





























Running Apache Spark on Kubernetes with AWS EMR on EKS brings big benefits – you get the best of both worlds. AWS EMR's optimized Spark runtime and AWS EKS's container orchestration come together in one managed platform. Sure, you could run Spark on Kubernetes yourself, but it's a lot of manual work. You'd need to create a custom container image, set up networking, and handle a bunch of other configurations. But with EMR on EKS, all that hassle goes away. With EMR on EKS, AWS supplies the Spark runtime as a ready-to-use container image, handles job orchestration, and ties it all into EKS. Just submit your Spark job to an EMR virtual cluster (which maps to an EKS namespace), and it runs as a Kubernetes pod under EMR’s control. You still handle some IAM and networking setup, but the heavy lifting like runtime tuning, job scheduling, container builds, is all handled for you.
In this article, we will first explain why EMR on EKS is useful, show how its architecture works, compare EMR on EC2 vs EMR on EKS. Finally, we will give you a step-by-step recipe (with actual AWS CLI commands and config samples) to get a Spark job running on Kubernetes via EMR on EKS.
Why Use AWS EMR on EKS for Spark Workloads?
First, why use AWS EMR on EKS at all? What do you gain by running Spark on Kubernetes under EMR instead of the familiar EMR on EC2 or even self-managed Spark on EKS? The short answer is flexibility and ease of management. EMR on EKS offers the best of both worlds: managed Spark plus Kubernetes. It avoids the hassle of building Spark containers and managing Spark clusters by hand.
What are the benefits of EMR on EKS?
AWS EMR on EKS model offers several advantages:
Benefit 1: Simplified Spark Runtime Management
You get the same managed Spark experience that EMR on EC2 provides, but on Kubernetes. EMR takes care of provisioning the Spark runtime (with pre-built, optimized Spark versions), auto-scaling, and provides development tools like EMR Studio and the Spark UI. AWS handles the Spark container images and integration so you don’t have to assemble them yourself.
Benefit 2: Cost Optimization via Kubernetes Resource Sharing
Your Spark jobs run as pods on an EKS cluster that can also host other workloads, so you avoid waste from idle clusters. Nodes come up and down automatically, and you pay only for actual usage. AWS specifically points out that with EMR on EKS “compute resources can be shared” and removed “on demand to eliminate over-provisioning”, leading to lower costs.
Benefit 3: Fast Job Startup and Performance Improvements
You can reuse an existing Kubernetes node pool, so there’s no need to spin up a fresh cluster for each job. This eliminates the startup lag of launching EC2 instances. In fact, AWS claims EMR’s optimized Spark runtime can run some workloads up to 3× faster than default Spark on Kubernetes.
Benefit 4: Flexible Spark and EMR Version Management
You can run different Spark/EMR versions side by side on the same cluster. EMR on EKS lets one EKS namespace host Spark 2.4 apps and another host Spark 3.0. According to AWS, you can use a single EKS cluster to run applications that require different Apache Spark versions and configurations. This is handy if some jobs need legacy code while others take advantage of newer Spark features.
Benefit 5: Native Integration with Kubernetes and AWS Tools
EMR on EKS ties into Kubernetes APIs and IAM Roles for Service Accounts (IRSA). You can use your existing EKS authentication methods, networking, logging, and autoscaler to manage Spark pods.
Benefit 6: EMR Cloud-Native Experience on Kubernetes
Finally, you still get EMR conveniences like EMRFS (optimized S3 access), default security and logging settings, and support for EMR Studio or Step Functions. AWS even provides AWS Step Functions and EMR on EKS templates to streamline workflows.
All in all, EMR on EKS is great if you already have (or plan to use) Kubernetes for container workloads and want the managed Spark experience. It avoids the manual work of installing Spark on Kubernetes (which you’d have to do if you ran open-source Spark on EKS).
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

EMR on EKS System Architecture Explained
At a very high level, EMR on EKS loosely couples Spark to Kubernetes. EMR (the control plane) simply tells EKS what pods to run, and EKS handles the actual compute (EC2 / Fargate). Here’s how it works under the hood:
The EMR on EKS architecture is a multi-layer pipeline. At the top level you have AWS EMR, which now has a “virtual cluster” registered to a namespace in your AWS EKS cluster. When you submit a Spark job through EMR (for example, using aws emr-containers start-job-run), EMR takes your job parameters and tells Kubernetes what to run. Under the hood, EMR creates one or more Kubernetes pods for the Spark driver and executors. Each pod pulls a container image provided by EMR (Amazon Linux 2 with Spark installed) and begins processing.
The Kubernetes layer (AWS EKS) is responsible for scheduling these pods onto available compute. It can use either self-managed EC2 nodes or Fargate to supply the necessary CPU and memory. In practice, you often configure an EC2 Auto Scaling Group behind EKS so that new nodes spin up as Spark executors need them. The architecture supports multi-AZ deployments: pods can run on nodes in different availability zones, giving resilience and access to a larger pool of instances.
Below the compute layer, your data lives in services like AWS S3, and your logs/metrics flow to CloudWatch (or another sink). EMR on EKS handles the wiring: it automatically ships driver and executor logs to CloudWatch Logs and S3 if you configure it, and even lets you view the Spark History UI from the EMR console after a job completes.
TL;DR: EMR on EKS decouples analytics from infrastructure: EMR builds the Spark application environment and Kubernetes provides the execution environment.
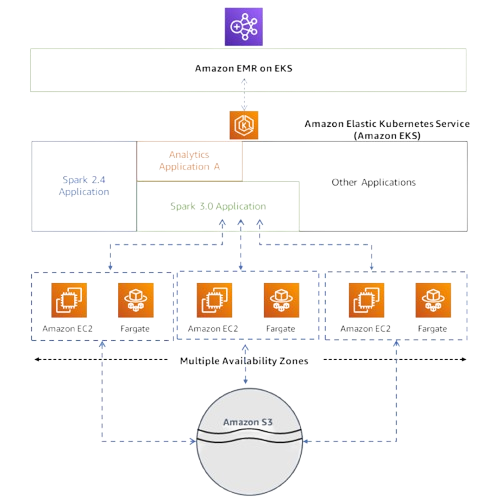
EMR on EKS “loosely couples” Spark to your Kubernetes cluster. When you run a job, EMR uses your job definition (entry point, arguments, configs) to tell EKS exactly what pods to run. Kubernetes does the pod scheduling onto EC2/Fargate nodes. Because it’s loose, you can run multiple isolated Spark workloads on the same cluster (even in different namespaces) and mix them with other container apps.
EMR on EC2 vs EMR on EKS: Detailed Comparison
It’s worth understanding the difference between the old-school EMR on EC2 vs EMR on EKS, so you know when to pick each. With EMR on EC2, Amazon launches a dedicated Spark cluster for you on EC2 instances (possibly with EC2 Spot for cost savings). Those instances are dedicated to EMR, and YARN or another scheduler allocates resources. You have full control of the cluster’s Hadoop/Spark config and node sizes, but the resources are siloed. In contrast, with EMR on EKS, you reuse your shared Kubernetes cluster. EMR on EKS simply runs Spark on that cluster’s nodes (alongside other apps).
| EMR on EC2 | 🔮 | EMR on EKS |
| Dedicated EC2 instances | Resource Allocation | Shared Kubernetes cluster |
| YARN-based scheduling | Orchestration | Kubernetes-native scheduling |
| Pay for dedicated instances | Cost Model | Pay only for actual resource usage |
| Limited to single EMR version per cluster | Multi-tenancy | Multiple versions and configurations |
| Slower due to EC2 instance provisioning | Startup Time | Faster using existing node pools |
| Native Hadoop ecosystem support | Integration | Cloud-native Kubernetes ecosystem |
| EMR managed scaling | Scaling | Kubernetes autoscaling + Karpenter/Fargate |
🔮 Use EMR on EC2 when you want a standalone cluster per workload. If you have a stable, heavy Spark job schedule and don’t already have Kubernetes in the picture, EMR on EC2 can be straightforward. It’s the classic way to run Hadoop/Spark and it integrates with HDFS/other Hadoop ecosystem tools out of the box. EMR on EC2 might also make sense if you need features currently only in EMR’s YARN-based mode, or if containerization is not a requirement.
🔮 Use EMR on EKS when you have a Kubernetes environment (or plan to) and want to colocate Spark with other container workloads. It’s great for multi-tenancy and agility – one EKS cluster can host multiple Spark applications (even with different EMR versions) and also run other services (like Airflow, machine learning apps, etc.). If you’re already managing infrastructure with EKS and Helm or Terraform, adding Spark workloads there avoids siloing. EMR on EKS also handles the complex AWS integration (EMRFS, S3, IAM) for you, whereas manually running Spark on vanilla Kubernetes would require gluing together a lot of pieces.
Step-By-Step Guide to Run Spark on Kubernetes with AWS EMR on EKS
Now we get hands-on. We’ll walk through all the setup steps, including code snippets and YAML where appropriate. You can run these commands in any region (just add the --region or ARNs/URIs as needed).
Prerequisite:
First things first, make sure you have the following things configured:
- AWS Management Console access with appropriate permissions
- Basic understanding of EMR cluster architecture and Spark fundamentals
- Familiarity with the AWS Management Console navigation
- AWS CLI configured with appropriate credentials and permissions
- kubectl (Kubernetes CLI) installed and configured
- eksctl (EKS cluster CLI) installed and configured
- Basic understanding of Kubernetes concepts (pods, namespaces, services)
- An existing VPC with appropriate subnets or permission to create new networking resources
- Understanding of IAM roles and policies for service integration
Step 1—AWS Console Access and CLI Setup for EMR and EKS
Log in to the AWS Console or make sure your AWS CLI is authenticated. If using the CLI, you should have a profile set up (using aws configure or environment variables) with credentials. You can test by running something like:
aws sts get-caller-identityIf this returns your account and user/role info, you’re ready. No specific AWS region is required for EMR on EKS itself, but keep in mind you’ll launch resources (like EKS nodes) in some region or AZs when prompted.
Note: Many AWS CLI commands require specifying a region or having a default region configured (~/.aws/config). Pick one (us-west-2) and use it consistently.
Step 2—Creating an AWS EKS Kubernetes Cluster
Now create an EKS cluster that Spark will run on. You can use eksctl for a simple setup.
eksctl create cluster \
--name my-emr-on-eks-cluster \
--nodes 3 \
--nodes-min 1 \
--nodes-max 4 \
--managedAs you can see, this command (in your default region) will create a new EKS cluster named my-emr-on-eks-cluster with 3 managed Linux node group instances (by default m5.large, but you can specify --node-type if you need something different). It also enables a node autoscaler (min 1, max 4).
Once it completes, eksctl updates your ~/.kube/config so that kubectl knows about this cluster. You can verify:
kubectl get nodes -o wideYou should see 3 (or up to 4 as they scale) EC2 instances ready. To view the workloads running on your cluster:
kubectl get pods -A -o wideNote: In production, you might want to create nodegroups in multiple AZs, use Spot instances, a wider node type mix, etc. This example uses a simple default setup for clarity.
Step 3—Setting Up Kubernetes Namespace and EMR Access
We’ll dedicate a Kubernetes namespace for EMR Spark jobs. A “namespace” in Kubernetes isolates resources. Let’s make one (called spark for example):
kubectl create namespace sparkNext, we must let EMR’s service account access this namespace. AWS provides the eksctl create iamidentitymapping command to link EMR’s service-linked role to the namespace. Run:
eksctl create iamidentitymapping \
--cluster my-emr-eks-cluster \
--namespace spark \
--service-name emr-containersThis command creates the necessary Kubernetes RBAC (Role & RoleBinding) and updates the aws-auth ConfigMap so that the AWSServiceRoleForAmazonEMRContainers role is mapped to the user emr-containers in the spark namespace. In other words, it gives EMR on EKS permission to create pods, services, etc. in spark. (If this fails, ensure you’re using a recent eksctl version and that your AWS credentials can modify the cluster’s IAM config).
Step 4—Create a Virtual Cluster for EMR (Register EKS Cluster with EMR)
Now register this namespace as an EMR virtual cluster. A virtual cluster in EMR on EKS terms is just the glue that tells EMR “use this EKS cluster and namespace for job runs”. It does not create new nodes; it just links to the existing cluster.
Use the AWS CLI emr-containers command:
aws emr-containers create-virtual-cluster \
--name spark-vc \
--container-provider '{
"type": "EKS",
"id": "my-emr-eks-cluster",
"info": {"eksInfo": {"namespace": "spark"}}
}'Replace my-emr-eks-cluster with your cluster name (as above). You’ll get back a JSON with a virtualClusterId (it looks like vc-xxxxxxxx).
After running, you can verify the virtual cluster with:
aws emr-containers list-virtual-clustersAnd note the ID for the one named spark-vc. We’ll use that in the next step. (The virtual cluster itself doesn’t create any servers; it just links EMR to the namespace).
Step 5—Registering EKS Cluster as EMR Virtual Cluster
Spark jobs running on EMR on EKS need an AWS IAM role to access AWS resources (for example, S3 buckets). This is called the job execution role. We create an AWS IAM role that EMR can assume, and attach a policy for S3 and CloudWatch logs.
5a—Define and Create the IAM Role (EMR Job Execution Role)
We’ll create a role that trusts EMR. One way is to trust the elasticmapreduce.amazonaws.com service and then update it for IRSA.
For example:
aws iam create-role --role-name EMROnEKSExecutionRole \
--assume-role-policy-document '{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {"Service": "elasticmapreduce.amazonaws.com"},
"Action": "sts:AssumeRole"
}]
}'Replace EMROnEKSExecutionRole with your own name. This sets up the role so EMR (service name elasticmapreduce.amazonaws.com) can assume it.
5b—Attach Required AWS Policies and Permissions
Next, attach an AWS IAM policy that grants permissions to this role. At minimum, give it read/write access to your S3 buckets and permission to write logs. For example:
aws iam put-role-policy --role-name EMROnEKSExecutionRole --policy-name EMROnEKSExecutionPolicy \
--policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:ListBucket",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::YOUR-LOGS-BUCKET",
"arn:aws:s3:::YOUR-LOGS-BUCKET/*"
]
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:DescribeLogStreams",
"logs:DescribeLogGroups"
],
"Resource": "arn:aws:logs:*:*:log-group:/aws/emr-containers/*"
}
]
}'Replace YOUR-LOGS-BUCKET with your S3 bucket name (or use * to allow all buckets, but locking it down is better). This grants S3 and CloudWatch Logs access.
After this, note the role ARN (you can fetch it with aws iam get-role). We’ll use that in the job submission.
aws iam get-role --role-name EMROnEKSExecutionRole --query 'Role.Arn' --output textStep 6—Enabling IRSA (IAM Roles for Service Accounts) in EKS
Prerequisites: Before running the update-role-trust-policy command, make sure that your EKS cluster has an OIDC identity provider associated. You can set this up with:
eksctl utils associate-iam-oidc-provider --cluster your-cluster-name --approveAWS EMR on EKS uses AWS IAM Roles for Service Accounts (IRSA) under the hood. To let Spark pods assume our role, we update its trust policy. AWS provides a handy command:
aws emr-containers update-role-trust-policy \
--cluster-name my-emr-eks-cluster \
--namespace spark \
--role-name EMROnEKSExecutionRoleThis command modifies the role’s trust policy to allow the OIDC provider for your EKS cluster, specifically any service account named like emr-containers-sa-*-<ACCOUNTID>-<something> in the spark namespace to assume it. Essentially, it ties the role to the Kubernetes service account that EMR creates for each job. After running this, your Spark driver and executor pods (which use that service account) will be able to use the permissions of EMROnEKSExecutionRole.
You can verify the trust policy was updated correctly by checking the role:
aws iam get-role --role-name EMROnEKSExecutionRole --query 'Role.AssumeRolePolicyDocument'The output should now include entries for both the EMR service and your EKS cluster's OIDC provider.
Step 7—Submitting Apache Spark Jobs to EMR Virtual Cluster
We’re ready to run a Spark job. Let’s assume you have a PySpark script my_spark_job.py in S3 (s3://my-bucket/scripts/my_spark_job.py) and you want the output in s3://my-bucket/output/. We’ll ask for 2 executors with 4 GiB each as a simple example.
Use the start-job-run command:
aws emr-containers start-job-run \
--virtual-cluster-id <my-virtual-cluster-id> \
--name example-spark-job \
--execution-role-arn arn:aws:iam::123456789012:role/EMROnEKSExecutionRole \
--release-label emr-6.10.0-latest \
--job-driver '{
"sparkSubmitJobDriver": {
"entryPoint": "s3://my-bucket/scripts/my_spark_job.py",
"entryPointArguments": ["s3://my-bucket/output/"],
"sparkSubmitParameters": "--conf spark.executor.instances=2 --conf spark.executor.memory=4G"
}
}'- Replace
<virtual-cluster-id>with the ID from Step 4. - Set the
--execution-role-arnto your role’s ARN from Step 5. --release-labelchooses the EMR/Spark version (6.10.0 is Spark 3.x; pick as needed).- The JSON under
--job-drivertells EMR to run spark-submit with our script. We pass the output path as an argument, and set Spark configs for 2 executors of 4 GiB memory.
You can add --configuration-overrides (in JSON) if you want to enable additional logging or set extra Spark configs. But the above is the basic form. After you run it, you’ll get a job-run ID. EMR on EKS will then schedule the Spark driver pod and executor pods on the cluster.
Step 8—Monitoring Spark Job Status and Viewing Results
After submission, you can track the job status. Use:
aws emr-containers describe-job-run \
--virtual-cluster-id <virtual-cluster-id> \
--id <job-run-id>This will show status (PENDING, RUNNING, etc.) and more details. You can also see the job in the EMR console under Virtual Clusters, or use EMR Studio if you have it set up.
Logs: EMR on EKS sends logs to CloudWatch Logs and S3 (if configured) by default. Check CloudWatch for log group named like /aws/emr-on-eks/ or similar. You should see log streams for your driver and executor. Also, EMR keeps the Spark History. In the EMR console’s “Job runs” details, there’s a link to the Spark UI logs for debugging.
For example, after starting the job, you can run:
aws emr-containers list-job-runs \
--virtual-cluster-id <virtual-cluster-id>to see the job's progress and current status. Use describe-job-run for details like log URIs or final status.
Collecting and Viewing Job Output and Logs
Once the job completes, any output will be in your S3 path (e.g. s3://my-bucket/output/). Check there for results. You can also open the Spark History Server UI via the EMR console to inspect job stages and metrics (just click the link for that job’s Spark UI). All the data-processing was done by pods on your EKS cluster, so there’s no EMR cluster to terminate – it was purely virtual.
Step 9—Resource Cleanup: Deleting EMR Virtual Clusters, EKS Namespace, and Roles
When you’re done, you’ll want to delete what you created to avoid charges.
Delete the Spark job runs (they are ephemeral, so you really only need to delete the virtual cluster).
1) Delete the EMR virtual cluster:
aws emr-containers delete-virtual-cluster --id <my-virtual-cluster-id>(You can list your virtual clusters to get the ID, or use the one from creation). This removes EMR’s registration.
2) Delete the Kubernetes namespace:
kubectl delete namespace spark-jobs3) Delete the EKS cluster:
eksctl delete cluster --name spark-cluster4) Remove the AWS IAM role and policies:
aws iam detach-role-policy \
--role-name EMRContainers-JobExecutionRole \
--policy-arn arn:aws:iam::aws:policy/AmazonEMRContainersServiceRolePolicy
aws iam delete-role \
--role-name EMRContainers-JobExecutionRole(If you attached any managed policies, detach them first).
Once cleaned up, you’ll only be charged for the time your nodes were up and any storage/transfer. There’s no separate “EMR on EKS” fee beyond normal EMR and EC2 usage.
Troubleshooting and Diagnosing Common EMR on EKS Issues
1) Fixing Pod Failures and Resource Constraint Errors
Issue: Jobs fail with insufficient resources errors.
Solution: Check node groups have adequate capacity and use appropriate instance types:
- Check node capacity
kubectl describe nodes- Verify resource requests vs available capacity
kubectl top nodes2) Resolving IRSA and AWS IAM Authentication Problems
Issue: Jobs fail with AWS permission errors despite correct AWS IAM policies.
Solution: Verify OIDC provider configuration and trust policy:
- Check OIDC provider exists
aws iam list-open-id-connect-providers- Verify trust policy includes correct OIDC provider
aws iam get-role --role-name EMROnEKSExecutionRole \
--query 'Role.AssumeRolePolicyDocument'3) Addressing Networking and DNS Issues with Spark on EKS
Issue: Jobs cannot access S3 or other AWS services.
Solution: Verify VPC endpoints, security groups, and DNS configuration:
- Check CoreDNS pods
kubectl get pods -n kube-system -l k8s-app=kube-dns- Verify VPC endpoints
aws ec2 describe-vpc-endpoints --filters "Name=vpc-id,Values=<your-vpc-id>"Save up to 50% on your Databricks spend in a few minutes!


Conclusion
And that’s a wrap! You have successfully set up and run Apache Spark applications on Kubernetes using AWS EMR on EKS. This powerful combination provides the flexibility of Kubernetes with the managed capabilities of EMR, enabling you to run scalable analytics workloads efficiently. EMR on EKS offers significant advantages in terms of resource utilization, cost optimization, and operational simplicity while maintaining the performance benefits of EMR's optimized Spark runtime. This makes it an excellent choice for organizations looking to modernize their big data infrastructure and adopt container-based architectures.
In this article, we have covered:
- Why AWS EMR on EKS?
- Architecture of EMR on EKS
- Difference between EMR on EC2 vs EMR on EKS
- Step-by-Step Guide to Run Spark on Kubernetes with AWS EMR on EKS
… and so much more!
Frequently Asked Questions (FAQs)
What is EMR on EKS?
AWS EMR on EKS is a deployment option for AWS EMR that enables running Apache Spark applications on AWS EKS clusters instead of dedicated EC2 instances. It combines EMR's performance-optimized runtime with Kubernetes orchestration capabilities.
What are the benefits of EMR on EKS?
The benefits of EMR on EKS include shared resource utilization, managed Spark versions, and faster startup. EMR on EKS allows you to consolidate analytical Spark workloads with other Kubernetes-based applications for better resource use. You get EMR’s automatic provisioning and EMR Studio support, and you only pay for the containers you run (nodes can scale down to zero). AWS also reports big performance gains using the EMR-optimized Spark runtime.
Why run Spark on Kubernetes instead of YARN?
Running Spark on Kubernetes can be simpler if you’re already using Kubernetes for other workloads. It lets you treat Spark jobs as container apps, using Kubernetes scheduling, monitoring, and autoscaling. As AWS explains, if you already run big data on EKS, EMR on EKS automates provisioning so you can run Spark more quickly. In contrast, YARN requires dedicated clusters and is tied to the Hadoop ecosystem. Kubernetes offers a unified platform and can make multi-tenancy and version management easier.
Do I need to build my own Spark Docker image?
No. EMR on EKS uses Amazon-provided container images with optimized Spark runtime. AWS manages the container image lifecycle, including security updates and performance optimizations, eliminating the need for custom image management.
Can I run multiple Spark versions on one EKS cluster?
Yes. EMR on EKS supports running different EMR release labels across separate virtual clusters (namespaces) on the same EKS cluster. This enables testing different Spark versions or maintaining legacy applications alongside modern workloads.
Is EMR on EKS more expensive than EMR on EC2?
Cost depends on usage patterns. EMR on EKS has no additional charges beyond standard EMR and compute costs. The shared resource model often reduces costs by eliminating idle cluster capacity, making it particularly cost-effective for variable or bursty workloads.
Can I use EMR Studio with EMR on EKS?
Yes. EMR Studio fully supports EMR on EKS virtual clusters through EMR interactive endpoints. You can attach Studio workspaces to virtual clusters for interactive development, debugging, and job authoring.
What is a virtual cluster in EMR on EKS?
A virtual cluster is a logical construct that maps AWS EMR to a specific Kubernetes namespace. It doesn't create physical resources but serves as the registration point for job submission and management within that namespace.
Does EMR on EKS use HDFS?
No. EMR on EKS typically uses AWS S3 via EMRFS for data storage rather than HDFS. This approach provides better durability, scalability, and cost-effectiveness for cloud-native architectures, though custom HDFS deployments are possible if required.
Do I need to manage Spark Operator or Spark-submit jobs?
EMR on EKS offers flexibility in job submission methods. You can use the AWS CLI/SDK with emr-containers commands for simplicity, or leverage Kubernetes-native approaches like the Spark Operator for more advanced orchestration scenarios.















