





























Snowflake file formats are like duct tape—they bind together the messy process of loading and unloading data. These database objects define the structure and organization of files in Snowflake stages, making staged data easy to query and ingest into tables. Snowflake file formats contain metadata about the data file, such as its type (CSV, JSON, AVRO, PARQUET, and more), formatting options, and compression method. They are valuable when loading/unloading data from Snowflake stages into tables, or when creating external tables on staged files.
In this article, we will walk you through how to create and manage Snowflake file formats. We will explore how this powerful feature can simplify the process of accessing staged data, making it easier than ever to load data into and unload data out of your Snowflake tables. We'll also delve into the various file types and formatting options.
Snowflake File Formats—Understanding the Depths
A Snowflake file format is a named database object that encapsulates information about a data file. This information includes the file's type (CSV, JSON, etc.), formatting options, and compression method.
Snowflake file formats are used to simplify the process of loading and unloading data from Snowflake tables. When you load data from a file into a table, you can specify the file format to use. This tells Snowflake how to interpret the data in the file and load it into the table correctly.
Here are the list of supported Snowflake file formats:
- CSV (Comma-separated values): This is the most common file format for loading data into Snowflake.
- JSON (JavaScript Object Notation): This is a flexible and lightweight file format that is often used for semi-structured data.
- Avro: A binary file format that is efficient for storing and querying large datasets.
- ORC (Optimized Row Columnar): A columnar file format that is optimized for analytical queries.
- Parquet: A columnar file format that is similar to ORC, but it is more widely supported.
- XML (Extensible Markup Language): This is a text-based file format that is often used for storing structured data.
Please note that Snowflake does not support unloading or exporting tables to all of the above file formats. The below table describes this.

Note: When loading data from files into tables, Snowflake supports either NDJSON (“Newline Delimited JSON”) standard format or comma-separated JSON format. However, when unloading data from tables to files, Snowflake exclusively outputs in NDJSON format.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

How to Create Snowflake File Formats?
Step-by-step guide to creating Snowflake file format
Step 1: Login to Snowflake and locate the "Databases" option and then Click on it to display a list of available databases. Choose the appropriate database and select the desired schema where you want to create the File Format.
Step 2: Now, at the top right-hand corner of the interface, you'll find a "Create" button. Click on this button to reveal a drop-down menu containing various options for creating different Snowflake objects.
Step 3: In the drop-down menu, look for the "File Format" option and click on it. This action will open a new window dedicated to creating a Snowflake File Format.
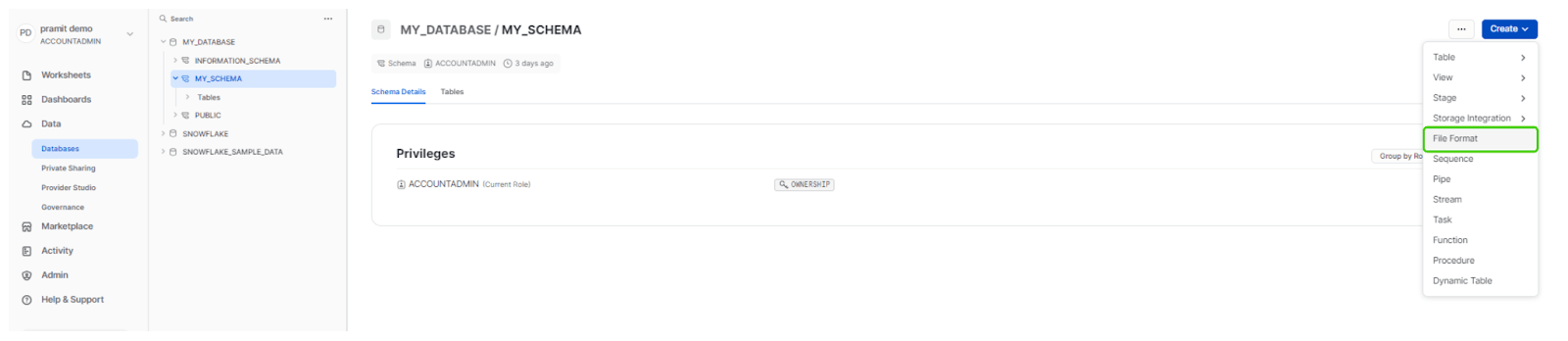
Step 5: Finally, you can specify the details and formatting options for your Snowflake File Format.
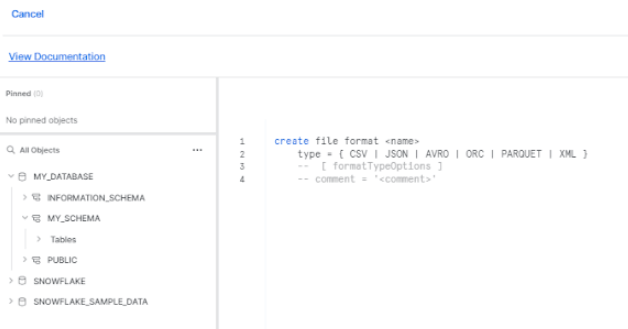
Alternatively:
Step 1: Instead of navigating through the database and schema options, you can directly open a Snowflake worksheet by clicking on the "Worksheet" option.
Step 2: Now, within the opened worksheet, select the appropriate database and schema, or you can also specify the database and schema names in the file format name itself.
Step 3: In the worksheet, execute a SQL statement to create the Snowflake File Format. The syntax for creating a File Format in Snowflake follows the pattern:
CREATE FILE FORMAT <file_format_name>
TYPE = <file_type>
[FORMAT_OPTIONS = (<format_options>)]
[COMPRESSION = <compression_type>];Snowflake File Formats Examples
Here are some examples of how to create Snowflake file formats for CSV, JSON, AVRO, ORC, PARQUET, and XML file type:
1) Snowflake File Format CSV:
CREATE FILE FORMAT my_csv
TYPE = 'CSV'
FIELD_DELIMITER = ','
RECORD_DELIMITER = '\n'
FIELD_OPTIONALLY_ENCLOSED_BY = '\"';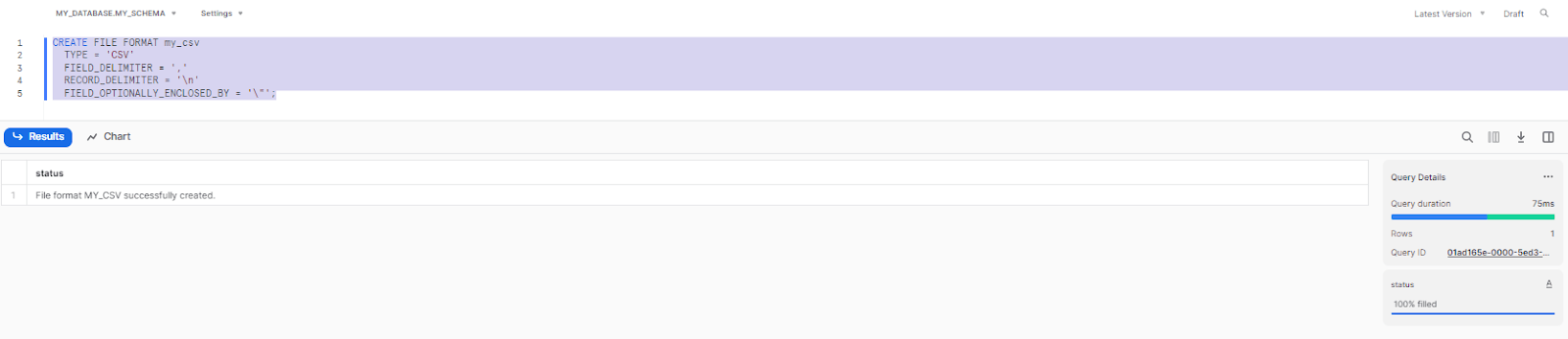
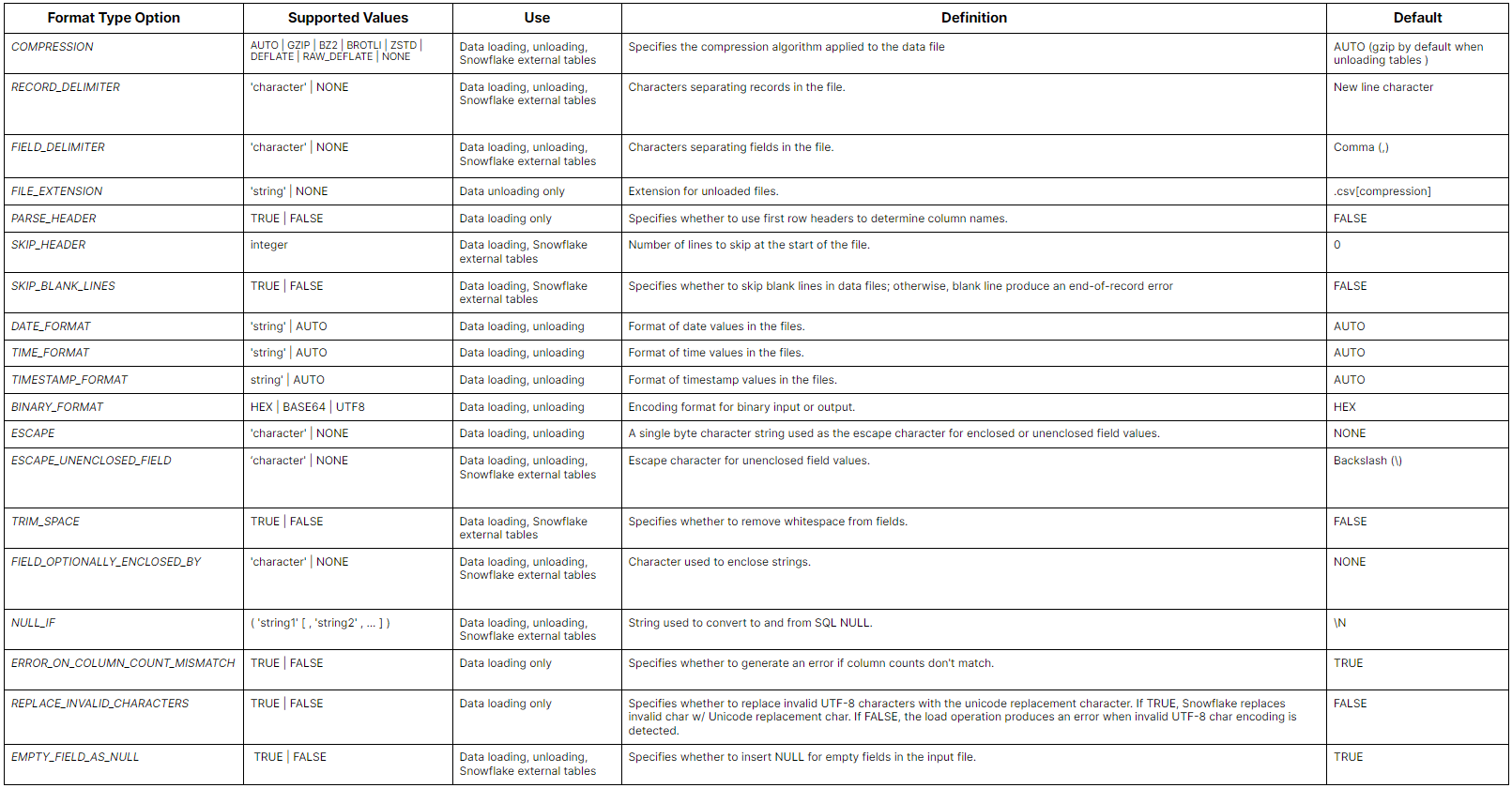
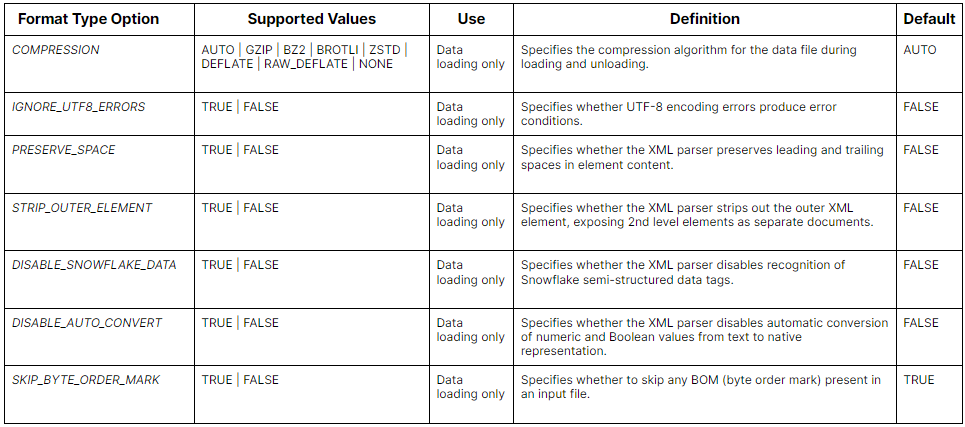
Here is a table summarizing the Snowflake File Format Type Options:
For CSV files:
2) Snowflake File Format JSON:
CREATE FILE FORMAT my_json
TYPE = 'JSON'; 
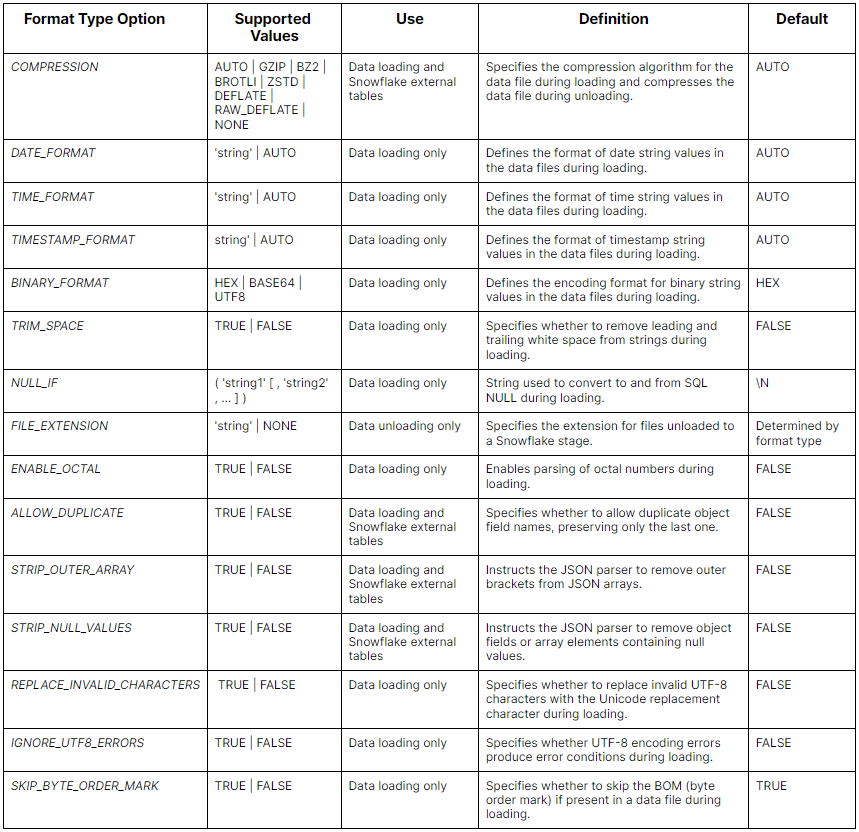
Here is a table summarizing the Snowflake File Format Type Options:
For JSON files:
3) Snowflake File Format Avro:
CREATE FILE FORMAT my_avro
TYPE = 'AVRO'
COMPRESSION = 'auto';
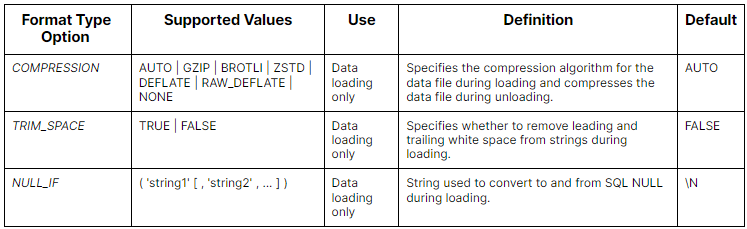
Here is a table summarizing the Snowflake File Format Type Options:
For AVRO files:
4) Snowflake File Format ORC:
CREATE FILE FORMAT my_orc
TYPE = 'ORC'; 
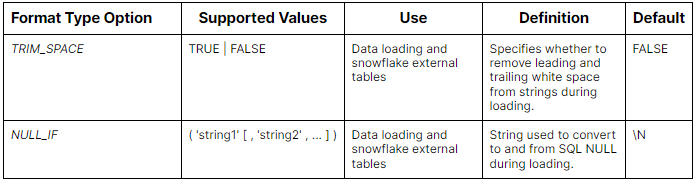
Here is a table summarizing the Snowflake File Format Type Options:
For ORC files:
5) Snowflake File Format Parquet:
CREATE FILE FORMAT my_parquet
TYPE = 'PARQUET'
COMPRESSION = 'snappy';
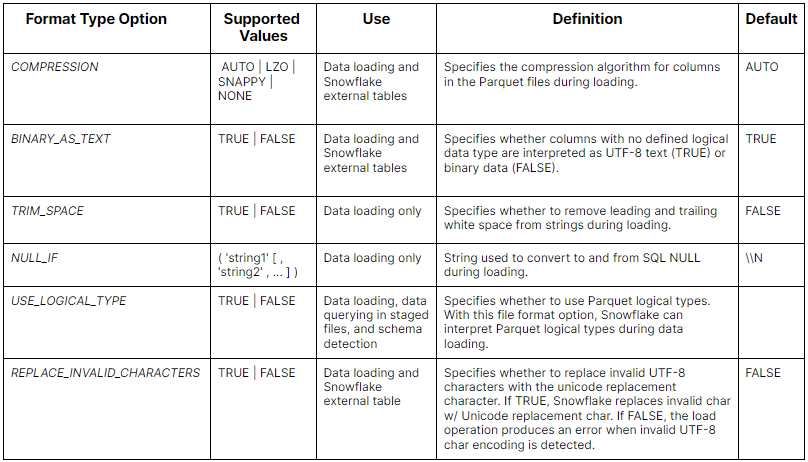
Here is a table summarizing the Snowflake File Format Type Options:
For PARQUET files:
6) Snowflake File Format XML:
CREATE FILE FORMAT my_xml
TYPE = 'XML'
STRIP_OUTER_ELEMENT = 'true'
ENABLE_SNOWFLAKE_DATA = 'true';
Here is a table summarizing the Format Type Options:
For XML files:
These are examples of how to create Snowflake file formats. For more in-depth information, please refer to the Snowflake documentation.
Use Cases for Snowflake File Formats
Snowflake File Formats are commonly utilized in three primary use cases:
- Loading data into Snowflake tables: When you load data from internal Snowflake stage or external Snowflake stage into Snowflake tables, you specify a file format that matches your data files. This tells Snowflake how to parse and interpret your data.
- Unloading data from Snowflake tables: Whenever you unload data from Snowflake tables into internal Snowflake stage or external Snowflake stage, you specify a file format to determine how the data files should be structured and formatted.
- Creating Snowflake External Tables: Snowflake External Tables allow you to query data stored in external Snowflake stages without loading it into Snowflake tables. You specify a file format when creating the external table to define how Snowflake should parse the external data files.
Here is one simple example that shows loading data into the student table from Snowflake stage named my_stage using file format my_csv.
COPY INTO STUDENTS from @my_stage/input.csv
file_format = (format_name = my_csv);Here is another example that shows creating an external table ext_table on top of student files using file format my_csv.
CREATE OR REPLACE EXTERNAL TABLE ext_table
WITH LOCATION = @my_stage_location/
FILE_FORMAT = (format_name = my_csv)
PATTERN='.*students.*[.]csv';Limitations of Snowflake File Formats:
Here are some of the limitations and restriction of Snowflake file formats:
- Snowflake File format types are limited to - CSV, JSON, AVRO, ORC, PARQUET, XML. Snowflake currently only supports these format types.
- File compression formats are limited to - GZIP, BZ2, ZSTD, DEFLATE, RAW (no compression). Snowflake only supports these compression codecs for file formats.
- Schema must match the table schema. The schema defined in the file format (if any) must match the schema of the Snowflake table. Otherwise the COPY or CREATE EXTERNAL TABLE statement will fail.
- Partitioning is only supported for a few types. Partitioning (loading subsets of data into tables based on partition keys) is only supported for ORC, PARQUET and JSON file formats currently.
Managing Snowflake File Formats
Snowflake file formats provides several operations for managing file formats, which allows users to modify, drop, show, and describe existing Snowflake file formats. These operations offer flexibility and control over the formatting options used for loading and unloading data in Snowflake.
ALTER Snowflake File Format:
ALTER FILE FORMAT command is used to modify existing file formats in Snowflake. It allows users to update designated properties of a file format to align with their specific needs. However, certain constraints apply; not all parameters are modifiable using this command. In cases where certain parameters must be changed, it becomes necessary to drop and subsequently recreate the file format.
Here is one example to change the compression method of a file format named "my_format" to GZIP, the following query can be executed:
ALTER FILE FORMAT my_format SET COMPRESSION = GZIP;Let’s modify our Snowflake file format for the example we provided earlier:
ALTER FILE FORMAT my_csv SET COMPRESSION = GZIP;
SHOW Snowflake File Format:
SHOW FILE FORMATS command provides a list of all the Snowflake file formats available. This query is useful for users to view the existing Snowflake file formats and their properties. For example, to retrieve the list of file formats, the following query can be executed:
SHOW FILE FORMATS;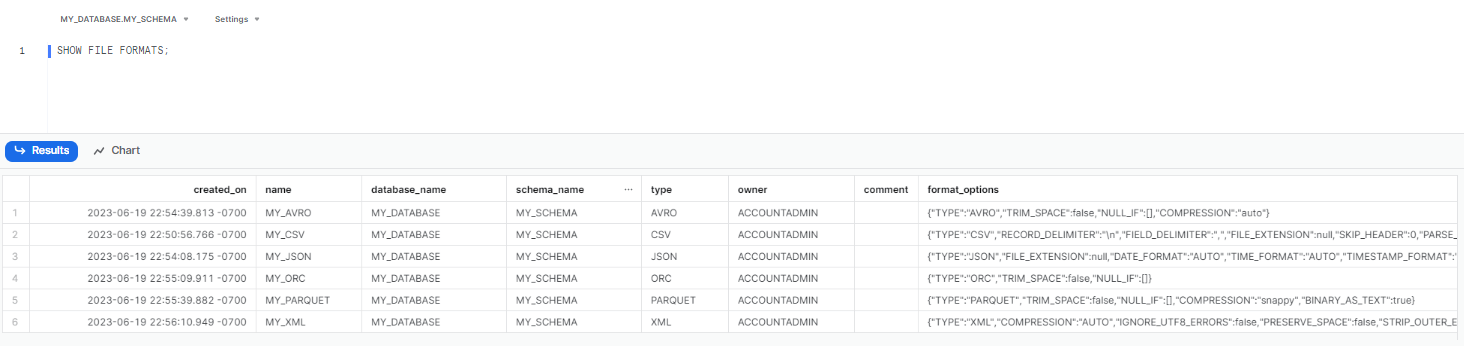
DESCRIBE Snowflake File Format:
DESCRIBE FILE FORMAT provides detailed information about a specific file format in Snowflake. It displays the properties and settings associated with the file format. For example, to describe the file format named "my_format," the following query can be used:
DESCRIBE FILE FORMAT my_format;Let’s take an example we provided earlier:
DESCRIBE FILE FORMAT my_csv;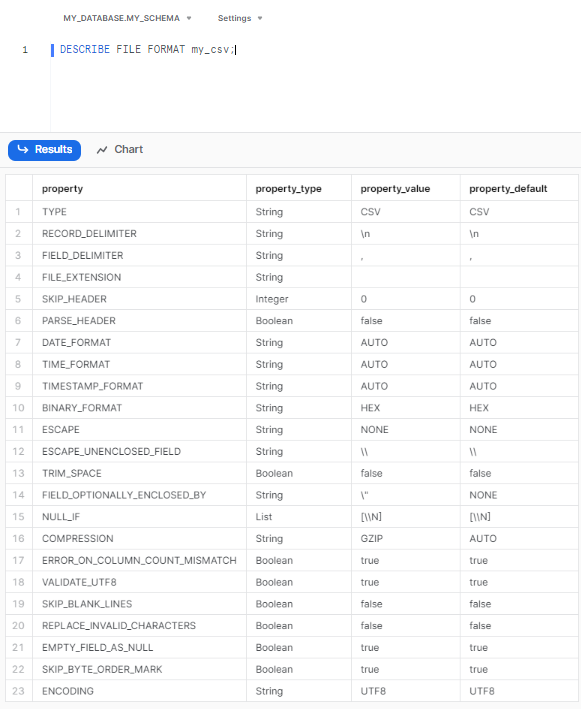
DROP Snowflake File Format:
DROP FILE FORMAT command allows users to delete an existing file format from the Snowflake database. This operation is useful when a file format is no longer needed or has become obsolete. To drop a file format named "my_format" the following query can be used:
DROP FILE FORMAT my_format;Let’s delete our previously created Snowflake file format;
DROP FILE FORMAT MY_CSV;
-- DROP FILE FORMAT MY_JSON;
-- DROP FILE FORMAT MY_AVRO;
-- DROP FILE FORMAT MY_ORC;
-- DROP FILE FORMAT MY_PARQUET;
-- DROP FILE FORMAT MY_XML;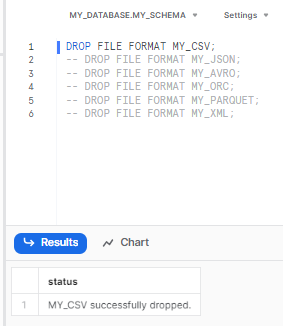
These operations allow users to easily manage their Snowflake file formats, allowing them to tailor the formatting options to their specific needs.
Performance Benchmarks of Snowflake File Formats
The type of file format you choose has a big effect on how quickly Snowflake loads data, how well it runs queries, and how much storage it uses.
Data Loading Speed
- Gzipped CSV files can provide incredibly quick initial bulk loading speeds, possibly surpassing columnar formats like Parquet and ORC. But note that use gzipped CSV only when your source is CSV and converting costs outweigh benefits.
- Don't assume that ingestion is always accelerated by conversion to Parquet. Converting data adds CPU and I/O overhead that can negate gains for one-off bulk loads.
- Snowflake shipped a vectorized scanner that dramatically speeds Parquet loads. Their benchmark tests show substantial ingest gains, making Parquet the preferred ingest format in many cases.
Optimal file sizing for load parallelism
- Aim for compressed file sizes between 100 and 250 MB to optimize cost and parallelism. Avoid many tiny files (<10 MB) and avoid extremely large files (for example >100 GB).
Query performance
- Columnar formats such as Parquet and ORC reduce I/O for analytic queries. They greatly reduce I/O operations and increase query speed by storing data column-wise, which enables query engines to read only the required columns, especially for queries involving a subset of columns.
- Snowflake stores semi-structured data in VARIANT with subcolumnar extraction up to implementation limits. Querying hot, fixed-schema fields from VARIANT is commonly slower than querying native table columns.
External tables and file statistics
- External tables read files from cloud storage and yield a VARIANT value by default. Query performance depends on file layout and available file-level statistics. Missing or incorrect statistics force Snowflake to scan files, which slows queries and refresh operations. Keep Parquet row groups and statistics well formed and use recommended file sizes.
TL;DR:
- Use Parquet/ORC for analytics and repeat queries.
- Use gzipped CSV for fast one-time bulk loads from native CSV sources, and only after validating cost vs conversion.
- Keep compressed files 100–250 MB. Merge or split files to hit that range.
- Make sure Parquet writers emit column statistics for external tables.
- If queries reference the same fields in VARIANT repeatedly, extract them to regular columns.
How File Formats Drive Snowflake Costs
Snowflake file format choices can also impact Snowflake costs in a few ways:
Storage costs
Snowflake bills storage at a flat TB/month rate, based on compressed size of data. Importantly, Snowflake automatically compresses all table data, so the storage used in Snowflake tables is the size after Snowflake’s internal compression. (Your choice of file format does not affect how Snowflake compresses the final table – CSV or Parquet, the table data will be compressed similarly in micro-partitions.) But, staged files (in an internal or external stage) are charged by their actual file size. Thus, storing raw CSV in a stage costs more than gzipped CSV or Parquet. Utilize compressed file formats (COMPRESSION='GZIP' on text formats) or naturally compact formats (Parquet/ORC) to reduce storage costs for staged data.
Compute costs
Snowflake compute usage is charged by warehouse usage: credits consumed = (credits/hour for size) × (run time). Since larger warehouses cost more per hour, there’s a trade-off. In many loading scenarios, a bigger warehouse will finish faster but cost about the same total credits (because 2× throughput at 2× credits/hour ≈ same credits). In practice, choose the smallest warehouse that meets your latency needs and always suspend it when idle to avoid extra charges.
Data transfer costs
If you unload data to external cloud storage in another region or cloud, Snowflake (and the cloud provider) may charge egress fees. Say, unloading to an S3 bucket in a different AWS region incurs transfer charges. Using a compressed output format (e.g. Parquet with Snappy) reduces the number of bytes transferred and thus saves on egress fees. Likewise, if you rely on an external stage (e.g. S3/Azure) for loading data, you’ll pay cloud storage costs for whatever you upload; again, compression helps reduce those costs. Snowflake itself does not charge for data ingress, but it does charge for egress outside your region. (Unloading within the same region is free for Snowflake credit, though you still pay cloud network fees if crossing accounts).
So to cut down on storage and transfer expenses, compress your staged files whenever you can. It may be cheaper to use Parquet/ORC than raw CSV, but keep in mind that Snowflake only charges for the compute time and the bytes you upload. The rest is handled by Snowflake's internal table compression, so the file format selection has no effect on monthly table-storage billing after data has been loaded.
Save up to 30% on your Snowflake spend in a few minutes!


Conclusion
Snowflake file formats are a handy tool for simplifying and streamlining data ingestion in Snowflake. They provide a structured method for defining the type, format, and compression of files in Snowflake stages, making them easily accessible as tables. Using Snowflake file formats, you can turn a jumble of files in a Snowflake stage into neatly organized, query-ready data.
Imagine Snowflake file formats as the GPS of a large ship navigating the vast ocean of data. Each data type or format represents a different destination, and the GPS—our Snowflake file format—guides us to them. It's not just about reaching the destination, but understanding the route, knowing which destinations to choose, and how to best navigate the journey.
FAQs
What is Snowflake stage?
A Snowflake stage is a location where data can be stored within the Snowflake data warehouse. It can be thought of as a folder or directory within the Snowflake environment where data files in various formats (such as CSV, JSON, or Parquet) can be stored and accessed by Snowflake users.
What is the difference between Snowflake stage and External Tables?
A Snowflake stage is a storage location for data files, whereas an external table is a virtual table that points to data stored outside Snowflake. The key difference is that a stage loads data into Snowflake, while an external table enables querying of data located external to Snowflake.
What is the difference between external table and regular table in Snowflake?
External tables reference external data sources. Regular tables store data natively within Snowflake.
What is the difference between Snowpipe and Snowflake external table?
Snowpipe in Snowflake is an automated data ingestion service that continuously loads data from external sources into Snowflake tables. On the other hand, an external table is a virtual table that references data stored outside of Snowflake.
What are the supported Snowflake file formats?
Snowflake supports a variety of file formats, including CSV, JSON, Avro, Parquet, ORC, and XML.
How do you use a file format in Snowflake?
Create it with CREATE FILE FORMAT, specifying the format type, compression, encoding, etc. Use it when loading/unloading data.
What is default Snowflake file format?
The default Snowflake file format is CSV. This means that if you do not specify a file format when loading or unloading data, Snowflake will use the CSV format.
What is the best Snowflake file format?
It depends on use case. Parquet/ORC for structured data, JSON/Avro for semi-structured, CSV for simple use cases. Consider size, performance, compression.
How do I get a list of Snowflake file formats in a Snowflake?
Use SHOW FILE FORMATS to display names, types, and properties of existing file formats.















