




























String manipulation—it’s like having a magic wand that can turn a mess of string/text data into neat, understandable pieces, ready for analysis. Being able to wave that wand and parse, slice, truncate, or modify strings opens up a world of possibilities when it comes to handling string-based data. Snowflake comes with a bunch of cool functions to manipulate string/text—and right at the center of this toolkit is the Snowflake SUBSTRING function. This function lets you snip out bits of text from a string, starting wherever you like and grabbing as many characters as you need.
In this article, we're going to cover what the Snowflake SUBSTRING function is all about. From its syntax and parameters to real-world applications, we’ll share everything you need to know. We’ll also provide some neat tricks and best practices to help you easily slice and dice strings
What Is Snowflake SUBSTRING or Snowflake SUBSTR Function?
Snowflake SUBSTRING function–which is also referred to as Snowflake SUBSTR function—allows extracting a subset of characters from a bigger string or binary value. It takes a base string as input, along with a starting position and optional length parameter, and returns the extracted substring.
Key characteristics of the Snowflake SUBSTRING function are:
- It works on STRING, VARCHAR, and BINARY data types in Snowflake.
- It is similar to the functions left and right.
- The starting index is 1-based, not 0-based
- It accepts a negative value for the starting position to count backward from the end of the string.
- The length parameter is optional (If not specified, it returns the rest of the string from the start position).
- It properly handles multibyte UTF-8 characters for VARCHAR inputs without splitting characters.
- It returns NULL if any input parameter is NULL.
- The Snowflake SUBSTR () and Snowflake SUBSTRING () functions are synonymous and completely interchangeable.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Syntax and Parameters of Snowflake SUBSTRING Function
Snowflake SUBSTRING function is a powerful tool for string manipulation. It follows a simple syntax but unlocks a wide range of possibilities when it comes to manipulating and dissecting strings or binary data.
Here’s how the syntax looks:
SUBSTR(input_string, start_position, length)
SUBSTRING(input_string, start_position, length)Or
SUBSTR( <base_expr>, <start_expr> [ , <length_expr> ] )
SUBSTRING( <base_expr>, <start_expr> [ , <length_expr> ] )Now, let’s break down the parameters:
- input_string (<base_expr>): This is the string from which you want to extract a substring. It could be a column name if you're working with a database table, or a string literal. Note that base_expr can either be of data type VARCHAR or BINARY.
- start_position (<start_expr>): It specifies the position in the string where you want to start extracting the substring. The starting index begins at 1, not 0, which means start_expr of 1 refers to the first character in the string. It’s crucial to remember this 1-based indexing, especially if you're transitioning from a programming language or db system that uses 0-based indexing.
- length (<length_expr>): It specifies the number of characters you want to extract from the start_expr. If the length parameter is omitted, or if it specifies more characters than are available starting from the start_expr, the function will return all characters from the start_expr to the end of the string.
Variations of Snowflake Substring function
Besides the standard Snowflake SUBSTRING function, there are other variations that offer different ways of extracting or working with strings. One of its cool cousins is REGEXP_SUBSTR, which steps in when you have some pattern matching to do. Let’s break it down:
How to use REGEXP_SUBSTR function?
REGEXP_SUBSTR can help you do more than just find a simple string. It can find specific patterns, which is super useful when you have a known text structure. For example, if you're looking for email domains in a text or string, REGEXP_SUBSTR can find them, even if you don't know where they start or end. It's a nifty function for when you need a bit more than what Snowflake's SUBSTRING function offers!!
Syntax:
REGEXP_SUBSTR( <subject> , <pattern> [ , <position> [ , <occurrence> [ , <regex_parameters> [ , <group_num> ] ] ] ] )What it does:
This function is utilized when you need to find a substring that matches a particular regular expression pattern.
Parameters:
- <subject>: The text/string you want to search in.
- <pattern>: The pattern you're looking for.
- <position> (optional): Where to start searching in the text.
- <occurrence> (optional): Which occurrence of the pattern you're interested in.
- <regex_parameters> (optional): Extra settings like case sensitivity.
- <group_num> (optional): If your pattern has groups, this picks which group to grab.
Example:
SELECT REGEXP_SUBSTR('[email protected]', '@([a-zA-Z0-9.-]+)') as domain;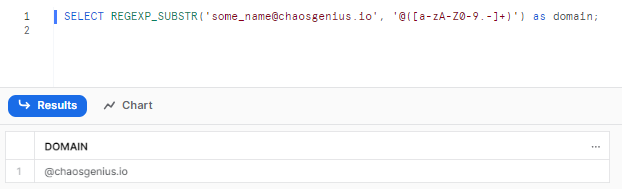
As you can see, REGEXP_SUBSTR function looks for the domain part of the email address by searching for the pattern after the "@" symbol.
Check out this documentation to learn more about Snowflake REGEXP_SUBSTR function
How to Use Snowflake SUBSTRING or Snowflake SUBSTR Function?
Now, let's look at some basic examples of using Snowflake SUBSTRING. This will help cement our understanding of how this function works to extract a portion of the base string.
Snowflake SUBSTRING() function extracts a portion of a string or binary value passed to it. It allows specifying a starting position and length to determine the substring that gets returned.
Internally, the function takes the following steps:
- Snowflake SUBSTRING checks if the base_expr input is a valid string or binary data type. Anything else will result in an error.
- It then evaluates the start_expr to determine the starting index for the substring extraction.
- If provided, the length_expr is evaluated to determine how many characters/bytes need to be extracted after the start position.
- Snowflake SUBSTRING function then extracts the substring from base_expr beginning at the calculated start_expr position. It will extract up to the end of the string or the length_expr portion if specified.
- This extracted substring is returned by the function. Its data type will match the input base_expr.
- If any of the input expressions (base_expr, start_expr, length_expr) resolve to NULL, then NULL is returned instead of a substring.
TLDR; Snowflake SUBSTRING analyzes the input parameters, calculates the appropriate start position and length, extracts that portion from the base string, and returns the substring value. The starting index and length allow extracting very specific sections of the input string in Snowflake SQL.
let's see some examples of using Snowflake SUBSTRING:
1) Snowflake SUBSTRING on String Literals
SELECT SUBSTRING('Chaos Genius', 1, 5); 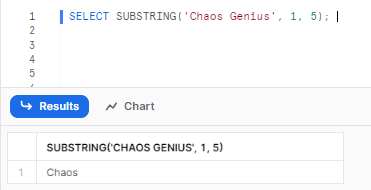
As you can see, this extracts the substring from “Chaos Genius” starting at position 1 (the first character) and extracting 5 characters. So it returns ”Chaos” as the substring.
SELECT SUBSTRING('Chaos Genius', 6, 7); 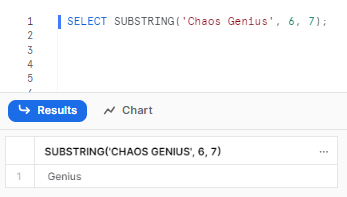
Clearly, here we start at position 6, which is the first character of “Genius”. We extract 7 characters after that, which returns “Genius” as the substring.
SELECT SUBSTRING('Chaos-Genius', 6); 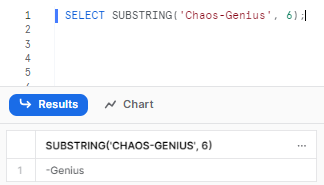
As you can see, here we start extracting from position 6, which is the “-” character. We haven't specified no length is specified, so it returns everything after “-” which is "Genius".
SELECT SUBSTRING('Chaos', -5, 5);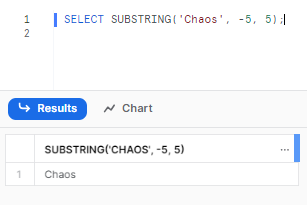
2) Using Snowflake SUBSTRING to Extract Domain Names From Email Addresses
Let’s first start by creating a table named user_emails and then let's insert some dummy data into it:
CREATE OR REPLACE TABLE user_emails (
id INTEGER,
email VARCHAR(255)
);
INSERT INTO user_emails (id, email) VALUES
(1, '[email protected]'),
(2, '[email protected]'),
(3, '[email protected]'),
(4, '[email protected]'),
(5, '[email protected]'),
(6, '[email protected]'),
(7, '[email protected]'),
(8, '[email protected]');Now that we have created the table and inserted some sample email addresses, we can use the SUBSTRING function to extract just the domain name portion from each email address string.
SELECT id, email, SUBSTRING(email, POSITION('@' IN email) + 1) AS domain_name
FROM user_emails;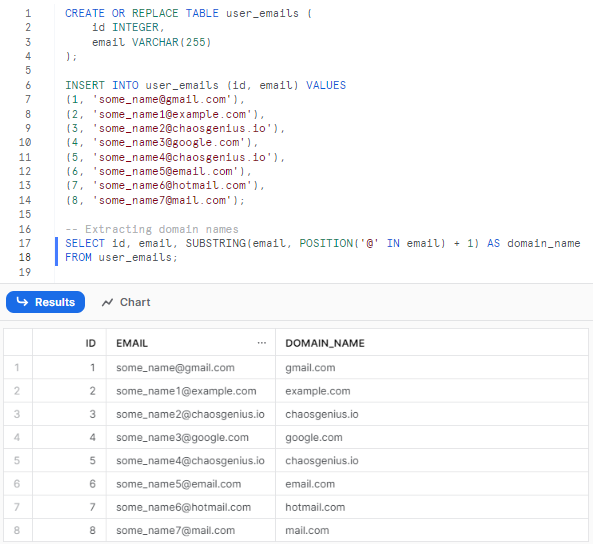
The POSITION function helps us find the index of the @ symbol, which marks the start of the domain name in the email. We then use SUBSTRING to return everything after the @ index to extract the domain.
As you can see, by using Snowflake SUBSTRING and POSITION together, we can easily extract the domain name portions from a list of email addresses in Snowflake. This helps cleanly separate the name and domain segments.
3) Using Snowflake SUBSTRING to Extract Year From Date Strings
Let's create a sample table containing date values stored as strings in YYYY-MM-DD format:
CREATE OR REPLACE TABLE sales_data (
id INTEGER,
sale_date VARCHAR(10) -- Dates stored as 'YYYY-MM-DD'
);
INSERT INTO sales_data (id, sale_date) VALUES
(1, '2022-01-15'),
(2, '2023-05-21'),
(3, '2019-08-30'),
(4, '2023-03-12'),
(5, '2022-11-05'),
(6, '2020-06-17'),
(7, '2019-12-24'),
(8, '2018-07-09'),
(9, '2020-02-29'),
(10, '2015-10-31');Now, that we have successfully created a table and inserted dummy data lets use Snowflake SUBSTRING function to extract just the 4 digit year portion from these string dates. To do so:
-- Extracting year
SELECT id, sale_date, SUBSTRING(sale_date, 1, 4) AS year
FROM sales_data;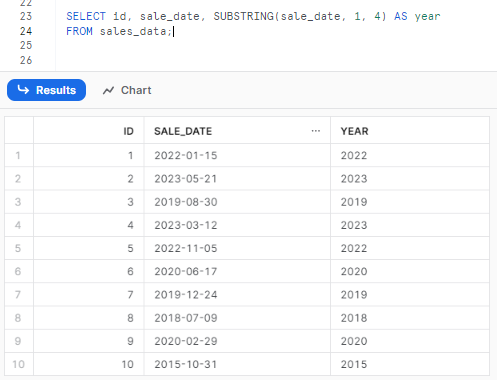
Clearly, you can see that, the Snowflake SUBSTRING function is used to return the first 4 characters from each sale_date, which corresponds to the year portion.
4) Using Snowflake SUBSTRING to Extract First and Last Names From Full Company Name
Let's create a sample table with some company full names:
CREATE OR REPLACE TABLE company_name (
id INTEGER,
full_name VARCHAR(255)
);
INSERT INTO company_name (id, full_name) VALUES
(1, 'Company Name'),
(2, 'Chaos Genius'),
(3, 'Amazon Web'),
(4, 'Google LLC'),
(5, 'Facebook Inc'),
(6, 'Tesla Motors'),
(7, 'Netflix Inc'),
(8, 'Samsung Electronics'),
(9, 'Intel Corp'),
(10, 'Cisco Sys');Now, that we have successfully created a table and inserted dummy data lets use Snowflake SUBSTRING function to extract the First and Last Names from Full Company Name
-- Extracting first and last copany names
SELECT id,
full_name,
SUBSTRING(full_name, 1, POSITION(' ' IN full_name) - 1) AS first_name,
SUBSTRING(full_name, POSITION(' ' IN full_name) + 1) AS last_name
FROM company_name;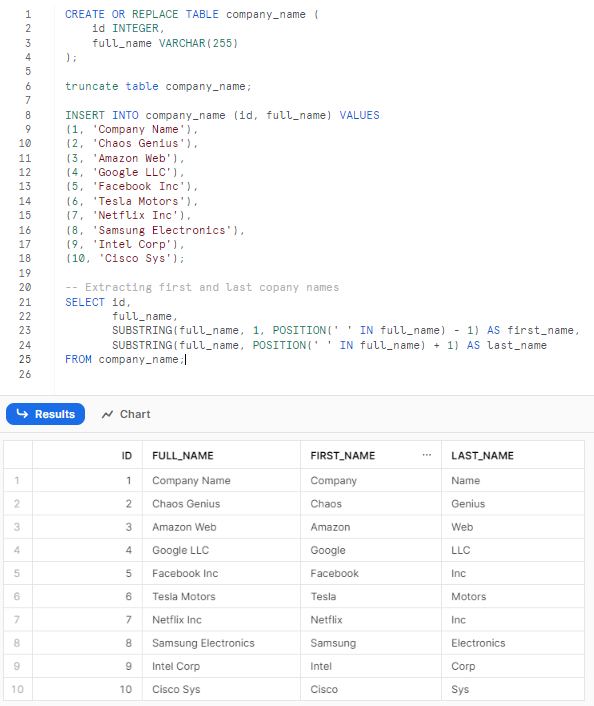
As you can see, First, we find the position of the space character using POSITION(' ' IN full_name). For the first name, we extract from the start until one less than this space position. For the last name, we extract from one after the space position to the end. So by combining Snowflake SUBSTRING and POSITION, we can easily split names that are stored together in a single column.
Tips for Utilizing Snowflake SUBSTRING
Here are some tips and best practices for utilizing the Snowflake SUBSTRING function effectively
1) Use Snowflake SUBSTRING for Fixed Width Extractions
Snowflake SUBSTRING function works very well when you need to extract a substring of fixed width from a base string. For example:
- Extracting a 4-character year from a date string
- Extracting a 2-character state code from addresses
- Extracting the first 3 letters as an abbreviation
Specifying a fixed length_expr allows cleanly extracting consistent width substrings regardless of full string length.
2) Combining Snowflake SUBSTRING with Other String Functions
Snowflake SUBSTRING can be combined with other string functions which allows for flexible data cleansing and standardization in one single query.
3) Use Snowflake SUBSTRING to Clean Column Values
Snowflake SUBSTRING is useful for cleaning data by removing unwanted prefixes, suffixes, and patterns from string columns. For example,
SELECT
SUBSTRING(col, 1, POSITION('_' IN col)-1)
FROM table;You can see that, this can extract a clean value by stripping unwanted underscores.
4) Handle NULL Values
Make use of COALESCE or CASE statements to handle NULL inputs to avoid errors:
SELECT
COALESCE(SUBSTRING(col, 1, 5), 'N/A')
FROM table;5) Mind the Indexes (Starts at 1—not 0)
Remember that Snowflake SUBSTRING follows a 1-based indexing approach rather than 0-based, meaning the first character in the base string has an index of 1 rather than 0 which differs from languages like Python and R, so be careful when using it.
6) VARCHAR Over BINARY
Prefer VARCHAR over BINARY data type for the base_expr unless you specifically need binary octet handling. VARCHAR makes substring extraction easier.
7) Mind the Collation
No linguistic processing is done by Snowflake SUBSTRING—extraction is fully based on raw byte/character indexes. Be aware when using it with potentially collated data.
8) Handles strings with multibyte characters
Snowflake SUBSTRING also supports multi-byte or UTF-8 encoded characters within VARCHAR strings. The start and length expressions properly account for variable width characters when extracting the substrings, which enables safely extracting substrings from strings with emojis, foreign languages, Unicode characters, and other complex characters.
When to Use Snowflake SUBSTRING function?
Snowflake SUBSTRING function in Snowflake is an extremely handy tool for manipulating and transforming string data. Here are some of the most popular use cases and scenarios of when to use the Snowflake SUBSTRING function:
1) During ETL when parsing and transforming string columns
SUBSTRING is extremely useful when extracting, parsing, and transforming string data during ETL processes. For example:
- Parsing concatenated columns like "City_State" into separate "City" and "State" columns using Snowflake SUBSTRING + SPLIT.
- Standardizing formatting differences by extracting relevant substrings from messy strings and concatenating with consistent separators.
- Extracting partial values like first name, last name, domain name, etc…. from larger strings during data cleaning.
So during ETL, Snowflake SUBSTRING can help parse, extract, and transform string columns into cleaned target formats.
2) When storing concatenated values (which need to be split)
If upstream systems store concatenated values in a single column like "FirstName_LastName", Snowflake SUBSTRING can help split them apart during loading into Snowflake, which avoids having to re-engineer upstream systems and can parse concatenated strings during ETL.
3) Extracting relevant substrings from long strings
For columns containing long strings, SUBSTRING is useful to extract only relevant portions. For example:
- Extracting a numeric ID embedded somewhere within a long text blob.
- Extracting the domain name from very long URLs for analysis instead of using full URLs.
So Snowflake SUBSTRING allows extracting useful substrings from wide string columns.
4) Extracting partial strings from a column
Getting the first few characters, last digits, etc. can be done easily via Snowflake SUBSTRING. For example:
- Extract the first 3 letters as an abbreviation for names
- Extract the last 4 digits of ID numbers
- Get the file extension from a filename
So Snowflake SUBSTRING can extract fixed width partial segments.
5) Getting parts of a string in reverse order
By using a negative start position, Snowflake SUBSTRING can extract substrings starting from the end of the base string. For example: Select SUBSTRING(col, -8, 4) would extract the last 4 characters from col, which allows getting parts of a string in reverse order as needed.
Save up to 30% on your Snowflake spend in a few minutes!


Conclusion
And that’s a wrap! Snowflake SUBSTRING function is an extremely valuable tool for slicing and dicing just the right pieces of string data that you need. So, whether you're using it for parsing names, cleaning text, extracting patterns, or more—this function packs a powerful punch in a compact package.
In this article, we covered:
- What the Snowflake SUBSTRING function is, including its syntax and parameters.
- How to use it for extracting substring?
- In-depth examples of using Snowflake SUBSTRING.
- Tips and best practices for effectively using Snowflake SUBSTRING function.
- When and where to use the Snowflake SUBSTRING function?
You can think of Snowflake SUBSTRING like a pair of scissors, ideal for neatly trimming up strings exactly how you want them. Learn this function, and you'll be slicing through strings like a pro in no time!!
FAQs
What is the Snowflake SUBSTRING Function?
Snowflake SUBSTRING function is used to return a specific portion of a string or binary value. It starts extracting characters from a position specified by the user and can optionally have a defined length.
Can the Snowflake SUBSTRING Function Handle Different Data Types?
Yes, the SUBSTRING function in Snowflake can handle both VARCHAR and BINARY data types. The function returns the data type similar to that of the input base_expr.
What Happens if the Start Position or Length is Negative in Snowflake SUBSTRING?
If a negative value is used for the start position in SUBSTRING, the function counts backward from the end of the string. A negative length will cause the function to return an empty string.
Does the Snowflake SUBSTRING Function in Snowflake Return NULL for Any Input Conditions?
Yes, if any of the inputs to the Snowflake SUBSTRING function are NULL, the function itself returns NULL.
Is There a Difference Between Snowflake SUBSTRING and Snowflake SUBSTR?
No, Snowflake SUBSTRING and Snowflake SUBSTR functions are synonymous and can be used interchangeably.
Can Snowflake SUBSTRING Function Be Nested Within Other Functions in Snowflake?
Yes, the Snowflake SUBSTRING function can be nested within other functions in Snowflake. The output of the SUBSTRING function can be passed as an input to another function, enabling complex string manipulations and analyses.
How do you escape a character for a single quote in Snowflake?
Use double backslashes \\ to escape special characters in single-quoted strings. For example, \\d represents \d.
How to Remove the Last Character of a String in Snowflake?
To remove the last character from a string, you can use the LEFT function combined with the LENGTH function. LEFT function extracts a specified number of characters from the beginning of a string, and LENGTH returns the length of the string. So, LEFT(string, LENGTH(string) - 1) effectively removes the last character from the string.
How do you find the position of a character in Snowflake?
To find the position of a character in a string in Snowflake, use the POSITION() or CHARINDEX() function. For example, the code below would return 1, indicating the position of character “C” in the word “Chaos”
Select POSITION('C' IN 'Chaos') as characater_positionIs there a way to substring from the end of a string?
Use a negative value for the start index to count backward from the end of the base string.
Are there any performance considerations for substring?
There is minimal performance overhead, but extracting substrings from very large strings could have an impact.









