












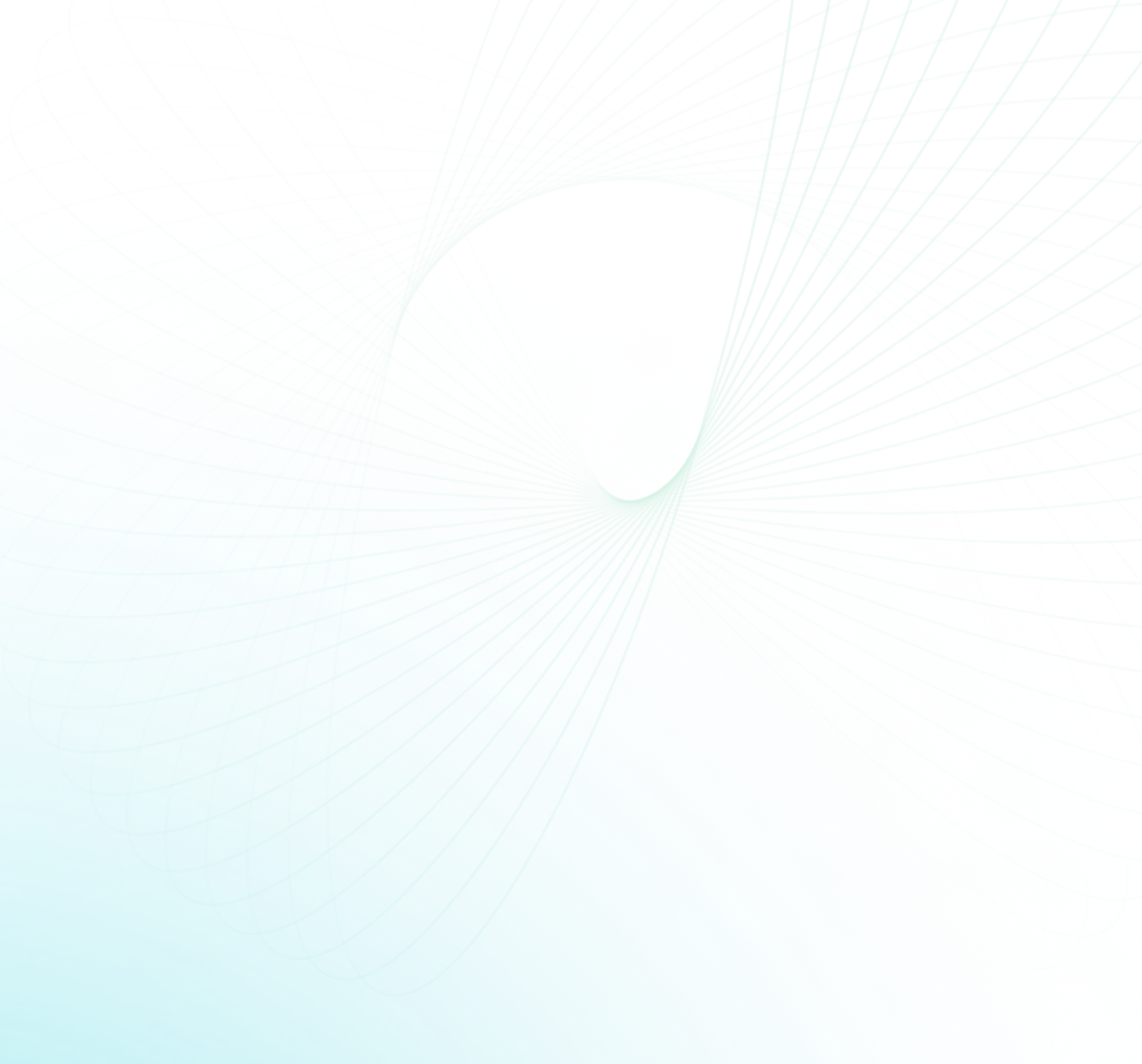
















Data ingestion is a critical step in any data analytics pipeline, and Databricks provides several methods to streamline this process. These include COPY INTO, manual file uploads, and Databricks Autoloader. While each of ‘em has its own advantages, Databricks Autoloader stands out as a cost-effective way to incrementally ingest data from cloud storage services. Autoloader is a powerful feature of Databricks that simplifies the process of ingesting and processing data from cloud storage services. It automatically detects new or updated files in the specified cloud storage location and triggers a Spark job to load and process that data.
In this article, we'll dive deep into Databricks Autoloader, exploring its key features, functionality, and a step-by-step guide to using it to ingest data into Delta Lake tables. We'll also compare Autoloader with other data ingestion methods and discuss its advantages and use cases.
What is Autoloader in Databricks?
Databricks Autoloader is a feature that automatically ingests and loads raw data files into Delta Lake tables as they arrive in cloud storage locations without any additional configuration. It provides a Structured Streaming source called "cloudFiles" that can monitor input directories on cloud file storage for new files in various file formats. The cloudFiles source will automatically load any new files into a Delta Lake table as they are detected. Databricks Autoloader supports both batch and streaming ingestion of files in Python and SQL. It can scale to process billions of files for large data migration or backfilling a table, as well as support near real-time loading of millions of files per hour. Autoloader handles all the tracking and processing of new files in an efficient, incremental manner without needing additional scheduling or manual intervention.
Another crucial aspect of Databricks Autoloader is its ability to provide exact-once processing semantics for ingested files. As new files are discovered in the monitored cloud storage location, their metadata is durably persisted in a cloud-based checkpoint location using a scalable key-value store (Apache RocksDB). This checkpoint information allows Autoloader to track the processing state of each individual file, ensuring that no file is ingested more than once, even in the event of failures, restarts, or infrastructure outages. In case of failures or interruptions during the ingestion process, Autoloader can reliably resume the pipeline from the last successfully committed checkpoint, avoiding duplicate processing and providing exactly-once guarantees when writing data into the target Delta Lake table. This fault tolerance and exactly-once processing semantics are achieved natively by Autoloader, without requiring any manual state management or custom code, simplifying the development and maintenance of reliable and idempotent data ingestion pipelines.
Databricks Autoloader supports ingesting data from the following cloud storage solutions:
- AWS S3(s3://): Amazon's object storage service, designed for scalability, data durability, and high availability.
- Azure Blob Storage(wasbs://): Microsoft's object storage solution for storing and accessing unstructured data at massive scales.
- Azure Data Lake Storage (ADLS) Gen2(abfss://): A Hadoop-compatible file system and analytics service built on top of Azure Blob Storage, optimized for big data analytics workloads.
- Google Cloud Storage (GCS)(gs://): Google's highly scalable and durable object storage service for storing and accessing data across Google Cloud and global applications.
- Azure Data Lake Storage (ADLS) Gen1(adl://): Azure Data Lake Storage Gen1, the previous generation of storage optimized for analytics on big data.
- Databricks File System (DBFS)(dbfs:/): A cloud-storage-agnostic file system used as the default file system in Databricks Workspace to reference files across cloud storage.
Note: Databricks Autoloader supports ingesting data from ADLS Gen1, Microsoft recommends migrating to ADLS Gen2 for better performance, scalability, and security features.
Here are some of the notable key capabilities of Databricks Autoloader:
1) Incremental and Efficient Data Ingestion
Databricks Autoloader can incrementally and efficiently process new data files as they arrive in cloud storage without any additional setup. It can load data files from S3, ADLS (Gen1 + Gen2), GCS, Azure Blob Storage, and DBFS.
2) Support for Multiple File Formats
Databricks Autoloader can ingest a wide range of file formats, including JSON (JavaScript Object Notation), CSV (Comma separated values), Parquet, ORC (Optimized row columnar format), Apache AVRO, Text files, BinaryFile.
3) Highly Scalable
Databricks Autoloader can process billions of files to migrate or backfill a table, supporting near real-time ingestion of millions of files per hour.
4) Exactly-Once Processing
Databricks Autoloader tracks ingestion progress by persisting file metadata in a cloud-based checkpoint location using a scalable key-value store (Apache RocksDB). This ensures that each file is processed exactly once, providing fault tolerance and allowing the ingestion pipeline to resume from the last successful checkpoint in case of failures or interruptions.
5) Schema Inference and Evolution
Autoloader can automatically infer the schema of the ingested data, enabling table initialization without manually defining the schema upfront. It can also handle schema evolution by detecting changes in the data schema and automatically updating the target Delta Lake table schema to accommodate new columns or data types.
6) Handling Faulty or Malformed Data
Databricks Autoloader can handle faulty or malformed data by capturing it in a designated _rescued_data column within the target Delta Lake table, ensuring that no data is lost or ignored during the ingestion process.
7) Integration with Delta Live Tables
Autoloader supports both Python and SQL in Delta Live Tables, enabling autoscaling of compute resources, data quality checks, automatic schema evolution handling, and monitoring via metrics in the event log.
8) Cost-Effective File Discovery
Databricks Autoloader's file discovery cost scales with the number of files being ingested rather than the number of directories, reducing cloud storage costs for large-scale ingestion pipelines.
9) File Notification Mode
Databricks Autoloader supports a file notification mode, where it automatically configures and subscribes to notification and queue services for file events from the input directory, enabling efficient ingestion of high volumes of files as they arrive.
10) Backfill Support
Databricks Autoloader supports backfilling operations, ensuring that all files are processed, even if they were missed during the initial ingestion run.
What file types are available in Databricks Autoloader?
Databricks Autoloader supports a wide range of file formats, they are:
- JSON (JavaScript Object Notation)
- CSV (Comma separated values)
- Parquet
- ORC (Optimized row columnar format)
- Apache AVRO
- Text files
- BinaryFile
How does Databricks Autoloader work?
As we have already covered above, Databricks Autoloader is designed to continuously monitor a specified cloud storage location (e.g., AWS S3, Azure Blob Storage, Azure Data Lake Storage (ADLS) Gen2, Google Cloud Storage (GCS), Azure Data Lake Storage (ADLS) Gen1, Databricks File System (DBFS)) for new or updated files. Whenever new raw data is detected, Autoloader triggers a Spark job to read the data from the cloud object storage and write it to a Delta Lake table.
The core process of Databricks Autoloader reading from cloud object storage and writing to Delta Lake tables involves the use of the cloudFiles method, which is part of the Spark DataFrameReader API. This method is designed to read data directly from cloud storage services.
Databricks Autoloader provides two modes for identifying new files in the cloud storage location: Directory Listing Mode and File Notification Mode.
1) Directory Listing mode:
Directory Listing Mode is the default mode used by Databricks Autoloader. In this mode, Autoloader identifies new files by periodically listing the contents of the input directory on the cloud storage. This mode allows you to quickly start Autoloader streams without any additional permission configurations, as long as you have access to the data on cloud storage.
- How it works: Autoloader optimizes the process of listing directories by leveraging cloud storage APIs to retrieve a flattened response, reducing the number of API calls required and, consequently, the associated cloud costs.
- Incremental Listing (deprecated): For lexicographically ordered files (e.g., date-partitioned or versioned files), Autoloader can leverage incremental listing, which involves listing only the recently ingested files rather than the entire directory. This optimization is available for ADLS Gen2, S3, and GCS.
- Lexical Ordering of Files: To take advantage of incremental listing, files need to be uploaded in a lexicographically increasing order, such as versioned files (e.g., Delta Lake transaction logs), date-partitioned files, or files generated by services like AWS DMS.
- Backfill Mechanism: To ensure eventual completeness of data, Autoloader automatically triggers a full directory listing after completing a configured number of consecutive incremental listings (default is 7).
- Performance: Directory Listing mode is suitable for small to medium-sized directories or when the volume of incoming files is moderate. For large directories or high volumes of files, File Notification mode is recommended.
2) File Notification Mode:
File Notification Mode is an alternative mode that Autoloader can use to automatically set up a notification service and queue service that subscribes to file events from the input directory. This mode is more performant and scalable for large input directories or a high volume of files but requires additional cloud permissions.
- How it works: Autoloader automatically sets up a notification service (e.g., AWS SNS, Azure Event Grid, Google Pub/Sub) and a queue service (e.g., AWS SQS, Azure Queue Storage, Google Pub/Sub) that subscribe to file events from the input directory.
- Cloud Resources: Autoloader creates and manages the required cloud resources (notification service, queue service) on your behalf, provided you have the necessary permissions.
- Scalability: File Notification mode can scale to ingest millions of files per hour, making it suitable for high-volume data ingestion scenarios.
- Permissions: To use File Notification mode, you need to grant Databricks Autoloader elevated permissions to automatically configure the required cloud infrastructure (notification service, queue service).
- Limitations: Changing the input directory path is not supported in File Notification mode. If the path is changed, Autoloader may fail to ingest files already present in the new directory.
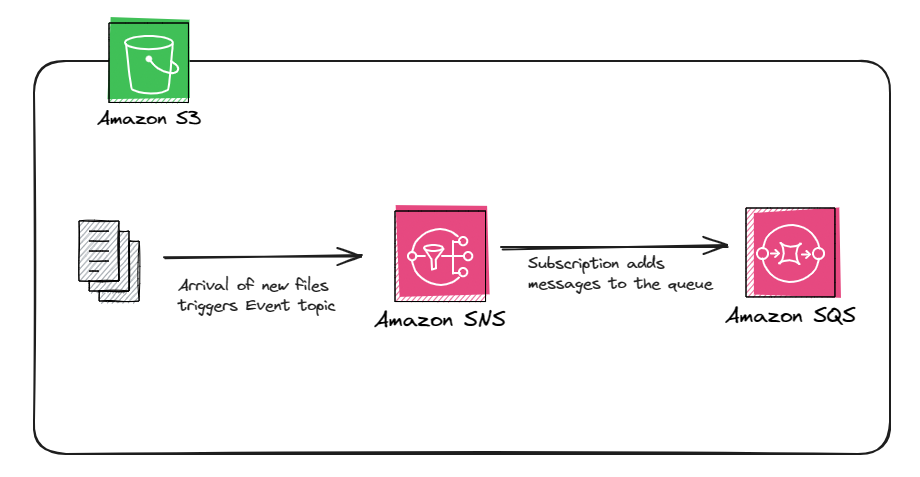
Both of ‘em provide exactly-once data processing guarantees, and you can switch between ‘em at any time while maintaining the ingestion state. The choice between the two modes depends on specific requirements, such as the volume of incoming data, the size of the input directory, and the desired performance and scalability.
CloudFiles Parameters:
Here is a list of cloudFiles parameters that you can configure for working with Databricks Autoloader.
Common Databricks Autoloader options (valid for both Directory listing and File notification):
The following are some commonly used cloudFiles parameters that you can configure for both Directory Listing or File Notification mode:
- cloudFiles.allowOverwrites—This Boolean parameter determines whether to allow modifications to input directory files to overwrite existing data. It is available in Databricks Runtime 7.6 and above. The default value is false.
- cloudFiles.backfillInterval—This parameter accepts an interval string (e.g., "1 day" or "1 week") and allows you to configure Autoloader to trigger asynchronous backfills at the specified interval. This option ensures that all files eventually get processed, as file event notification systems do not guarantee 100% delivery of all uploaded files. It is available in Databricks Runtime 8.4 and above.
- cloudFiles.format—This required parameter specifies the data file format in the source path. Allowed values include "avro", "binaryFile", "csv", "json", "orc", "parquet", and "text".
- cloudFiles.includeExistingFiles—This Boolean parameter determines whether to include existing files in the stream processing input path or to only process new files arriving after initial setup. The default value is true.
- cloudFiles.inferColumnTypes—This Boolean parameter specifies whether to infer exact column types when leveraging schema inference. By default, columns are inferred as strings when inferring JSON and CSV datasets.
- cloudFiles.maxBytesPerTrigger—This parameter specifies the maximum number of new bytes to be processed in every trigger. You can specify a byte string (e.g., "10g") to limit each microbatch to a specific data size.
- cloudFiles.maxFilesPerTrigger—This parameter specifies the maximum number of new files to be processed in every trigger. When used together with cloudFiles.maxBytesPerTrigger, Autoloader consumes up to the lower limit of either parameter.
- cloudFiles.partitionColumns—This parameter accepts a comma-separated list of Hive-style partition columns that you would like inferred from the directory structure of the files.
- cloudFiles.schemaEvolutionMode—This parameter specifies the mode for evolving the schema as new columns are discovered in the data.
- cloudFiles.schemaHints—This parameter allows you to provide schema information to Autoloader during schema inference.
- cloudFiles.schemaLocation—This required parameter (when inferring the schema) specifies the location to store the inferred schema and subsequent changes.
Directory listing options
- cloudFiles.useIncrementalListing: This deprecated parameter specifies whether to use incremental listing rather than full listing in Directory Listing mode. Databricks recommends using File Notification mode instead.
File notification options
- cloudFiles.fetchParallelism—This parameter specifies the number of threads to use when fetching messages from the queuing service in File Notification mode.
- cloudFiles.pathRewrites—This parameter is required if you specify a queueUrl that receives file notifications from multiple S3 buckets, and you want to leverage mount points configured for accessing data in these containers. It allows you to rewrite the prefix of the bucket/key path with the mount point.
- cloudFiles.resourceTag—This parameter allows you to specify a series of key-value tag pairs to help associate and identify related resources across different cloud providers.
- cloudFiles.useNotifications—This Boolean parameter specifies whether to use File Notification mode (true) or Directory Listing mode (false) to determine when there are new files.
Advanced Databricks Autoloader Features:
1) Schema inference:
Databricks Autoloader can automatically infer the schema of the data being ingested, even if the schema changes over time. This is particularly useful when dealing with semi-structured or evolving data formats like JSON or CSV. To enable schema inference, you need to specify the cloudFiles.schemaLocation option, which determines the location to store the inferred schema and subsequent changes.
2) Schema evolution:
In addition to schema inference, Databricks Autoloader supports schema evolution, which means it can handle changes in the schema of the ingested data over time. This is achieved by using the cloudFiles.schemaEvolutionMode option, which specifies the mode for evolving the schema as new columns are discovered in the data.
The default schema evolution mode is "addNewColumns" when a schema is not provided. This mode allows Autoloader to add new columns to the existing schema as they are discovered in the data. If a schema is provided, the default mode is "none", which means that Autoloader will not automatically evolve the schema, and any new columns in the data will be ignored.
You can also provide cloudFiles.schemaHints to guide Autoloader during schema inference, allowing you to specify additional schema information or override the inferred types.
Step-By-Step Guide to Using Autoloader to Ingest Data to Delta Lake
Prerequisites and Setup
- Active Databricks account: You'll need an active Databricks account to follow along with this guide. If you don't have one, you can sign up for a free trial or community edition.
- Working knowledge of Python: While Databricks Autoloader can be used with various programming languages supported by Databricks, this guide will primarily focus on Python.
Step 1—Create a Cluster
Before you can start using Databricks Autoloader, you'll need to create a Databricks cluster. A cluster is a set of computing resources (virtual machines) that will execute your Spark jobs. To create a Databricks cluster, first, you need to log in to your Databricks workspace. Navigate to the "Compute" section and click on "Create Compute".
Choose the appropriate cluster configuration based on your needs (e.g., cluster mode, worker type, and number of workers). Once the cluster is running, you're ready to move to the next step.
If you want to learn more in-depth insights about cluster configuration in Databricks, refer to this article.
Step 2—Create a Notebook
Databricks Notebooks are web-based environments where you can write and execute code. In your Databricks workspace, click on the "+ New" button located on the left sidebar navigation bar, then select "Notebook" from the menu.
Give your notebook a name and select the appropriate language (e.g., Python). Attach your newly created cluster to the notebook by selecting it from the "Cluster" dropdown menu.
Step 3—Scheduled Streaming Loads using Databricks Autoloader
Databricks Autoloader can be used to perform scheduled streaming loads from cloud storage locations. This is useful when you have a continuous stream of data being generated, and you want to ingest it into Delta Lake tables in near real-time. Here's how to configure Databricks Autoloader for streaming ingestion:
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "csv")
.load("<input-path>")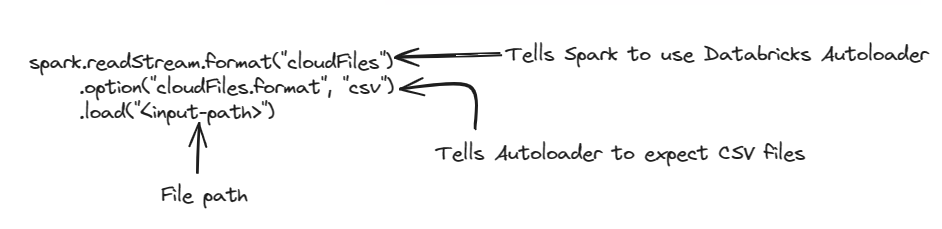
In this code, we first initiate a streaming DataFrame reader using spark.readStream, which allows us to read data from streaming sources in a structured way using Spark. We then tell Spark to use the Autoloader by specifying "cloudFiles". This indicates that our streaming data will come from Cloud object storage. To configure the file format, we use the option method and set "cloudFiles.format" to "csv". This informs Spark that the files stored in Cloud Files are in CSV format. Finally, we define the path location in Cloud Files from where the files need to be read using the load method. The path provided is "<input-path>". Specifying this path tells Spark streaming to continuously monitor this location for any new or updated files. As new CSV files are added or existing ones are modified at "<input-path>", Spark will automatically read them.
Step 4—Scheduled Batch Loads using Databricks Autoloader
In addition to streaming ingestion, Databricks Autoloader can also be used for scheduled batch loads. This is useful when you have data that arrives in batches (e.g., only once every few hours) and you want to ingest it into Delta Lake tables on a recurring schedule. Here's an example of how to configure Databricks Autoloader for scheduled batch ingestion:
val df = spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/input/path")
df.writeStream.trigger(Trigger.Once)
.format("delta")
.start("/output/path")This code example sets up a structured streaming workflow in Spark that reads streaming data from CloudFiles as the source and writes the results to Delta Lake as the sink. We then tell Spark to use the Autoloader by specifying "cloudFiles". This indicates that our streaming data will come from Cloud object storage. To configure the file format, we use the option method and set "cloudFiles.format" to "json". This informs Spark that the files stored in Cloud Files are in CSV format. Finally, we define the path location in Cloud Files from where the files need to be read using the load method. This returns a streaming DataFrame (df) representing the data stream from CloudFiles that will be continuously updated as new files are added or modified. The streaming DataFrame is then written out as the streaming sink. A trigger of Trigger.Once() is defined to process the data from the source only once instead of continuously. The output format is specified as "delta" to write the results to Delta Lake storage, which provides ACID transactions and reliable queries. The output path is set as "/output/path" using the start method. This will load the streaming data from CloudFiles, apply any transformations, and write the processed data once to Delta Lake located at "/output/path".
Step 5—Configure Databricks Autoloader to Ingest CSV & JSON to a Delta Table
In this step, we'll use Databricks Autoloader to ingest CSV and JSON data from dbfs into a Delta Lake table, it is the same for any cloud storage location.
For JSON:
First, let's import the necessary functions from the pyspark.sql.functions module:
%python
from pyspark.sql.functions import col, current_timestampHere, we import the col function, which is used to reference columns in a DataFrame, and the current_timestamp function, which returns the current timestamp.
Next, we define some variables that will be used in the code:
input_data_path = "<input-path>"
current_user = spark.sql("SELECT regexp_replace(current_user(), '[^a-zA-Z0-9]', '_')").first()[0]
processed_table_name = f"{current_user}_databricks_autoloader_demo"
checkpoint_dir_path = f"/tmp/{current_user}/_checkpoint/databricks_autoloader_demo"
- input_data_path is the path to the JSON data files that we want to ingest.
- username is the current user's name, with non-alphanumeric characters replaced with underscores. We get this by running a SQL query with the regexp_replace function.
- processed_table_name is a string that combines the username and "databricks_autoloader_demo" to create a unique table name.
- checkpoint_dir_path is the path where we'll store the checkpoint for the structured streaming job.
Now, we're ready to configure the Databricks Autoloader to ingest the JSON data and write it to a Delta table:
(spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.schemaLocation", checkpoint_dir_path)
.load(input_data_path)
.select("*", col("_metadata.file_path").alias("source_file"), current_timestamp().alias("processing_time"))
.writeStream
.option("checkpointLocation", checkpoint_dir_path)
.trigger(availableNow=True)
.toTable(processed_table_name))
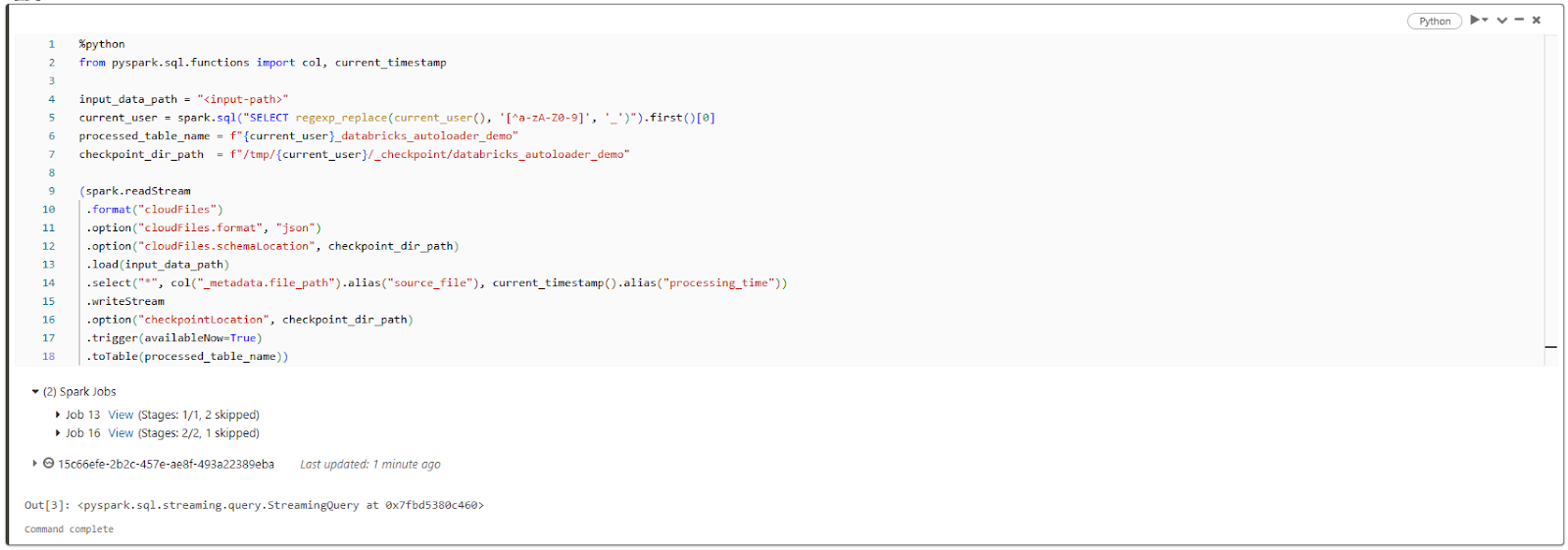
Let's break this down:
- .format("cloudFiles") tells spark to use Databricks Autoloader.
- .option("cloudFiles.format", "json") tells Spark that the input files are in JSON format.
- .option("cloudFiles.schemaLocation", checkpoint_dir_path) sets the location where Spark will store the schema of the input data.
- .load(input_data_path) loads the data from the specified file_path.
- .select(...) selects all columns from the input data, adds a new column source_file containing the file path, and another column processing_time with the current timestamp.
- .writeStream configures the output as a streaming write.
- .option("checkpointLocation", checkpoint_dir_path) sets the location for the checkpoint directory.
- .trigger(availableNow=True) tells Spark to start the streaming query immediately with the available data.
- .toTable(processed_table_name) writes the streaming data to a Delta table with the specified table_name.
For CSV:
The process to configure Autoloader to ingest CSV data to a Delta table is very similar to the process we saw earlier for ingesting JSON. The only change you need to make is in the cloudFiles.format option.
(spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "csv") # Change this line to specify CSV format
.option("cloudFiles.schemaLocation", checkpoint_dir_path)
.load(input_data_path)
.select("*", col("_metadata.file_path").alias("source_file"), current_timestamp().alias("processing_time"))
.writeStream
.option("checkpointLocation", checkpoint_dir_path)
.trigger(availableNow=True)
.toTable(processed_table_name))Instead of setting "cloudFiles.format" to "json", you need to set it to "csv". This tells Spark that the input files are in CSV format instead of JSON. The rest of the process remains the same.
Step 6—View and Interact With Your Newly Ingested Data
After setting up the Autoloader to ingest data into a Delta table, you can process and interact with the ingested data using Databricks notebooks. Notebooks execute code cell-by-cell, allowing you to run specific parts of your code and see the results immediately.
Execute the Ingestion Code
To run the ingestion code that you completed in the previous step, follow these instructions:
- Select the cell containing the ingestion code.
- Press SHIFT+ENTER.
This will execute the code in the selected cell, and the ingested data will be written to the specified Delta table.
Query the Ingested Data
After the ingestion is complete, you can query the newly created table to access the ingested data. Here's how:
First, copy and paste the following code into an empty cell:
%python
df = spark.read.table(processed_table_name)Second, press SHIFT+ENTER to run the cell.

This creates a Spark DataFrame df by reading data from the Delta table with the specified processed_table_name. The DataFrame df now contains the ingested data, and you can perform various operations on it.
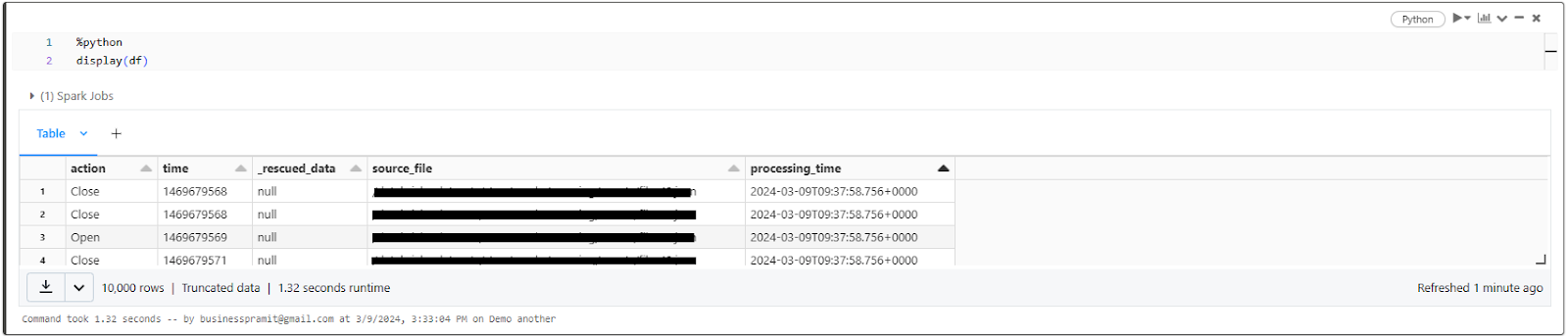
As you can see in the above screenshot, Databricks Autoloader automatically generates a column called _rescued_data to handle malformed data during the load process. The primary purpose of the _rescued_data column is to rescue data that does not conform to the inferred or provided target table schema during the load process. It ensures that non-matching values are captured instead of being dropped or causing failures.
Specifically, the rescued data column will contain cell values from the source data that:
- Are in columns not defined in the target schema
- Do not match the data type specified in the target schema
- Do not match the case of column names defined in the target schema
Preview the Data
To preview the ingested data in the DataFrame df, follow these steps:
Paste the following code into an empty cell and then run it:
%python
display(df)
The display function will render the contents of the DataFrame df in the notebook output, allowing you to visually inspect the ingested data.
Step 7—Schedule the Notebook as a Job to Run Automatically
After you've processed and interacted with the ingested data in your Databricks notebook, you might want to run the notebook as a production script or a scheduled job. Databricks allows you to schedule notebooks as tasks within a job. In this step, we'll create a new job that you can trigger manually. To do so, first open the Job Scheduler by clicking the “Schedule” button at the top right of the notebook interface. Then, name the new job, select the "Manual" job type since you want to trigger it manually for now, choose the cluster you created earlier, and click "Create" to build the job. With the job set up, you can run it immediately by clicking the "Run now" button that appears—this will kick off your notebook code on the cluster. And to monitor progress and results, simply click the timestamp next to "Last run" to view logs and output from that initial manual job run.
What Are the Key Main Advantage of Using Databricks Autoloader?
Databricks Autoloader offers several compelling advantages that streamline and simplify the data ingestion process from cloud storage services, making it a powerful and efficient tool for modern data analytics pipelines. The key advantages of using Autoloader are:
1) Automated File State Management and Exactly-Once Processing
Databricks Autoloader eliminates the need for manual file state management by automatically tracking the ingestion progress and maintaining checkpoint information. This ensures that only new or updated files are processed during subsequent runs, preventing duplication and data inconsistencies. Autoloader provides exact-once processing guarantees, ensuring that data is ingested reliably and without any loss or duplication.
2) Efficient File Discovery and Scalability
Databricks Autoloader leverages two modes for identifying new files: Directory Listing mode and File Notification mode. Directory Listing mode optimizes the process of listing directories by utilizing cloud storage APIs to retrieve a flattened response, reducing the number of API calls and associated costs. File Notification mode, on the other hand, utilizes cloud-native event notification services to receive real-time updates when new files are added to the input directory. This mode is highly scalable and can ingest millions of files per hour, making it suitable for high-volume data ingestion scenarios.
3) Automatic Setup and Configuration
Databricks Autoloader abstracts away the complexities of configuring and managing cloud infrastructure components required for incremental data processing. It can automatically set up and manage notification services (e.g., AWS SNS, Azure Event Grid, Google Pub/Sub) and queueing services (e.g., AWS SQS, Azure Queue Storage, Google Pub/Sub), allowing you to focus on the data ingestion logic rather than the underlying infrastructure.
4) Schema Inference and Evolution
Databricks Autoloader can automatically infer the schema of the ingested data, even if the schema changes over time. This feature, known as schema evolution, ensures that no data is lost or corrupted due to schema changes, making Autoloader well-suited for handling semi-structured or evolving data formats like JSON or Parquet. You can specify options like cloudFiles.schemaLocation and cloudFiles.schemaEvolutionMode to control the schema inference and evolution process.
5) Incremental Processing and Fault Tolerance
Autoloader supports incremental processing, which means it can efficiently process only the new or updated data since the last run, avoiding redundant processing of existing data. This is achieved through efficient file discovery mechanisms and checkpoint management. Also, Autoloader is designed to be fault-tolerant and idempotent, ensuring that data processing can recover from failures and handle duplicates correctly.
7) Cost-Effective
Databricks Autoloader helps reduce the overall costs associated with data ingestion by leveraging cloud object storage and only processing new or updated data. You only pay for the compute resources used during the actual ingestion process, rather than maintaining a continuously running cluster or processing redundant data. Also, Autoloader's optimizations, such as efficient file discovery and incremental processing, can further reduce cloud storage costs.
What Is the Difference Between Databricks Autoloader and Delta Live Tables?
Databricks Autoloader and Delta Live Tables (DLT) are two distinct but complementary features in Databricks. They share some common capabilities, but they are designed to address different aspects of the data engineering and analytics workflow. Here's a comparison between the two:
|
Databricks Autoloader |
|
|
Databricks Autoloader is designed for streaming data ingestion and processing from cloud storage locations. |
Databricks DLT is designed for building and managing data pipelines that can handle both batch and streaming workloads. |
|
Databricks Autoloader supports structured data formats like JSON, CSV, Parquet, and others. |
DLT can ingest data from various sources, including cloud storage, databases, streaming sources, and more. |
|
Databricks Autoloader is primarily used for ingesting data directly from cloud storage (e.g., Azure Data Lake, Amazon S3, Google Cloud Storage). |
DLT can ingest data from various sources, including cloud storage, databases, and streaming sources. |
|
Databricks Autoloader provides automatic file discovery, ingestion, and processing. |
DLT provides a declarative syntax for defining and executing complex data transformations on both batch and streaming data. |
|
Databricks Autoloader supports automatic schema inference and schema evolution, allowing it to handle semi-structured or evolving data formats. |
Like Databricks Autoloader, DLT supports schema inference, schema evolution, and schema enforcement. |
|
Databricks Autoloader is optimized for high-throughput ingestion and processing, ensuring efficient and scalable data ingestion. |
DLT is optimized for complex data transformations and pipelines, allowing you to define and execute intricate data processing workflows. |
What Is the Main Difference Between Databricks Autoloader and COPY INTO?
Databricks Autoloader and COPY INTO are two different features in the Databricks Lakehouse Platform, designed for different purposes and use cases related to data ingestion and loading. Here's a comparison between the two:
|
Databricks Autoloader |
Databricks COPY INTO |
|
Databricks Autoloader is designed for low-latency, continuous data ingestion scenarios, where data is constantly arriving in small batches or streams. |
COPY INTO is designed for bulk loading large datasets in a batch mode, typically during initial data ingestion or periodic data refreshes. |
|
Databricks Autoloader creates a streaming DataFrame or stream of data, which can be further processed using Structured Streaming operations. |
COPY INTO loads data directly into a Delta table or Parquet directory, creating a static DataFrame or dataset. |
|
Databricks Autoloader monitors the specified source directory and triggers ingestion processes whenever new or updated files are detected, ensuring only new data is ingested. |
COPY INTO performs a one-time load of data from the specified source, without continuous monitoring or incremental loading capabilities. |
|
Databricks Autoloader supports automatic schema inference and schema evolution, allowing it to handle semi-structured or evolving data formats. |
Like Autoloader, COPY INTO provides options for schema inference, schema evolution, and handling of corrupted records. |
|
Databricks Autoloader leverages two modes for identifying new files: Directory Listing mode and File Notification mode, optimized for efficient file discovery and scalability. |
COPY INTO processes files in a non-deterministic order, unlike Autoloader's ability to process files in a specific order. |
Conclusion
And that’s a wrap! Databricks Autoloader is a powerful feature that streamlines data ingestion and processing into Delta Lake tables from cloud storage services like AWS S3, Azure Blob Storage, or Google Cloud Storage. It automatically discovers and ingests new data files, infers the schema without requiring manual coding. Plus it only processes new or updated data so you're not wasting resources. And the best part is how reliable it is—if anything goes wrong, it'll pick back up where it left off, so you don't have to worry about data getting lost. With Databricks Autoloader, ingesting and processing your data is so much more hands-off. You won't have to build custom scripts to monitor files and load data anymore. It just works in the background so you can focus on analyzing your data instead of worrying about the ingestion process.
In this article, we have covered:
- What is Autoloader in Databricks?
- What file types are available in Databricks Autoloader?
- How does Databricks AutoLoader work?
- Step-by-step Guide to using Autoloader to ingest data to Delta Lake
- What Are the Key Main Advantage of Using Databricks Autoloader?
- Difference between Autoloader, Delta live tables and COPY INTO
FAQs
What is Databricks Autoloader?
Databricks Autoloader is a feature in Databricks that automatically ingests and loads raw data files into Delta Lake tables as they arrive in cloud storage locations without any additional configuration.
What cloud storage services does Databricks Autoloader support for data ingestion?
Databricks Autoloader supports ingesting data from AWS S3, Azure Blob Storage, Azure Data Lake Storage (ADLS) Gen2, Google Cloud Storage (GCS), Azure Data Lake Storage (ADLS) Gen1, and the Databricks File System (DBFS).
What are the two modes of file detection supported by Databricks Autoloader?
Two modes of file detection are Directory Listing mode and File Notification mode.
What file formats can Databricks Autoloader ingest?
Databricks Autoloader can ingest JSON, CSV, XML, PARQUET, AVRO, ORC, TEXT, and BINARYFILE file formats.
How does Databricks Autoloader ensure exactly-once processing of ingested files?
Databricks Autoloader persists file metadata in a scalable key-value store (Apache RocksDB) in the checkpoint location, ensuring that each file is processed exactly once and can resume from where it left off in case of failures.
What is the purpose of the cloudFiles.schemaLocation option in Databricks Autoloader?
The cloudFiles.schemaLocation option specifies where Databricks Autoloader should store the inferred schema and any subsequent changes to it.
How does Databricks Autoloader handle schema evolution when ingesting data?
Databricks Autoloader supports schema evolution by merging the inferred schema with the existing table schema, ensuring that no data is lost or corrupted due to schema changes.
Can Databricks Autoloader handle faulty or malformed data during ingestion?
Yes, Databricks Autoloader can capture faulty or malformed data in a _rescued_data column, ensuring that no data is lost or ignored.
How does Databricks Autoloader integrate with Delta Live Tables?
Databricks Autoloader supports both Python and SQL in Delta Live Tables, enabling autoscaling compute infrastructure, data quality checks, automatic schema evolution handling, and monitoring via metrics in the event log.
What is the recommended Autoloader mode for ingesting large volumes of files?
For ingesting large volumes of files or high file arrival rates, the File Notification mode is recommended over the Directory Listing mode, as it offers better scalability and faster performance.
What is the difference between Databricks Autoloader and COPY INTO?
Databricks Autoloader is designed for low-latency, continuous data ingestion scenarios where data is constantly arriving, while COPY INTO is designed for bulk loading large datasets in a batch mode, typically during initial data ingestion or periodic data refreshes.
How does Databricks Autoloader scale to process billions of files or millions of files per hour?
Databricks Autoloader leverages cloud storage services' notifications and RocksDB to efficiently track new or updated files, enabling it to process billions of files or millions of files per hour.
Can Databricks Autoloader automatically infer the schema of ingested data?
Yes, Databricks Autoloader can automatically infer the schema of the ingested data, even if the schema changes over time.
Can Databricks Autoloader handle nested data structures in ingested files?
Yes, Databricks Autoloader supports handling nested data structures in ingested files.
How does Databricks Autoloader differ from Delta Live Tables?
Databricks Autoloader is designed for streaming data ingestion and processing, while Delta Live Tables is designed for building data pipelines and handling batch and streaming workloads with complex data transformations.
Can Databricks Autoloader be configured to process files in a specific order?
Yes, Databricks Autoloader can be configured to process files in a specific order, such as based on file names or timestamps.















