





























Terabytes of data are stacking up, and your on-premises infrastructure is at capacity. Sounds familiar? Legacy systems are choking on the workload, hardware costs are blowing out of control, and scaling up may appear unfeasible. But the good news is that AWS EMR can help you resolve these challenges in less than 10 minutes. AWS EMR is a fully managed service that takes the pain out of running frameworks like Apache Hadoop, Apache Spark, Apache Hive, Trino, and more. It sets up clusters in no time, scales when you need it to, and fits right into the AWS ecosystem. You no longer need to supervise servers or blow budgets on idle machines.
In this article, we show you exactly how to create an EMR cluster from scratch using the AWS console. We break down what AWS EMR is, how it is built, and provide an exact step-by-step guide on how to launch the cluster, configure roles, choose instance types, and enable security and cost-saving features, best practices, and more. Let’s dive right into it.
What is AWS EMR (Amazon Elastic MapReduce)?
AWS EMR (Amazon Elastic MapReduce) is Amazon's fully managed big data platform that simplifies running and scaling Apache Hadoop, Apache Spark, Apache Hive, Trino and other open source big data frameworks on AWS. EMR handles the heavy lifting of cluster provisioning, configuration, tuning, monitoring, and patching, allowing organizations to focus on their data analytics and processing workflows rather than infrastructure management.

AWS EMR first hit the scene in 2009, mainly focused on Hadoop MapReduce workloads. Since then, it's grown into a full-fledged big data platform. Now, it offers performance-boosted runtimes for a range of frameworks like Apache Spark, Trino, Apache Flink, and Apache Hive. This leads to significant cost savings and better performance than using traditional on-premises infrastructure.
A key strength of AWS EMR lies in its flexible storage architecture that decouples compute and storage resources, providing multiple storage options optimized for different use cases:
- Local HDFS: runs on core nodes for intermediate data processing, with the primary node managing the NameNode and metadata operations.
- EMR File System (EMRFS): a Hadoop-compatible interface to S3 that provides configurable consistency models and optimizations for cloud storage access patterns.
- EC2 Instance Store: provides high-performance local storage for temporary data during shuffle operations and spill-to-disk scenarios.
- Optionally, Amazon EBS volumes for high-throughput or low-latency storage requirements.
AWS offers four distinct deployment modes, each addressing different use cases:
➥ EMR on EC2
Traditional cluster deployment where you select EC2 instance types or instance fleets. YARN (Yet Another Resource Negotiator) schedules containers across nodes, providing full control over cluster configuration and resource management.
➥ EMR on AWS EKS
AWS EMR on EKS provides a deployment option for Amazon EMR that allows you to run open source big data frameworks on Amazon Elastic Kubernetes Service (Amazon EKS).
➥ EMR Serverless
AWS EMR Serverless is a serverless option in EMR that makes it easy for data analysts and engineers to run applications using big data analytics frameworks without configuring, managing, and scaling clusters or servers. AWS automatically scales capacity per second based on workload demands.
➥ EMR on Outposts
Extends EMR capabilities to on-premises environments through AWS Outposts, enabling local data processing while maintaining cloud API compatibility and management consistency.
AWS EMR's main goal is to make it easy to run big data applications without the hassle of managing the underlying infrastructure itself.
Key Features and Capabilities of AWS EMR
AWS EMR comes with a suite of features designed to make big data processing more manageable.
Feature 1: Scalability and Elastic Resource Management
A core strength of EMR is its dynamic scalability. You can resize your clusters based on workload demands. EMR Auto Scaling or the more recent EMR Managed Scaling can automatically add or remove instances (the virtual servers your cluster runs on).
Feature 2: Cost-Effectiveness and Pricing Models
EMR uses several cost optimization strategies:
- Pay-per-use pricing model with no upfront commitments
- Support for AWS EC2 AWS Spot Instances (spare EC2 capacity given at large discounts)
- AWS Graviton processor support for improved price-performance ratios
- Automatic resource scaling to match workload demands
Feature 3: Supported Big Data Frameworks (Hadoop, Spark, Hive, Presto, ...)
AWS EMR natively supports a comprehensive range of open source frameworks, including:
And others…
Feature 4: Data Storage Integration with S3 and HDFS
AWS EMR integrates seamlessly with AWS S3. The EMR File System (EMRFS) enables EMR clusters to use AWS S3 as a persistent object store for input and output data. You can terminate your EMR cluster (and stop paying for it) while your data remains safe in S3. EMR clusters can also utilize the Hadoop Distributed File System (HDFS), which runs on the cluster's core nodes, primarily for ephemeral or intermediate data.
Feature 5: AWS Service Ecosystem Integration
AWS EMR integrates with various AWS services:
- AWS S3
- AWS CloudWatch Monitoring
- Amazon DynamoDB
- AWS IAM (Identity and Access Management)
- AWS VPC (AWS Virtual Private Cloud)
- AWS Lake Formation
- AWS Glue Data Catalog
And others…
Feature 6: High Availability and Fault Tolerance
EMR supports multi-master configurations for applications with master components (Spark, Hive, Presto). If one master fails, another takes over automatically, keeping everything running. The platform also replicates data and has built-in recovery mechanisms to handle failures.
Feature 7: Security Features (Encryption, IAM, Kerberos)
AWS prioritizes security, and EMR offers several layers of protection:
- IAM roles for access control
- EC2 Security Groups for network isolation
- Encryption (At Rest and In Transit)
- Kerberos for authentication
- Table-level and fine-grained access control for open-table formats
Feature 8: Interactive Development Environments (EMR Studio, Notebooks)
AWS EMR provides various interactive development environments, such as:
- EMR Studio
- EMR Notebooks
- SSH Access
Feature 9: EMR Deployment Options (EC2, EKS, Serverless, Outposts)
EMR offers flexibility in deployment across various environments:
- Traditional EMR on EC2 Clusters
- EMR on AWS EKS (Elastic Kubernetes Service)
- EMR Serverless
- EMR on Outposts
AWS EMR Use Cases and Applications
AWS EMR handles big data processing across several key areas. Here's where it makes the biggest impact:
Use Case 1: ETL (Extract, Transform, Load) Data Processing
AWS EMR excels at batch processing and data transformations (ETL). It can pull data from various sources (databases, logs), transform it using frameworks like Spark or Hadoop, and then load it into destinations such as AWS S3, Amazon Redshift, or other AWS services. The pay-as-you-go model makes it particularly cost-effective for irregular, high-volume ETL operations.
Use Case 2: Machine Learning and Model Training Workflows
AWS EMR provides a scalable platform for machine learning workflows, including data preprocessing, feature engineering, model training, and batch inference. Data scientists leverage it for exploratory analysis, feature engineering, and training complex models with libraries like Spark MLlib, TensorFlow, and more, unconstrained by infrastructure limitations.
Use Case 3: Real-Time Stream Processing with Kafka and Flink
EMR works with Apache Kafka and Apache Flink to process streaming data for real-time analytics, event detection, and streaming ETL. It creates long-running, fault-tolerant streaming data pipelines that analyze events as they happen – particularly useful in finance for trading decisions or IoT applications.
Use Case 4: Interactive Data Analytics and Business Intelligence
AWS EMR Notebooks provide Jupyter-based environments for ad-hoc data exploration. Analysts can interactively query large datasets, create visualizations, and iterate on analytical findings without waiting for traditional batch processing cycles.
Use Case 5: Log Analysis and Clickstream Processing
AWS EMR processes raw log files, structures them for storage in data warehouses like Amazon Redshift, and extracts insights from historical data. It's commonly used for clickstream analysis, enabling tracking of user behavior, optimization of website performance, and personalization of experiences.
When Should You Choose AWS EMR?
EMR really shows its worth when dealing with huge amounts of data that traditional systems can't handle. Consider EMR for:
- Datasets exceeding multiple terabytes
- Complex analytics requiring distributed computing
- Variable workloads that benefit from elastic scaling
- Applications requiring integration with the broader AWS ecosystem
- Organizations seeking to avoid infrastructure management overhead
EMR works especially well for certain workloads that can leverage distributed processing patterns and benefit from the scalability, cost-effectiveness, and managed nature of cloud-based analytics platforms.
AWS EMR Architecture: Components and Infrastructure
The AWS EMR service architecture consists of several interconnected layers that work together to provide a comprehensive big data processing platform. These layers include cluster composition, storage management, resource management, data processing frameworks, and application interfaces.
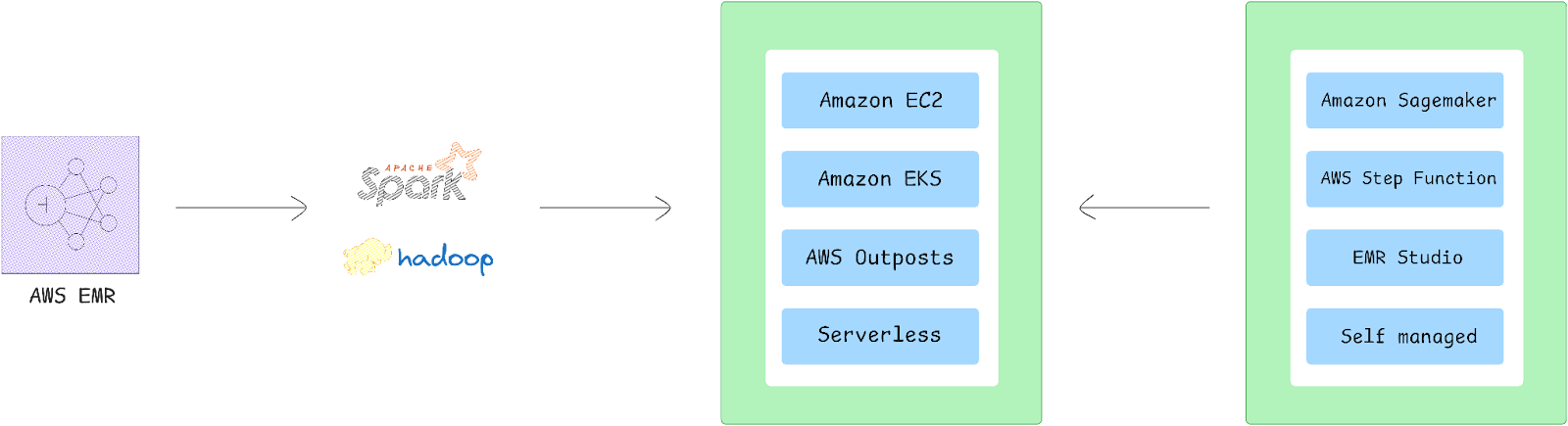
➥ AWS EMR Cluster Composition: Primary, Core, and Task Nodes
Clusters in AWS EMR are groups of Amazon EC2 (Elastic Compute Cloud) instances referred to as “nodes”. These nodes are organized into specific roles to facilitate distributed data processing:
Primary node: Manages job scheduling, task coordination, and cluster health. Every EMR cluster has exactly one primary node, even in single-node setups.
Core nodes: These are the workhorses. They actually run your tasks and also store data using the Hadoop Distributed File System (HDFS). If you're building a multi-node cluster, you'll definitely have core nodes because they're essential for both computation and data storage right on the cluster.
Task nodes: Perform compute-only operations without storing persistent data. They are often used with AWS Spot Instances to optimize costs, as they can be terminated without risking data loss. EMR intelligently ensures that critical application processes run on the more stable core nodes.
➥ Storage Architecture: HDFS, EMRFS, and Instance Store
AWS EMR supports three storage options, balancing performance, persistence, and cost:
HDFS is built right into your core nodes, perfect for big datasets and parallel processing. HDFS spreads data across those core instances and keeps copies for fault tolerance, which is handy. It's really good for temporary, intermediate data during a job. Just remember, anything in HDFS vanishes when your cluster shuts down.
EMR File System (EMRFS) lets your cluster seamlessly hook up with AWS S3. Unlike HDFS, data in AWS S3 sticks around even after your cluster goes away, which is a big deal for persistent storage, input/output, and archiving. It really lets EMR scale with AWS S3's massive capacity.
The local file system (instance store) resides on disks attached to EC2 instances. It offers high I/O performance for temporary data but is non-persistent and best used as scratch space during computations.
➥ Cluster Resource Management with YARN and Spot Instances
The resource management layer orchestrates the allocation and utilization of cluster resources to ensure optimal performance and fault tolerance:
YARN: Acts as the central resource manager in EMR, enabling different data processing frameworks to dynamically share cluster resources. YARN separates job management from resource allocation, making things more scalable and allowing multiple users or applications to share the cluster without stepping on each other's toes. EMR even sets up YARN with “node labels” (like “CORE”), which means certain critical processes can only run on stable core nodes, helping keep your jobs steady.
AWS Spot Instances: AWS EMR often uses AWS Spot Instances to cut costs, especially for those task nodes that don't hold data. Since AWS Spot Instances can get interrupted, EMR is smart about it: it makes sure your critical application master processes always run on the more reliable core nodes.
Monitoring and Resilience: AWS EMR agents on each node monitor YARN processes and cluster health, sending metrics to CloudWatch Monitoring. If a node fails, EMR can automatically replace it, contributing to cluster stability without constant manual intervention.
➥ Data Processing Frameworks Layer (Spark, Hadoop, Hive)
AWS EMR provides a choice of engines tailored for different types of big data workloads:
➥ Application and Programming Interfaces Layer
The top layer of the EMR architecture encompasses the big data tools and applications that run on your EMR cluster, providing a flexible environment for building, testing, and deploying data processing workloads.
- Applications Supported by EMR — AWS EMR backs a bunch of popular applications, including Apache Hive, Pig, Spark Streaming, and more. Spark Streaming, for instance, handles real-time data, while Hive and Pig are great for batch processing with SQL-like interfaces.
- Programming Languages and Interfaces — Developers have plenty of options for interacting with EMR. Spark supports Java, Scala, Python, and R. MapReduce primarily uses Java. You can manage EMR applications through the EMR console, the AWS Command Line Interface (CLI), or various SDKs, making it easy to run and monitor your jobs.
How AWS EMR Clusters Operate: End-to-End Workflow
So, how does this all tie together? AWS EMR uses those EC2 instances to run open source frameworks. These frameworks split your big datasets into smaller tasks that run in parallel across the cluster, which makes processing super efficient.
A key architectural principle of AWS EMR is the separation of compute and storage. EMR integrates with AWS S3 via EMR File System (EMRFS), allowing data to be stored persistently in AWS S3 while computations are performed on the EMR cluster. Data in AWS S3 remains accessible even after an EMR cluster is terminated.
YARN manages all the resources, handling allocation and scheduling across your EC2 instances to optimize performance. Your cluster generally has that primary node for overall management, core nodes for storage and processing, and task nodes for specific jobs without data storage.
AWS EMR also offers autoscaling, letting your cluster automatically adjust its size based on your workload. This works hand-in-hand with AWS Spot Instances for cost savings on less critical jobs. You can even run multiple EMR clusters simultaneously, all accessing the same dataset in AWS S3, which is great for different teams or applications working in parallel.
Monitoring? That's handled by AWS CloudWatch Monitoring, which tracks metrics, logs, and alarms. CloudWatch Monitoring helps you keep an eye on cluster health, and EMR can automatically replace a failed node. AWS CloudTrail logs API calls, which is helpful for auditing and compliance.
You've got flexibility in how you deploy EMR, too. AWS EMR offers deployment flexibility through several options:
- Traditional EC2 Setup
- EMR on AWS EKS (Elastic Kubernetes Service)
- EMR Serverless
For developers, EMR Studio provides an integrated environment for building, running, and debugging Spark and Hadoop jobs. It supports Python, Scala, and R and plays nice with version control systems like Git, making data exploration and collaboration a lot smoother.
Once your processing jobs are done, you can just terminate your clusters to stop the compute charges; your data stays safe and sound in AWS S3. That's what makes AWS EMR such a capable and cost-effective solution for handling big data.
Check out the article below to learn more in-depth about AWS EMR architecture.

Now let's get started and set up the AWS EMR cluster in just a few minutes.
Step-by-Step Guide: Creating an AWS EMR Cluster in 10 Minutes
But hold up. Before you can create an EMR cluster, you need several AWS resources configured properly. These prerequisites are important for a smooth EMR cluster launch.
Prerequisites for Creating an EMR Cluster:
- AWS Account Setup — You need an active AWS account with sufficient permissions. Not only basic EC2 access is required, but you also need permissions for EMR, S3, IAM, and AWS VPC resources.
- AWS S3 Bucket — Create a bucket for storing cluster logs, job scripts, input data, and output results. Use the same region where you'll run your cluster
- EC2 Key Pair — Generate an EC2 key pair in your target region. You'll need this for SSH access to cluster nodes.
- IAM Roles — EMR requires specific service roles:
- EMR_DefaultRole
- EMR_EC2_DefaultRole
- EMR_AutoScaling_DefaultRole
- AWS VPC and Networking — Your cluster needs a AWS VPC with at least one subnet. Public subnets work for testing, but production clusters should use private subnets with NAT gateways for internet access.
- AWS CLI (Optional) — The AWS Command Line Interface (CLI) is useful for scripting and managing AWS services, though it’s optional.
Step 1—Log In to AWS Management Console
First, log in to the AWS Management Console. And enter your credentials.
Step 2—Create S3 Bucket for EMR Data Storage
AWS S3 is the go-to for data storage with EMR clusters. Why? Because it’s scalable and highly available. You'll want an AWS S3 bucket to stash your input data, scripts, and those important log files.
Here’s how you do it:
In the AWS Console, search for "S3" and go to the AWS S3 service.
Click "Create Bucket".
Give your bucket a unique name. Pick a region that's geographically close to where you plan to run your EMR cluster. This can help reduce latency.
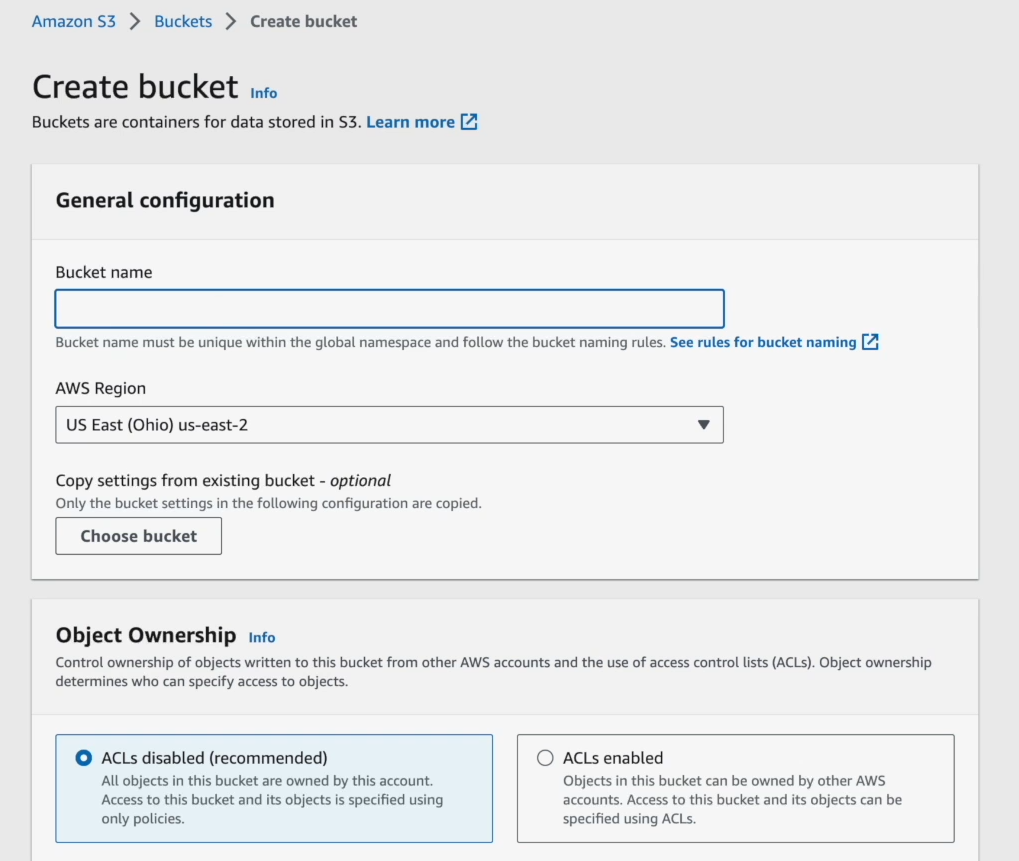
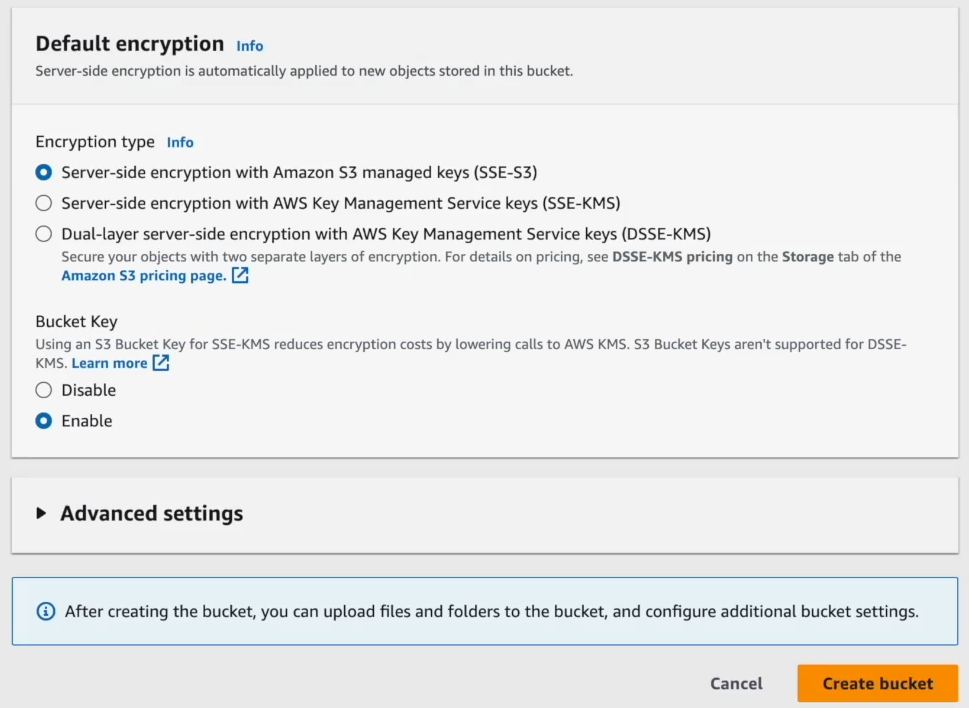
Set up Versioning and Server-Side Encryption if you need them.
It is recommended to create a few folders inside your bucket. This helps keep things tidy:
Create three different folders:
- input for your raw data.
- output for your results.
- logs for, well, logs.
Step 3—Configure VPC for Network Isolation and Security
Setting up your AWS Virtual Private Cloud (AWS VPC) isn't just a suggestion; it’s about keeping your EMR cluster isolated and secure. It is just like putting your cluster in its own private network.
Here’s how you do it:
Go to the AWS VPC Dashboard in the AWS Management Console.
Click "Create VPC". Give it a name and pick a CIDR block (like 10.0.0.0/16).

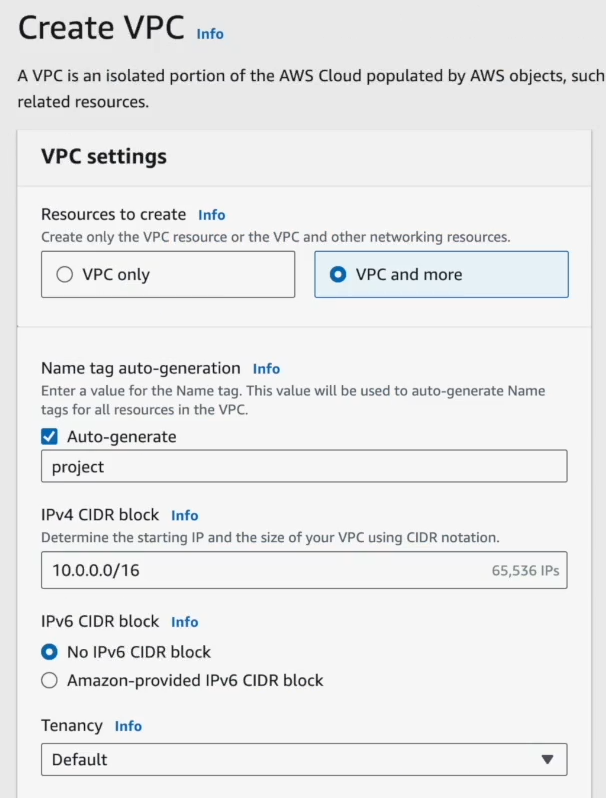
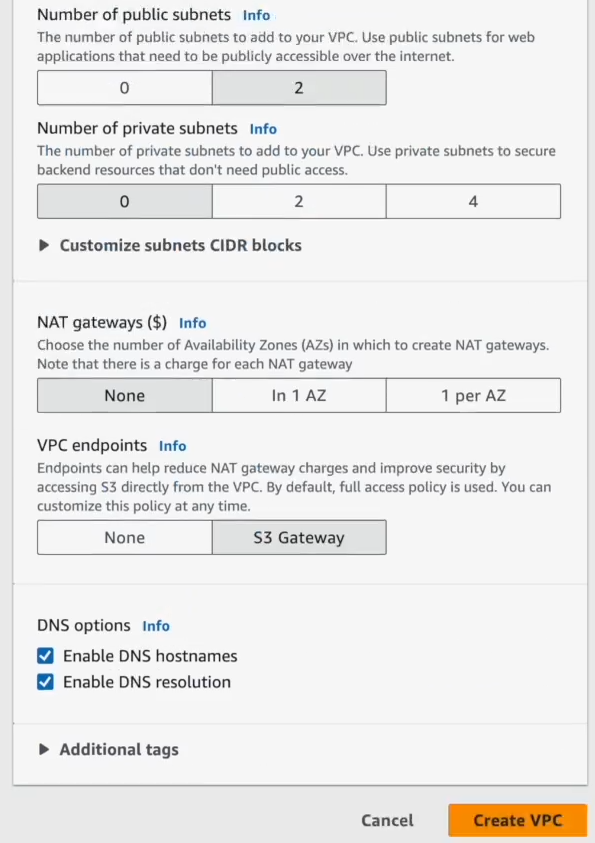
Now you'll need to set up public and private subnets. Generally, if your EMR master node needs internet access, put it in a public subnet. But remember, private subnets offer better security. It's often a trade-off.
Step 4—Launch EMR Cluster from AWS Console
Now for the main event: firing up your AWS EMR cluster. For this example, we will use the Apache Spark framework.
Navigate to the EMR Dashboard by searching for "EMR" in the AWS console.
Click "Create Cluster" to create an EMR cluster.

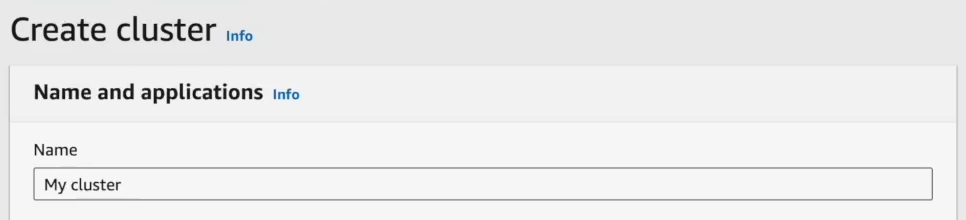
Step 5—Configure Cluster Name and Identification
First, name your cluster. Choose a name that clearly identifies this Spark cluster.
Step 6—Select EMR Release Version
Then, select the EMR release version. The EMR release version determines which open source applications and their versions are available. For a Spark-ready cluster, pick a recent EMR 6.x or 7.x series release. Newer releases often bring performance improvements and bug fixes.
For example, EMR 7.9.0 includes AWS SDK for Java 2.31.16/1.12.782, Delta 3.3.0-amzn-1, Hadoop 3.4.1, Hudi 0.15.0-amzn-6, Iceberg 1.7.1-amzn-2, Spark 3.5.5, and Zookeeper 3.9.3.
Step 7—Select Big Data Frameworks (Spark, Hadoop, Hive, ...)
Next, in the applications bundle list, select Apache Spark or your preferred framework.

Step 8—Choose EC2 Instance Types for Cluster Nodes
Then pick instance types to match your workload. This is where the compute power for the cluster is defined.
Instance Groups vs Instance Fleets
AWS EMR offers two ways to configure nodes:
a) Instance Groups
This is a more traditional approach. Each node type (Primary, Core, Task) gets its own group, and all instances within that group are the same type. Scaling is often manual or uses simple CloudWatch metrics.
b) Instance Fleets
This is generally the preferred, more flexible, and cost-effective option. With instance fleets, multiple instance types can be specified (up to 30 via CLI/API, 5 via console) for each node type (Core, Task). EMR then picks the best available instances based on the allocation strategy (like, lowest price, capacity optimized).
Instance Type and Count
The computational needs of the core and task nodes depend on the type of processing an application performs. Many jobs can run on general-purpose instance types, which offer balanced performance in terms of CPU, disk space, and input/output.
a) Master Node
The primary node typically does not have large computational requirements. For clusters with many nodes or applications specifically deployed on the primary node, a larger primary node might be required to improve cluster performance.
b) Core and Task Nodes
- General Purpose: Instances like m5.xlarge or m6g.xlarge (Graviton2) offer a good balance.
- Compute-Optimized: For CPU-intensive jobs, consider c5.xlarge or c6g.xlarge (Graviton2).
- Memory-Optimized: For memory-intensive tasks, especially with Spark, r5.xlarge or r6g.xlarge (Graviton2) are good choices.
- Storage-Optimized: For storage-heavy jobs, leverage i3 or i4 instances with NVMe-based storage.
So, whenever you are selecting an instance type, consider that the "vCPU" count displayed in the AWS Management Console represents the number of YARN vcores for that instance type, not the actual number of EC2 vCPUs. For the actual EC2 vCPU count, refer to the Amazon EC2 Instance Types documentation.
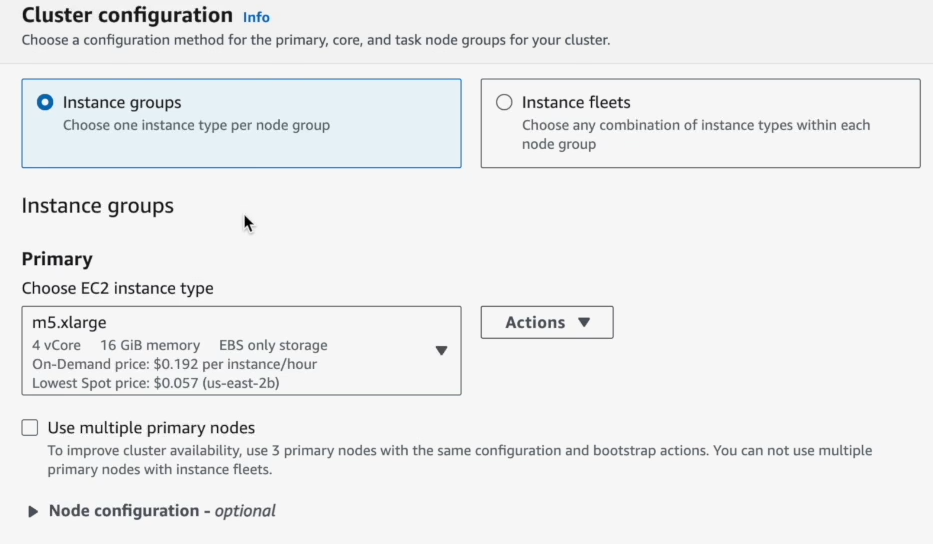
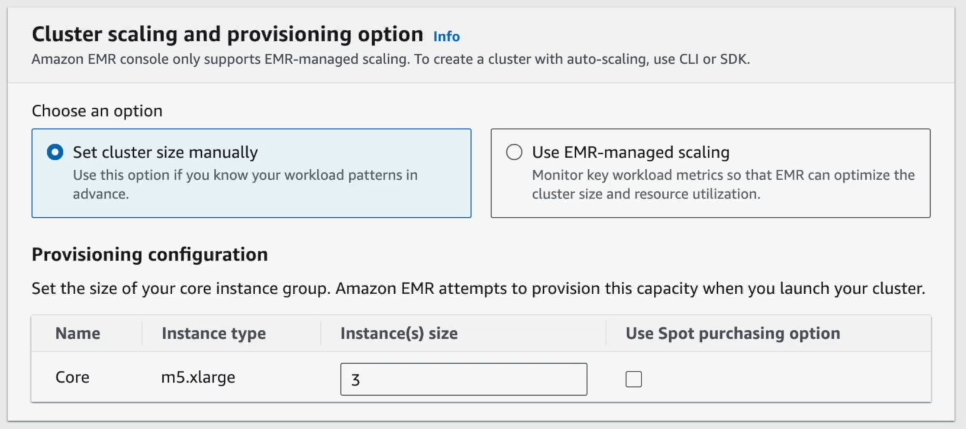
Step 9—Configure Node Count and Instance Settings
After that, configure your nodes. Specify the number of core and task nodes. Replace the default instance type with one suited to your Spark workload.
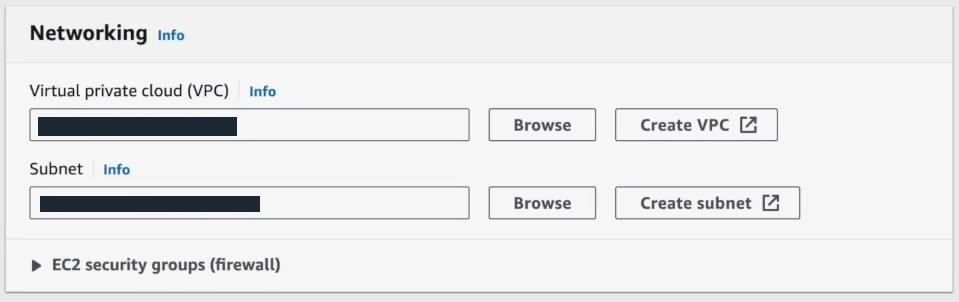
Step 10—Configure Network and Security Settings
Now, set upthe network and security. Select the AWS VPC and subnet you created in step 3.
Step 11—Add EC2 Key Pair for SSH Access
Add an EC2 key pair for SSH access. You'll thank yourself later if you need to troubleshoot directly.
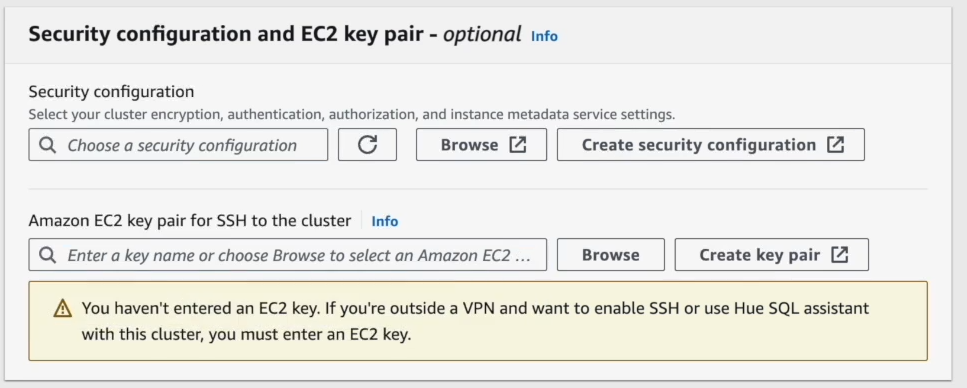
Assign proper service roles. Either choose one if you already have it or create a new one. These manage permissions for EC2 and EMR.

Step 12—Create and Assign EC2 Instance Profile
Choose “Create an instance profile”, then grant read and write access to all AWS S3 buckets in your account so the cluster can interact with your data.
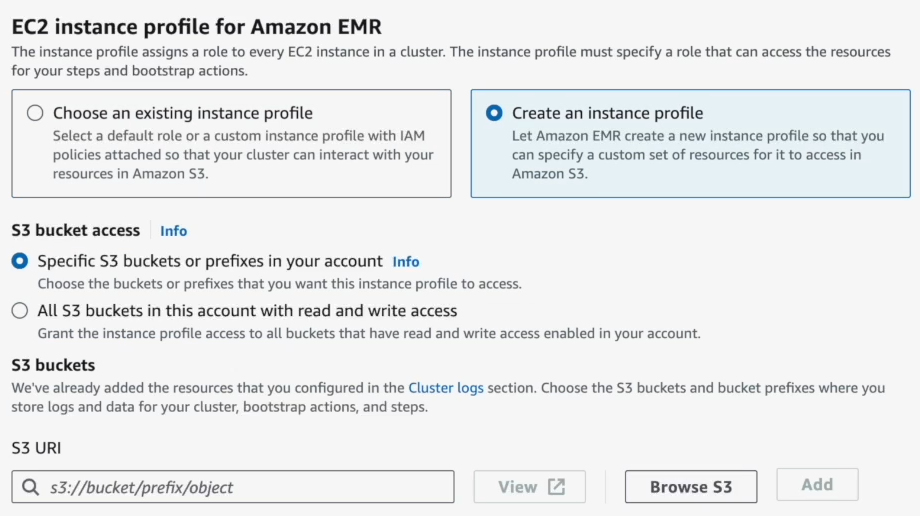
Step 13—Enable Cluster Logging to S3
Finally, enable logging and point it to the logs folder in your AWS S3 bucket from step 2. This lets you track cluster activity and debug issues.
Step 14—Review Configuration and Create EMR Cluster
Review all settings, then click “Create Cluster”.

Cluster creation takes a few minutes.
Step 15—Upload Input Data and Spark Scripts to S3
Next, create a Spark script locally using Python and save it as main.py. Put your raw data in s3://your-bucket/input/. Write a Spark script (Python or Scala).
Now, upload this script to the root folder in your AWS S3 bucket.
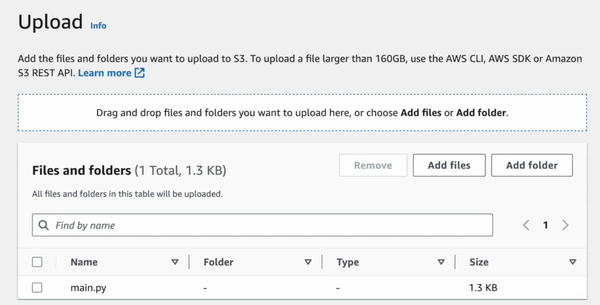
Step 16—Add Spark Application Steps to EMR Cluster
Go back to your EMR cluster in the AWS console. Click on Steps, then click Add Step.
Configure it like this:
- Step Type: Pick "Spark Application"
- Script Location: Give it the S3 path to your main.py script (s3://your-bucket/main.py).
- Arguments: If your Spark job needs extra parameters, put them here.
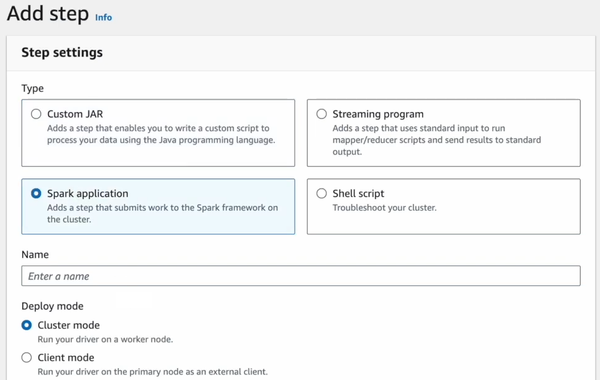

Finally, click "Add" to queue up the Spark job. It’s now waiting for its turn.
Step 17—Monitor Spark Job Execution and Status
You'll want to keep an eye on your Spark job. The EMR console's "Steps" tab shows you the real-time status: pending, running, or finished. If something goes wrong, or even if it goes right, check the logs. They're in your AWS S3 logs folder, or you can view them directly in the EMR console.
Optional—SSH Access to Primary Node for Debugging
Sometimes you need to get your hands dirty on the cluster itself. To SSH into your primary node. Go to the EC2 Dashboard. Find your primary node instance and jot down its public DNS or IP address. Crucially, make sure your EC2 security group lets in SSH traffic from your IP address. If it doesn't, you're locked out. Then, use SSH to connect:
ssh -i /path/to/your-key.pem hadoop@<Primary-Node-Public-DNS>Once you’re in, you can run commands or scripts directly on the cluster. It's a lifesaver for debugging.
Step 18—Terminate Cluster and Clean Up Resources
This step is arguably the most important for your wallet. Once your Spark jobs are done, shut down that EMR cluster. Seriously. Go to your EMR Dashboard, pick your cluster, and hit "Terminate". This stops the meter.
Also, take a look at your AWS S3 resources. If you're not using that input data or those log files anymore, get rid of them. Why pay for storage you don't need?
That’s it! If you follow these steps carefully, you’ll have a fully functioning Apache Spark on EMR setup. It takes a little setup, but once it’s running, it’s a powerful platform for all your big data needs.
AWS EMR Cost Optimization and Security Best Practices
Getting an EMR cluster running is one thing; making it perform efficiently and cost-effectively is another. Here are some cost optimization strategies and security best practices to consider for setting up functional and effective AWS EMR clusters:
Cost Optimization Strategies for EMR Clusters
Optimization 1: Enable EMR Managed Scaling for Dynamic Resource Allocation
Enable EMR managed scaling for dynamic workload adjustment. On EMR 5.30+ you can turn on managed scaling in the cluster settings, specifying minimum and maximum core/task counts. EMR will then monitor metrics (YARN pending memory, etc.) and add or remove instances to meet demand (This way you never pay for unused idle nodes). You can also define manual autoscaling policies (based on CloudWatch Monitoring) on instance groups, but EMR’s managed scaling usually covers most cases and is easier to use.
Optimization 2: Use S3 for Cost-Effective Persistent Storage
Store your big data on AWS S3 instead of HDFS. AWS S3 is far cheaper than EBS storage with HDFS replication. EMRFS makes S3 act like HDFS for Spark. This lets you scale storage independently of compute, and avoid paying for idle EBS.
Optimization 3: Select Appropriate EC2 Instance Types for Workloads
Pick the EC2 family that fits your workload. For most Spark jobs, general-purpose types (M5, M6g) give a good balance. If your workload is CPU-bound (e.g. large shuffles, data conversions), consider Compute-optimized (C5/C6). If it’s memory-heavy (large joins, caches), try Memory-optimized (R5/R6). Note that master nodes rarely need much compute for clusters under ~50 nodes; an m5.xlarge is often enough. For very large clusters or if you run services on the master (Hive server, etc.), scale it up (8xlarge or more).
Optimization 4: Leverage Spot Instances for Task Nodes (70-90% Cost Savings)
AWS Spot Instances offer unused EC2 capacity at steep discounts (often 70–90% off on-demand prices). EMR works well with AWS Spot for fault-tolerant workloads. A common pattern is to use On-Demand or Reserved instances for the master and core nodes (which run HDFS and critical services), and use AWS Spot for task nodes or even some extra core capacity. EMR’s Yarn scheduling ensures the Spark driver stays on core nodes, so losing Spot task nodes won’t kill your job. If Spot instances terminate, EMR will retry tasks on remaining nodes. In practice, mix 60–80% Spot for non-critical nodes. Remember to diversify Spot types/zones to reduce interruptions.
Optimization 5: Use ARM-Based Graviton2 Instances for 20% Cost Reduction
Newer ARM-based instances (m6g, r6g) often have up to ~20–30% lower cost for equivalent performance. Amazon found EMR Spark on Graviton2 (EMR 6.x +) can cut costs by ~20% with similar or slightly better speed. If your Spark applications use Java 11+ and libraries are compatible, test a Graviton instance type to save money.
Optimization 6: Configure Auto-Termination for Idle Clusters
To avoid charges for idle time, shut down the cluster when not in use. If you only need it for a job or set of steps, configure the cluster to auto-terminate on completion. EMR can auto-terminate when no steps remain, so you aren’t billed while waiting. Note that terminating the cluster stops EC2 billing; data in AWS S3 persists.
Optimization 7: Right-Size Instances and Optimize Resource Utilization
Don’t over-provision. Right-size instance counts and disk sizes. Use smaller instances in a larger number rather than a few very big ones, if that’s more cost-effective. Use instance store volumes (NVMe SSD) on types like I3 or D3 if your job is I/O-bound; these have high throughput and can lower I/O costs. Tune Spark executor memory/cores so you fully utilize each node.
Optimization 8: Optimize Data Layout with Parquet and Compression
Store data in compressed, columnar formats (Parquet/ORC) and partition it by a key field. Compressed Parquet on AWS S3 can be 3–5× smaller than text CSV, reducing both AWS S3 costs and I/O.
Security Best Practices for Production EMR Clusters
Best Practice 1: Implement Least-Privilege IAM Roles and Policies
- Use least-privilege IAM.
- Replace default EMR roles (EMR_DefaultRole, EMR_EC2_DefaultRole) in production with custom roles scoped to only the resources you need.
- Use separate IAM users/groups for people who operate the cluster.
- Manage user access via IAM Identity Center (SSO) when available.
Best Practice 2: Secure EC2 Key Pair and Restrict SSH Access
The EC2 key pair you selected enables SSH to the master. If you choose a key, you must safeguard its private key. For security, disable password logins on the cluster and only allow SSH from your IP. After launch, edit the master node’s security group: remove any rule that allowed SSH from 0.0.0.0/0, and add a rule to allow port 22 only from your specific IP address (or your corporate VPN IP). If you apply this, only trusted sources can reach your cluster via SSH.
Best Practice 3: Configure Security Groups for Network-Level Protection
EMR uses security groups as virtual firewalls. Make sure the master security group allows only the minimum inbound traffic needed (SSH from your IP, and any service ports if you use web interfaces). If you have a private subnet, avoid giving the master a public IP. Use a NAT gateway or VPN/bastion for access. Enable the EMR Block Public Access feature to prevent accidentally launching a cluster open to the Internet.
Best Practice 4: Enable Encryption at Rest for HDFS and S3 Data
Protect your data with encryption. AWS EMR supports encryption at rest and in transit via security configurations. Enable at-rest encryption to have EMR encrypt HDFS (local disks), Write-Ahead Logs, and EMRFS (AWS S3) data.
Best Practice 5: Enable Encryption in Transit for Data Movement
Use AWS S3 encryption (SSE-KMS or SSE-S3) for buckets holding sensitive data. All EMR logs and outputs should be in encrypted buckets. If your EMR release supports it, turn on LUKS local-disk encryption so that HDFS/EBS data is encrypted on the instances as well.
Best Practice 6: Deploy EMR in Private Subnets with VPC Isolation
If you need even strict isolation, consider placing EMR in private subnets with no Internet gateway. Put any Hive metastores in private networking too. Use AWS VPC flow logs and CloudWatch Monitoring to audit network traffic.
Conclusion
And that’s a wrap! Creating an EMR cluster in AWS can indeed be a quick process, especially for basic provisioning. But creating one that's properly configured, secure, and cost-effective takes a bit more thought. However, building a robust, cost-effective, and secure AWS EMR environment for production workloads requires careful consideration of instance types, networking, security configurations, and optimization strategies.
Start small, monitor everything, and scale based on actual usage patterns. Don't over-engineer your first cluster; you can always iterate and improve.
EMR simplifies big data processing by managing the underlying infrastructure, allowing teams to focus on data analytics rather than operational overhead. Its elasticity, cost-effectiveness through AWS Spot and Graviton instances, and deep integration with the AWS ecosystem make it a powerful platform.
In this article, we have covered:
- What is AWS EMR?
- What Is AWS EMR Used For?
- AWS EMR Architecture 101
- Step-by-Step Guide to Set up and Create an EMR cluster
- Optimization Strategies and Best Practices for AWS EMR clusters
… and so much more!
Frequently Asked Questions (FAQs)
What is an Amazon EMR cluster?
An Amazon EMR cluster is a collection of Amazon EC2 instances (nodes) that work together to process large amounts of data using open-source big data frameworks like Apache Spark, Hadoop, and Hive. EMR manages the provisioning, configuration, and scaling of these clusters.
How to set up an EMR studio?
AWS EMR Studio is an integrated development environment for data scientists and engineers. To set it up, go to the EMR console, select “EMR Studio” from the left navigation, and choose “Create a Studio”. Users then configure the Studio name, AWS S3 location for workspaces, authentication mode (IAM or IAM Identity Center), AWS VPC, subnets, and EC2 security groups.
Which EMR release should I pick for Spark?
For Spark workloads, it is generally recommended to pick the latest EMR 6.x or 7.x series release. Newer releases include updated Spark versions, performance improvements, and bug fixes.
Should I use Instance Groups or Instance Fleets?
Instance Groups are simpler—one instance type per node role. Instance Fleets let you mix multiple instance types for better availability and cost optimization. Start with Instance Groups until you understand your usage patterns.
What's the best way to store input and output data?
The best way to store input and output data for EMR is typically AWS S3. EMRFS allows clusters to seamlessly access data in AWS S3 as if it were a file system. This decouples storage from compute, meaning data persists even after the cluster is terminated, which is cost-effective and scalable. HDFS on core nodes is better suited for ephemeral or intermediate data during job execution.
How can I cut my EC2 costs on AWS EMR?
Several strategies help cut EC2 costs on EMR:
- Use Spot Instances for Task nodes, which can offer significant discounts.
- Enable EMR Managed Scaling to automatically adjust cluster size based on workload, preventing over-provisioning.
- Utilize AWS Graviton instances for better price-performance.
- Choose Instance Fleets to mix On-Demand and Spot instances and diversify instance types for better capacity acquisition and cost optimization.
- Make sure clusters auto-terminate when idle or after job completion.
How do I encrypt data at rest and in transit?
Data encryption in EMR is configured using Security Configurations.
- At rest encryption covers data in AWS S3 (via EMR File System (EMRFS) using SSE-S3, SSE-KMS, CSE-KMS, or CSE-Custom) and local disks (using LUKS or AWS KMS).
- In transit encryption uses open-source TLS features, configured by providing PEM certificates or a custom certificate provider.
Can I change instance types after launch?
Generally, changing the instance type of a running EC2 instance (and thus an EMR node) is not directly supported without stopping the instance. For an EMR cluster, the instance types are set at launch. While EMR allows resizing a running cluster by adding or removing nodes, changing the instance type of existing nodes in an instance group or fleet typically involves terminating and re-provisioning those nodes or launching a new cluster with the desired instance types.
What happens if a Spot node terminates during a Spark job?
If a Spot node (typically a Task node) terminates during a Spark job, Spark's internal retry mechanism will attempt to reschedule the lost tasks or executors on other available nodes in the cluster. Because Task nodes do not store persistent data, their termination does not result in data loss, though it might temporarily impact job progress as tasks are re-executed.
How do I monitor cluster performance?
Use CloudWatch Monitoring for infrastructure metrics, Spark UI for application performance, and YARN ResourceManager for resource utilization. Set up CloudWatch alerts for cluster health and job failures.
Should I run multiple applications on one cluster?
It depends. Long-running clusters can share resources between applications, but isolated clusters provide better resource guarantees and security boundaries. Consider your SLA requirements and cost constraints.















