





























Data generation worldwide is absolutely exploding. A report from Statista projects that the amount of data created, captured, copied, and consumed is set to hit 394 zettabytes by 2028. Businesses now routinely gather petabytes of logs, metrics, and events daily from users and transactions. Traditional row-oriented OLTP (Online Transaction Processing) databases like MySQL and Postgres are great for handling transactions. But they often hit a wall with heavy analytical workloads. Scanning full rows, even with indexes, slows down aggregate queries across millions or billions of records. This is exactly where columnar OLAP (Online Analytical Processing) engines comes in. They store data by column, compress it efficiently, and only read the specific fields needed for each query. The result? Analytics can be vastly faster, often 100 times quicker or more than row stores. Today, open source columnar databases lead the way in large-scale analytics. Among them, ClickHouse and Druid (Apache Druid, to be precise) are two prominent OLAP systems. Both are designed to ingest massive data streams or batches and execute complex SQL queries with impressive speed. Yet, under the hood, they take very different approaches to achieve these goals.
In this article, we will put ClickHouse vs Druid head-to-head, looking at their underlying architectures, data storage options, ingestion methods, query execution, indexing, concurrency, fault tolerance, SQL support, scalability, ecosystem integrations, and more, so you can figure out which might be the perfect fit for your specific needs.
No time to read it all? Jump straight to each section:
What is ClickHouse?
ClickHouse, short for "Clickstream Data Warehouse", is a high-performance, open source column-oriented database built specifically for Online Analytical Processing (OLAP) use cases. It was originally developed by Yandex and is now maintained by ClickHouse, Inc. and a vibrant open source community. Its primary function is to allow users to run analytical queries over vast amounts of data and get results quickly. The "column-oriented" aspect is fundamental: instead of storing all data for a single row together (like traditional databases), ClickHouse stores all values belonging to a single column together. For analytical queries that usually only need a few columns out of many, this approach cuts down the amount of data that needs to be accessed, resulting in much faster speeds.
We have covered a lot more in-depth about ClickHouse, including its key features. You can find more in-depth here:

What is Apache Druid?
Apache Druid is also an open source, distributed analytics database, but it's particularly engineered for real-time data ingestion and fast "slice-and-dice" OLAP queries on large datasets, especially event-oriented or time-series data. The terms "real-time" and "slice-and-dice" are key to understanding what Druid is all about. It's made to get data ready for querying in just seconds, and it lets users interactively explore and filter data across many dimensions with minimal lag.
Apache Druid's core design is heavily focused on three pillars:
- Enabling real-time data ingestion
- Providing low-latency query responses (often sub-second)
- Handling high levels of query concurrency
Apache Druid in 5 Minutes - ClickHouse vs Druid
Here's a highlight of some key features that define Apache Druid:
1) Columnar Storage — Just like ClickHouse, Druid stores data by column. With columnar storage, Apache Druid only has to load the specific columns required for your query, which speeds things up considerably. Plus, Apache Druid also optimizes how each column is stored based on the data type, helping with scans and aggregations.
2) Real-time and Batch Ingestion — Apache doesn't force a choice between immediate data ingestion or bulk loading later. It handles both real-time streaming (like from Kafka or Kinesis) and batch loading (from places like HDFS or S3). And get this: once data is in, it's pretty much immediately ready for querying.
3) Seriously Scalable and Distributed — Apache Druid employs a multi-process, microservice-like architecture where different types of nodes handle specific tasks like ingestion, querying, and coordination. Deployments can range from a few servers to hundreds, capable of handling high data ingestion rates (millions of records per second) and still delivering query responses in sub-second to a few seconds, even with trillions of records.
4) Massively Parallel Processing — When a query is submitted, Druid can process it across the entire cluster simultaneously, leveraging all available resources. That parallel muscle is a big reason why it's so fast.
5) Self-Healing and Self-Balancing — Adding or removing servers to scale the cluster is designed to be straightforward. Apache Druid figures out how to re-balance everything on its own in the background. It's designed for high availability and is fault-tolerant.
6) Indexes for Quick Filtering — Apache Druid automatically creates indexes to help it filter and search through data quickly. For dimension columns (those used for filtering and grouping), it builds dictionary encodings (mapping string values to integer IDs) and then creates compressed bitmap indexes (like Roaring bitmaps) for each unique value. These bitmaps are highly efficient for logical AND and OR operations on multiple filter conditions.
7) Time-Based Partitioning — Apache Druid always partitions data by time into segments. So that when you query for a specific time range, it only has to look at the relevant time chunks (segments), significantly boosting performance for time-series analyses.
8) Optional Rollup (Pre-aggregation) — During ingestion, Druid can optionally pre-aggregate data. If multiple raw events have identical dimension values within a given timestamp granularity, Druid can combine them into a single row, summing up metric values. This can substantially reduce storage size and boost query performance but involves a loss of raw event granularity.
11) Integration Friendly — Apache Druid gets along well with others, integrating with popular tools like Kafka, Hadoop, Spark, cloud storage services and more.
12) SQL Support — Yeap, you can query Apache Druid using SQL, which is pretty standard and makes it easier for folks already familiar with databases. It also has its own native query language if you need more low-level control.
… and so much more !!
Now, let's see how ClickHouse vs Druid compare against each other? Let's break down the differences.
What Is the Difference Between Druid and Clickhouse?
ClickHouse vs Druid—Feature-By-Feature Comparison
Before we get into the details, here's a quick table summarizing the main differences between ClickHouse vs Druid. Keep in mind this is simplified; the in-depth ClickHouse vs Druid deep dive is in the following section.
| ClickHouse | 🔮 | Apache Druid |
| Raw query speed across diverse OLAP queries, high data compression, resource efficiency | Strength | Sub-second query latency, true real-time ingestion, high concurrency |
| Monolithic-leaning (single server process focus), Shared-nothing, distributed MPP engine; three-layer design; supports compute-storage separation | Architecture | Distributed, multi-process (microservice-like) architecture with specialized node roles (Coordinator, Broker, Historical, Router, MiddleManager, Peon etc.). |
| Sparse primary index based on ORDER BY key (sorting key); marks every Nth row (granule). | Primary Indexing | Primarily time-based partitioning; segments are the primary unit for pruning. |
| Optional data skipping indexes (minmax, set, bloom filter) for non-primary key columns. | Secondary/Dimension Indexing | Automatic dictionary encoding and bitmap indexes (e.g: Roaring) for all string dimension columns. |
| Optimized for batch/micro-batch inserts (>1000 rows) via Kafka engine + Materialized View or async_insert; not true event-at-a-time. | Data Ingestion (Streaming) | True real-time ingestion with native Kafka/Kinesis connectors; data queryable in seconds; exactly-once semantics. |
| INSERT INTO... SELECT, file uploads (CSV, Parquet, etc.); efficient for large batches. | Data Ingestion (Batch) | Native batch (index_parallel), SQL-based (INSERT/REPLACE with EXTERN), Hadoop-based (index_hadoop). |
| Vectorized execution engine; processes data in batches/vectors using SIMD instructions. | Query Execution Engine | Scatter/gather model; Broker distributes sub-queries to Data nodes; relies heavily on indexes and segment pruning. |
| Powerful, largely ANSI-compliant SQL with extensive analytical functions and data types. | SQL Support | SQL support via Apache Calcite; good standard coverage, but function library less extensive than ClickHouse. |
| Supports various JOIN types; performance varies, denormalization often advised for large tables. | JOIN Capabilities | Limited JOIN support, especially for large distributed tables; pre-joining or lookups preferred. |
| ALTER TABLE UPDATE/DELETE are heavy, asynchronous mutations rewriting parts; Lightweight Deletes available. | Update/Delete Operations | No direct OLTP-style updates. Deletes by marking segments unused (then kill task) or re-indexing specific records. |
| Sharding and replication; nodes typically handle all roles. | Scalability (Horizontal - Compute) | Independent scaling of service types (Ingestion, Query, Historicals). |
| Manual data rebalancing for self-hosted OSS when shards change. ClickHouse Cloud offers easier scaling. | Scalability (Storage Rebalancing) | Automatic segment rebalancing by Coordinator when Historical nodes change. |
| ReplicatedMergeTree with ClickHouse Keeper/ZooKeeper for data redundancy. | Fault Tolerance / HA | Segment replication on Historicals from Deep Storage; redundant master services with ZooKeeper leader election. |
| Workload Scheduling (CREATE WORKLOAD) for granular resource control; older global limits also exist. | Concurrency | Query laning on Brokers, service tiering; inherently separate ingest/query nodes. |
| Requires ALTER TABLE for schema changes; can be heavy for existing data. | Schema Evolution | Schema stored with segments. Auto-discovery for new columns in new data; changing existing data schema requires re-indexing. |
| Heavy analytical queries, batch processing, log/metric analysis where some ingest latency is OK. | Ideal Workloads | Real-time interactive dashboards, event-driven analytics, high-concurrency monitoring, time-series data. |
| Broad ecosystem. Native connectors (Kafka engine, RabbitMQ, Kinesis engine, etc), plus 100+ community/partner integrations for data sources. BI tools: Grafana, Superset, Tableau, Metabase, etc via JDBC/ODBC. Supports Spark, Flink (via custom jobs or connectors) | Ecosystem & Integrations | Rich streaming and BI support. Native Kafka/Kinesis ingestion (no extra connectors needed). Strong support for Apache Superset (Druid was its original backend). JDBC/ODBC drivers allow other tools (Tableau, Qlik, Power BI). Has Presto/Trino connector and stream sinks for Flink/Spark. |
Now, let's dive into the details of how ClickHouse vs Druid compare feature by feature.
First, let's start with how these two are built.
1️⃣ ClickHouse vs Druid—Architectural Differences (Monolithic vs Modular)
Let's dive into the core of this article—ClickHouse vs Druid. We'll compare their architectures and highlight the key differences.
ClickHouse Architecture
ClickHouse generally follows a more traditional layered database architecture, although it's highly optimized for its OLAP (Online Analytical Processing) purpose. ClickHouse Architecture consists of three main layers:
➥ ClickHouse Architecture Layer 1—Query Processing Layer
Query Processing Layer takes your SQL query, parses it,creates an optimized execution plan (both logical and physical), and then executes it using a highly efficient vectorized execution engine.
A vectorized execution engine processes data in chunks (vectors) rather than row-by-row, often leveraging SIMD instructions on the CPU for parallel computation within a single core. ClickHouse further parallelizes work across multiple CPU cores on a single node and, for distributed setups, across multiple nodes (shards) in a cluster. Runtime code generation (JIT compilation) can sometimes be used for extra speed.
➥ ClickHouse Architecture Layer 2—Storage Layer
Storage Layer deals with how data physically resides on disk. The core component here is the ClickHouse MergeTree family of table engines. These engines store data in sorted, immutable "parts" on local disk, with data organized by columns within each part. Background processes continuously merge these parts over time to maintain efficiency and consolidate data. Storage Layer layer also handles partitioning (usually by time), the sparse primary index, data skipping indexes for further optimization, and replication via ReplicatedMergeTree engines.
➥ ClickHouse Architecture Layer 3—Integration Layer
Integration Layer connects ClickHouse to the outside world. It supports over 50 integration table functions and engines, allowing it to connect with a wide range of external systems. These include:
- Relational databases (MySQL, PostgreSQL, SQLite) - via engines like MySQL, PostgreSQL, or ODBC / JDBC table functions.
- Object storage (AWS S3, Google Cloud Storage (GCS), Azure Blob Storage) - often via the S3 table engine or S3 table function.
- Streaming systems (Kafka) - via the Kafka engine.
- NoSQL/Other systems (Hive, MongoDB, Redis) - via engines/functions like Hive, MongoDB, Redis.
- Data Lakes (interacting with formats like Iceberg, Hudi, Delta Lake ) - via engines like Iceberg, Hudi, DeltaLake.
- Standard protocols like ODBC - via the ODBC table function.
While ClickHouse clusters are used for scaling and high availability, the fact that a single ClickHouse server process often handles these diverse responsibilities gives it a more "unified" feel compared to Druid's collection of distinct services.
Coordination for replication in a ClickHouse cluster depends on an external system. Typically, this is ClickHouse Keeper, the recommended Raft-based solution, or Apache ZooKeeper. This unified server model offers simplicity, which can be helpful for smaller deployments. When focusing on the raw processing power of a well-provisioned node, it cuts down on inter-process communication overhead. This overhead can be a challenge in more distributed designs.
Apache Druid Architecture
In contrast, Apache Druid adopts a distributed, multi-process architecture that resembles a collection of microservices. Each type of service has a specific role and, importantly, can often be scaled independently of the others, offering fine-grained control over cluster resources.
The key components of Apache Druid services are:
➥ Apache Druid Component 1—Druid Coordinator
The Coordinator is like the data manager. It watches over the Historical nodes, tells them which data segments to load or drop, makes sure Druid segments are replicated correctly across nodes, and handles segment balancing to keep the load even. It also manages automatic data compaction.
➥ Apache Druid Component 2—Druid Overlord
The Overlord is responsible for data ingestion. It assigns ingestion tasks to MiddleManager or Indexer nodes and coordinates when new data segments are finalized and published to deep storage and made available to Historicals.
➥ Apache Druid Component 3—Druid Broker
This is the query gateway. Clients send their queries (either SQL, which is translated by Apache Calcite, or Druid's native JSON-based queries) to Broker nodes. The Broker determines which Historical nodes (for stored data) or real-time ingestion nodes (like MiddleManagers or Indexers, for very recent data) hold the relevant data segments for the query's time range and filters. It then "scatters" rewritten sub-queries to these nodes, "gathers" the partial results, merges them, and returns the final answer to the client. Brokers also handle query caching.
➥ Apache Druid Component 4—Druid Router (Optional)
The Router can act as a unified API gateway in front of Brokers, Overlords, and Coordinators. It simplifies client interaction and routing requests appropriately. The Druid web console is also typically hosted on Router nodes.
➥ Apache Druid Component 5—Druid Historical
These are the workhorses for querying stored data. Historicals download immutable data segments from deep storage (acting as a permanent backup) onto their local disk (which serves as a cache) and keep them memory-mapped for fast access. They execute the sub-queries sent by the Broker and return partial results. Historicals do not handle ingestion or accept writes.
➥ Apache Druid Component 6—Druid MiddleManager & Druid Peon
These are the primary specialists for real-time data ingestion. MiddleManagers receive ingestion tasks from the Overlord and launch separate JVM processes called Peons to execute these tasks. Peons read from streaming sources (like Kafka), index data into segments in memory (making it immediately queryable), and eventually hand off completed segments to deep storage for persistence and to Historicals for long-term querying.
➥ Apache Druid Component 7—Druid Indexer (Optional/Experimental)
An alternative ingestion process that runs tasks as threads within a single JVM. This can potentially offer better resource sharing, especially for streaming ingestion, compared to the MiddleManager/Peon model where each Peon is a separate JVM. Typically, a deployment would use either MiddleManagers/Peons or Indexers for streaming, not both.
This distributed setup relies on three crucial External Dependencies:
- Deep Storage — It is essential for durability. Deep Storage is a distributed filesystem (like HDFS) or an object store (like Amazon S3, Google Cloud Storage, or Azure Blob Storage) where all finalized data segments are permanently stored. If Historical nodes are lost, they can reload their data from here.
- Metadata Store — A relational database (such as PostgreSQL or MySQL) that stores metadata about Druid segments, ingestion rules, configuration details, and task information. It's important to note that the actual user data is not stored here.
- Apache ZooKeeper — Used for internal service discovery, distributed coordination among Druid services (like which Coordinator/Overlord is the current leader), and leader election.
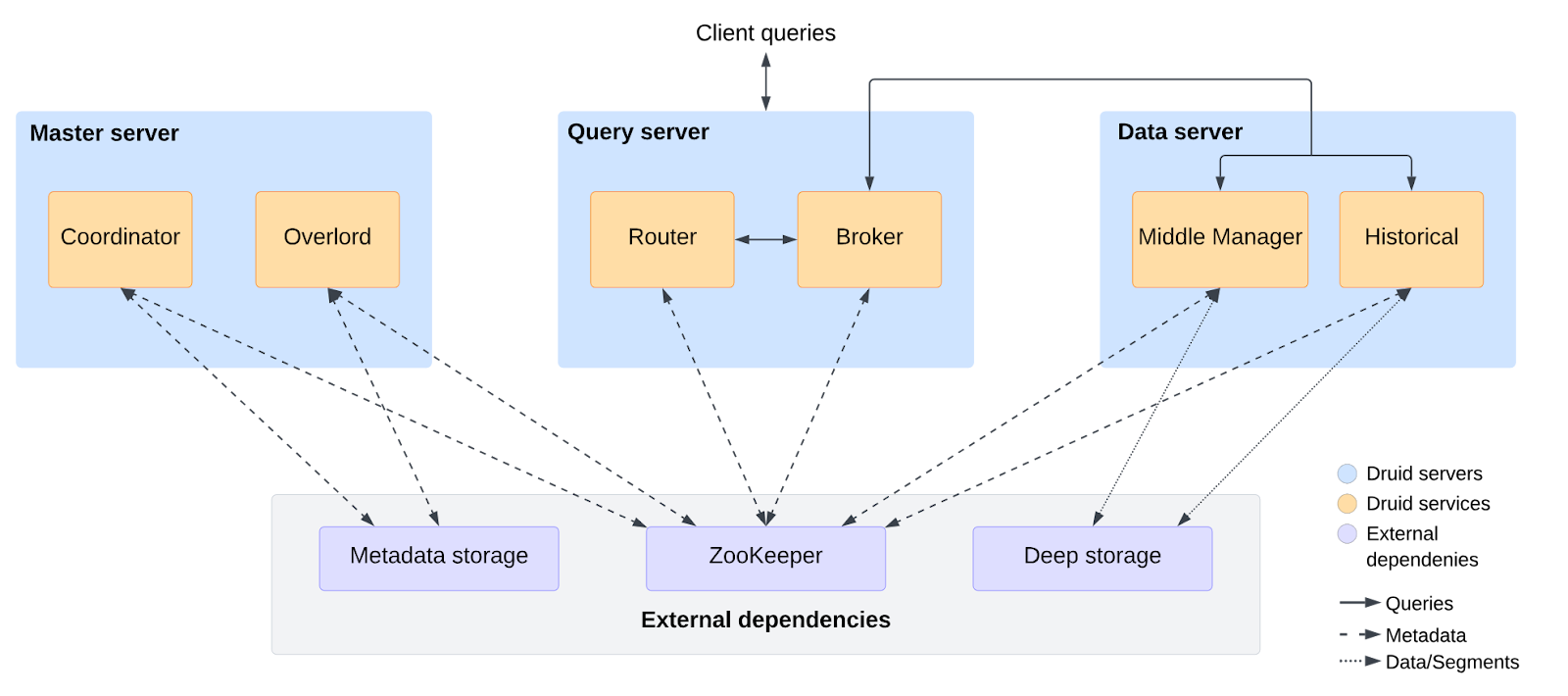
ClickHouse has a unified process that's easy to deploy and fast. But if it fails, the impact is big. Druid has separate services that can be scaled individually, making it flexible. However, this complexity requires more effort to manage.
🔮 ClickHouse vs Druid TL;DR: ClickHouse's architecture leans towards a more unified server process per node, potentially offering deployment simplicity and raw node power. Apache Druid embraces a modular, microservice-style architecture, providing component-level scalability and isolation but with more moving parts to manage.
2️⃣ ClickHouse vs Druid—Data Storage & Format (ClickHouse MergeTree vs Segments)
Both ClickHouse vs Druid store data in columnar format. This is a fundamental point for OLAP workloads. Why? Because analytical queries usually only need to read a few columns out of potentially very wide tables. In a traditional row-oriented database, the system would have to read the entire row (all its columns) just to get to the few columns it cares about. Columnar storage avoids this by allowing the database to read only the data for the columns specified in the query, insanely reducing I/O and speeding up processing.
ClickHouse Data Storage & Format
The core of ClickHouse storage is MergeTree and its variants (ReplacingMergeTree, SummingMergeTree, AggregatingMergeTree, CollapsingMergeTree, VersionedCollapsingMergeTree, GraphiteMergeTree). When data is inserted into a MergeTree table, ClickHouse creates immutable "parts" on disk. Each part contains a chunk of rows sorted by the table's primary key (or by its ORDER BY key).
ClickHouse MergeTree relies on several fundamental properties to store data.
Primary Key & Sorting — Every MergeTree table must have an ORDER BY clause defining the sorting key (which also acts as the primary key if PRIMARY KEY isn't explicitly set differently). Data within each part is physically sorted on disk according to this key. This sorting is vital for efficient data retrieval and compression.
Sparse Primary Index — ClickHouse doesn't create an index entry for every single row. Instead, it builds a sparse primary index based on the ORDER BY key. Sparse Index stores "marks" that point to the start of data blocks, called granules (typically 8192 rows by default, defined by index_granularity). Because it only stores marks for every granule, the index remains small enough to fit comfortably in memory, allowing ClickHouse to quickly identify which granules might contain the data needed for a query based on a primary key range filter, enabling it to skip reading large, irrelevant blocks of data.
Columnar Files — Inside each data part, data for each column is typically stored in separate compressed files (this is known as the "Wide" format). For small insert batches, to reduce the number of files, columns might be grouped into a single file (the "Compact" format).
Compression — ClickHouse is renowned for its highly effective data compression, using algorithms like LZ4 (the default) or ZSTD, significantly reducing the storage footprint and often speeds up queries by reducing the amount of data that needs to be read from disk and transferred.
Partitions (Optional) — Users can optionally define a PARTITION BY key, frequently based on a time unit like month or day (e.g., PARTITION BY toYYYYMM(date_column)). Partitioning helps with data management (for instance, efficiently dropping old partitions) and allows ClickHouse to skip reading entire partitions if they don't match a query's filters (a process called partition pruning). BUT, unlike the ORDER BY key, the PARTITION BY key does not directly influence the physical sort order of data within a part.
Note: The ORDER BY key is a powerful for achieving speed gains, but its effectiveness differs on intelligent schema design. The chosen sorting key must align with common query filter patterns. If filters are frequently applied to columns that are not early in the ORDER BY sequence, the sparse index offers less benefit for those filters, and ClickHouse might have to scan more data.
Apache Druid Data Storage & Format
Apache Druid's fundamental unit of storage is the segment. Segments are immutable, columnar data files created during the ingestion process.
Unlike ClickHouse where partitioning is optional, Druid always partitions segments based on a specific time interval (defined by segmentGranularity, e.g: HOUR or DAY). Each segment typically contains anywhere from a few hundred thousand to a few million rows, with a common recommendation aiming for a segment size of 300-700 MB for optimal performance. Secondary partitioning within a time chunk (by a dimension value) is also possible.
Data within each segment is stored columnarly and optimized by data type.
During ingestion, Apache Druid automatically creates several index structures within each segment for dimension columns (columns used for filtering and grouping):
- Dictionary Encoding — For string dimensions, Druid builds a dictionary that maps each unique string value to an integer ID. The column data then stores these compact integer IDs instead of the original, potentially much larger, strings. This saves space and speeds up comparisons.
- Bitmap Indexes — For each unique value in a dictionary-encoded dimension, Druid creates a compressed bitmap index (typically using efficient Roaring bitmaps). This bitmap indicates exactly which rows within that segment contain that specific value. These bitmaps are highly efficient for filtering because logical AND and OR operations on multiple filter conditions can be performed very quickly by directly manipulating the bitmaps.
Apache Druid can also optionally perform pre-aggregation during ingestion, a feature known as rollup. If multiple raw input events have identical dimension values and fall within the same timestamp granularity, Druid can combine them into a single row in the segment, summing up any metric values. This can significantly reduce storage size and boost query performance but involves a loss of raw event granularity.
Druid's automatic indexing approach for all dimensions simplifies operations for users, as there's no need to manually define or tune secondary indexes for filtering. The combination of dictionary encoding and bitmap indexes makes Druid particularly adept at handling queries involving filters and group-bys, even on high-cardinality dimensions. But remember that, the process of creating and storing these dictionaries and bitmaps for every dimension column adds computational overhead during ingestion. It can also result in a larger overall storage footprint for the indexed data compared to ClickHouse’s sparse primary index approach, especially if there are many dimensions or dimensions with very high cardinality.
Note: Although indexes are compressed, they still occupy storage space.
🔮 ClickHouse vs Druid TL;DR: ClickHouse uses a sparse primary index tied to its ORDER BY key, offering efficient storage and targeted speed if queries align with this key. Apache Druid automatically creates dictionary encodings and bitmap indexes for all string dimensions, providing broad filtering capabilities out-of-the-box but with higher ingestion and storage costs for these indexes.
3️⃣ ClickHouse vs Druid—Data Ingestion Approach (Micro-Batch vs True Real-Time)
The way ClickHouse vs Druid handle data ingestion differs in a big way, and this impacts how up-to-date your data is and which applications they're more suited for.
ClickHouse Data Ingestion Approach
ClickHouse generally performs best when data is inserted in batches. The ideal batch size is often recommended to be between 10,000 and 100,000 rows, with a minimum of around 1,000 rows for reasonable efficiency.
Why this preference for batches? It stems directly from the mechanics of the ClickHouse MergeTree storage engine. Each INSERT statement creates one or more new, immutable data "parts" on disk. Inserting rows one by one or in very small batches leads to a proliferation of tiny parts. While ClickHouse has background processes that continuously merge these small parts into larger, more optimal ones, an excessive number of small parts can significantly increase CPU and I/O load due to constant merging activity. Batching amortizes the overhead of part creation and merging across many rows, leading to much higher overall throughput and lower system load.
Here are some common ways to get data into ClickHouse include:
- INSERT INTO... VALUES — Suitable for inserting data directly, but should always be used with multiple rows per statement (batching) for performance.
- INSERT INTO... SELECT — Efficient for inserting data from the results of another query, often used for data transformations or moving data between tables within ClickHouse.
- File-Based Ingestion — Using the clickhouse-client or tools like clickhouse-local to ingest data from files in various formats such as CSV, JSON, Parquet, Native, etc.
- Kafka Integration — Typically achieved using the Kafka table engine combined with a Materialized Views that reads from the Kafka engine table and inserts into a target ClickHouse MergeTree table. It's important to understand that this often functions as micro-batching. The Kafka engine consumes messages from Kafka in batches, and the materialized view then inserts these batches into the final table. Achieving true event-at-a-time processing where each individual message results in an immediate tiny insert is generally not the optimal way to use ClickHouse due to the MergeTree mechanics previously discussed. Other tools like Kafka Connect (using JDBC or dedicated sink connectors) or Vector can also bridge Kafka and ClickHouse, often handling the batching externally before data reaches ClickHouse.
- Asynchronous Inserts — For cases where client-side batching is hard, ClickHouse provides asynchronous inserts with the async_insert=1 setting. When this is on, the ClickHouse server keeps small incoming inserts in memory. It then writes them to disk in larger batches. The server flushes the buffer when it hits a set size (async_insert_max_data_size) or after a timeout (async_insert_busy_timeout_ms). The wait_for_async_insert setting decides if the client waits for the data to be written to disk or just acknowledged by the buffer. This server-side batching shifts the workload from the client. It helps efficiency for high-concurrency, low-volume insert patterns. However, setting wait_for_async_insert=0 can be risky. The client may miss errors that happen during the disk flush.
Apache Druid Data Ingestion Approach
Apache Druid was designed with real-time data ingestion as a primary objective. It aims to make streaming data available for querying almost immediately after it arrives.
Druid achieves this through its architecture and native integrations:
Native Streaming Ingestion (Kafka & Kinesis) — Apache Druid offers built-in, connector-free integration with Apache Kafka and Amazon Kinesis. Users configure an ingestion "supervisor" specification that tells Druid how to connect to the stream, parse the data, and ingest it. This native integration is robust, supporting exactly-once processing semantics to prevent data loss or duplication, even if failures occur. This tight integration is often simpler to set up and manage for Kafka/Kinesis pipelines compared to ClickHouse's Kafka engine/Materialized View approach or relying on external connector tools for these specific sources.
Batch Ingestion — Druid also supports batch loading from various sources:
- Native Batch (index_parallel) — A flexible method for ingesting files from sources like HDFS, S3, GCS, or local files. Ingestion tasks run in parallel on MiddleManager nodes.
- SQL-based Batch (INSERT/REPLACE) — Allows using SQL queries to ingest data, either from external sources (using the EXTERN function) or by transforming data already in Apache Druid. This aims to provide a more familiar interface for batch ETL.
- Hadoop-based Batch (index_hadoop) — Leverages an existing Hadoop cluster (YARN/MapReduce) to perform large-scale batch ingestion, often used for very large historical data loads.
While Druid excels at streaming, its batch ingestion mechanisms, particularly the native and Hadoop-based ones that require JSON-based task specifications, can sometimes be perceived as more complex to configure and tune compared to ClickHouse's more SQL-centric batch approaches like INSERT INTO... SELECT or direct file uploads.
A notable aspect of Apache Druid ingestion is its handling of schema evolution. Apache Druid stores the schema within each segment. This allows new data with new columns to be ingested without affecting older segments. Apache Druid 26.0 and later introduced schema auto-discovery, where Apache Druid can automatically detect field names and data types during ingestion, and even update table schemas (e.g., adding new columns, changing data types like Long to String if needed) as the source data evolves, without requiring manual intervention or re-indexing of existing data. Changing types or dropping columns in existing data still requires a re-indexing task.
🔮 ClickHouse vs Druid TL;DR: ClickHouse favors batched inserts for optimal MergeTree performance, offering micro-batching for streams. Druid is built for true real-time streaming ingestion with immediate queryability, especially from Kafka and Kinesis, and has more agile schema handling for new data.
4️⃣ ClickHouse vs Druid—Query Execution Model (Vectorized vs Scatter/Gather Query Execution)
ClickHouse vs Druid both of ‘em are designed to execute queries across multiple CPU cores and, in clusters, across multiple nodes. But, their underlying strategies for query execution differ significantly.
ClickHouse Query Execution Model
ClickHouse uses vectorized execution engine. Instead of processing data one row at a time, operations such as filtering, aggregation, and calculations are performed on batches, or "vectors", of column values simultaneously. This method utilizes modern CPU capabilities, specifically SIMD (Single Instruction, Multiple Data) instructions, which apply one operation to multiple data points in a single CPU cycle. Vectorization reduces the overhead from interpreting query instructions and making function calls for each value, leading to performance improvements, particularly for scans and aggregations over large datasets.
Now, when you run a query on a bunch of ClickHouse servers hooked up together in a cluster, where data is split up (sharded) and maybe copied (replicated). Here’s the typical flow:
- A query arrives at any ClickHouse node, which acts as the initiator (or coordinator) for that query.
- The initiator node analyzes the query. For queries involving a Distributed table engine, and if settings like optimize_skip_unused_shards are active, it determines which shards (and therefore, which servers) hold the necessary data. It then forwards the relevant query parts to one replica of each required shard. The initiator node processes its local data directly if it holds relevant portions. The choice of remote replica can depend on load balancing configurations.
- Each shard replica executes its part of the query on its local data using the vectorized engine.
- These servers send their intermediate results—such as partial aggregations or filtered data—back to the initiator node.
- The initiator node merges these partial results to produce the final query result and sends it to the client. Settings like max_parallel_replicas can configure the initiator to query multiple replicas of each shard in parallel, using the result from the first to respond, which can enhance query speed and fault tolerance.
This whole vectorized thing, combined with multi-threading locally and distributed processing in a cluster, makes ClickHouse effective for CPU-intensive analytical tasks that scan and aggregate large volumes of data.
Apache Druid Query Execution
Apache Druid uses a “scatter/gather” query execution model, closely tied to its distributed architecture and indexing strategy.
Here’s the typical journey of an interactive query in Druid:
- A query, either in SQL (parsed by Apache Calcite) or Druid's native JSON format, reaches a Broker node.
- The Broker is the query quarterback. It checks with the cluster metadata (managed by Coordinator nodes and stored in a Metadata Store) to see which data segments hold the info relevant to your query's time range and other filters. This segment pruning significantly reduces the amount of data scanned. Segments are Druid's fundamental storage unit, typically containing several million rows, stored in a columnar format, and optimized with dictionary encoding for string columns and bitmap indexes.
- The Broker divides the main query into sub-queries for the identified segments. It "scatters" these sub-queries in parallel to the appropriate Data nodes: Historical nodes for immutable, historical data, and MiddleManager nodes (running Indexer tasks) or dedicated Indexer nodes for real-time data streams.
- Each Data node executes its assigned sub-query on the segments it holds locally. Druid emphasizes data locality; Historicals pre-load segments from deep storage (like S3 or HDFS) into memory or local disk caches. This minimizes data transfer from deep storage during query execution. On Data nodes, query processing heavily uses dictionary encoding and bitmap indexes for string-based dimension columns to accelerate filtering. Druid automatically creates these dictionary encodings and bitmap indexes for all string dimension columns during ingestion. Numeric metric columns are typically aggregated and stored directly. The primary time column is also extensively indexed.
- The Data nodes return their partial results to the originating Broker.
- The Broker "gathers" these partial results and merges them to form the final answer to the original query.
Apache Druid also utilizes caching. Brokers can cache final query results, and Historicals can cache per-segment results, speeding up subsequent identical queries.
Apache Druid’s scatter/gather system, combined with its aggressive indexing (especially bitmap indexes for fast filtering on dimensions), time-based partitioning, and keeping data close to the compute power (pre-loaded segments), is really tuned for getting you answers fast—often in under a second. It shines when queries can effectively use time ranges and dimension filters to prune the search space, letting those bitmap indexes do their magic on the relevant segments. Druid's architecture is designed with independently scalable services for ingestion, querying, and coordination.
🔮 ClickHouse vs Druid TL;DR: ClickHouse leans on a highly efficient vectorized engine that crunches data in batches, which is great for CPU-heavy analytical tasks, both on a single machine and spread across a cluster. Druid, on the other hand, uses a scatter/gather approach that’s all about low-latency, index-driven queries. It aggressively prunes data and fans out the work to specialized nodes that often have the needed data already in memory or close by.
5️⃣ ClickHouse vs Druid—Indexing Strategy (Sparse Primary Key vs Automatic Bitmap/Dictionary)
Indexes are like the signposts within a database, helping queries find the data they need without having to scan every single piece of information. Both ClickHouse vs Druid use indexing, but their approaches and the types of indexes they employ are fundamentally different.
ClickHouse Indexing Strategy:
ClickHouse's indexing revolves around two main concepts: Sparse Primary + Data Skipping.
ClickHouse’s MergeTree tables always have a primary key, but this is implemented as a sparse index.
Sparse Primary Index — As we have already discussed in the storage section, this index doesn't store an entry for every row. Instead, for each data part, it stores "marks" corresponding to the first row of each data granule (a block of, by default, 8192 rows). These marks hold the minimal values of the primary key columns in that block. When a query has a WHERE on the primary key, ClickHouse can binary-search these marks to skip whole blocks that fall outside the filter. This is extremely space-efficient (the index is tiny compared to row count). However, if your query predicates don’t align with the primary key, ClickHouse generally must scan every row in each relevant block.
Data Skipping (Secondary) Indexes — To help with filtering on columns that are not part of (or not early in) the ORDER BY key, ClickHouse offers optional data skipping indexes (sometimes referred to as secondary indexes). These are not traditional B-tree indexes that point to individual rows. Instead, they store aggregate information about data granules. Here are some common types:
So by default, only the sparse primary index is present. The effective use of data skipping indexes requires understanding query patterns and data distribution.
Apache Druid Indexing Strategy:
Apache Druid takes a different route, automatically and extensively indexing every string dimension column at ingestion time within each segment.
- Dictionary Encoding — For every string dimension column, Druid builds a dictionary. Dictionary maps each unique string value encountered in that column (within a segment) to a compact integer ID. The actual column data then stores these integer IDs instead of the original strings, saving space and speeding up comparisons.
- Bitmap Indexes — For each unique value (and its corresponding integer ID from the dictionary) in a dimension column, Apache Druid creates a bitmap index (commonly using highly optimized Roaring bitmaps). This bitmap has a bit for each row in the segment, indicating whether that row contains the specific dimension value. When a query filters on one or more dimension values, Druid performs very fast logical operations (like bitwise AND, OR, NOT) directly on these compressed bitmaps to find the set of matching rows. This is effectively a full inverted index on all dimensional data.
Numeric metric columns in Druid typically don't have such elaborate indexing; they are usually stored as compressed arrays of values because they are primarily aggregated rather than filtered upon.
Druid's automatic indexing for dimensions makes operations easier. Users don’t have to define or tune secondary indexes for filtering. Druid uses dictionary encoding and bitmap indexes. This helps it handle queries with filters and group-bys on high-cardinality dimensions well. However, creating and storing these dictionaries and bitmaps for each dimension column adds computational overhead during ingestion. It can also result in a larger storage footprint for the indexes compared to ClickHouse’s sparse primary index and optional skip indexes.
🔮 ClickHouse vs Druid TL;DR: ClickHouse relies on a sparse primary index tied to data sort order, with optional, manually configured data skipping indexes (like bloom filters) to help prune data blocks. Apache Druid automatically creates comprehensive inverted indexes (dictionaries and bitmaps) for all string dimensions, enabling fast filtering at the cost of higher ingestion overhead and index storage. Druid's indexes are more "complete" for filtering any dimension, while ClickHouse's are lighter but more dependent on schema design and query alignment with the primary key.
6️⃣ ClickHouse vs Druid—Concurrency & Workload
ClickHouse vs Druid are both high-performance OLAP engines, but they take very different approaches to concurrency, query scheduling, and mixed workloads.
ClickHouse Concurrency & Workload
a) Concurrency Model
ClickHouse handles concurrency by internally allocating work across a global pool of threads. Each query grabs as many threads as it’s allowed (up to max_threads, by default matching your CPU core count), then competes for execution slots in the ConcurrencyControl system. If slots are full, queries queue up inside ClickHouse.
The default is “unlimited” concurrency (0 means no cap), but you can set global limits for selects, inserts, or connections:
max_concurrent_queriesmax_concurrent_select_queriesmax_concurrent_insert_queriesmax_connections(default 4096)
Recent ClickHouse releases (since 23.9) do support fine-grained workload scheduling. You define resources and workloads via SQL (CREATE RESOURCE cpu, CREATE WORKLOAD ...), then tag queries with SETTINGS workload='name'. Each workload can have its own thread limits and priorities. Lower priority means higher precedence; weight distributes freed slots when priorities tie. There are separate settings for “master” and “worker” threads, to prevent head-of-line blocking.
If you turn off ClickHouse's scheduler (use_concurrency_control=0), the OS takes over thread management. The system remains monolithic: all reads, writes, merges, and background tasks share the same CPU and I/O pool. There's no hard wall between workloads unless you split them across clusters or hardware.
b) Query Prioritization
ClickHouse doesn’t offer explicit “query lanes” like Druid. Instead, everything is governed by your workload definitions:
For example, you can do:
CREATE RESOURCE cpu_res WITH max_concurrent_threads = 100;
CREATE WORKLOAD high_prio WITH resource = 'cpu_res', priority = 1, max_concurrent_threads = 80;
CREATE WORKLOAD low_prio WITH resource = 'cpu_res', priority = 2, max_concurrent_threads = 60;You tag queries with SETTINGS workload='high_prio'. The scheduler always favors lower-priority values. If priorities match, weight determines sharing. These limits are strictly enforced—no dynamic “stealing” of threads.
A common misconception: capping master threads (max_concurrent_master_threads) doesn't restrict total queries. It only limits how many can start in parallel; queued queries can still pile up behind that gate.
ClickHouse doesn't have a single built-in setting to cap the number of simultaneous queries beyond max_concurrent_queries. Many deployments use connection poolers or proxies to limit query inflow upstream.
c) Mixed Workload (Ingestion vs Query) Isolation
In ClickHouse, ingestion and queries share the same CPU and disk resources on each server. However, the MergeTree engine design ensures minimal locking: new inserts create fresh parts, and queries always read consistent snapshots of all parts. Merging of parts happens in background threads. As stated in the ClickHouse documentation, “inserts are fully isolated from SELECT queries, and merging inserted data parts happens in the background without affecting concurrent queries”. In practice this means streaming inserts or batch loads do not pause concurrent selects. CPU contention can occur if merges or heavy inserts consume cores, but ConcurrencyControl still fairly time‐slices threads.
ClickHouse offers limited knobs to isolate workloads beyond query concurrency. For example, you could create separate shards or clusters for high-priority analytics and for heavy ingestion. Within one cluster, you can throttle insert throughput (batch size, background thread count), but there is no native “ingest priority” setting. Under normal conditions, queries remain fast even under heavy ingestion. The main consideration is disk I/O: very high insert rates increase I/O and can slightly slow queries. Thus careful sizing and use of fast disks (or tiered storage policies) are important in real deployments, but there is no strict separation of ingestion vs query nodes in ClickHouse.
Apache Druid Concurrency & Workload:
Apache Druid, on the other hand, was built from day one for high concurrency.
a) Concurrency
Apache Druid is built as a distributed system of specialized services. Query concurrency is determined by thread pools in the Broker and Historical nodes.
- Brokers: Each query uses an HTTP thread. The pool size (
druid.server.http.numThreads) defaults to a function of core count, but is tunable. Druid suggests leaving a few threads for non-query tasks. - Historicals: Segment-processing concurrency is set via
druid.processing.numThreads(usuallyCPU cores - 1per node). That’s how many segment-scanning tasks run in parallel.
If all threads are busy, queries queue. The queue is capped by druid.server.http.queueSize. There’s no global “max queries” limit; you scale concurrency by adding more Brokers or Historicals.
b) Query Prioritization
Druid attaches an integer priority to every query (default 0). Higher numbers mean higher priority. This value flows through Brokers to Historicals, guiding scheduling. With the hilo laning strategy, queries below 0 are “low”; 0 or above are “high” or “interactive”.
druid.query.scheduler.laning.strategy = hilo
druid.query.scheduler.laning.maxLowPercent = 20
druid.query.scheduler.numThreads = 48This reserves up to 20% of Broker threads for low-priority queries. High-priority queries can't be starved by background workloads. You can define custom lanes by name and set each lane’s size.
Druid can also demote “big” queries (long time ranges, many segments) using threshold rules, so quick, interactive queries aren’t delayed by heavy analytics.
c) Mixed Workloads
Druid’s architecture keeps ingestion and queries apart. Indexer and MiddleManager nodes handle ingestion (batch or streaming) on their own thread pools (druid.worker.capacity). Once data lands in storage and is loaded by Historicals, it's available for queries. Brokers and Historicals never handle ingestion; they're reserved for queries.
Real-time ingestion tasks (Kafka, Kinesis) can serve queries directly for "hot" data, but these are advanced setups and run on dedicated nodes.
Druid supports service tiering: you can assign certain Historicals to “hot” data, others to “cold” deep storage; you can tier Brokers for high- or low-priority queries. This is much more granular than anything ClickHouse natively supports.
🔮 ClickHouse vs Druid TL;DR: Apache Druid offers strong workload isolation thanks to its microservices design, explicit query laning, and service tiering. You can scale ingestion and query concurrency separately, and prioritize workloads with clear, enforceable boundaries. ClickHouse now has a robust internal workload scheduler, but it’s still a monolithic engine. All operations share the same CPU and I/O pool, but are not hard-isolated. For most analytics workloads, ClickHouse’s efficiency and low-latency queries make this a non-issue. For strict separation, especially under heavy ingestion, Druid’s architecture is more flexible.
7️⃣ ClickHouse vs Druid—Fault Tolerance & High Availability
Both ClickHouse vs Druid support clustering for high availability (HA), but their mechanisms differ.
ClickHouse Fault Tolerance & High Availability
ClickHouse achieves fault tolerance via table replication, using its ReplicatedMergeTree family of table engines.
➥ Replication — When using ReplicatedMergeTree, data for each shard in a cluster is copied across multiple nodes (replicas). A common setup is to have at least two replicas for each shard to provide fault tolerance. All replicas are typically active and can serve read queries.
➥ Coordination with ClickHouse Keeper/ZooKeeper — Distributed coordination is managed by ClickHouse Keeper (a C++ Raft-based implementation) or Apache ZooKeeper. Keeper/ZooKeeper stores metadata about replicas, manages a distributed log of operations (like inserts, merges, DDL statements), and handles leader election for certain operations to ensure consistency across replicas.
➥ Failure Behavior — If a node hosting a replica goes down, the other replicas for that shard continue to function and serve queries. INSERT statements can be directed to any available replica of the shard. When the failed node rejoins the cluster, its ReplicatedMergeTree tables will communicate with Keeper/ZooKeeper and synchronize any missed data parts from other healthy replicas to catch up.
➥ Client-Side Considerations — If a node becomes unavailable, client applications or load balancers typically need logic to redirect their connections and queries to a healthy replica of the required shard. ClickHouse itself doesn't transparently reroute an in-flight query if its target node fails mid-execution.
➥ Data Rebalancing — In open source ClickHouse, if you add new nodes to a shard or want to re-shard data for better distribution, the system does not automatically rebalance existing data parts across the nodes. This rebalancing is a manual operational task.
Apache Druid Fault Tolerance & High Availability
Apache Druid's fault tolerance strategy is built upon the replication of data segments on Historical nodes, the use of durable deep storage, and redundancy for its master/control plane services.
➥ Segment Replication & Deep Storage — Apache Druid segments, once created, are immutable. They are permanently stored in deep storage (e.g: S3, HDFS). The Coordinator process ensures that each segment is replicated onto a configurable number of Historical nodes. Historicals load these segments from deep storage and cache them locally for querying.
➥ Failure Behavior (Historical Node) — If a Historical node fails, the segments it was serving are not lost because they exist in deep storage and on other replicas. The Coordinator will detect the failure and instruct other available Historical nodes to load the affected segments from deep storage, thus maintaining the desired replication factor and data availability. Queries are automatically routed to the remaining healthy Historicals serving the data.
➥ Master Service HA — Critical control services like the Coordinator and Overlord are typically run in pairs (or more) for high availability. Apache ZooKeeper manages leader election for these services; only one instance is active at a time, and if the active leader fails, ZooKeeper facilitates the election of a new leader from the standby instances.
➥ Broker Statelessness — Broker nodes, which handle query routing, are stateless. They can be scaled out, and multiple instances are typically run behind a load balancer. If a Broker fails, traffic is simply directed to other healthy Brokers.
➥ Dependencies — A robust Apache Druid HA setup also relies on a fault-tolerant ZooKeeper ensemble (e.g: 3 or 5 nodes) and a replicated metadata store (e.g: PostgreSQL or MySQL with its own HA setup) to avoid single points of failure in these critical external dependencies.
🔮 ClickHouse vs Druid TL;DR: ClickHouse vs Druid both use ZooKeeper (or its equivalent, ClickHouse Keeper) for coordination. Druid's architecture, with its decoupled deep storage and automated segment management by the Coordinator, generally offers a more hands-off and elastic approach to data availability and recovery compared to self-managed ClickHouse. ClickHouse's replication is solid, but scaling and some failover aspects can be more manual in OSS.
8️⃣ ClickHouse vs Druid—SQL Dialect & Functionality
SQL skills are a big deal for many data pros, and both ClickHouse vs Druid have SQL interfaces. But here's the thing: their SQL flavors have different strengths, drawbacks, and performance profiles.
ClickHouse SQL Dialect & Functionality
ClickHouse provides a powerful SQL dialect that is largely compliant with the ANSI SQL standard but also includes numerous extensions specifically optimized for analytical tasks. It supports a wide array of standard constructs:
- Core SQL: SELECT, INSERT, ALTER, CREATE, GROUP BY, ORDER BY.
- Advanced SQL: Various JOIN types (see below), subqueries (in FROM, WHERE, SELECT), Common Table Expressions (CTEs), and window functions.
Where ClickHouse particularly stands out is its incredibly rich library of built-in functions:
Aggregate Functions — Beyond standard aggregates (COUNT, SUM, AVG, MIN, MAX), ClickHouse offers many specialized ones like uniq (and its variants like uniqCombined for approximate distinct counts), groupArray (to collect values into an array per group), quantiles (and other statistical functions). It also features aggregate function combinators (e.g., -If, -Array, -State, -Merge) that modify the behavior of aggregate functions, allowing for powerful conditional or stateful aggregations.
Regular Functions — An extensive collection covering arithmetic, comparisons, logical operations, type conversions, date/time manipulation (with time zone support), string processing (including regular expressions, splitting, searching), array manipulation (with higher-order functions like map, filter, fold), JSON operations, URL parsing, hashing functions, conditional logic (if, multiIf), functions for working with NULL values, bitwise operations, geographical functions, and even functions for invoking machine learning models.
Table Functions — These are functions that return a table and can be used in the FROM clause of a query. They are used for reading data from external sources (s3, hdfs, url, mysql, postgresql, jdbc, odbc), generating data (numbers, generateRandom), or accessing cluster information (cluster, remote).
Window Functions — ClickHouse supports standard window function syntax (OVER (PARTITION BY... ORDER BY...)), including ranking functions (row_number, rank, dense_rank) and aggregate functions used over windows.
ClickHouse also supports a wide array of data types, from standard numerics, strings, dates, and booleans to more complex and specialized types like Array(T), Tuple(T1, T2,...), Map(K, V), Enum, UUID, IPv4/IPv6, Nested data structures (for arrays of tuples), LowCardinality(T) (a dictionary encoding optimization for columns with few unique values), and a robust JSON object type.
Note that ClickHouse's SQL is powerful, but users coming from traditional RDBMS should be aware of some differences. For example, ALTER TABLE... UPDATE or DELETE operations (mutations) are asynchronous, background operations that rewrite data parts, not in-place modifications suitable for transactional workloads.
Apache Druid SQL Dialect & Functionality
Apache Druid provides SQL support through a translation layer built on Apache Calcite. Incoming SQL queries are parsed and planned by Calcite on the Broker nodes and then translated into Druid's native JSON-based query language for execution on the Data nodes (Historicals, MiddleManagers/Indexers).
Apache Druid SQL supports many standard features :
- SELECT (including DISTINCT)
- FROM (tables, lookups, subqueries, joins)
- WHERE
- GROUP BY (including GROUPING SETS, ROLLUP, CUBE)
- HAVING
- ORDER BY
- LIMIT / OFFSET
- UNION ALL
- JOIN (primarily INNER and LEFT on equality conditions)
- EXPLAIN PLAN
It supports a range of standard SQL data types (VARCHAR, BIGINT, FLOAT, DOUBLE, TIMESTAMP, etc.) and includes functions for aggregation, arithmetic, date/time manipulation, string operations, comparisons, and more.
However, Apache Druid's SQL layer has historically had some limitations compared to standard SQL or ClickHouse, although it continues to improve :
- JOINs: While supported, JOIN performance can be challenging, especially between large distributed tables. Apache Druid performs best when queries operate on a single, often denormalized, datasource. Pre-joining data during ingestion is often recommended for optimal performance.
- Function Library: While covering common analytical needs, Druid's built-in function library might not be as extensive or specialized for certain niche analytical tasks as ClickHouse's vast collection.
- Specific Operator Limitations: Some advanced SQL features like PIVOT/UNPIVOT are experimental. UNION ALL has restrictions on where and how it can be used in a query. ORDER BY is limited for queries that don't involve aggregation; typically, non-aggregation queries can only be ordered by the __time column.
Apache Druid's SQL interface runs smoothly, thanks in part to Apache Calcite. But when it comes to optimization, Druid focuses on fast filtering and aggregation within a single data source. For top-notch performance, it's best to design your data models with Druid's strengths in mind. It often means denormalizing data rather than relying on complex multi-table JOINs that can slow you down at query time.
🔮 ClickHouse vs Druid TL;DR: ClickHouse offers a more comprehensive, flexible, and analytically rich SQL environment. Druid's SQL is a capable interface to its specialized engine, best suited for queries that align with its strengths in fast filtering and aggregation on denormalized or lookup-joined data, with ongoing improvements to expand its capabilities.
9️⃣ ClickHouse vs Druid—Scalability Model & Elasticity (Manual vs Automated)
As data grows and queries get more demanding, it's crucial to be able to scale your database smoothly and flexibly. ClickHouse vs Druid are both built for horizontal scalability, but there are key differences in their models and how easy they are to scale, especially when you're hosting them yourself.
ClickHouse Scalability Model
ClickHouse supports both vertical scaling (increasing resources like CPU, RAM, disk on existing nodes) and horizontal scaling (distributing data and queries across multiple nodes).
➥ Horizontal Scaling (Self-Hosted Open Source):
- Sharding — Data is partitioned across multiple nodes (shards) based on a sharding key defined in a Distributed table engine. Each shard holds a subset of the total data. Queries against the Distributed table are automatically parallelized, with parts of the query executed on each relevant shard.
- Replication — ReplicatedMergeTree tables maintain identical copies of data (replicas) across multiple nodes within each shard. This provides fault tolerance and can also improve read concurrency, as different queries can be directed to different replicas of the same shard.
Note that one issue with self-managed, open source ClickHouse clusters is that they do not automatically rebalance existing data when you add or remove shards. Instead, admins must plan and execute a data migration strategy to distribute the data evenly.
➥ Vertical Scaling (Self-Hosted Open Source) in ClickHouse can be achieved by upgrading the hardware of individual ClickHouse server nodes—more CPU cores, more RAM, or faster/larger disks. ClickHouse is very efficient at utilizing available hardware.
➥ ClickHouse Cloud Elasticity:
ClickHouse Cloud, the managed service offering, aims to simplify scaling and provide more elasticity.
- ClickHouse Cloud can automatically scale compute resources (CPU and RAM) up or down based on observed demand (CPU and memory consumption during a lookback window).
- Adding and removing replicas in ClickHouse Cloud is simplified, typically eliminating the manual data rebalancing difficulties of the open-source version for replication changes. The service may also make it easier to alter sharding setups, albeit this depends on the specific cloud provider.
- Some managed ClickHouse offerings can automatically increase storage capacity as data grows.
Apache Druid Scalability Model
Apache Druid is designed with horizontal scalability and elasticity as core architectural principles.
➥ Horizontal Scaling by Node Type — Apache Druid scales horizontally by adding more nodes of specific service types:
- Need more ingestion capacity? Add MiddleManager or Indexer nodes.
- Need to store more data or handle a higher query load on historical data? Add Historical nodes.
- Need higher query concurrency or better query planning/merging capacity? Add Broker nodes.
➥ Independent Scaling of Components — Apache Druid has the ability to scale different components (ingestion, storage/query serving, query routing) independently is a major advantage. You can tailor the cluster resources precisely to match bottlenecks in your specific workload, leading to potentially better resource utilization and cost efficiency compared to scaling entire monolithic nodes.
➥ Automatic Segment Rebalancing — The coordinator process keeps an eye on historical nodes, and when one is added, removed, or fails, it springs into action. Its job is to rebalance data segments and query loads across all the nodes that are up and running. To get things back in balance, it tells nodes to load or drop segment replicas as needed to maintain the desired replication factor and achieve a balanced distribution of data and query load.
➥ Cloud-Native Design and Deep Storage Decoupling — Apache Druid's reliance on deep storage (like S3 or HDFS) decouples data persistence from the compute nodes (Historicals). Historical nodes load the data segments they need from this central repository. This architecture makes it easier to scale the compute tier (Historicals) up or down in cloud environments, as new nodes can simply fetch the data they need from deep storage.
➥ Vertical Scaling — Apache Druid can also be scaled vertically by assigning larger instance types to appropriate node roles as needed.
➥ Elasticity in Managed Druid Services — Managed Druid services, such as Imply, use this cloud-native architecture to deliver elastic scaling, frequently automating resource modifications based on workload. Some solutions may also integrate with Kubernetes to provide autoscaling features.
🔮 ClickHouse vs Druid TL;DR: Self-managed Apache Druid offers more built-in elasticity and automation for scaling (especially data rebalancing) due to its architectural design. Self-managed ClickHouse requires more manual effort for shard rebalancing. Managed cloud versions of both platforms aim to simplify scaling significantly.
🔟 ClickHouse vs Druid—Ecosystem Integration
No database exists in a vacuum. Its value is often amplified by how well it integrates with the tools and systems already in use – programming languages, data pipelines, BI platforms, and monitoring systems.
ClickHouse Integration and Ecosystem:
ClickHouse has a broad and rapidly growing ecosystem. Its integration layer is flexible, with compatibility that covers a wide swath of modern data infrastructure. Here’s what stands out:
➥ Programming Language Clients — ClickHouse offers official and third-party connectors for C++, Go, JavaScript, Java, Python, and Rust.
➥ Data Exchange — ClickHouse supports over 50 integration table functions and engines enabling seamless data exchange with external systems, including support for various file formats and protocols.
➥ Data Pipeline and Ingestion — With the help of ClickPipes, users can set up continuous data pipelines from sources like Amazon MSK, and Apache Kafka. ClickPipes abstracts away much of the complexity in onboarding streaming data, and the roadmap includes even more connectors.
➥ External Data Sources — ClickHouse supports direct connectivity to relational databases (MySQL, PostgreSQL, SQLite) via table engines and functions. It can also pull data from NoSQL systems like MongoDB and Redis, and from data lakes using Iceberg, Hudi, and Delta Lake engines.
➥ Object Storage — ClickHouse provides native support for AWS S3, Google Cloud Storage, and Azure Blob Storage.
➥ Streaming Systems — ClickHouse Kafka engine lets you ingest streaming data directly. ClickHouse can act as a sink for real-time event processing pipelines.
➥ BI and Visualization — ClickHouse integrates with popular BI tools like Tableau, Grafana, Superset, and Redash. ODBC/JDBC drivers broaden compatibility further.
➥ Standard Protocols — ODBC and JDBC support allow ClickHouse to connect with a wide range of legacy and enterprise systems.
ClickHouse's integration layer goes beyond just connecting a lot of sources. It also uses a pull-based approach, where ClickHouse actively pulls in the data it needs, instead of waiting for it to be sent over. This simplifies things for ETL and ELT workflows.
Apache Druid Integration and Ecosystem:
Apache Druid also integrates well with common data tools and platforms, particularly in the real-time and BI space. Its ecosystem is shaped by its focus on streaming analytics and high-concurrency workloads:
➥ Streaming Data Ingestion — Apache Druid has native, connector-free integration with Apache Kafka and Amazon Kinesis.
➥ Batch Data Ingestion — Apache Druid supports batch ingestion from HDFS, cloud object storage (like S3), and local files. You can schedule and automate ingestion tasks for historical data.
➥ SQL and Query APIs — Apache Druid exposes a SQL API (powered by Apache Calcite) and a native JSON-based query language.
➥ Programming Language Clients — While not as extensive as ClickHouse, Druid offers JDBC/ODBC drivers and REST APIs, which allow integration with Java, Python, and other languages.
➥ BI and Visualization — Druid connects with BI tools such as Tableau, Superset, and Looker. Its ODBC/JDBC drivers make it compatible with most analytics platforms.
➥ ETL and Data Pipeline Tools — Apache Druid integrates with Apache NiFi, Apache Airflow, and other ETL tools for orchestrating data flows.
➥ Cloud and Big Data Platforms — Apache Druid can run on AWS, GCP, Azure, and integrates with Amazon EMR for big data processing pipelines.
➥ Security and Monitoring — Apache Druid supports integration with enterprise authentication systems, logging, and monitoring tools.
Apache Druid’s real strength is its streaming data integration. Its architecture is optimized for high-throughput, low-latency ingestion, and query-on-arrival analytics.
🔮 ClickHouse vs Druid TL;DR: ClickHouse has a pretty broad ecosystem, with a big focus on being flexible and compatible with lots of things. It's a solid choice if you need to connect to different data sources, programming languages, and cloud environments, or if you want to easily grab data from anywhere. Druid, however, emphasizes speed. It excels in streaming and real-time analytics. Itprovides native integrations with Kafka and Kinesis. Druid can handle many concurrent workloads, making it ideal for operational analytics and event-driven systems. It may not support as many languages or external databases like ClickHouse, but when it comes to streaming data and fast query results at scale, it's tough to beat.
ClickHouse vs Druid — Pros & Cons
After dissecting their features, let's round up the strengths and weaknesses of ClickHouse vs Druid. Now lets dive into ClickHouse Pros and Cons.
ClickHouse Pros and Cons
ClickHouse Pros:
- Blazingly fast query speed. ClickHouse is known for sub-second analytic queries even on petabytes of data, due to its vectorized execution engine.
- Very rich SQL functionality. ClickHouse offers a comprehensive SQL dialect with extensive support for complex JOINs (though they require optimization), subqueries, window functions, and a vast library of built-in functions tailored for analytics (time series, geospatial, advanced aggregations, array manipulations, …).
- Very simple architecture. Clickhouse is very easy for deployment and upgrades. No multiple services to juggle. (You do need ZooKeeper/ClickHouse Keeper for replication, but otherwise it’s straightforward.)
- Efficient storage mechanism. Clickhouse’s columnar storage format, coupled with highly effective compression algorithms (like LZ4 and ZSTD) and sparse primary indexes, leads to significant storage efficiency and fast data scanning.
- You can alter schemas, use nested/array types, apply TTLs or replacements on tables. ClickHouse is quite forgiving with data formats (CSV, JSON, Parquet, etc).
- Active open source community
- ClickHouse generally requires fewer nodes than Apache Druid for comparable workloads, so hardware cost can be lower. And it’s Apache 2.0 open source (no licensing fee).
ClickHouse Limitations:
- ClickHouse is not truly Real-Time. It batches inserts, so there’s a lag before new data is queryable. For use cases demanding instant visibility, this can be a drawback.
- Growing a cluster (sharding/replication) in ClickHouse requires planning and manual configuration. There’s no built-in elasticity or autoscaling in the open source version.
- You must design shards and replication factors yourself. If coordination (ZooKeeper) fails, writes can’t be replicated.
- Mutations (ALTER TABLE... UPDATE/DELETE) are heavyweight, asynchronous background operations that rewrite data parts; not designed for frequent, OLTP-style modifications and can be resource-intensive.
- ClickHouse is less suitable for High Concurrency dashboards. ClickHouse can handle many queries, but its design means very high concurrent interactive loads (thousands of users) can stress the system more than Apache Druid.
- ClickHouse has limited secondary indexes. By default it only has the sparse index. Queries on non-key columns may require full scans or custom skip indexes (BloomFilter, etc) which add admin overhead.
- Denormalization is often needed in ClickHouse. For speed, you may need to pre-join or denormalize data. Joins are supported but can be slower than scanning a single table.
ClickHouse and Druid are active open source projects, so limitations are addressed and new features are added over time.
Apache Druid Pros and Cons
Next up lets see Apache Druid Pros and Cons.
Apache Druid Pros:
- Apache Druid can provide sub-second freshness of streaming data, making it a perfect fit for live dashboards and monitoring.
- Apache Druid is designed for interactive analytics: it can handle thousands of simultaneous queries (e.g. Tableau users) with low latency.
- Apache Druid provides automatic workload management. The Coordinator automatically balances data and enforces replication, and queries are automatically parallelized across segments.
- Apache Druid has built-in OLAP features. It has native support for top-N queries, approximate analytics (count-distinct, percentiles), and bitmap indexes for lightning-fast filters.
- You can scale ingestion, storage, and query layers independently. Hots-warm architecture lets you keep recent data on fast nodes and older data on cheap storage.
- Apache Druid provides first-class connectors to Kafka and Kinesis, plus reliability features like exactly-once ingestion via Kafka offsets.
- Imply (the original Druid creators) offers a managed platform, and many large companies use Druid (Netflix, Yahoo, etc). Its own UI and SQL interface are mature.
Apache Druid Cons:
- It is complex. Running a production Apache Druid cluster involves many moving parts: at least ZooKeeper + metadata store + multiple Druid services. Tuning memory and JVM for each service can be challenging.
- Since Apache Druid favors denormalized event tables, you often need to flatten data beforehand. Joins are very limited, so multi-table queries are hard.
- Apache Druid typically requires more hardware. Thousands of cheap servers may be needed for massive scale. The necessity of deep storage and caching adds cost.
- Apache Druid lag for batch queries. While streaming is real-time, if you load backfill data or compact segments, queries can slow during compaction. Dropping/altering data is not as straightforward.
- Some analytical SQL features (like window functions) are missing in Apache Druid. Schema evolution (adding columns) is possible but more manual.
- Apache Druid has been noted to have “no fault tolerance on the query execution path”: if a Historical node fails during a query, that portion may fail unless retries occur.
ClickHouse vs Druid: What's Best for You?
So, after laying out all these features, the big question remains: when should you pick ClickHouse, and when is Apache Druid the better choice.
Pick Apache Druid if:
- Your primary goal is powering interactive dashboards or applications where users expect query results almost instantly, even with complex filters.
- You need to ingest data from streaming sources like Apache Kafka or Amazon Kinesis and make it queryable within seconds of its arrival, with strong delivery guarantees.
- Your application will have many users or services querying the data simultaneously, requiring robust support for hundreds or even thousands of queries per second (QPS) while maintaining low latency.
- Your queries frequently filter by time ranges, and you need fast filtering and aggregation across various dimensions within those time windows.
- You need the flexibility to scale ingestion, storage, and query resources independently based on bottlenecks, ideally with automated data rebalancing.
- You want the database to handle indexing for filtering dimensions automatically, reducing the need for manual tuning.
- You need strong fault tolerance backed by independent deep storage and automated segment recovery/rebalancing.
- You require features like query prioritization (lanes) or resource tiering to manage mixed workloads effectively.
- Your data sources have evolving schemas, and you need the database to adapt, potentially using auto-discovery.
Pick ClickHouse if:
- You need the absolute fastest performance for heavy analytical queries, including complex aggregations, large scans, and potentially some JOINs.
- You primarily load data in large batches or can tolerate the slight delay of micro-batching for streaming sources.
- You need rich and flexible SQL capabilities. Your analysis requires complex data manipulation, leveraging a wide array of built-in functions directly in SQL.
- Storage efficiency and compression are major concerns. Minimizing disk footprint is critical, and you want to leverage best-in-class compression.
- You prefer a less complex setup, especially if your scale doesn't immediately warrant Druid's full distributed complexity.
- You have the expertise or willingness to tune primary keys, configure data skipping indexes, and manage cluster scaling manually (for self-hosting).
- Your main goal is processing large analytical jobs quickly, rather than serving thousands of concurrent low-latency requests.
- You need more capable JOINs. While still requiring optimization, ClickHouse generally offers more robust JOIN capabilities than Druid.
It's not about which database is the best fit overall, but which one suits you. Think about what matters most and match those priorities to what ClickHouse and Druid do well.
Conclusion
And that wraps up our ClickHouse vs Druid comparison. If you are trying to pick between ClickHouse and Druid, remember that both are incredibly mature, powerful, open source columnar databases capable of delivering impressive analytical performance at scale. They've earned their places as top contenders in the OLAP space for good reasons.
ClickHouse truly stands out for its raw query speed, especially on complex analytical tasks, its resource efficiency, and its powerful SQL dialect. It's often the champion when maximum throughput on batch data or heavy computations is the goal. Apache Druid, on the other hand, is purpose-built for scenarios demanding true real-time ingestion, sub-second query latency, and extremely high concurrency. Its strength lies in powering interactive applications and dashboards where immediate data visibility and responsiveness under load are crucial. So the best option entirely depends on you and what best aligns with your specific workload patterns (streaming vs batch), query requirements (latency vs throughput, complexity), concurrency needs, operational capabilities, and tolerance for architectural complexity.
In this article, we have covered:
- What is ClickHouse?
- What is Apache Druid?
- What Is the Difference Between ClickHouse vs Druid?
- ClickHouse vs Druid—Architecture
- ClickHouse vs Druid—Data Storage & Format
- ClickHouse vs Druid—Data Ingestion
- ClickHouse vs Druid—Query Execution Model
- ClickHouse vs Druid—Indexing
- ClickHouse vs Druid—Concurrency
- ClickHouse vs Druid—Fault Tolerance & HA
- ClickHouse vs Druid—SQL Support
- ClickHouse vs Druid—Scalability
- ClickHouse vs Druid—Ecosystem
- ClickHouse vs Druid — Pros & Cons
… and so much more!
FAQs
Which database is faster than ClickHouse?
Database speed depends heavily on the specific workload and query type. ClickHouse is known for its high performance, especially in raw scan speed and complex aggregations , but some databases might outperform it in specific scenarios. Say Apache Druid can be faster for queries requiring high concurrency and heavy filtering on time and dimensions. Some other specialized commercial databases or various open source DBs are also faster on certain query types. But, there isn't one universally "faster" database; performance is context-dependent.
Is Apache Druid good?
Yes, Apache Druid is widely regarded as a powerful and effective database, particularly for real-time analytics use cases. It excels in scenarios demanding fast data ingestion (especially streaming), low-latency queries (often sub-second), high concurrency, and efficient analysis of event-driven or time-series data. Plus it has been widely adopted by big tech giants.
Why is Apache Druid fast?
Druid achieves its speed through a combination of architectural choices and optimizations tailored for OLAP workloads like Columnar Storage, Time-based Partitioning, Indexing (Dictionary Encoding & Bitmaps), Data Locality, Scatter/Gather Query Execution, Optional Rollup/Summarization and so much more.
Who are the typical users of Apache Druid?
Apache Druid is typically used by organizations needing to analyze large volumes of real-time and historical event data with low latency and high concurrency.
How mature is Apache Druid as a technology?
Apache Druid is considered mature and well-established. It originated around 2011 , was open sourced shortly after, and is now an Apache Software Foundation project. It has been deployed in demanding production environments at large scale by numerous major companies for several years.
Is ClickHouse open source?
Yes, ClickHouse is open source software. It is distributed under the permissive Apache License 2.0.
Can ClickHouse replace traditional RDBMS systems?
Generally, no. ClickHouse is an OLAP (Online Analytical Processing) database optimized for fast analytical queries over large datasets. Traditional RDBMS like PostgreSQL or MySQL are typically OLTP (Online Transaction Processing) databases, designed for frequent reads, writes, updates, and deletes of individual records with strong consistency (ACID) guarantees. ClickHouse lacks efficient row-level updates/deletes and full ACID transaction support, making it unsuitable for OLTP workloads.
Are ClickHouse and Druid ACID compliant?
No, neither ClickHouse nor Druid are fully ACID (Atomicity, Consistency, Isolation, Durability) compliant in the traditional RDBMS sense.
How does ClickHouse manage updates and deletes?
ClickHouse provides several methods for modifying data, differing significantly from traditional OLTP updates/deletes:
- Mutations (ALTER TABLE... UPDATE/DELETE... WHERE...)
- Lightweight Deletes (DELETE FROM... WHERE...)
- Partition Dropping (ALTER TABLE... DROP PARTITION...)
ClickHouse vs Druid—which one is easier to operate?
ClickHouse’s deployment is simpler in that you mainly run a ClickHouse server (plus ZooKeeper/ClickHouse Keeper). Druid requires multiple services and usually a metadata DB. However, ClickHouse requires manual cluster management (shards, replication), whereas Druid automates data balancing. For a small or medium setup, ClickHouse is usually easier (single binary to install). For very large, dynamic environments, Druid’s automation is beneficial if you have the operational expertise.
Can ClickHouse query “live” streaming data like Kafka in real time?
ClickHouse can ingest streams (it has a Kafka engine and materialized views for Kafka topics), but this data is buffered. In practice, ClickHouse processes Kafka messages in micro-batches (often on the order of seconds). Newly arriving events will appear in query results after the next flush, not instantaneously.
Can I use Kafka for ingestion in both ClickHouse and Druid?
Yes. ClickHouse has a Kafka table engine that pulls from Kafka topics (partitioned by topic+partition) and can feed data into MergeTree tables via materialized views. Druid has a Kafka indexing service (supervisor) which assigns Kafka partitions to ingestion tasks.
Is there a managed cloud option for ClickHouse and Druid?
Yes. ClickHouse Cloud (by Altinity/ClickHouse Inc) offers a serverless ClickHouse with auto-scaling. For Druid, Imply (the company behind Druid) offers Imply Cloud, a managed Druid service.















