the compute resources.
For example:
CREATE TASK my_task
WAREHOUSE = my_wh
SCHEDULE = '60 minute'
AS
-- Snowflake SQL statement (Automate SQL)
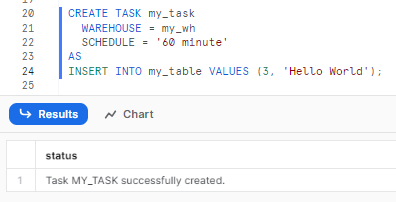
Make sure to size the warehouse appropriately for the workload.
Note: If the WAREHOUSE parameter is not defined when creating a Snowflake tasks, by default Snowflake will use its managed compute resources (Serverless model)
How to Schedule Snowflake Tasks ?
Snowflake provides two scheduling mechanisms for tasks : Interval-based scheduling notation and CRON notation.
Let's explore both in detail:
Types of scheduling mechanisms:
1) Interval-based scheduling or NON-CRON notation
NON-CRON notation allows interval-based scheduling. You specify a fixed time interval at which the task should run.
For example, run every 60 minutes:
SCHEDULE = '60 minute'The downside is that you cannot specify a particular runtime. The task will run at an interval relative to its start time.
2) CRON notation (Time-based scheduling)
CRON notation provides powerful, time-based scheduling. You can specify a particular time for the task to be executed.
The syntax is:
SCHEDULE = 'USING CRON * * * * * UTC'The asterisks represent minute, hour, day of month, month and day of week respectively.
Here are some few good websites that can help you understand cron scheduling better and write cron expressions for you:
For example, run at 11 AM UTC every Sunday:
SCHEDULE = 'USING CRON * 11 * * MON UTC'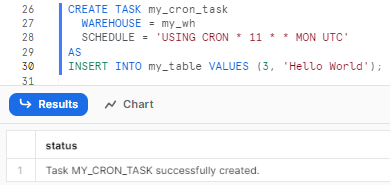
This allows flexible, time-based scheduling.
Here are some useful websites that can help you better understand cron scheduling and generate cron expressions:
- Crontab.guru : Interactive cron expression generator and explainer, which allows you to visually build cron schedules.
- EasyCron : Online cron expression generator with predefined cron schedule examples.
- CronMaker : A simple cron generator with an interactive interface.
- CronTab-generator : Helps you build cron expressions online along with examples.
Step-by-Step Process of Managing Snowflake Tasks
Once Snowflake tasks are created, you can control the state of a Snowflake task using the ALTER TASK command.
But first, to check the status of all the Snowflake tasks you can make use of the SHOW TASKS command.
SHOW TASKS;
To turn on a task:
ALTER TASK my_task RESUME;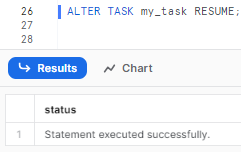
This will resume a suspended task.
To turn off a task:
ALTER TASK my_task SUSPEND;
You can check the Snowflake task history using the TASK_HISTORY() function:
SELECT * FROM TABLE(INFORMATION_SCHEMA.TASK_HISTORY())
WHERE TASK_NAME = 'my_task'
You can also specify the task name to check the status of that particular Snowflake tasks.
SELECT * FROM TABLE(INFORMATION_SCHEMA.TASK_HISTORY())
WHERE NAME = 'my_task'This returns information on each run including status, start time, end time, failures etc.
Advanced Snowflake Tasks Concepts
Understanding Snowflake Task Tree
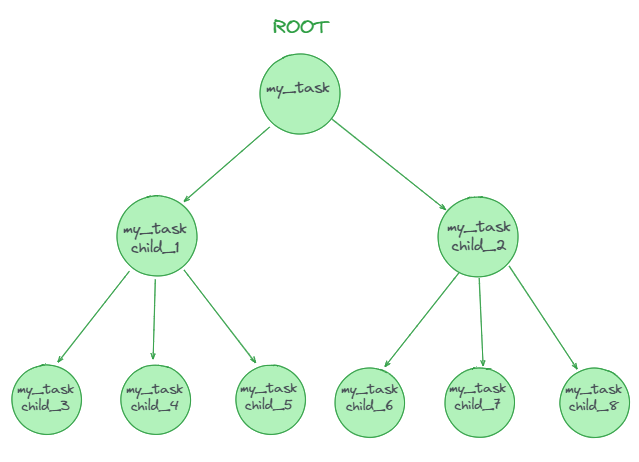
Snowflake Tasks Trees allow you to create dependencies between tasks to automatically execute them in a sequential workflow. The key components of a Snowflake Tasks Tree are a root parent task, child tasks, task dependencies, a single task owner, and an overall tree structure.
The root task in Snowflake sits at the pinnacle of the tree. It operates on a defined schedule, which can be set using either CRON or interval-based notation. This root task initiates the entire workflow, running autonomously based on its schedule. Every other task in the tree is either directly or indirectly dependent on this root task.
Child tasks stem from the root or other parent tasks. Unlike the root, child tasks don't require their own schedule. Instead, they're set to run "after" a designated parent task has finished. This configuration establishes the task dependencies that shape/structure the tree.
The dependencies control the order of execution — each child task will only start after its defined parent completes successfully, which enables automatically cascading and orchestrating tasks into a larger sequential process flow.
Every task within the tree must have a common task owner—a role equipped with the necessary privileges. Also, all Snowflake tasks should be located within the same database and schema.
From a structural standpoint, the tree resembles a B-tree hierarchy, with the root at the top and child tasks branching out and forming layers beneath. Check out the diagram below 👇 for an even better understanding of the concept.
Snowflake Task Tree Limitations:
Snowflake task tree can accommodate up to 1000 Snowflake tasks in total.
Individual parent tasks can have a maximum of 100 child Snowflake tasks.
When executed, the root task runs first based on its defined schedule. Upon completion, it triggers the next layer of dependent child tasks. This creates a cascading and sequential execution of the entire workflow.
Example of a Snowflake Task Tree for an ETL Pipeline:
Here is a sample Snowflake task tree that runs a simple ETL pipeline:
Step 1: Create a root task to load raw data from S3:
CREATE TASK load_raw_data
WAREHOUSE = COMPUTE_WH
SCHEDULE = '0 0 * * *' -- runs hourly
AS
COPY INTO raw_data
FROM @s3_stage;Step 2: Create a child task to transform the raw data:
CREATE TASK transform_data
WAREHOUSE = COMPUTE_WH
AFTER load_raw_data
AS
INSERT INTO transformed_data
SELECT col1, col2, col3
FROM raw_data;Step 3: Create a child task to load transformed data into production:
CREATE TASK load_production
WAREHOUSE = COMPUTE_WH
AFTER transform_data
AS
INSERT INTO prod_table
SELECT * FROM transformed_data;Step 4: Suspend the root task to prevent automatic triggering:
ALTER TASK load_raw_data SUSPEND;This will:
- Load raw data (root task)
- Transform it (first child)
- Load into production (second child)
Chaining/Linking Snowflake tasks in this manner orchestrates an automated ETL process, with the root serving as the initiator and the children directing the data flow.
Manually Executing a Snowflake Task
The EXECUTE TASK command allows manually triggering a one-time run of a Snowflake task outside of its defined schedule. This is useful for ad-hoc testing or execution of a task.
To manually execute a task:
Step 1: Use the EXECUTE TASK command and specify the name of the task:
EXECUTE TASK my_task;
This will trigger the immediate asynchronous execution of that task.
Some key points to remember for manually executing a Snowflake tasks:
- Manually overrides defined schedule if any
- Task runs ad-hoc based on execute command
- Useful for testing or one-off execution
- Asynchronous execution - control does not block
- Can execute suspended tasks
- Can pass optional parameters/variables
For example, to execute a task called 'generate_daily_report':
EXECUTE TASK generate_daily_report;This will immediately run this task to generate the report without waiting for its defined schedule.
We can check the task history to confirm manual execution:
SELECT * FROM TABLE(INFORMATION_SCHEMA.TASK_HISTORY());For a more in-depth guide on Snowflake TASK, check out this comprehensive video from Data Engineering Simplified.
Step-by-step process of Building a Snowflake Task for Tracking INSERT Operations
Snowflake tasks offer a powerful way to implement continuous ELT pipelines by combining them with Snowflake table streams. The Snowflake streams can capture real-time changes to source tables, while the tasks process the change data incrementally.
Specifically, you can create a table stream on a source table to buffer INSERT, UPDATE, and DELETE operations. A task can then be defined to poll the stream on a scheduled interval using SYSTEM$STREAM_HAS_DATA(). This function checks if the stream has any new change data.
If there is new data, the task will run a query to extract the changed rows from the stream. For example, it can insert only the new INSERT rows into a separate audit table. If the stream has no new data, then the scheduled task will simply skip the current run.
In this way, the stream acts as a change data capture buffer, while the task handles the incremental processing. Together they provide an efficient way to build scalable ELT pipelines that react to real-time changes in the source system. The task polling model ensures that load on the source is minimized by only querying for new changes at defined intervals.
TL;DR: Snowflake streams and Snowflake tasks provide an efficient solution for continuous integration workflows, addressing the challenge of managing and responding to ongoing data changes.
Detailed Steps to Create a Snowflake Task for Monitoring INSERT Operations:
Here is a detailed step-by-step process to build a Snowflake task to track INSERT operations from a stream:
Step 1: Create a table stream on the source table to capture INSERTs
CREATE STREAM my_insert_stream ON TABLE my_source_table;This will create a stream that will buffer all INSERT operations on the table.
Step 2: Define a new task to process the insert stream
CREATE TASK process_inserts
WAREHOUSE = my_wh
SCHEDULE = '5 MINUTE'
AS
// Query insert data from stream
This creates a scheduled task that will run every 5 minutes.Step 3: Check if the stream has new data using SYSTEM$STREAM_HAS_DATA()
WHEN
SYSTEM$STREAM_HAS_DATA('my_insert_stream')This will allow the task to detect if there are any new inserts in the stream.
Step 4: If new data is available, query the stream to retrieve the new INSERT rows.
INSERT INTO my_audit_table
SELECT * FROM my_insert_stream
WHERE METADATA$ACTION = 'INSERT';This will insert all the new rows from the stream into the audit table.
Step 5: Finally, resume the task to activate it
ALTER TASK process_inserts RESUME;This will start the task and begin processing insert data from the stream.
Step-by-step process of Scheduling stored procedure via snowflake task
Snowflake tasks provide a convenient way to schedule the execution of stored procedures automatically. By defining a task that calls a procedure on a timed schedule, you can set up regular and recurring Snowflake SQL execution logic encapsulated within procedures. This avoids having to manually call the procedures each time.
Steps to Schedule a Stored Procedure using a Snowflake Task:
Here is a step-by-step process to schedule a stored procedure using a Snowflake task:
Step 1: Create a stored procedure containing the Snowflake SQL logic that needs to run on a schedule:
CREATE PROCEDURE my_stored_proc()
RETURNS string
LANGUAGE javascript
AS
$$
// Procedure logic
return 'Procedure ran successfully';
$$;
Step 2: Define a new task that will call this stored procedure:
CREATE TASK run_procedure
WAREHOUSE = my_wh
SCHEDULE = '1 MINUTES'
AS
CALL my_stored_proc();
The schedule interval defines how often the task will execute. Here it is set to hourly.
Step 3: Verify the task was created successfully by checking the task list:
SHOW TASKS;Step 4: Resume the task to activate the scheduling:
ALTER TASK run_procedure RESUME;
The Snowflake task will now call the stored procedure every 1 hour based on the schedule.
Step 5: Finally, review Task History to inspect the execution details and history of the Snowflake tasks by using TASK_HISTORY() function.
SELECT * FROM TABLE(INFORMATION_SCHEMA.TASK_HISTORY());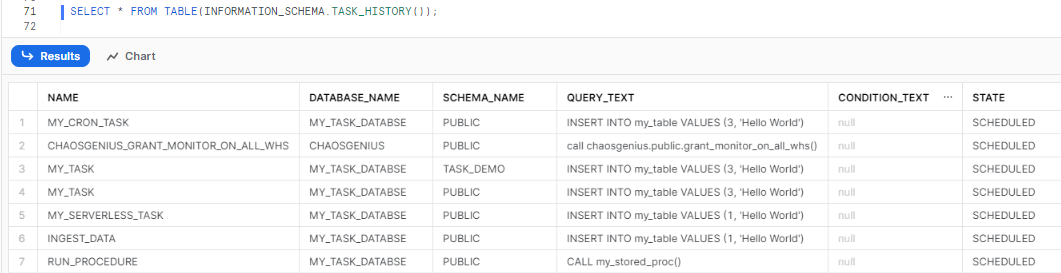
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Conclusion
Snowflake Tasks enable robust native scheduling and automation of SQL statements, stored procedures, and orchestrated pipelines within Snowflake. Key features include configurable scheduling, dependency management, incremental workflows via Snowflake table streams, monitoring, and troubleshooting. With simple commands to manage tasks, Snowflake Tasks provide powerful workflow automation without external tools. In this article, we provided an in-depth overview of Snowflake Tasks and a comprehensive guide to:
- Creating and scheduling Snowflake tasks
- Selecting capacity and monitoring executions
- Using CRON vs non-CRON notations for scheduling
- Building task dependencies to create workflows
- Tracking changes and incremental loads
- Executing stored procedures on a schedule
- Troubleshooting failures and checking history
- Architecting complex workflows with multi-level task trees
Snowflake Tasks is like having a personal assistant right inside Snowflake — allowing you to easily schedule and automate processes without any external orchestration.
FAQs
What types of SQL statements can Snowflake Tasks execute?
Snowflake tasks can execute INSERT, UPDATE, MERGE, DELETE statements as well as call stored procedures. They allow most DML operations useful for ETL or data manipulation.
Can multiple SQL statements be executed in one Snowflake Task?
No, a Snowflake task can only contain one SQL statement or call to a stored procedure. For multi-statement workflows, create a stored procedure and invoke it from the task.
Is there a limit on the number of tasks in a Snowflake account?
There are no hard limits on the number of tasks per account, it depends on warehouse sizes. There are recommended limits of around 200 tasks per virtual warehouse.
Can Snowflake tasks execute Python or Java code?
No, Snowflake tasks can only execute SQL statements and stored procedures. For more complex logic in Python, Java etc, external schedulers would be required.
What is a DAG in the context of Snowflake tasks?
Directed Acyclic Graph (DAG) is a series of tasks with a single root task and additional tasks organized by their dependencies. DAGs flow in one direction, ensuring tasks later in the series don't prompt earlier tasks.
How does Snowflake handle overlapping DAG runs?
By default, only one instance of a DAG is allowed to run at a time. However, the ALLOW_OVERLAPPING_EXECUTION parameter can be set to TRUE to permit overlapping DAG runs.
What happens when a task in a DAG is suspended?
When the root task of a DAG is suspended, you can still resume or suspend any child tasks. If a DAG runs with suspended child tasks, those tasks are ignored during the run.
How does Snowflake handle task versioning?
When a task is first resumed or manually executed, an initial version is set. After a Snowflake task is suspended and modified, a new version is set upon resumption or manual execution.
Can session parameters be set for Snowflake tasks?
Yes, session parameters can be set for the session in which a task runs using the ALTER TASK command. However, tasks do not support account or user parameters.
How does Snowflake handle tasks that repeatedly fail?
Snowflake offers the SUSPEND_TASK_AFTER_NUM_FAILURES parameter, which can automatically suspend tasks after a specified number of consecutive failed runs.
What is the EXECUTE TASK command in Snowflake?
EXECUTE TASK command manually triggers a single run of a scheduled task, useful for testing Snowflake tasks before enabling them in production.
How can I view the task history in my Snowflake account?
Task history can be viewed using SQL or Snowsight. Roles with specific privileges, like ACCOUNTADMIN, can use Task_History() function to view task history.
How are costs associated with Snowflake tasks determined?
Costs vary based on the compute resource source. User-managed warehouses are billed based on warehouse usage, while Snowflake-managed resources are billed based on actual compute resource usage.
What are the compute models available for Snowflake tasks?
Snowflake offers two compute models: Snowflake-managed (serverless) and user-managed (virtual warehouse).
How does Snowflake handle task scheduling and Daylight Saving Time?
The cron expression in a task definition supports specifying a time zone, and tasks run according to the local time for that zone. Special care is needed for time zones that recognize daylight saving time to avoid unexpected task executions.
How does Snowflake ensure that Snowflake tasks are executed on schedule?
Snowflake ensures only one instance of a task with a schedule is executed at a given time. If a task is still running when the next scheduled execution time occurs, that scheduled time is skipped.
Do Snowflake tasks require permanent virtual warehouses?
Snowflake provides serverless Snowflake tasks that use auto-scaling resources, no permanent warehouses are required. But user-managed tasks do require defined virtual warehouses.









