





























So you've got a massive dataset on your hands, and one of the first things you need to know is how many rows or records it contains. This is a must-have for data analysis and reporting. It gives you a sense of the data's size, helps you identify patterns, and ensures your reports are on point. In Snowflake, counting rows is a breeze. You can use the Snowflake COUNT function, which is super versatile and fast. It helps you count rows efficiently and accurately in all sorts of situations.
In this article, we will cover everything you need to know about the Snowflake COUNT function, exploring its different types, practical applications, and best practices.
Let's jump right in and start counting!
What Is COUNT() in Snowflake?
The Snowflake COUNT function is an aggregate function used to count the number of rows that match a specified condition. It can count all rows, count rows with non-NULL values in a specific column, or count distinct values. The primary purpose of using the COUNT function is to provide accurate counts of rows, which is essential for data aggregation, summarization, and reporting.
Purpose of Using Snowflake COUNT
The main purpose of using the Snowflake COUNT function is to get a quick numerical summary of your data. Here are some common scenarios where Snowflake COUNT is useful:
- Getting the total number of records in a table
- Counting how many times a specific value appears
- Checking for the presence of non-NULL values
- Performing grouped counts
- Validating data completeness or identifying gaps
Now that we've got the basics down, let's look at the different ways you can use COUNT in Snowflake.'
Save up to 30% on your Snowflake spend in a few minutes!


What Are the Types of Snowflake COUNT Functions?
Snowflake offers several variants of the COUNT function, each with its own specific use. Let's break them down:
1) Snowflake COUNT(*)
The Snowflake COUNT(*) function counts all rows in a table or result set, including duplicate rows and rows containing NULL values. It's your go-to when you need a quick headcount of your entire dataset.
Syntax and Examples
SELECT COUNT(*) FROM your_table;Snowflake COUNT(*) syntax
For example, if you want to know how many orders you've received:
SELECT COUNT(*) AS total_orders FROM orders;Snowflake COUNT(*) example
Or
If you want to know the total number of employees in the employees table:
SELECT COUNT(*) AS total_employees FROM employees;Snowflake COUNT(*) example
Easy peasy, right? But wait, there's more!
2) Snowflake COUNT(column_name)
The Snowflake COUNT(column_name) function counts the number of non-NULL values in a specific column. It's perfect when you want to count occurrences of a particular attribute or check for data completeness in a column.
How does it differ from Snowflake COUNT(*)?
COUNT(*) counts every row, even if all columns in a row are NULL. In contrast, COUNT(column_name) explicitly ignores NULL values in the specified column. This distinction is crucial when dealing with sparse data or columns that allow NULLs.
Syntax and Examples
SELECT COUNT(column_name) FROM your_table;Snowflake COUNT(column_name) syntax
For example, let's say you want to count how many customers have provided their email addresses:
SELECT COUNT(email) AS total_emails FROM customers;Snowflake COUNT(column_name) example
If the number of emails is less than the total number of customers, you know some customers haven't provided their email addresses.
3) Snowflake COUNT(DISTINCT column_name)
Last but not least, we have Snowflake COUNT(DISTINCT column_name).
Snowflake COUNT(DISTINCT column_name) function counts the number of distinct non-NULL values in a column. It helps in identifying unique entries within a dataset, ignoring all duplicates.
Use this when you need to know how many different values exist in a column, regardless of how many times each value appears.
How does it differ from Snowflake COUNT(*)?
Snowflake COUNT(*) gives you the total number of rows, whereas Snowflake COUNT(DISTINCT column_name) tells you how many unique values exist in a specific column.
Syntax and Examples
SELECT COUNT(DISTINCT column_name) FROM your_table;Snowflake COUNT(DISTINCT column_name) syntax
For example, if you want to know how many different products you've sold:
SELECT COUNT(DISTINCT product_id) AS unique_products_sold FROM sales;Snowflake COUNT(DISTINCT column_name) example
This tells you that out of all your sales, a certain number of products were purchased, regardless of how many times each product was sold.
But wait, there's more! What if you want to count only certain things based on a condition?
Snowflake COUNT with Conditions — COUNT_IF
Sometimes, you don't want to count every single thing. You want to count only the things that meet certain criteria. That's where Snowflake COUNT_IF comes to the rescue.
Snowflake COUNT_IF function allows for conditional counting, where only rows that meet a specified condition are counted.
Basic Syntax and Usage of Snowflake COUNT_IF(condition)
Basic Syntax:
Here's how you use this function:
SELECT COUNT_IF(condition) FROM table_name;Snowflake COUNT_IF(condition) syntax
Parameters:
- condition: This is a boolean expression that determines which rows to count. If the condition is true for a row, that row is counted.
Example:
For example, let's say you want to count orders over $1000:
SELECT COUNT_IF(order_total > 1000) AS high_value_orders
FROM orders;Snowflake COUNT_IF(condition) example
Or
If you want to count the number of rows in the orders table where the status is “completed”.
SELECT COUNT_IF(status = 'completed') AS completed_orders FROM orders;Snowflake COUNT_IF(condition) example
Pretty easy, right?
Snowflake's COUNT_IF is very powerful. It can simplify your queries and make your code easier to read. You can ditch those crazy-long WHERE clauses or CASE statements inside a COUNT. With COUNT_IF, you can get the same result in a way that's much more straightforward and more elegant.
Now that you have a good grasp on Snowflake's COUNT function, let's compare it with other aggregate functions.
What Is the Difference Between SUM and COUNT in Snowflake?
Both Snowflake SUM and Snowflake COUNT are aggregate functions, they serve different purposes. Let's break down the differences:
| Snowflake SUM | Snowflake COUNT |
| Snowflake SUM is used to compute the total sum of a set of numeric values | Snowflake COUNT counts the number of non-NULL values (or all values if using COUNT(*)) |
| Snowflake SUM accepts numeric expressions, which can include integer, float, and decimal types | Snowflake COUNT can be used on any data type, including numeric, string, and date types |
| Snowflake SUM ignores NULL values in its computation | Snowflake COUNT also ignores NULL values when counting specific columns, but COUNT(*) includes all rows regardless of NULLs |
| Snowflake SUM returns a numeric type, which is the same or a larger type than the input to accommodate the sum | Snowflake COUNT returns an integer |
| Snowflake SUM is ideal for aggregating numerical data, such as computing total sales, total expenses, or any other sum aggregation | Snowflake COUNT is useful for counting rows, counting occurrences of a specific condition, or counting non-NULL entries in a column |
| Snowflake SUM can be used as a window function with the OVER clause to perform calculations over a subset of rows defined by the window | Snowflake COUNT can also be used as a window function with the OVER clause |
|
Syntax: SUM([DISTINCT] <expr1>) |
Syntax: COUNT([DISTINCT] <expr1>) or COUNT(*) |
As you can see, COUNT is primarily about quantity, while SUM is about total value.
What Is the Difference Between MAX and COUNT in Snowflake?
Now let's compare Snowflake COUNT with Snowflake MAX:
| Snowflake MAX | Snowflake COUNT |
| Snowflake MAX returns the largest value in a specified column. It's often used to find the maximum value within a dataset | Snowflake COUNT returns the number of non-NULL records in a specified column. It can also return the total number of records, including NULLs, when using COUNT(*) |
| Snowflake MAX returns a value with the same data type as the input values (e.g., NUMBER, FLOAT) | Snowflake COUNT returns a NUMBER indicating the count of records |
| Snowflake MAX ignores NULL values unless all records are NULL, in which case it returns NULL | Snowflake COUNT ignores NULL values when using COUNT( <expr> ); includes NULLs when using COUNT( * ) |
| Snowflake MAX can be used with GROUP BY to find the maximum value in each group | Snowflake COUNT can be used with GROUP BY to count records in each group |
| Snowflake MAX can be used with the OVER clause to find maximum values over a partitioned window | Snowflake COUNT can be used with the OVER clause to count records over a partitioned window |
| Syntax: MAX( <expr> ) |
Syntax: COUNT( <expr> ) or COUNT( * ) |
What Is the Difference Between MIN and COUNT in Snowflake?
Lastly, let's look at how Snowflake COUNT compares to Snowflake MIN:
| Snowflake MIN | Snowflake COUNT |
| Snowflake MIN returns the smallest value in a specified column. It's often used to find the minimum value within a dataset. | Snowflake COUNT returns the number of non-NULL records in a specified column. It can also return the total number of records, including NULLs, when using COUNT(*). |
| Snowflake MIN returns a value with the same data type as the input values (e.g., NUMBER, FLOAT). | Snowflake COUNT returns a NUMBER indicating the count of records. |
| Snowflake MIN ignores NULL values unless all records are NULL, in which case it returns NULL. | Snowflake COUNT ignores NULL values when using COUNT(<expr>); includes NULLs when using COUNT(*). |
| Snowflake MIN can be used with GROUP BY to find the minimum value in each group. | Snowflake COUNT can be used with GROUP BY to count records in each group. |
| Snowflake MIN can be used with the OVER clause to find minimum values over a partitioned window. | Snowflake COUNT can be used with the OVER clause to count records over a partitioned window. |
| Syntax: MIN(<expr>) |
Syntax: COUNT([DISTINCT] <expr1>) or COUNT(*) |
TL;DR: Differences Between COUNT and Other Aggregates
| Function | Purpose | Ignores NULLs? | Return Type | Can be Window? |
|---|---|---|---|---|
| SUM | Adds numeric values | Yes | Same/larger numeric as input | Yes |
| COUNT | Counts rows/values | Yes (except COUNT(*)) | NUMBER | Yes |
| MAX | Largest value | Yes (returns NULL if all NULL) | Same as input | Yes |
| MIN | Smallest value | Yes (returns NULL if all NULL) | Same as input | Yes |
Practical Examples of Using Snowflake COUNT Function
Let's dive into some real-world examples using the Snowflake COUNT function. We'll start by creating a Students table and populating it with some dummy data. Then, we'll explore various ways to use Snowflake COUNT on this dataset.
Setting Up Our Sample Data
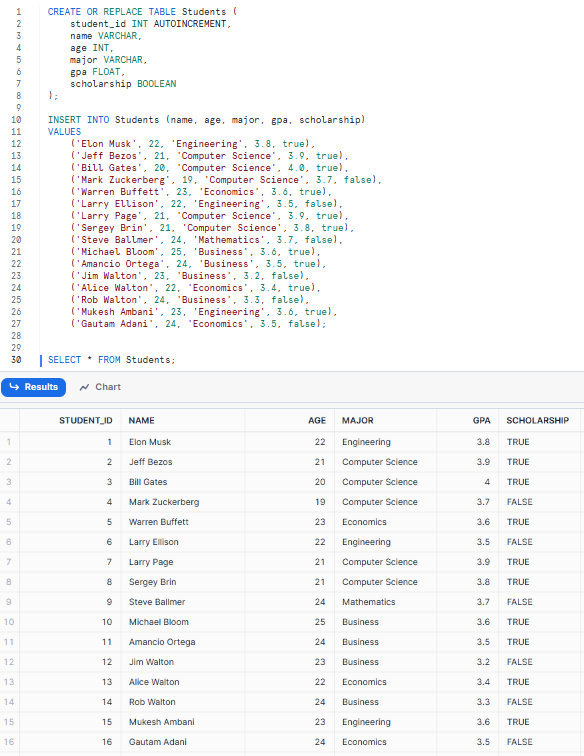
First, let's create our Students table and insert some dummy data:
CREATE OR REPLACE TABLE Students (
student_id INT AUTOINCREMENT,
name VARCHAR,
age INT,
major VARCHAR,
gpa FLOAT,
scholarship BOOLEAN
);
INSERT INTO Students (name, age, major, gpa, scholarship)
VALUES
('Elon Musk', 22, 'Engineering', 3.8, true),
('Jeff Bezos', 21, 'Computer Science', 3.9, true),
('Bill Gates', 20, 'Computer Science', 4.0, true),
('Mark Zuckerberg', 19, 'Computer Science', 3.7, false),
('Warren Buffett', 23, 'Economics', 3.6, true),
('Larry Ellison', 22, 'Engineering', 3.5, false),
('Larry Page', 21, 'Computer Science', 3.9, true),
('Sergey Brin', 21, 'Computer Science', 3.8, true),
('Steve Ballmer', 24, 'Mathematics', 3.7, false),
('Michael Bloom', 25, 'Business', 3.6, true),
('Amancio Ortega', 24, 'Business', 3.5, true),
('Jim Walton', 23, 'Business', 3.2, false),
('Alice Walton', 22, 'Economics', 3.4, true),
('Rob Walton', 24, 'Business', 3.3, false),
('Mukesh Ambani', 23, 'Engineering', 3.6, true),
('Gautam Adani', 24, 'Economics', 3.5, false);
SELECT * FROM Students;
Creating Students table and inserting some dummy data - Snowflake row count
Now that we have our sample data, let's explore some practical examples using the COUNT function.
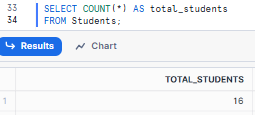
Example 1—Counting Rows in a Table Using Snowflake COUNT
Let's start with the most basic use of Snowflake COUNT—finding the total number of students in our table.
SELECT COUNT(*) AS total_students
FROM Students;This might return:
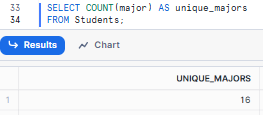
Example 2—Counting Non-Null Values
Let's count the number of majors in the student's table.
SELECT COUNT(column_name) AS unique_majors
FROM Students;This could give us:
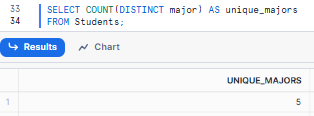
Example 3—Counting Distinct Values
Now, let's find out how many different majors our students are pursuing.
SELECT COUNT(DISTINCT major) AS unique_majors
FROM Students;This could give us:
Example 4—Using COUNT_IF for Conditional Counting
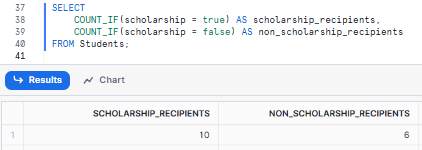
Let's use Snowflake COUNT_IF to count scholarship recipients and non-recipients in a single query.
SELECT
COUNT_IF(scholarship = true) AS scholarship_recipients,
COUNT_IF(scholarship = false) AS non_scholarship_recipients
FROM Students;This could give us:
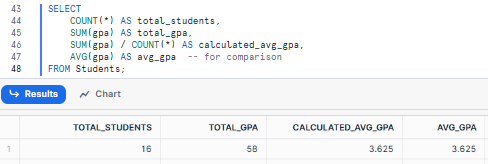
Example 5—Combining Snowflake COUNT with SUM
Let's calculate the total GPA (sum), the number of students (count), and use these to derive the average GPA.
SELECT
COUNT(*) AS total_students,
SUM(gpa) AS total_gpa,
SUM(gpa) / COUNT(*) AS calculated_avg_gpa,
AVG(gpa) AS avg_gpa -- for comparison
FROM Students;This could give us:
As you can see, this example combines COUNT with MIN and MAX to give an overview of GPA ranges within each major.
Example 6—Combining Snowflake COUNT with MIN
Now, let's find the count of students and the age of the youngest student for each major.
SELECT
major,
COUNT(*) AS student_count,
MIN(age) AS youngest_student_age
FROM Students
GROUP BY major
ORDER BY youngest_student_age;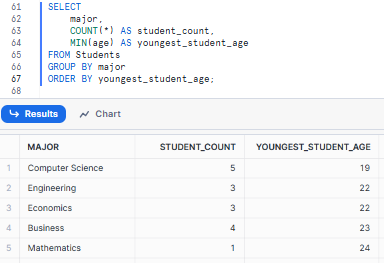
As you can see, how combining Snowflake COUNT and MIN can give us insights into the age distribution within each major.
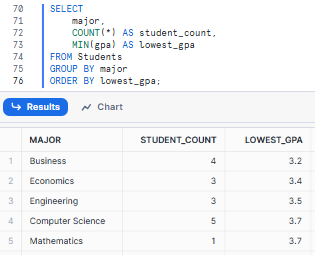
Let's try another example and analyze the lowest GPA in each major along with the student count.
SELECT
major,
COUNT(*) AS student_count,
MIN(gpa) AS lowest_gpa
FROM Students
GROUP BY major
ORDER BY lowest_gpa;Combining Snowflake COUNT with MIN - Snowflake row count
This could give us:
Example 7—Combining Snowflake COUNT with MAX
Let's find the count of students, the age of the oldest student, and the highest GPA for each major.
SELECT
major,
COUNT(*) AS student_count,
MAX(age) AS oldest_student_age,
MAX(gpa) AS highest_gpa
FROM Students
GROUP BY major
ORDER BY highest_gpa DESC;Combining Snowflake COUNT with MAX - Snowflake row count
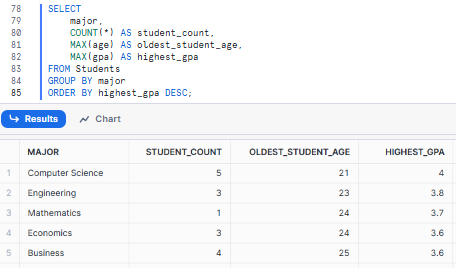
That is it! This is only the tip of the iceberg in terms of what the Snowflake COUNT function is capable of! You may also combine it with tons of other SQL functions to gain valuable insights from your data.
Common Errors with Snowflake COUNT and How to Fix Them
The Snowflake COUNT function is straightforward and user-friendly, but you might encounter some common mistakes and issues while using it.
1) Misunderstanding NULL handling: COUNT(*) vs COUNT(expression)
The Issue:
A common misconception is assuming that COUNT(*) ignores rows containing NULL values in any column. This is incorrect. COUNT(*) counts rows. COUNT(expression) counts only rows where expression is not NULL. This distinction is vital for accurate data analysis, especially with sparse datasets.
Fixes / examples:
- To count all rows (including rows where some columns are
NULL):
SELECT COUNT(*) FROM my_schema.my_table;- To count non-null values of a column:
SELECT COUNT(some_col) FROM my_schema.my_table;- To inspect NULLs before you count:
SELECT
COUNT(*) AS total_rows,
COUNT(some_col) AS non_null_some_col,
SUM(CASE WHEN some_col IS NULL THEN 1 ELSE 0 END) AS null_some_col
FROM my_schema.my_table;Tip. If you need explicit control, test col IS NULL or col IS NOT NULL in WHERE to make intent explicit.
2) Performance assumptions: "COUNT(column) is slower than COUNT(*)"
The Issue:
Many users assume COUNT(column_name) is significantly slower than COUNT(*) because it appears to necessitate a scan of the specified column.
The Reality:
Snowflake's architecture and advanced query optimizer frequently render performance differences negligible for simple COUNT queries. Snowflake maintains rich metadata statistics at the micro-partition level, including row counts and column statistics. For unfiltered COUNT queries, both COUNT(*) and COUNT(column_name) can leverage these metadata statistics without requiring a full table scan, provided the column doesn't have an extremely high NULL percentage that would invalidate metadata.
Fix:
- For pure row counting without conditional logic, COUNT(*) is generally the optimal and most idiomatic choice.
- When filtering is involved, ensure appropriate clustering keys are defined on the filter columns to aid micro-partition pruning.
- Always use EXPLAIN or the Query Profile in your specific environment to understand the actual execution plan and avoid making assumptions.
3) Query profile numbers look odd vs final results (rewrites, limits, and planner tricks)
The Issue:
The Query Profile may display step-specific row counts that do not directly correspond to the final output row count, which can be confusing.
Why:
Snowflake's query planner is sophisticated; it rewrites queries and displays logical steps that may involve intermediate row sets. For example, some steps might show rows before a LIMIT clause, TOP clause, or late-stage filter reduces them. Additionally, materialized internal steps and predicate pushdowns can alter what is scanned versus what is ultimately returned.
Fix:
- Utilize
EXPLAINor the Query Profile to meticulously inspect both logical and physical execution steps. Pay close attention to steps labeled Limit or Aggregate to identify where row reduction occurs. - For debugging, simplify complex queries or add a
LIMITclause to isolate planner behavior and compare intermediate results, distinguishing them from data-related issues.
4) Deduplication mistakes when using COUNT(DISTINCT)
The Issue:
Using COUNT(DISTINCT ...) on tables that contain duplicate ingestion events or on data that should have been deduped earlier hides the real issue and may give wrong business answers. COUNT(DISTINCT) can be expensive on high-cardinality fields.
Fix:
- Remove duplicates deliberately before counting. Common patterns:
- Use
QUALIFYwithROW_NUMBER()to pick one row per business key, then count.
- Use
with dedup as (
select * ,
row_number() over (partition by id order by load_time desc) rn
from raw_table
)
select count(*) from dedup where rn = 1;QUALIFYcan be used inline:select ... from raw_table qualify row_number() over (partition by id order by load_time desc) = 1.- Use
MERGE(upsert) during ingestion to prevent duplicates entering the target table. MERGE is atomic and reduces downstream dedupe pain. - If you only need an estimate,
APPROX_COUNT_DISTINCTis much faster and uses HyperLogLog. Use it when a probabilistic answer is acceptable.
5) Row access policies can change cost and results for COUNT
Problem:
Row access policies applied to a table may force Snowflake to evaluate a policy expression per row. That can prevent metadata-only optimizations and cause higher scan costs. It also changes which rows are visible and therefore the count.
Fix:
Know where policies are applied. The engine effectively creates a secure, dynamic view at runtime to enforce the policy. If counting, test performance with and without the policy in a controlled environment. If policies are broad or call external lookups, they will affect cost. Consider moving complex checks to precomputed flags or centralized mapping tables referenced efficiently.
6) Using metadata views for fast row estimates and when they mislead
Snowflake exposes metadata views such as INFORMATION_SCHEMA.TABLES and INFORMATION_SCHEMA.TABLE_STORAGE_METRICS which include ROW_COUNT and storage metrics. These are updated periodically and are fast to query. They are not always real-time to the millisecond.
When to use them:
- Use metadata views for dashboards, monitoring, and quick checks across many tables.
- Do not use them as the single source of truth for legal or billing reconciliation without understanding their update lag. If you need an exact, current row count, run
SELECT COUNT(*)in a transaction or a reliable reporting process.
Quick checklist to avoid common Snowflake COUNT mistakes
- Clearly decide whether you need total rows (COUNT(*)), non-NULL values (COUNT(col)), or unique values (COUNT(DISTINCT col)).
- For very large tables, test query performance. Consider using clustering keys, filters, or APPROX_COUNT_DISTINCT when exact counts are prohibitively expensive.
- Dededuplicate data upstream during ingestion using MERGE, QUALIFY + ROW_NUMBER(), or INSERT OVERWRITE patterns.
- If query results and the Query Profile appear inconsistent, meticulously analyze the profile and EXPLAIN the query. Look for late-stage filters, limits, or planner rewrites.
- Be aware that row access policies can dynamically alter both result visibility and query performance. Test their impact and, if necessary, redesign policies for high-volume counting operations.
Best Practices of Using Snowflake COUNT Function
Now that we've explored the ins and outs of the COUNT function, let's talk about how to use it effectively. Here are some best practices to keep in mind:
1) Use Snowflake COUNT(*) for Total Row Counts
So you want to count all the rows, including the ones with NULL values? Snowflake COUNT(*) is your best bet. It's optimized for this purpose and is generally faster than counting a specific column.
2) Handling NULL Values
Remember that Snowflake COUNT(column_name) ignores NULL values. If you need to include NULL values in your count, use COUNT(*) or COALESCE.
3) Optimizing DISTINCT Counts
Snowflake COUNT(DISTINCT column) can be slow on large datasets. For approximate counts of unique values, consider using Snowflake's HyperLogLog functions like HLL or APPROX_COUNT_DISTINCT.
4) Performance Considerations
For large datasets, COUNT operations can be slow. Here are some tips to improve performance:
a) Minimize the data volume being processed by applying filters early:
Less efficient
SELECT COUNT(*) FROM orders WHERE order_date > '2024-01-01';More efficient
SELECT COUNT(*) FROM orders WHERE order_date > '2024-01-01' AND order_date <= CURRENT_DATE();b) Avoid Complex Views: When possible, count from base tables rather than complex views:
Potentially slow if view_orders is complex
SELECT COUNT(*) FROM view_orders;Potentially faster
SELECT COUNT(*) FROM orders WHERE /* conditions from view */;c) Simplify your queries: Sometimes, simpler queries can be optimized better by Snowflake:
This might be slower
SELECT COUNT(*) FROM (SELECT DISTINCT customer_id FROM orders);This is typically faster
SELECT COUNT(DISTINCT customer_id) FROM orders;5) Use Appropriate Indexes and Clustering Keys
Note that Snowflake doesn't have traditional indexes, it uses micro-partitions and clustering to optimize query performance. So make sure your tables are clustered on frequently filtered columns:
ALTER TABLE orders CLUSTER BY (order_date);This can significantly speed up Snowflake COUNT operations that filter on the clustered column.
6) Use Snowflake COUNT_IF for Complex Conditional Counts
Instead of using subqueries or complex CASE statements, use COUNT_IF for cleaner, more efficient conditional counts.
7) Be Aware of Data Changes
Remember that COUNT results can change if data is being actively inserted or deleted. For consistent results in reports, consider using time-travel queries or snapshots
If you follow these best practices, you'll be able to use the COUNT function more effectively and efficiently in your Snowflake queries.
Further Reading
If you want to get more info about Snowflake COUNT Function, here are some great resources:
- Snowflake COUNT Function Documentation
- Working with Unique Counts
- Snowflake COUNT_IF
- APPROX_COUNT_DISTINCT
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Conclusion
And that's a wrap! You've learned a ton about the Snowflake COUNT function. You now know the basics, advanced techniques, and best practices to count your data like an expert. Remember, Snowflake COUNT is more than just a simple count. It helps you understand your data's structure, check your datasets, and get useful insights. You can use COUNT to count total records, unique values, or subsets based on conditions. It's often the first step in many data analysis tasks. Practice and understand its quirks to get really good at it, and don't forget about performance with large datasets. So, start counting! Your data is waiting to be discovered.
In this article, we have covered:
- What Is COUNT() in Snowflake?
- What are the types of Snowflake COUNT functions?
- What is the difference between SUM and COUNT in Snowflake?
- What is the difference between MAX and COUNT in Snowflake?
- What is the difference between MIN and COUNT in Snowflake?
- Practical Examples of Using Snowflake COUNT Function
- Best practices for using Snowflake COUNT function
…and more!
FAQs
What is the Snowflake COUNT function?
The Snowflake COUNT function returns the number of rows that match a specified condition, including rows with non-NULL values when using COUNT(column) and all rows when using COUNT(*).
Does Snowflake COUNT(*) include NULL values?
Yes, COUNT(*) counts all rows, including those with NULL values in any column.
What is the difference between COUNT(*) and COUNT(column_name)?
COUNT(*) counts all rows, including those with NULL values, whereas COUNT(column_name) counts only non-NULL values in the specified column.
Can Snowflake COUNT be used with conditions?
Yes, COUNT_IF can be used to count rows that meet specific conditions.
How to count distinct values in Snowflake?
Use Snowflake COUNT(DISTINCT column_name) to count distinct non-NULL values in a column.
Can I use Snowflake COUNT with multiple columns?
Yes, you can count distinct combinations of values in multiple columns.
How does Snowflake COUNT work with window functions?
Snowflake COUNT can be used as a window function with the OVER() clause, allowing partitioning and ordering of the result set.
Can I count rows in views?
Yes, Snowflake COUNT can be used on views just like tables. But be mindful of the potential performance impact on large views.
What are approximate distinct count functions in Snowflake?
Functions like APPROX_COUNT_DISTINCT use algorithms to estimate distinct counts, offering faster performance for large datasets.
Can Snowflake COUNT be used in combination with GROUP BY?
Yes, Snowflake COUNT is often used with GROUP BY to count rows within grouped categories.










