





























Snowflake has consistently improved its data type options, and this year has been especially notable for these enhancements. The platform didn't just introduce a variety of new data types; it also made numerous under-the-hood improvements. Existing Snowflake data types can now handle larger amounts of data more effectively. Rather than completely reinventing the wheel, Snowflake improved its fundamental kinds.
In this article, we provide a comprehensive breakdown of the major Snowflake data type upgrades rolled out in 2025: new structured type support, a native FILE data type, expanded column size limits, XML's general availability, an enhanced VECTOR type for embeddings and AI tasks—and more.
Quick Summary: 5 Major Snowflake Data Type Changes in 2025
- The 128 MB Tier:
VARIANT: 16 MB to 128 MBARRAY: 16 MB to 128 MBOBJECT: 16 MB to 128 MB
- The 64 MB Tier:
BINARY: 8 MB to 64 MBGEOGRAPHY: 8 MB to 64 MBGEOMETRY: 8 MB to 64 MB
Snowflake Data Type Categories: Complete Classification
Snowflake supports a wide range of SQL data types, organized into several categories.
- Numeric —
NUMBER (DECIMAL), INT (INTEGER), FLOAT/DOUBLE, etc. - String/Binary —
VARCHAR/CHAR (STRING, TEXT, NCHAR, etc.), BINARY/VARBINARY. - Logical —
Snowflake BOOLEAN data type. - Date/Time —
DATE, TIME, and TIMESTAMP variants (TIMESTAMP_LTZ, TIMESTAMP_NTZ, TIMESTAMP_TZ, plus aliases like DATETIME). - Semi-Structured —
Snowflake VARIANT data type,Snowflake OBJECT, andSnowflake ARRAY type. (Snowflake VARIANT data type can hold any data type; Snowflake OBJECT and ARRAY also store VARIANT values) - Structured —
Snowflake ARRAY(...) data typeandSnowflake OBJECT(...) data typewith defined element types, andSnowflake MAP(key_type, value_type). These structured types allow you to specify an array of a specific type or an object with typed fields. - Unstructured —
Snowflake FILE data type. (See below). - Geospatial —
Snowflake GEOGRAPHYandSnowflake GEOMETRY data type, for spherical or planar spatial data. - Vector —
Snowflake VECTOR data type, for fixed-length numeric vectors (used in AI/ML embeddings).
Here is a quick table overview of Snowflake data types, categories, and example types:
| Category | Snowflake Data Types |
| Numeric | NUMBER (DECIMAL), INT (INTEGER/BIGINT/etc.), FLOAT, DOUBLE, REAL |
| String/Binary | VARCHAR (CHAR, TEXT, STRING, etc.), NVARCHAR, BINARY, VARBINARY |
| Logical | BOOLEAN |
| Date/Time | DATE, TIME, TIMESTAMP_LTZ, TIMESTAMP_NTZ, TIMESTAMP_TZ (TIMESTAMP alias DATETIME) |
| Semi-Structured | VARIANT, OBJECT, ARRAY |
| Structured | ARRAY(...), OBJECT(...), MAP(..., ...) |
| Unstructured | FILE |
| Geospatial | GEOGRAPHY, GEOMETRY |
| Vector | VECTOR |
These categories cover almost everything you’d use in Snowflake tables.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

🔮 Snowflake Structured Types: ARRAY, OBJECT, and MAP in Standard Tables (GA July 2025)
Structured Snowflake data types (ARRAY, OBJECT, MAP) allow columns to have nested, typed content. Prior to 2025, Snowflake only allowed you to load arrays or JSON-like objects into a specific VARIANT column. Snowflake now provides full support for structured types in regular (non-Iceberg) tables.
Snowflake columns can now be explicitly defined as an ARRAY, OBJECT, or MAP with specific types. (Previously, structured columns were generally allowed only in Snowflake Iceberg tables). You can now explicitly declare columns as, say, an ARRAY of INT or an OBJECT with specific fields without hiding them inside a VARIANT. Structured types still aren’t allowed in dynamic tables, hybrid tables, external tables, or similar environments, but for regular tables they’re now GA.
Now you can have a column defined as ARRAY(NUMBER) or OBJECT(str VARCHAR, num NUMBER). This makes SQL queries more precise and can improve performance, since Snowflake knows the exact types ahead of time.
Timeline:
- Preview: May 2025 (release 9.14)
- General Availability: Mid-July 2025 (release 9.19)
Snowflake Structured Types Limitations:
- Not supported in dynamic tables, hybrid tables, or external tables
- Available in standard tables and Iceberg tables
For reference, here’s how you might define each Snowflake structured type in SQL:
1) Snowflake ARRAY Type
ARRAY(NUMBER) for an array of numbers. You can even nest further: ARRAY(ARRAY(VARCHAR)) for an array of arrays of strings.
2) Snowflake OBJECT Type
OBJECT(col1 VARCHAR, col2 NUMBER) for a fixed object with two keys col1 and col2. Each key can have its own type. (Order matters here: the list of keys is part of the type definition).
3) Snowflake MAP Type
MAP(VARCHAR, NUMBER) for a dictionary with string keys and number values. Keys must be either Snowflake VARCHAR or INTEGER (NUMBER with scale 0).
You can also nest these types. Say, an array could hold objects, or an object’s values could be arrays or even other objects. This lets you model complex data directly in the schema. Snowflake treats each inner field as its own sub-column.
Structured Types Tutorial: Step-by-Step Implementation Example
Step 1: Creating a Table with Structured Type Columns
First, let's create a table. Here, we define it with:
- a simple
INTEGERkey - a structured
ARRAYfor preferences - a nested
OBJECTfor addresses (including lat/lng) - a
MAPfor arbitrary key→value tags
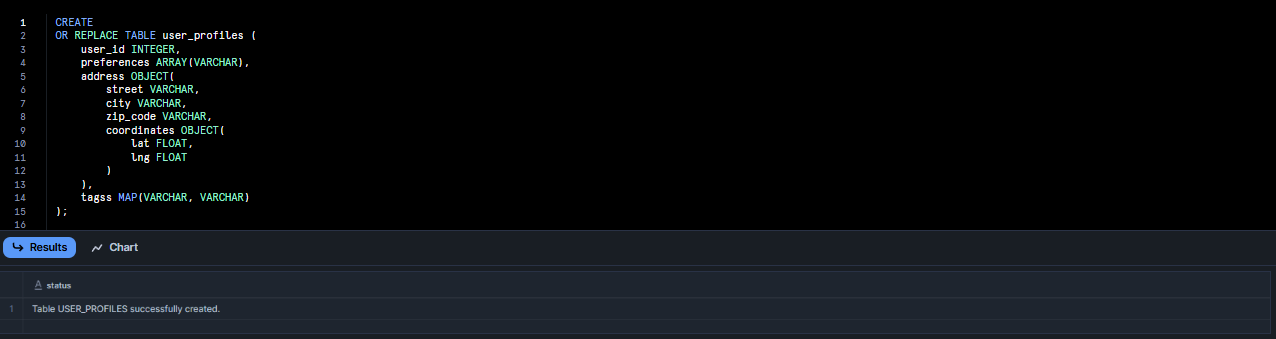
CREATE
OR REPLACE TABLE user_profiles (
user_id INTEGER,
preferences ARRAY(VARCHAR),
address OBJECT(
street VARCHAR,
city VARCHAR,
zip_code VARCHAR,
coordinates OBJECT(
lat FLOAT,
lng FLOAT
)
),
tagss MAP(VARCHAR, VARCHAR)
);
Step 2: Inserting Data into Structured Type Columns Using ARRAY_CONSTRUCT and OBJECT_CONSTRUCT
Now, let's insert into the Snowflake table using INSERT … SELECT because Snowflake requires constructs to be cast into structured types.
INSERT INTO
user_profiles
SELECT
1,
-- build and cast to a structured Snowflake VARCHAR array
ARRAY_CONSTRUCT('notifications', 'dark_mode', 'auto_save')::ARRAY(VARCHAR),
-- build and cast to the same OBJECT definition as above
OBJECT_CONSTRUCT(
'street',
'123 Main St',
'city',
'San Francisco',
'zip_code',
'94105',
'coordinates',
OBJECT_CONSTRUCT('lat', 37.7749, 'lng', -122.4194)
)::OBJECT(
street VARCHAR,
city VARCHAR,
zip_code VARCHAR,
coordinates OBJECT(lat FLOAT, lng FLOAT)
),
-- parse a JSON literal and cast to MAP(VARCHAR, VARCHAR)
PARSE_JSON('{"category":"premium","source":"organic"}')::MAP(VARCHAR, VARCHAR);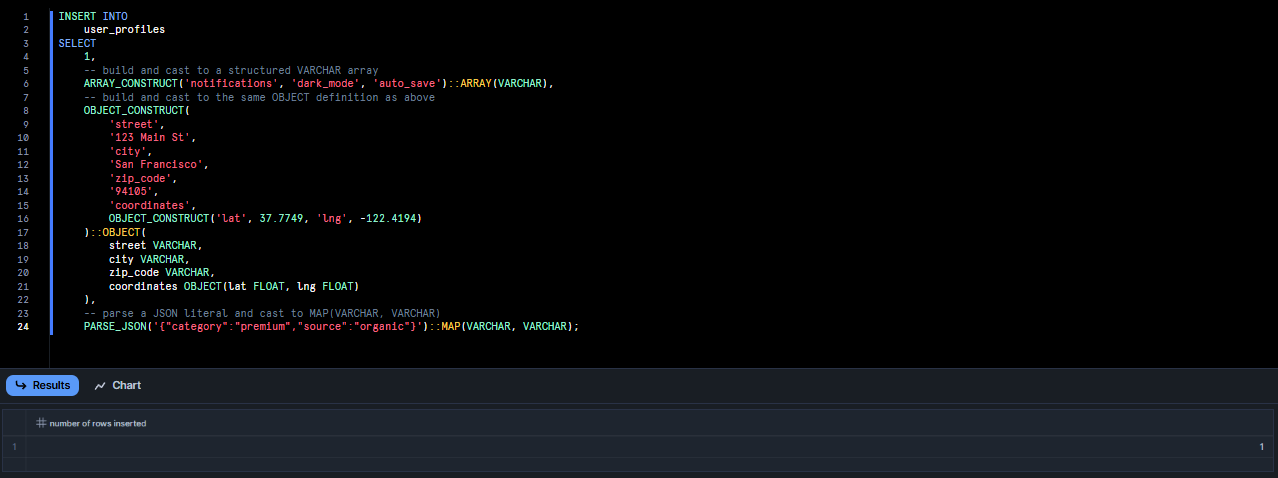
Note that each construct call is explicitly cast (::) to the matching structured type declared above.
- ARRAY_CONSTRUCT builds a semi-structured array, then
::ARRAY(VARCHAR)makes it our typed column. - OBJECT_CONSTRUCT similarly for the address.
- PARSE_JSON + cast yields the MAP.
Step 3: Verifying Structured Data Insertion with SELECT Queries
Quick check that the row exists:
SELECT
*
FROM
user_profiles;
Step 4: Inspecting Table Schema and Column Type Definitions with DESCRIBE TABLE
Now, to inspect the column definitions and types. Execute the following command:
DESCRIBE TABLE user_profiles;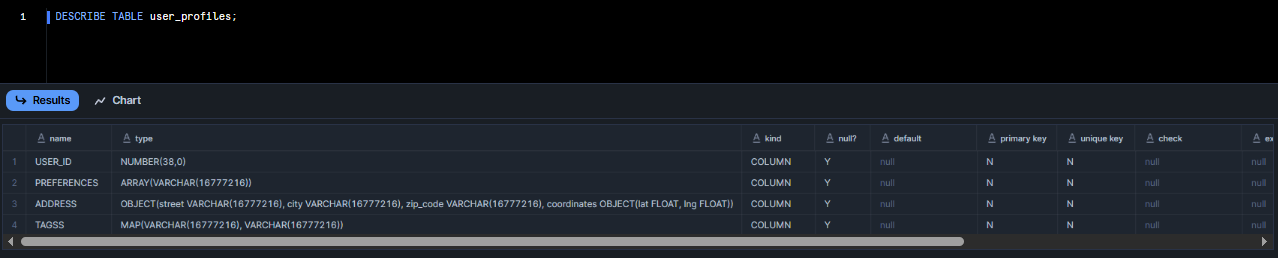
Step 5: Querying and Extracting Nested Fields from Structured Types
Now, if you want to extract specific fields, execute the code below:
SELECT
user_id,
preferences [0] AS first_preference,
address:city::VARCHAR AS city,
address:coordinates:lat::FLOAT AS latitude,
tagss ['category']::VARCHAR AS user_category
FROM
user_profiles;
preferences[0]: first element of the arrayaddress:city: dot-path into the objectaddress:coordinates:lat: nested object accesstagss['category']: lookup in the map
Overall, Snowflake structured types give you more control over nested data and tighter schema definitions. They’re great for cases where you know exactly what fields should appear, and you want the engine to validate types.
Just remember the limitation: not available in hybrid/external tables yet, and Snowflake Iceberg tables handle them automatically.
🔮 Fresh New Snowflake FILE Data Type: Storing Unstructured File References (Preview April 2025)
Snowflake introduced a brand-new FILE data type in April 2025 (preview). It’s not generally available yet. This type is meant for Snowflake unstructured data: it lets you store references to files (images, PDFs, audio) in a table. A FILE column does not contain the file’s bytes. Instead, it holds metadata about a staged file, such as the stage name, path, content type, size, and last-modified timestamp. You can think of it as a pointer or link to a file, rather than the file itself. The main purpose of this FILE is to make it easy to mix Snowflake unstructured data (images, PDFs) directly into SQL workflows, especially for AI use cases.
Let's say your data (images, documents, audio) is stored in an external system or Snowflake stage; a FILE column just keeps the path and metadata. In a table, it looks like any other column, but internally, Snowflake only keeps a reference. This is perfect for multimodal analytics: say, you could have a table of product reviews with an image column of type FILE and text columns, then run AI sentiment or image tasks on those files.
Snowflake FILE type bundles several metadata fields.
| Field | Description |
| STAGE | Name of the stage (internal or external) |
| RELATIVE_PATH | Path within the stage |
| STAGE_FILE_URL | Full URL of the file in the stage |
| SCOPED_FILE_URL | Secure, time-limited URL |
| CONTENT_TYPE | MIME type (image/png, application/pdf) |
| SIZE | File size in bytes |
| ETAG | Content hash for caching/validation |
| LAST_MODIFIED | Timestamp of last update |
Each FILE value must include the content type, size, etag, last_modified, and one way of specifying the location (stage + path or a file URL). You usually use TO_FILE('<stage_path>') or TO_FILE('file://some/url') to create the reference, and Snowflake fills in the rest.
Example:
Suppose you have an external stage my_images full of image files. You can do:
CREATE TABLE images_table(img FILE); -- 'img' column holds file references
ALTER STAGE my_images DIRECTORY=(ENABLE=true); -- enable directory listing if needed
-- Populate the table with references to each file in the stage:
INSERT INTO images_table
SELECT TO_FILE(file_url)
FROM DIRECTORY(@my_images);
Here, TO_FILE(file_url) takes each staged file’s URL and creates a FILE object. After that, images_table.img holds a FILE value for each file. You can query its metadata with built-in functions. For example:
SELECT
FL_GET_RELATIVE_PATH(img) AS path,
FL_GET_CONTENT_TYPE(img) AS type,
FL_GET_LAST_MODIFIED(img) AS mod_time
FROM images_table;This would list the relative path, content type, and modification time for each image in the table. (Snowflake provides many FL_ functions to extract parts of the FILE reference.) The FILE column makes it easy to use Snowflake’s unstructured-AI features (like AI/ML image or document analytics) directly on files stored in stages.
Note: Snowflake FILE is in preview mode. It must have certain fields (CONTENT_TYPE, SIZE, ETAG, LAST_MODIFIED) and doesn’t yet work in ORDER BY, GROUP BY, SnowScript, Snowflake Iceberg/external tables. But it’s enabled on all accounts.
🔮 Bigger Column Size Limits (128 MB and 64 MB)
Another important update was about column size limits. Snowflake bumped up the maximum column size limits for large types. Now each column can hold about 8 times more data.
- VARCHAR, VARIANT, ARRAY, and OBJECT: up to 128 MB of data (up from 16 MB).
- BINARY, GEOGRAPHY, and GEOMETRY: up to 64 MB (up from 8 MB).
You can now store much larger strings or JSON blobs in a single column now. But, the default length for VARCHAR and BINARY remains 16MB/8MB. To actually use the bigger size, you must specify it when you create (or alter) a column.
How do you use this? There’s nothing you need to change in your code, except you might need to enable the new behavior in very old accounts. For new or updated accounts after June, the 2025_03 bundle (which turns this feature on) is enabled by default. If you had a really old account with the 2025_02 bundle disabled, you would have needed to opt-in. But basically today you get the larger limits automatically.
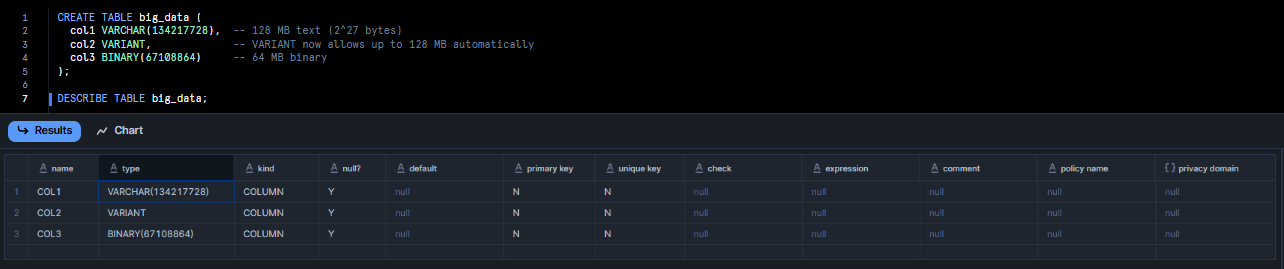
Example:
To create a table with a max-size text and binary column:
CREATE TABLE big_data (
col1 VARCHAR(134217728), -- 128 MB text (2^27 bytes)
col2 VARIANT, -- VARIANT now allows up to 128 MB automatically
col3 BINARY(67108864) -- 64 MB binary
);
You could also alter an existing VARCHAR column to the new limit:
ALTER TABLE big_data
ALTER COLUMN col1 SET DATA TYPE VARCHAR(134217728); -- expand to 128 MBNote: You cannot alter an existing BINARY column’s size – it must be created with the larger size from the start.) For VARIANT, ARRAY, and OBJECT types, you don’t need to change anything. These structured/semi-structured types now automatically allow up to 128MB per value.
(One thing to watch: extremely large columns can affect performance or memory usage, so use them carefully).
🔮 Snowflake XML support matured to GA
Semi-structured data got a boost, too. Snowflake has long let you load JSON, Avro, Parquet, etc, into VARIANT columns, but in March 2025 it finally brought XML into GA. Now you can load XML files directly into a VARIANT column by using a file format of TYPE=XML. Under the hood Snowflake parses the XML and stores it as a semi-structured VARIANT.
One thing: by default, XML element order is not preserved, so it’s like a key-value structure internally.
Using it is straightforward: treat your XML like any other semi-structured load. For example:
CREATE OR REPLACE TABLE xml_table(data VARIANT);
COPY INTO xml_table
FROM @my_stage/xml_files/file1.xml
FILE_FORMAT=(TYPE=XML)
ON_ERROR='CONTINUE';This copies the XML document into the VARIANT column data. You can then query it much like JSON.
SELECT data:"$" FROM xml_table;It returns the parsed XML content. You can use the same hierarchical path operators (: and ->) or XMLGET functions.
SELECT
XMLGET(data, 'Person') AS person_node,
data:"Person"."Name" AS person_name
FROM
xml_table;This uses XMLGET to pull out XML elements.
Snowflake treats XML as a first-class semi-structured format now, similar to JSON.
This update is mostly about convenience and completeness. Many enterprises have XML-based feeds or old data in XML, and they no longer have to pre-convert to JSON or parse it themselves. Snowflake just handles it natively now. It doesn’t add a new column type, but it does expand how Snowflake treats data formats.
No special syntax is needed beyond using the XML file format. Just keep in mind that XML in Snowflake ends up in a VARIANT, so it inherits all the usual size limits (now up to 128 MB as noted above). The queries you write against XML-loaded data are essentially the same as JSON queries. This makes Snowflake a one-stop shop for most common data file types.
🔮 Enhanced Snowflake VECTOR Data Type
Snowflake VECTOR data type (for numeric vectors used in AI/ML) became generally available in 2024. In 2025 it’s fully supported and polished. A VECTOR column stores a fixed-size array of numbers (either FLOAT or INT) – for example an embedding with 768 dimensions. The maximum dimension is 4096. This lets you store semantic embeddings in Snowflake for similarity search or RAG applications.
To specify a Snowflake VECTOR data type, use the following syntax:
VECTOR( <type>, <dimension> )<type>can be INT (32-bit integer) or FLOAT (32-bit floating point).<dimension>is the vector’s length, a positive integer up to 4096
Valid and Invalid Examples
✅ Valid:
VECTOR(FLOAT, 256)
VECTOR(INT, 16)❌ Invalid:
VECTOR(STRING, 256) -- Unsupported element type
VECTOR(INT, -1) -- Invalid dimensionHere are some limitations of Snowflake VECTOR data type.
- Snowflake VECTOR is supported in SQL, the Python connector, and Snowpark Python, but not in other languages
- You can't directly unload Snowflake VECTOR columns; unload as ARRAY, then cast to VECTOR after loading
- Not supported in Snowflake VARIANT columns.
- Cannot be a clustering key.
- Not supported with Snowpipe, Search Optimization, Snowflake Iceberg tables, bind variables, scripting, or server-side binding in certain cases.
🔮 Additional Enhancements
Aside from the major ones mentioned above, Snowflake released a few other upgrades this year:
- Smoother casting between semi-structured and structured types: You can now cast between semi-structured and structured types more smoothly. Example,
[1,2,3]::ARRAY(NUMBER)casts a Snowflake VARIANT array to a structured array of NUMBERs. This just means the engine will validate the contents against the target type. It’s a nice bonus for data pipeline scripts. - Spread Operator (
**): Snowflake introduced a ** operator to expand arrays into individual columns. It’s not a data type change, but it lets you take an array column and turn it into multiple columns in a SELECT. In other words, it “spreads” an array into multiple values in one go.
SELECT a, **b FROM my_table; -- b is an array- Snowflake MAP helpers: Structured Snowflake MAP(key, value) types were already available with the structured types GA, but just to note: you can define a map column like
my_map MAP(VARCHAR, INT)inCREATE TABLE. Snowflake also provides casting between OBJECT and MAP types and functions likeMAP_KEYS (Extract all keys), MAP_VALUES (Extract all values), MAP_INSERT (Add key-value pairs)to work with them. - Performance Improvements:
- Faster operations on large VARIANT, ARRAY, and OBJECT columns
- Better type inference for semi-structured data
- Enhanced error messages for type conversions
Snowflake Data Type Migration, Best Practices, and Performance Guide
- Use typed ARRAY/OBJECT/MAP when the nested schema is stable and you want strict type validation and predictable query performance. Structured types are ideal for production tables with repeated, well-known nested fields.
- Keep using Snowflake VARIANT when the nested shape is highly variable, evolving, or when ingestion is heterogeneous. Snowflake VARIANT remains the best option for exploratory, ingestion-first workflows.
- Prefer FILE references or external stage references for images, large documents or binaries. Use Snowflake VARIANT or VARCHAR for moderately large textual payloads where needed. If you must store very large JSON or blobs in a single column, test memory and query performance under realistic concurrency.
- Load as Snowflake ARRAY, then cast to Snowflake VECTOR. Because direct unload/load of VECTOR is limited, prefer staging arrays then performing
::VECTORcasts in controlled update steps. - Check your account’s behavior bundles (
2025_01,2025_02,2025_03etc.) if you rely on increased size limits or changed XML parsing. Newer account bundles enable the larger size limits by default, but older accounts may need manual enablement or object refresh.
Save up to 30% on your Snowflake spend in a few minutes!


Conclusion
And that's a wrap! Snowflake has been cranking out updates left and right, so it feels like something new is always around the corner. The big takeaways for 2025 so far are that structured types are live, Snowflake FILE data type is in testing, column sizes have gotten a lot bigger, and XML is fully on board. These changes all focus on how we handle and store data. Be sure to check the latest docs for any last-minute tweaks (Snowflake likes to refine its preview features before they go live), but the main idea is clear: Snowflake is making its data types more flexible and powerful.
Frequently Asked Questions (FAQs)
What is a data type in Snowflake?
A data type specifies what kind of values a column can hold. Snowflake groups types into categories like numeric (NUMBER, INT, FLOAT), string/binary (VARCHAR, BINARY), logical (BOOLEAN), date/time, semi-structured (VARIANT, OBJECT, ARRAY), structured (ARRAY, OBJECT, MAP). These types determine storage format and supported operations.
How do I see data types in Snowflake?
You can use DESC TABLE or SHOW COLUMNS.
CREATE TABLE t(val STRING, x VARIANT);
DESC TABLE t;This will list each column and its data type. You can also query INFORMATION_SCHEMA.COLUMNS for programmatic access.
Which data types are not supported by Snowflake?
Snowflake does not support traditional LOB types. For example, it has no native BLOB or CLOB; instead use Snowflake VARIANT or BINARY/VARCHAR. It also doesn’t support things like SQL ENUM or custom user-defined types. Virtually all standard data (numbers, strings, dates, JSON) is supported.
How do structured types differ from Snowflake VARIANT?
Structured types (like ARRAY(INT) or OBJECT(name VARCHAR, age INT)) have a fixed internal schema: you define the element/key types up front. Snowflake VARIANT is an untyped container (semi-structured): it can hold any JSON-like data.
ARRAY(INT) is a structured array of numbers, whereas Snowflake VARIANT could hold an array of any type.
Can I use Snowflake ARRAY Type and OBJECT in external or hybrid tables?
No. As of 2025, structured columns (ARRAY, OBJECT, MAP) are only supported in standard (Snowflake-managed) tables. They are not allowed in dynamic, hybrid, or external tables. Only Iceberg tables had them before, and now standard tables do too.
What is the FILE data type for?
Snowflake FILE data type is a Snowflake unstructured data type that stores a reference to a staged file. A FILE column holds metadata about a file (stage name, path, size, MIME type). It lets you include documents or media in tables. Essentially, FILE links to a file but doesn’t load its contents into Snowflake rows.
Is FILE generally available?
No. Snowflake FILE data type is currently in preview (announced April 2025). It’s available to all accounts in preview mode, but it’s not marked as GA yet in the docs
Do I need to change table definitions for larger limits?
For most types (VARIANT, ARRAY, OBJECT), no action is needed – they automatically accept the new 128 MB limit. But for VARCHAR or BINARY, you must explicitly define the larger size. Like, VARCHAR(134217728) for 128MB text or BINARY(67108864) for 64MB binary. If you have an existing VARCHAR column and want to enlarge it, you can use ALTER TABLE ... ALTER COLUMN ... SET DATA TYPE VARCHAR(134217728). Otherwise the default remains 16MB for VARCHAR (8MB for BINARY).
How do I load XML into Snowflake?
Stage your XML file, then use COPY INTO with FILE_FORMAT=(TYPE=XML).
CREATE TABLE xml_store(data VARIANT);
COPY INTO xml_store FROM @my_stage/file.xml FILE_FORMAT=(TYPE=XML);This loads the XML into the VARIANT column. Snowflake will parse the XML into the same JSON-like structure you query with the dot/array syntax.
Can I query XML like JSON in Snowflake?
Yes. Once XML is in a VARIANT column, you use the same query methods as JSON.
SELECT xml_column:"$.root.item"::VARCHAR FROM table;Snowflake provides XML-specific functions like XMLGET() for more complex operations.
What's the maximum size for VECTOR data type?
VECTOR types support up to 16,000 dimensions. Each element is a FLOAT, so a fully-utilized VECTOR can be quite large. The exact size limit depends on the precision and dimension count you specify.
Do structured types work with time travel?
Yes, structured types support time travel just like other Snowflake data types. You can query historical data using AT or BEFORE clauses with tables containing ARRAY, OBJECT, or MAP columns.
Can I convert VARIANT to structured types?
Yes, but you need to explicitly create new columns with structured types and migrate data:
ALTER TABLE ADD COLUMN new_structured_col ARRAY(VARCHAR);
UPDATE TABLE SET new_structured_col = old_variant_col::ARRAY(VARCHAR);Are there performance differences between structured types and VARIANT?
Yes. Structured types can be faster for predictable query patterns because Snowflake knows the data structure upfront. But, VARIANT offers more flexibility and might perform better for diverse, unpredictable data structures.















