





























Databricks—a powerful unified analytics platform for data engineering, data science, big data, analytics, machine learning, and AI—offers a range of data objects such as Catalogs, Databases, Tables, Views, and Functions for structured data management and computation. Of these, tables play a crucial role, offering a structured way to store, query, filter, and aggregate large datasets, making data processing seamless and efficient. But if you want to create a table that is short-lived and scoped to your session, there’s something called Temporary Tables. These tables handle transient or intermediate data operations. Keep in mind that in Databricks, the direct creation of temporary tables using a CREATE TEMPORARY TABLE command isn’t supported. Instead, you can achieve similar functionality with Databricks temporary views. Temporary views are lightweight, session-bound objects that store intermediate results and automatically expire when the session ends. They provide a way to store intermediate results without cluttering your workspace with persistent tables.
In this article, we will cover everything you need to know about Databricks Temporary Views, why you can't use the CREATE TEMPORARY TABLE command, and how Temporary Views can fill the gap. On top of that, we'll also break down the features and best practices for using these views, giving you a clear guide on how to use them.
What Are Temporary Tables in Databricks?
Temporary tables, in general, provide a way to store temporary data within a session. They are session-specific, meaning they exist only for the duration of the user's active session and are automatically dropped when the session ends. Here are some key characteristics of temporary tables:
➥ Session-Specific Scope — Temporary tables are confined to the current user session. They are not visible or accessible to other users or sessions.
➥ In-Memory Storage — Data in temporary tables is typically cached in memory for faster access and processing.
➥ Automatic Cleanup — Temporary tables are removed automatically when the session ends., freeing up resources.
Databricks and Temporary Views
Given that Databricks does not support temporary tables and CREATE TEMPORARY TABLE command directly, Temporary views serve as an effective alternative.
Temporary views in Databricks are essentially named, session-scoped views that offer a virtual representation of data. They don't physically store data but rather define a query that retrieves data from an underlying source, such as a table or DataFrame.
Save up to 50% on your Databricks spend in a few minutes!


What Is a Temporary View in Databricks?
Databricks temporary view is a named, session-scoped view that provides a temporary, in-memory representation of data. It acts as a virtual table, allowing you to query and manipulate data without physically creating a new table. They are:
➥ Session-Specific — Databricks temporary views can only be accessed within the session or notebook where they were created. They cannot be referenced outside of this context.
➥ Session Lifetime — Databricks temporary views are dropped automatically when the session ends or when the notebook is detached from the cluster.
➥ Flexible in Data Handling — They can represent data from SQL queries or DataFrames.
➥ Non-Persistent — Databricks temporary views do not store data permanently in the underlying storage.
GLOBAL TEMPORARY Views
Databricks also supports GLOBAL TEMPORARY views, which are scoped to the entire cluster. These views are accessible across all sessions within the same cluster, providing a way to share temporary data structures across multiple users or applications.
GLOBAL TEMPORARY views are stored in a system-preserved temporary schema called global_temp.
What Is the Difference Between View and Temporary View?
Now that we have discussed what a Databricks table is and what a Databricks temporary view is, let's briefly explore the differences between Databricks views and Databricks temporary views to give you a clear understanding. Let's quickly dive in.
| Databricks View | Databricks Temporary View |
|---|---|
| Databricks Views are persistent and stored in the catalog | Databricks Temporary Views are non-persistent and exist only in the session |
| Scope of Databricks Views is global—accessible across sessions and users | Scope of Databricks Temporary Views is session-specific—accessible only within the creating session |
| Databricks Views have their metadata stored in a metastore (e.g, Hive metastore, Unity Catalog) | Databricks Temporary Views are not stored; they exist in memory only |
| Databricks Views are ideal for reusable, shareable query results | Databricks Temporary Views are suitable for ad-hoc queries or temporary data transformations |
| Databricks Views can have permissions defined via the catalog | Databricks Temporary Views do not have access control and are restricted to the session |
| Databricks Views are created using CREATE VIEW | Databricks Temporary Views are created using CREATE OR REPLACE TEMP VIEW |
| Databricks Views remain until explicitly dropped | Databricks Temporary Views are automatically dropped at session termination |
How to Create Databricks Temporary Table-like Structures Using Temporary Views?
Creating a Databricks temporary table involves using temporary views, as Databricks does not support traditional temporary tables. Here is a detailed guide on how to do this effectively:
Step 1—Start a Databricks Workspace Session
To start working with Databricks, first log in to your Databricks account, then attach your workspace to an active cluster.
Open your workspace and navigate to the "Clusters" tab. Create or select an All-Purpose Databricks compute cluster.

Attach your Databricks notebook to the cluster to execute commands.
Step 2—Prepare/Load the Source Data
Databricks temporary tables require source data to work with. Here’s how you can prepare and load data for use in Databricks.
You can load data into Databricks using SQL queries or programmatically via the DataFrame API. Here’s an example of creating a CollegeStudents table from a CSV file:
Loading Data with Databricks SQL Queries:
CREATE TABLE students (
id INT,
name STRING,
grade INT
)
USING CSV
OPTIONS (path 'dbfs:/FileStore/<file-path>/file.csv', header true);Loading Data with the DataFrame API:
Or if you want to use Python or Scala, you can utilize the DataFrame API to load the data programmatically.
df = spark.read.format("csv").option("header", "true").load("dbfs:/FileStore/<file-path>/students.csv")
df.printSchema()
df.show(5)For this article, we will manually insert some dummy data into the CollegeStudents table for simplicity and better demonstration. You can use this approach to simulate the data setup without relying on external files. Here is a simple example of inserting data:
CREATE TABLE CollegeStudents (
id INT,
name STRING,
grade INT
);
INSERT INTO CollegeStudents VALUES
(1, 'Elon Musk', 93),
(2, 'Jeff Bezos', 90),
(3, 'Bernard Arnault', 78),
(4, 'Warren Buffett', 92),
(5, 'Larry Page', 88),
(6, 'Sergey Brin', 91),
(7, 'Bill Gates', 83),
(8, 'Carlos Slim Helu', 79),
(9, 'Mukesh Ambani', 89),
(10, 'Amancio Ortega', 75);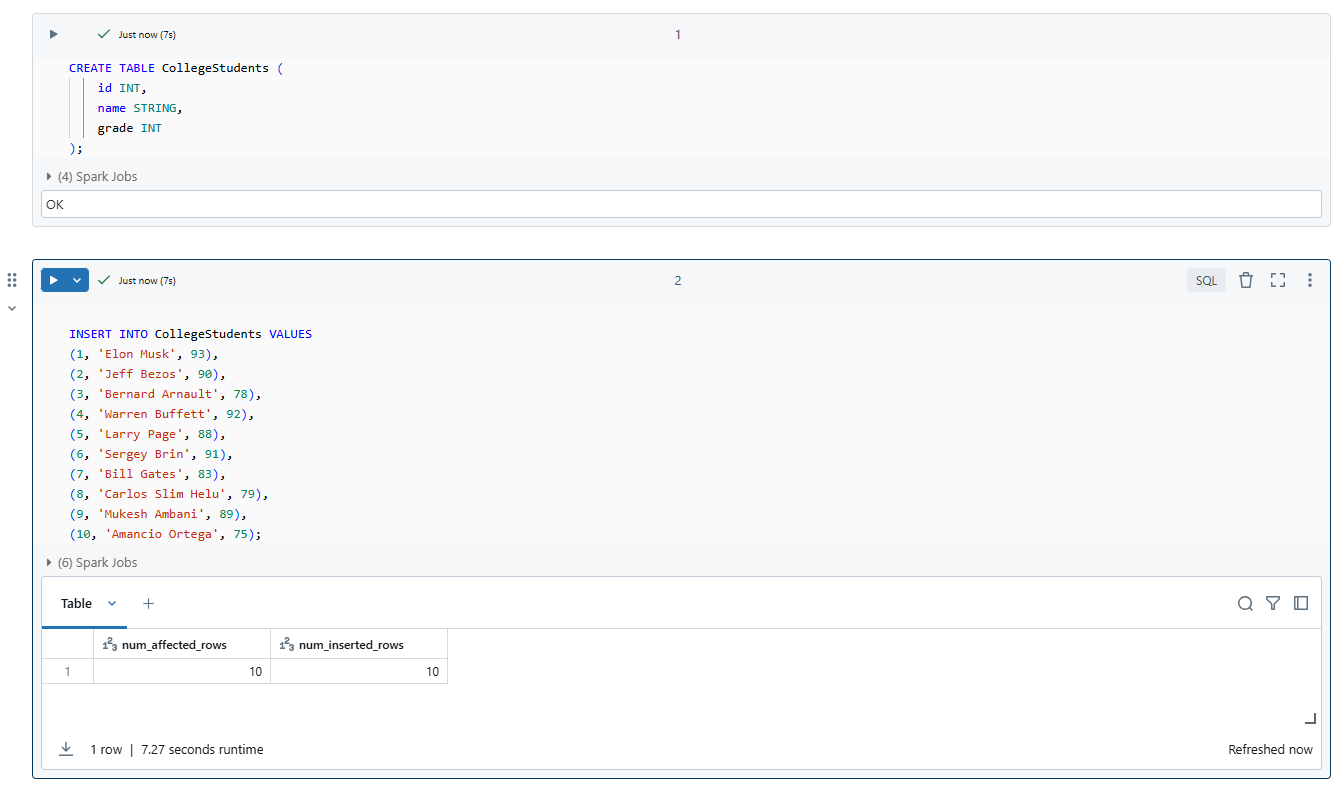
Now that you have inserted the data, you can query the table to verify its contents:
SELECT * FROM CollegeStudents;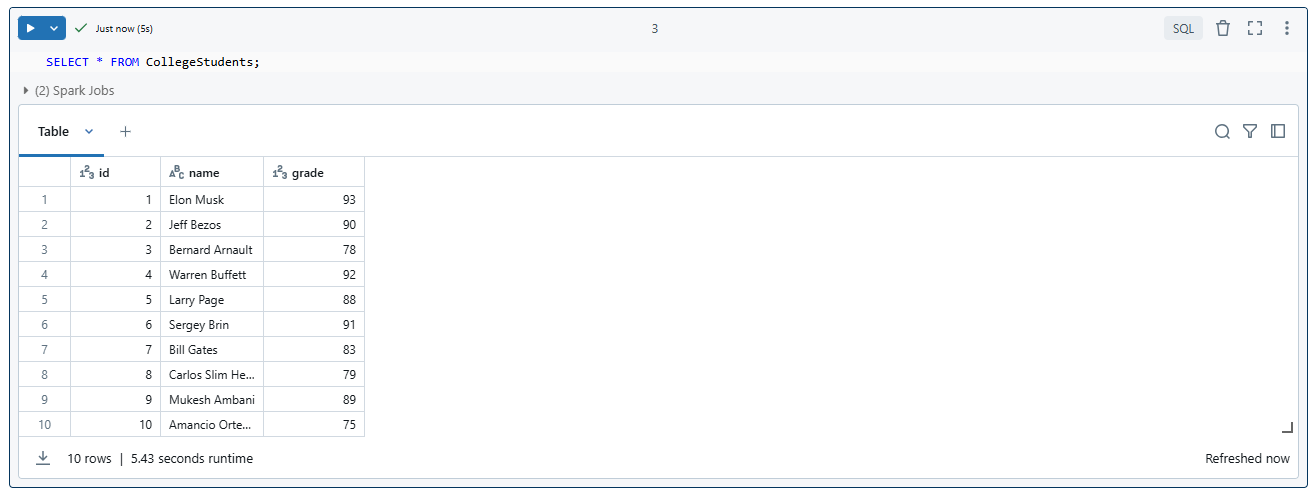
Alternatively, use Python to create a DataFrame:
from pyspark.sql import SparkSession
# Create a SparkSession
spark = SparkSession.builder.appName("CollegeStudents").getOrCreate()
# Create a DataFrame from a list of tuples
data = [
(1, "Elon Musk", 93),
(2, "Jeff Bezos", 90),
(3, "Bernard Arnault", 78),
(4, "Warren Buffett", 92),
(5, "Larry Page", 88),
(6, "Sergey Brin", 91),
(7, "Bill Gates", 83),
(8, "Carlos Slim Helu", 79),
(9, "Mukesh Ambani", 89),
(10, "Amancio Ortega", 75)
]
df = spark.createDataFrame(data, ["id", "name", "grade"])
# Show the DataFrame
df.show()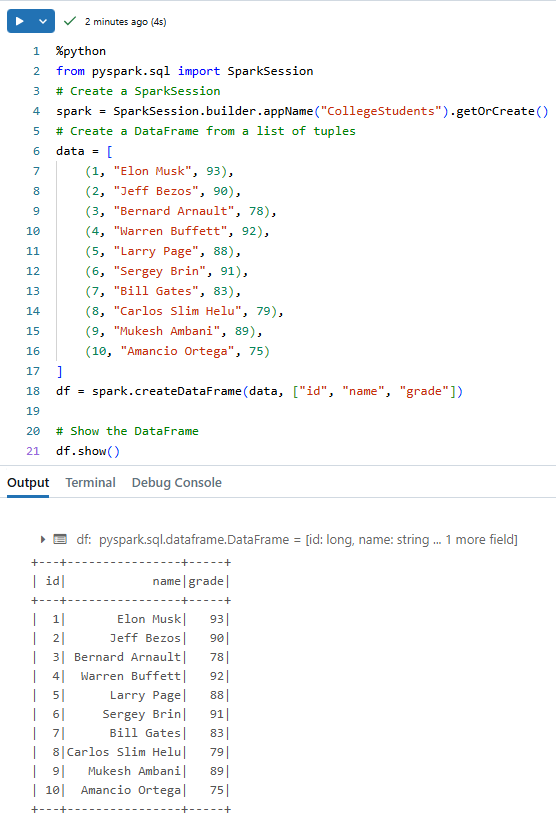
This dummy dataset represents students' IDs, names, and grades—sufficient for creating and working with temporary tables in the next steps.
Now, lets proceed to create the temporary table using SQL and the DataFrame API.
Step 3—Create a Temporary Table Using Databricks SQL Queries
After setting up the CollegeStudents table, you can create a temporary table using SQL. This table will only exist during the active session and is useful for quick transformations or intermediate data processing.
Databricks does not have a direct SQL command to create a temporary table, as you might in traditional SQL databases or Snowflake. But, you can use a temporary view as an alternative. Temporary views in Databricks are session-specific and are created using the CREATE OR REPLACE TEMPORARY VIEW command.
CREATE TEMPORARY VIEW temp_students AS
SELECT * FROM CollegeStudents WHERE grade > 80;
Here you can see that this command creates a temporary table named temp_students that filters only students with grades above 80. Now you can query this temporary view as needed.
Step 4—Create a Temporary Table Using DataFrame API
You can also create a temporary view using the DataFrame API in Python. It is particularly beneficial when you want to process data programmatically before creating the view:
# Filtering data using DataFrame transformations
filtered_df = df.filter(df.grade > 80)
# Create a temporary table
filtered_df.createOrReplaceTempView("temp_students")
Step 5—Verify Databricks Temporary Table
To verify that the Databricks temporary table or so-called temporary view is working, use SQL or the DataFrame API.
By using SQL:
SELECT * FROM temp_college_students;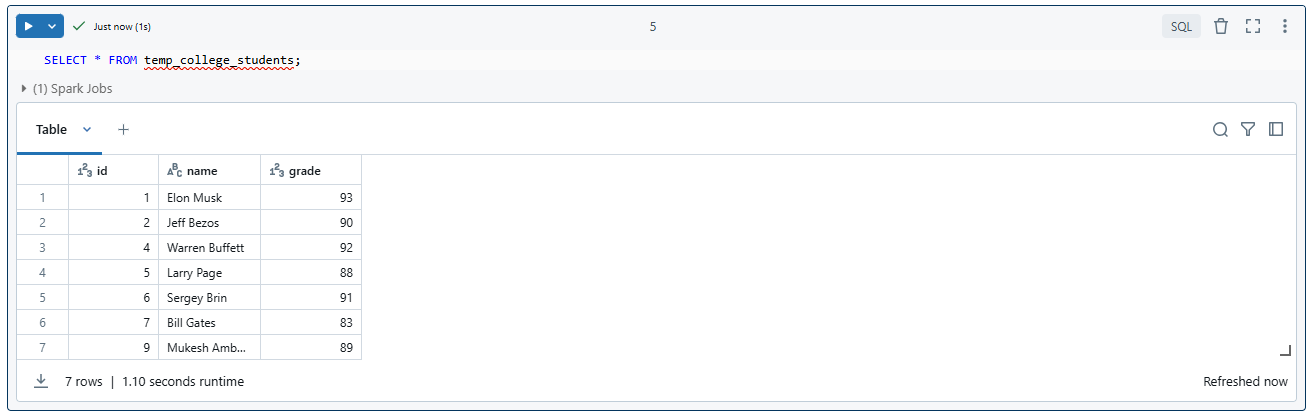
SELECT COUNT(*) AS student_count FROM temp_college_students;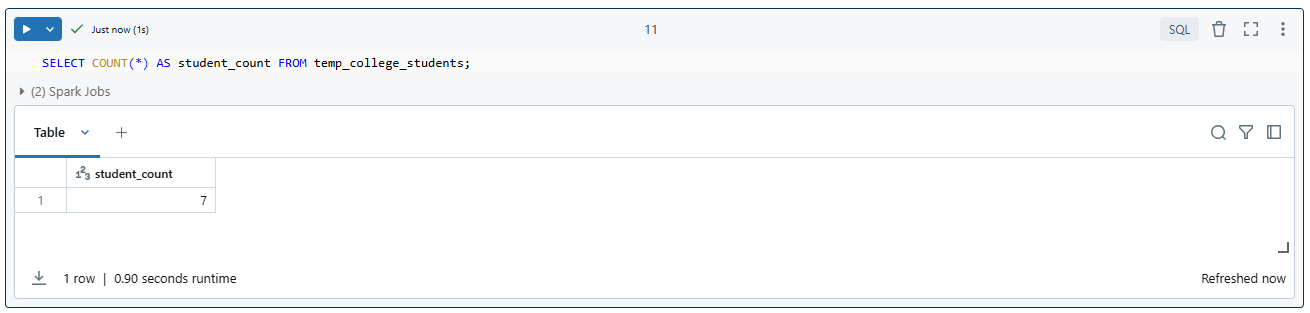
Using Python/Scala:
filtered_df.show()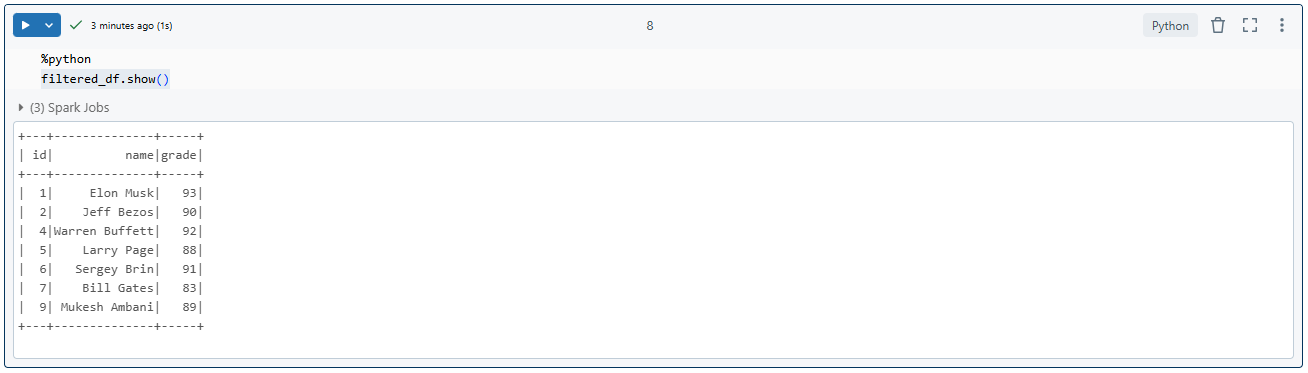
Reconnect or Restart:
- Close the session or restart the cluster.
- Run the query again to confirm that the temporary table no longer exists.
If you attempt to query it after the session ends, you’ll receive an error because temporary tables are session-scoped.
Step 6—Clean Up and Drop the Databricks Temporary Table
Temporary views are removed when the session ends or the cluster is restarted. If you attempt to query a temporary view after the session ends, you will encounter an error.
To explicitly or manually drop a temporary view during an active session, use:
DROP VIEW IF EXISTS temp_college_students;
As you can see the Databricks temporary view is removed immediately, freeing up memory and resources.
Performance Benchmarks for Databricks Temporary Views
- Databricks temporary views are logical constructs, meaning they are lazily evaluated. The query defining the view is not executed, and no data is processed or stored, until an action (like show(), count(), or writing to a sink) is performed on the view or a subsequent query referencing it.
- Temporary views facilitate Spark's Catalyst Optimizer. The optimizer can more efficiently examine the complete Directed Acyclic Graph (DAG) of transformations by breaking down intricate logic into smaller, modular temporary views, which may result in more efficient execution strategies. Overall query performance may be enhanced as a result.
- Explicit caching can greatly improve performance for temporary views that are accessed frequently during a single SparkSession. The computed data is stored in memory (and spills to disk if memory is insufficient) for quicker retrieval when df.cache() is used on a DataFrame prior to creating a temporary view, or CACHE TABLE temp_view_name in SQL. Databricks often recommends Delta caching for compute-heavy workloads, which accelerates data reads by creating copies of remote files in local storage. However, if a temporary view is only used once, caching is generally not recommended as it adds complexity.
- Recomputation is a crucial performance factor. Spark may repeatedly run the underlying query logic if an intermediate result is produced using a temporary view and then queried repeatedly without caching. If this is used often in various parts of a complex job, it may result in lower performance when compared to materializing the intermediate result into a persistent Delta table.
- Be very careful with temporary views performing complex string matching or manipulations over large datasets. In certain situations, replacing such a temporary view with a pre-computed static table might drastically reduce job runtimes by leveraging indexing and avoiding dynamic recomputation.
To sum up, temporary views are quick because they are logical and don't require physical data operations until they are requested. Their true performance impact depends on how they are used within the overall data pipeline, the efficiency of underlying queries, and strategic application of caching when intermediate results are repeatedly accessed.
Cost of Databricks Temporary Views
Databricks charges users based on Databricks Units (DBUs). Temporary views are logical definitions and therefore do not have a direct DBU cost. Nevertheless, the computation resources required to execute the queries that create or reference temporary views result in DBU usage.
Compute Costs
The primary cost driver related to temporary views is the compute time spent by the Databricks cluster to process the data defined by the view.
Even if your cluster is idle, the time it runs incurs compute costs from your cloud provider, as well as Databricks DBU charges.
Larger datasets processed by temporary views or more complex queries will use more DBUs. DBU consumption is directly impacted by variables like data volume, memory usage, and vCPU power.
Using temporary views in an All-Purpose Compute cluster (common for interactive notebooks) generally incurs higher DBU costs per hour compared to Job clusters designed for automated, non-interactive workloads. This implies that using temporary views in interactive development may be more costly than running a production pipeline.
Storage Costs
Temporary views do not directly incur storage costs in cloud object storage because they do not physically store data persistently. They are virtual. Data that is explicitly cached on the cluster nodes using df.cache() or CACHE TABLE will use memory and possibly local disk space. Though it isn't a separate persistent storage bill from your cloud provider, this consumption is a component of the total compute resources and so adds to DBU costs.
Cost Optimization Strategies
To efficiently control costs when utilizing temporary views:
- Make sure the underlying queries defining your temporary views are as efficient as possible.
- Configure clusters with appropriate auto-termination settings to shut down idle clusters, minimizing DBU charges from inactive compute
- Only cache temporary views if the intermediate results are going to be reused multiple times within the same SparkSession to avoid recomputation overhead.
- Move interactive code to optimized Job clusters for production workloads; these clusters usually have lower DBU rates than All-Purpose clusters.
- Though the DBU cost is mostly related to the active compute, temporary views can be explicitly dropped with DROP VIEW IF EXISTS after use to immediately free up logical resources even though they automatically drop.
To put it simply, temporary views are flexible, but their cost is mostly related to the compute resources (DBUs) used to create and query them. Efficient code and careful cluster management are key to cost optimization
TL;DR:
🔮 Databricks does not support direct creation of temporary tables using the CREATE TEMPORARY TABLE command.
🔮 Instead, temporary views are used to mimic the behavior of temporary tables. These views are lightweight, session-scoped constructs designed for handling intermediate or short-lived data.
🔮 Temporary views automatically expire when the session ends—helping to manage resources and avoid unnecessary clutter in the workspace.
🔮 Temporary views are perfect for intermediate calculations or temporary data management, as they do not persist on disk—reducing memory overhead and maintaining a clean workspace.
To create a temporary view in Databricks, you can use the following syntax:
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Conclusion
And that's a wrap! Databricks temporary tables, implemented through temporary views, represent a straightforward solution for session-specific data management. While Databricks doesn't support CREATE TEMPORARY TABLE directly, temporary views act as an effective alternative—allowing you to manage transient data without the need for permanent storage. These views exist only during the active session and are perfect for scenarios where data is needed temporarily for querying and processing.
In this article, we have covered the following topics:
- What are temporary tables in Databricks?
- What is a temporary view in Databricks?
- What is the difference between a view and a temporary view?
- How to create a temporary table in Databricks?
...and so much more!
FAQs
What are temporary tables in Databricks?
Temporary tables are session-specific, in-memory data structures that exist only for the duration of a user session.
What is a temporary view in Databricks?
A temporary view is a session-scoped, named representation of a query's result. It is created using a DataFrame or Databricks SQL queries. Although they function similarly to temporary tables, they are technically not tables but views of underlying datasets.
How long do temporary tables last in Databricks?
Temporary tables (implemented as temporary views) last only for the duration of the user session. They are automatically dropped when the session ends.
What are some use cases for Databricks temporary tables?
Temporary tables are useful for intermediate data transformations, data exploration, testing, and sharing data within a session.
What is the syntax to create a Databricks temporary table?
Databricks uses the CREATE OR REPLACE TEMP VIEW statement to create temporary views.
How to create a temporary view in Spark?
You can create temporary views in Spark using the createOrReplaceTempView() method on a DataFrame.
What is the advantage of using a temporary table instead of a table?
Temporary tables are useful for short-lived data manipulations and exploration without affecting permanent tables.
Which is faster view or temp table?
Temporary views are typically faster than regular views because they often cache data in memory.
Can you query a temp table?
Yes, you can query temporary tables (implemented as temporary views) just like regular tables using SQL.
Can a Databricks temporary table have the same name as a regular/permanent table?
Yes, temporary tables can share names with permanent tables since they are session-scoped. Within the same session, the temporary table will take precedence over the permanent one when queried.
Are Databricks temporary tables visible across different sessions?
No, temporary tables are session-scoped and cannot be accessed outside the session in which they were created.
What happens if you drop a permanent table that a temporary table is based on?
If the source table of a temporary view is dropped, the temporary view becomes invalid. Subsequent queries using the view will fail until the source table is recreated.
How do I drop a Databricks temporary view?
You can drop a Databricks temporary view using:
DROP VIEW IF EXISTS temp_table;Can I Create Multiple Temporary Views in the Same Session?
Yes, you can create multiple temporary views within a single Spark session. Each view can be based on different source data or transformations.
How Do Temporary Views Handle Complex Data Types?
Databricks Temporary views fully support complex data types, including:
- Nested structures
- Arrays
- Maps
- Structs
How Do Temporary Views Interact with Different Databricks Clusters?
Databricks temporary views are strictly session and cluster-specific. They do not persist across:
- Different cluster sessions
- Notebook restarts
- Cluster terminations
What are the performance implications of using temporary views?
Temporary views can improve performance by caching data in memory, but excessive use can lead to memory constraints.
Can I use temporary views with Delta Lake tables?
Yes, you can create temporary views based on Delta Lake tables.
What are some best practices for using temporary views?
Use temporary views for session-specific data manipulation and avoid storing sensitive data in temporary views.















